HiveHadoopSQL开源MapReduceImpala大数据初创公司
在GigaOM安排Structure: Data的日程的时候,就意识到很有必要讨论在Hadoop上运行SQL查询,然而却未认识到Hadoop上运行SQL查询竟然变的这么重要。
本文是Gigaom的资深编辑Derrick Harris?撰写的一篇文章,其实,对SQL支持并不是Hadoop的最终目标,但是这一特性将会帮助Hadoop找寻自己的生存方式,让Hadoop在那些已经明白下一代分析的重要性但又不想迈向MapReduce专家之路的公司中取得一席之地。
当然,Facebook发起了整场运动 ――在2009年创造了Hive,它把类似数据库SQL查询功能引向了Hadoop 。Hive现在已经是Apache的一个开源项目,包括数据管理层以及类SQL的结构化查询语言HiveQL。在过去的数年里,Hive的确是非常有用而且很流行,但是由于Hive对MapReduce依赖,查询速度有着“先天性不足”,因为在查询的过程中,MapReduce需要扫描整个数据集,而且在Job的处理过程中还需要把大量的数据传输到网络。对主流用户而言,难以有很大的吸引力。
请记住,下一代的SQL-on-Hadoop工具并不仅仅只是商业智能,也不是仅仅只能读取存储在Hadoop上数据的数据库产品, EMC Greenplum, HP Vertica, IBM Netezza, ParAccel, Microsoft SQL Server以及Teradata/Aster Data全部都允许某些方式的Hadoop数据查询。而且这些是应用,框架以及可以让用户从内部进行Hadoop数据查询的引擎,有时候也会重构底层计算以及数据基础设施。这种方式的优点在于:可以利用已有存储形式的数据,从理论上讲,对数据的分析应用就不需要再访问两个独立的数据存储。
数据仓库和BI:The Structure: Data set
Apache Drill: Drill是由MapR主导、基于Hadoop之上的类似于谷歌的Demel(或者说BigQuery)交互式查询引擎。首次公布在8月份,不过该项目正处在开发阶段,也是Apache的孵化器计划,根据其网站所言:“(Drill)明确的目标就是扩展到10000台服务器,而且能够在几秒钟之内处理PB级的数据和数万亿条的记录。”
MapR的产品管理总监Tomer Shiran表示:“Drill与MapReduce相辅相成。在谷歌,数以千计的工程师每天都在使用Dremel和MapReduce,未来也将有着更多的人来使用Drill与MapReduce。 ”
Hadapt:Hadapt实际上在2011年的Structure: Data大会上发布,它也是第一批SQL-on-Hadoop的厂商之一,其独特之处在于,在市场上已经有了真正的产品,而且已经培育了自己的客户群。其独一无二的架构包括先进的SQL分析工具,为MapReduce以及相关任务打造的split-execution引擎,也包含HDFS和相关的存储。

Hadapt提供了一体化的分析环境,旨在对Hadoop里面的数据执行分析操作,还能对SQL环境中传统的结构化数据进行分析。而Hadapt的平台设计成了可以在私有云或公共云环境上运行,提供了从一个环境就能访问所有数据的优点,所以除了MapReduce流程和大数据分析工具外,现有的基于SQL的工具也可以使用。Hadapt可以在Hadoop层和关系数据库层之间自动划分查询执行任务,提供了Hadapt所谓的优化环境,这种环境可以充分利用Hadoop的可扩展性和关系数据库技术的快速度。
Platfora:从技术来讲,这并不是一个SQL产品,Platfora现在是“红的发紫”,而且意图打造大数据商业智能(BI)的新蓝图。大家都知道,如何能够把冗杂的数据(不管是邮件、文档、音频等)进行有效处理、视觉化,让它变成普通的用户都能看得懂的东西,“数据”才能真正变得有价值。但是Hadpoop只有一小部分开发者(相对而言)在使用,而Platfora却想把它变成一个任何人都可以理解、使用的工具。虽然也有其他的创业者在做类似的事情,但是Platfora在数据处理速度上有明显的优势,同时非常直观,并且他们在用HTML5的canvas来做解决方案,既可以保证操作简便又能兼容不同设备上的数据,公司在10月份进行的产品发布。
Qubole:Qubole是一个建设云平台进行数据分析和处理的创业公司。联合创始人兼CEO是Ashishi Thusoo,在创办Qubole之前,Ashishi负责Facebook数据基础设施团队。在他的领导下,团队创造了世界上最大的数据分析与处理平台。他也是Apache Hive项目的联合创始人,并作为该项目的Apache软件基金会的创始副总裁。Qubole声称具有自动扩展能力,并且对Hadoop代码做过优化,高速的列数据缓存可以让其服务比单独运行Hive时要快很多。Qubole运行在AWS上,相对而言,这比维护一个物理集群要容易得多。

数据仓库和BI:续篇
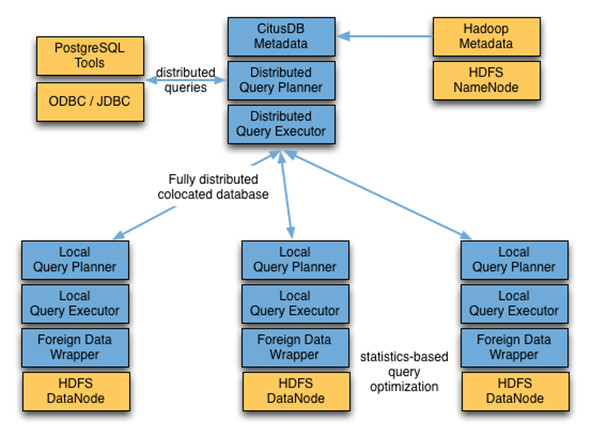
Citus Data: Citus Data的CitusDB并不仅仅只关注于Hadoop,而是想把其分布式的Postgres能力扩展到所有的数据类型中。其中的一项功能“foreign data wrappers”,它能够把多种数据类型(像CSV, log以及JSON files,而且这些数据类型在原生的Postgres上是并不匹配的)转化成数据库的原生类型,接下来在几秒钟之内就能使用其特有的分布式处理技术来完成查询。由于其Postgres的功能,CitusDB也能连接不同的数据源(比如Postgres-Hadoop),这样就不需要用户进行独立的查询,然后再手动地连接数据。
Cloudera Impala:Cloudera Impala可能是SQL-on-Hadoop上最重要的成果,这是一个大规模的并行处理引擎,成功避开了MapReduce进行交互式地查询部署在HDFS或者Hbase中的数据。不过,因为Cloudera并不构建应用程序,它依赖更高层次的BI和分析合作伙伴为用户提供接口。
在2012年纽约进行的大数据技术会议Strata Conference + Hadoop World上,Cloudera发布了实时查询开源项目Impala 1.0 beta版,称 比原来基于MapReduce的Hive SQL查询速度提升3~90倍,而且更加灵活易用。Impala不再使用缓慢的Hive+MapReduce批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或者HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。其架构如下图所示。

Impala的架构(来自ZDNet)
Karmasphere:就像Hive一样,Karmasphere也是依赖于MapReduce处理查询,这也就意味着其速度要慢于其他的新途径。与Hive不同的是,Karmasphere允许并行查询,而且其包含一个可视化的界面,可以用于编写查询以及过滤查询结果。
Karmasphere提供了直接访问Hadoop里面结构化和非结构化数据的优点,它还可以运用SQL及其他语言,用于即席查询和进一步的分析。使用SQL及其他语言,用户就能创建即席查询,然后处理结果。Karmasphere Studio为开发人员提供了一种图形化环境,可以在里面开发自定义算法,为应用程序和可重复的生产流程创建实用的数据集。
Lingual:Lingual是来自Concurrent的一个新的开源项目,其母公司从事Hadoop Cascading框架设计。Lingual运行在Cascading之上,(Cascading是一个架构在Hadoop上的API,用来创建复杂和容错数据处理工作流。它抽象了集群拓扑结构和配置来快速开发复杂分布式的应用,而不用考虑背后的MapReduce),并提供给开发者和分析师一个真正的ANSI SQL接口,在其之上可以运行分析或者是构建应用。Lingual兼容传统的BI工具,JDBC以及Cascading系的API。
Phoenix:Phoenix是一个新的,相对来说并不为人知的一个开源项目,出自Salesforce.com,旨在打造一个更快的SQL查询,面向的对象有HBase或者是部署在HDFS之上的NoSQL数据库。用户通过JDBC接口与其进行交互。

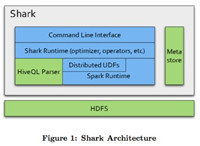 Shark:Shark虽然不是技术上的Hadoop,但是它们也有很深的渊源。Shark,从一定意义上说代表了“Hive on Spark”,使用Hive也就意味着它与Hadoop也存在着密切的关系。使用Shark运行并行处理Job要比MapReduce快100倍,Shark宣称对比传统的Hive而言,这是一个巨大的提升。
Shark:Shark虽然不是技术上的Hadoop,但是它们也有很深的渊源。Shark,从一定意义上说代表了“Hive on Spark”,使用Hive也就意味着它与Hadoop也存在着密切的关系。使用Shark运行并行处理Job要比MapReduce快100倍,Shark宣称对比传统的Hive而言,这是一个巨大的提升。
Stinger Initiative:Stinger Initiative是由Hortonworks主导的 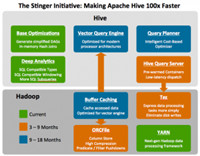 一个科研成果,可以让Hive的速度提升高达100倍,而且引入了更多的功能。Stinger为Hive添加了更多的SQL分析能力,但是最关键的方面在于底层基础设施的提升:一个优化的执行引擎,一个列式文件格式,能够避免MapReduce的运行瓶颈。
一个科研成果,可以让Hive的速度提升高达100倍,而且引入了更多的功能。Stinger为Hive添加了更多的SQL分析能力,但是最关键的方面在于底层基础设施的提升:一个优化的执行引擎,一个列式文件格式,能够避免MapReduce的运行瓶颈。
Operational SQL
Drawn to Scale:Drawn to Scale也是一家初创公司,它在HBase之上构建了一个 SQL数据库,这里的关键词是“数据库”。其产品称之为Spire,它仿照了谷歌的F1设计。Spire拥有一个分布式索引,所有的查询只发送给相关数据的存储节点,所以其读取和写入的速度都很快,系统还能够处理大量的并发用户。

 Splice Machine:Splice Machine(数据库初创公司)也尝试通过在原生的HBase分布式数据库上建立其Splice SQL Engine来取得一席之地。Splice Machine关注的是事务完整性,这也是它区别于可扩展的NoSQL数据库和分析类SQL-on-Hadoop产品的特色所在。它依赖于HBase的auto-sharding功能,这也是为了让扩展变得更加容易
Splice Machine:Splice Machine(数据库初创公司)也尝试通过在原生的HBase分布式数据库上建立其Splice SQL Engine来取得一席之地。Splice Machine关注的是事务完整性,这也是它区别于可扩展的NoSQL数据库和分析类SQL-on-Hadoop产品的特色所在。它依赖于HBase的auto-sharding功能,这也是为了让扩展变得更加容易