З°СФ
ЙПјёЖӘОДХВОТГЗҪйЙЬБЛИзәОІйҝҙІйСҜјЖ»®ЎўіЈУГФЛЛг·ыөДҪйЙЬЎўІўРРФЛЛгөД·ҪКҪЈ¬УРРЛИӨөДҝЙТФөг»чІйҝҙЎЈ
ұҫЖӘҪ«·ЦОцФЪSQL ServerЦРЈ¬ИзәОАыУГПИУРЛчТэПоҪшРРІйСҜРФДЬУЕ»ҜЈ¬НЁ№эБЛҪвХвР©ЛчТэПоөДУҰУГ·ҪКҪҝЙТФЦёөјОТГЗИзәОҪЁБўЛчТэЎўөчХыОТГЗөДІйСҜУпҫдЈ¬ҙпөҪРФДЬУЕ»ҜөДДҝөДЎЈ
ПРСФЙЩРрЈ¬ҪшИлұҫЖӘөДХэМвЎЈ
јјКхЧјұё
»щУЪSQL Server2008R2°жұҫЈ¬АыУГОўИнөДТ»ёцёьјтҪаөД°ёАэҝвЈЁNorthwindЈ©ҪшРРҪвОцЎЈ
јтҪй
ЛщОҪөДЛчТэУҰУГҫНКЗФЪОТГЗИХіЈРҙөДT-SQLУпҫдЦРЈ¬ИзәОАыУГПЦУРөДЛчТэПоЈ¬ФЩ·ЦОцөД»°ҫНКЗОТГЗЛщРҙөДІйСҜМхјюЈ¬ЖдКөҙуІҝ·ЦЗйҝцТІОЮ·ЗТФПВјёЦЦЈә
1ЎўөИУЪОҪҙКЈәselect ...where...[email protected]
2ЎўұИҪПОҪҙКЈәselect ...where...column> or < or <> or <= or >= @parameter
3Ўў·¶О§ОҪҙКЈәselect ...where...column in or not in or between and @parameter
4ЎўВЯјӯОҪҙКЈәselect ...where...Т»ёцОҪҙК orЎўand ЖдЛьОҪҙК orЎўand ёь¶аОҪҙК....
ОТГЗҫНТАҙО·ЦОцЙПГжјёЦЦЗйҝцПВЈ¬ИзәОАыУГЛчТэҪшРРІйСҜУЕ»ҜөД
Т»Ўў¶ҜМ¬ЛчТэІйХТ
ЛщОҪөД¶ҜМ¬ЛчТэІйХТҫНКЗSQL ServerФЪЦҙРРУпҫдөДКұәтЈ¬ІЕёсКҪ»ҜІйСҜМхјюЈ¬И»әуёщҫЭІйСҜМхјюөДІ»Н¬ЧФ¶ҜөДИҘЖҘЕдЛчТэПоЈ¬ҙпөҪРФДЬМбЙэөДДҝөДЎЈ
АҙҫЩёцАэЧУ
SET SHOWPLAN_TEXT ONGOSELECT OrderIDFROM OrdersWHERE ShipPostalCode IN (N'05022',N'99362')
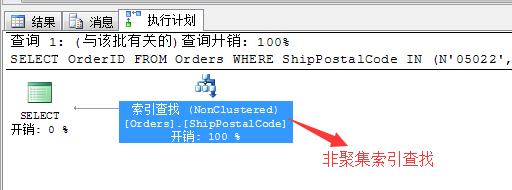
ТтОӘОТГЗФЪұнOrdersөДБРShipPostalCodeБРЦРҪЁБўБЛ·ЗҫЫјҜЛчТэБРЈ¬ЛщТФХвАпІйСҜөДјЖ»®АыУГБЛЛчТэІйХТөД·ҪКҪЎЈХвТІКЗРиТӘҪЁБўЛчТэөДөШ·ҪЎЈ
ОТГЗАҙАыУГОДұҫөД·ҪКҪАҙІйҝҙёГУпҫдөДПкПёөДЦҙРРјЖ»®ҪЕұҫЈ¬УпҫдұИҪПіӨЈ¬ОТУГјЗКВұҫ»»РРЈ¬ёсКҪ»ҜІйҝҙ
ОТГЗЦӘөАХвХЕұнөДёГБРАпҙжФЪТ»ёц·ЗҫЫјҜЛчТэЈ¬ЛщТФФЪІйСҜөДКұәтТӘҫЎБҝК№УГЈ¬Из№ыНЁ№эЛчТэЙЁГиөД·ҪКҪПыәДҫНұИјЫҙуБЛЈ¬ЛщТФSQL ServerҫЎБҝПлІЙИЎЛчТэІйХТөД·ҪКҪЈ¬ЖдКөIN№ШјьЧЦәНOR№ШјьЧЦВЯјӯКЗТ»СщөДЎЈ
УЪКЗЙПГжөДІйСҜМхјюҫНЧӘ»»іЙБЛЈә
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'05022'
OR
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'99362'
ХвСщҫНҝЙТФІЙУГЛчТэІйХТБЛЈ¬ПИІйХТөЪТ»ёцҪб№ыЈ¬И»әуФЩІйХТөЪ¶юёцЈ¬¶шХвёц№эіМФЪSQL ServerЦРҫНұ»іЖОӘЈә¶ҜМ¬ЛчТэІйХТЎЈ
КЗІ»КЗУРөгЦЗДЬөДёРҫхБЛ....
ЛщТФУРКұәтОТГЗРҙУпҫдөДКұәтЈ¬ҫЎБҝТӘК№УГSQL ServerөДХвөгЦЗДЬБЛЈ¬ИГЖдДЬЧФ¶ҜөДІйХТөҪЛчТэЈ¬МбЙэРФДЬЎЈ
УРКұәтЖ«Ж«ОТГЗРҙөДУпҫдИГSQL ServerөДЦЗДЬПыК§Ј¬ҫЩёцАэЧУЈә
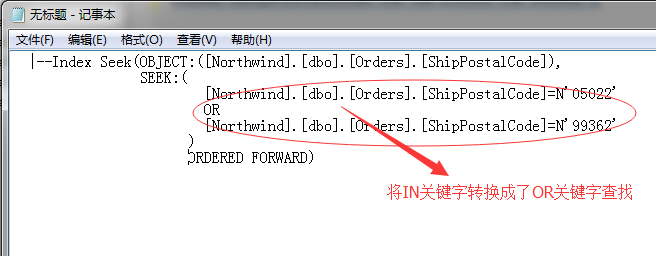
--ІОКэ»ҜІйСҜМхјюDECLARE @Parameter1 NVARCHAR(20),@Parameter2 NVARCHAR(20)SELECT @Parameter1=N'05022',@Parameter2=N'99362'SELECT OrderIDFROM OrdersWHERE ShipPostalCode IN (@Parameter1,@Parameter2)
ОТГЗҪ«ХвБҪёцҫІМ¬өДЙёРтЦөёДіЙІОКэЈ¬УРКұәтОТГЗРҙөДҙжҙў№эіМ»ТіЈПІ»¶ХвГҙЧцЈЎОТГЗАҙҝҙХвЦЦ·ҪКҪөДЙъіЙөДІйСҜјЖ»®
ұҫАҙәЬјтөҘөДТ»ёц·ЗҫЫјҜЛчТэІйХТёг¶ЁөДЦҙРРјЖ»®Ј¬ОТГЗЦ»КЗҪ«ХвБҪёцКэЦөГ»УРЦұҪУРҙИлIN№ШјьЧЦЦРЈ¬¶шКЗАыУГБЛБҪёцұдБҝАҙҙъМжЎЈ
ҝҙҝҙЙПГжSQL ServerЙъіЙөДІйСҜјЖ»®ЈЎДбВк...Хв¶јКЗР©Й¶ЈҝЈҝЈҝ»№УГЖрАҙЗ¶МЧСӯ»·Ј¬ОТҫНІйСҜБЛТ»ёцOrdersұн...ДгЗ¶МЧСӯ»·ёцЙ¶....ЙПГж¶ҜМ¬ЛчТэІйХТөДДЬБҰИҘДДБЛЈҝЈҝЈҝ
әГ°ЙЈ¬ОТГЗУГОДұҫІйСҜјЖ»®АҙІйҝҙПВЈ¬ХвёцјтөҘөДУпҫдөҪөЧФЪёЙР©Й¶...
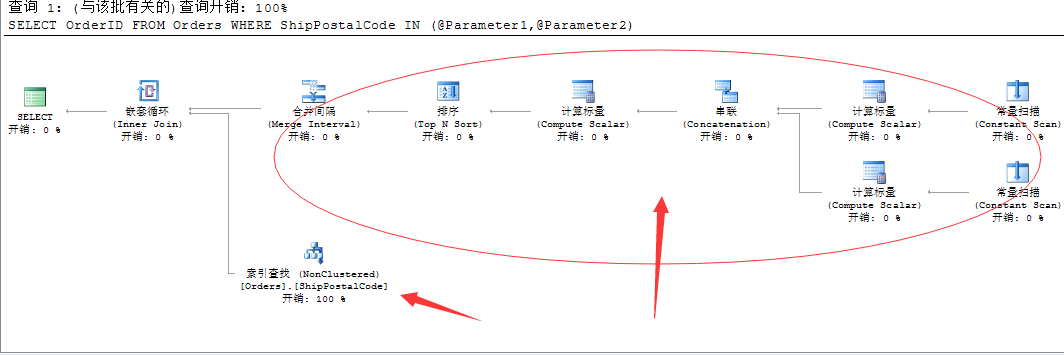
|--Nested Loops(Inner Join, OUTER REFERENCES:([Expr1009], [Expr1010], [Expr1011])) |--Merge Interval | |--Sort(TOP 2, ORDER BY:([Expr1012] DESC, [Expr1013] ASC, [Expr1009] ASC, [Expr1014] DESC)) | |--Compute Scalar(DEFINE:([Expr1012]=((4)&[Expr1011]) = (4) AND NULL = [Expr1009], [Expr1013]=(4)&[Expr1011], [Expr1014]=(16)&[Expr1011])) | |--Concatenation | |--Compute Scalar(DEFINE:([Expr1004]=[@Parameter2], [Expr1005]=[@Parameter2], [Expr1003]=(62))) | | |--Constant Scan | |--Compute Scalar(DEFINE:([Expr1007]=[@Parameter1], [Expr1008]=[@Parameter1], [Expr1006]=(62))) | |--Constant Scan |--Index Seek(OBJECT:([Northwind].[dbo].[Orders].[ShipPostalCode]), SEEK:([Northwind].[dbo].[Orders].[ShipPostalCode] > [Expr1009] AND [Northwind].[dbo].[Orders].[ShipPostalCode] < [Expr1010]) ORDERED FORWARD)
НҰёҙФУөДКЗ°ЙЈ¬ЖдКөОТ·ЦОцБЛТ»ПВҪЕұҫЈ¬№ШУЪОӘКІГҙ»бЙъіЙХвёцјЖ»®ҪЕұҫөДФӯТтЈ¬КЗОӘБЛҪвҫцИзПВјёёцОКМвЈә
1ЎўЗ°ГжОТГЗРҙөДҪЕұҫФЪINАпГжРҙөДКЗБҪёціЈБҝЦөЈ¬ІўЗТКЗІ»Н¬өДЦөЈ¬ЛщТФРОіЙБЛБҪёцЛчТэЦөөДІйХТНЁ№эOR№ШјьЧЦЧйәПЈ¬
ХвЦЦ·ҪКҪГІЛЖГ»ОКМвЈ¬ө«КЗОТГЗҪ«ХвБҪёцКэЦөұдіЙБЛІОКэЈ¬ХвҫНТэАҙБЛРВөДОКМвЈ¬јЩИзХвБҪёцІОКэОТГЗКдИлөДКЗПаөИөДЈ¬ДЗГҙАыУГЗ°ГжөДЦҙРРјЖ»®ҫН»бЙъіЙИзПВ
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'05022'
OR
[Northwind].[dbo].[Orders].[ShipPostalCode]=N'05022'
ХвСщЦҙРРІъЙъөДКдіцҪб№ыҫНКЗ2МхТ»СщөДКдіцЦөЈЎ...ө«КЗұнАпГжИ·КөЦ»УР1МхКэҫЭ...ЛщТФХвСщКдіцҪб№ыІ»ХэИ·ЈЎ
ЛщТФұдіЙІОКэәуКЧПИҪвҫцөДОКМвҫНКЗИҘЦШОКМвЈ¬2ёцТ»СщөДұдіЙ1ёцЎЈ
2ЎўЙПГжұдіЙІОКэЈ¬»№ТэИлБЛБнНвТ»ёцОКМвЈ¬јУИлОТГЗБҪёцЦөУРТ»ёцҙ«ИлөДОӘNullЦөЈ¬»тХЯБҪёц¶јОӘNullЦөЈ¬Н¬СщКдіцҪб№ыГжБЩЧЕХвСщөДОКМвЎЈЛщТФХвАп»№ТӘҪвҫцөДИҘNullЦөөДОКМвЎЈ
ОӘБЛҪвҫцЙПГжөДОКМвЈ¬ОТГЗАҙҙЦВФөД·ЦОцТ»ПВЦҙРРјЖ»®Ј¬ҝҙSQL ServerИзәОҪвҫцХвёцОКМвөД
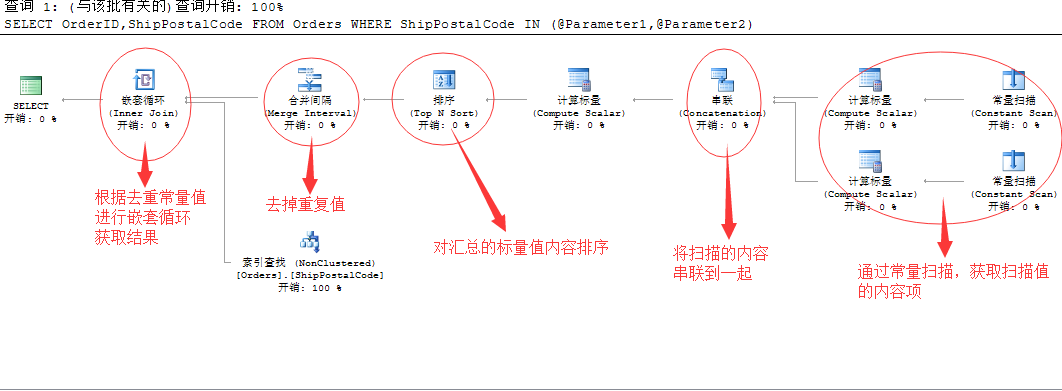
јтөҘөгҪ«ҫНКЗНЁ№эЙЁГиұдБҝЦРөДЦөЈ¬И»әуҪ«ДЪИЭҪшРР»гЧЬЦөЈ¬И»әуФЪҪшРРЕЕРтЈ¬ФЩҪ«ІОКэЦРөДЦШёҙЦөИҘөфЈ¬ХвСщ»сИЎөДЦөҫНКЗТ»ёцХэИ·өДЦөЈ¬ЧоәуДГХвР©ИҘЦШәуөДІОКэЦөІОУлөҪЗ¶МЧСӯ»·ЦРЈ¬әНұнOrdersҪшРРЛчТэІйХТЎЈ
ө«КЗ·ЦОцөД№эіМЦРЈ¬УРТ»ёцОКМвОТТІГ»ҝҙГч°ЧЈ¬ҫНКЗЧоәГөДҫӯ№эИҘЦШЦ®әуөДіЈБҝ»гЧЬЦөЈ¬УГАҙЗ¶МЧСӯ»·Б¬ҪУөДКұәтЈ¬ФЪПВГжөДЛчТэІйХТөДКұәтөД№эВЛМхјюұдіЙБЛ and ІйХТ
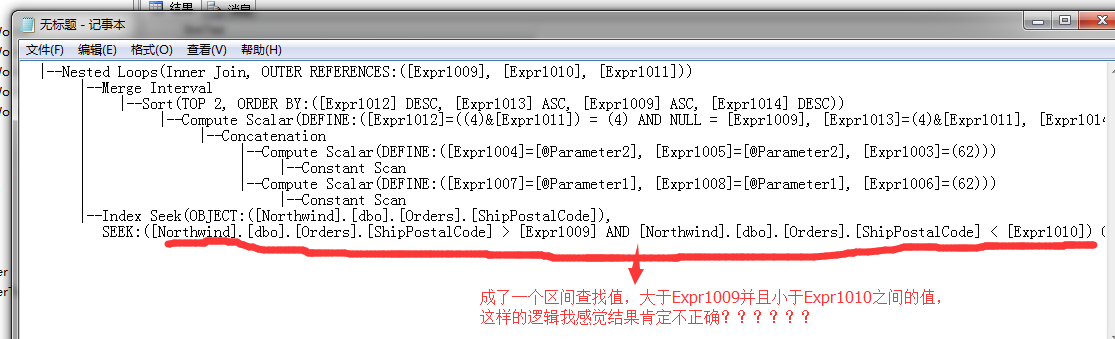
ОТҪ«ЙПГжөДЧоәуөДЛчТэІйХТМхјюЈ¬ХыАнИзПВЈә
|--Index Seek(OBJECT:([Northwind].[dbo].[Orders].[ShipPostalCode]), SEEK:
(
[Northwind].[dbo].[Orders].[ShipPostalCode] > [Expr1009]
AND
[Northwind].[dbo].[Orders].[ShipPostalCode] < [Expr1010]
) ORDERED FORWARD)
ХвёцөШ·ҪФхГҙёгөДЈҝОТТІГ»ЕӘЗеіюЈ¬»№НыУРҝҙГч°ЧНҜР¬өДЙФјУЦёөјПВ....
әГБЛЈ¬ОТГЗјМРш
ЙПГжөДЦҙРРјЖ»®ЦРЈ¬МбөҪБЛТ»ёцРВөДФЛЛг·ыЈәәПІўјдёфЈЁmerge interval operatorЈ©
ОТГЗАҙ·ЦОцПВХвёцФЛЛг·ыөДЧчУГЈ¬ЖдКөФЪЙПГжОТГЗТСҫӯФЪЦҙРРјЖ»®өДНјЦРұкКҫіцёГФЛЛг·ыөДЧчУГБЛЈ¬ИҘөфЦШёҙЦөЎЈ
ЖдКө№ШУЪИҘЦШөДІЩЧчУРәЬ¶аөДЈ¬ұИИзЗ°ГжОДХВЦРОТГЗМбөҪөДёчЦЦИҘЦШІЩЧчЎЈ
ХвАпФхГҙУЦГ°іцёцәПІўјдёфИҘЦШЈҝЖдКөФӯТтәЬјтөҘЈ¬ТтОӘОТГЗФЪК№УГХвёцФЛЛг·ыЦ®З°ТСҫӯ¶ФҪб№ыҪшРРБЛЕЕРтІЩЧчЈ¬ЕЕРтәуөДҪб№ыПоЦШёҙЦөКЗҪфҪфҝҝФЪТ»ЖрөДЈ¬ЛщТФҫНТэИлБЛәПІўјдёфөД·ҪКҪИҘҙҰАнЈ¬ХвСщРФДЬКЗЧоәГөДЎЈ
ёьЦШТӘөДКЗәПІўјдёфХвЦЦФЛЛг·ыУҰУГіЎҫ°І»ҪцҪцҫЦПЮУЪЦШёҙЦөөДИҘіэЈ¬ёьЦШТӘөДКЗ»№УҰУГУЪЦШёҙЗшјдөДИҘіэЎЈ
АҙҝҙПВГжөДАэЧУ
--ІОКэ»ҜІйСҜМхјюDECLARE @Parameter1 DATETIME,@Parameter2 DATETIMESELECT @Parameter1='1998-01-01',@Parameter2='1998-01-04'SELECT OrderID FROM ORDERSWHERE OrderDate BETWEEN @Parameter1 AND DATEADD(DAY,6,@Parameter1)OR OrderDate BETWEEN @Parameter2 AND DATEADD(DAY,6,@Parameter2)
ОТГЗҝҙҝҙХвёцЙъіЙөДІйСҜјЖ»®По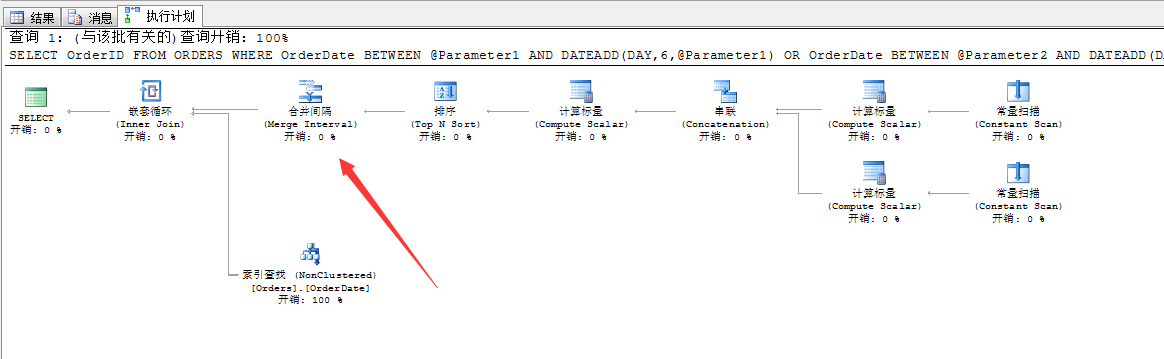
ҝЙТФҝҙөҪЈ¬SQL ServerОӘОТГЗЙъіЙөДІйСҜјЖ»®Ј¬әНЗ°ГжОТГЗРҙөДУпҫдКЗТ»ДЈТ»СщөДЈ¬өұИ»ОТГЗөДУпҫдТІГ»Чц¶аЙЩёД¶ҜЈ¬ёД¶ҜөДөШ·ҪҫНКЗІйСҜМхјюЙПЎЈ
ОТГЗАҙ·ЦОцПВХвёцІйСҜМхјюЈә
WHERE OrderDate BETWEEN @Parameter1 AND DATEADD(DAY,6,@Parameter1)
OR OrderDate BETWEEN @Parameter2 AND DATEADD(DAY,6,@Parameter2)
әЬјтөҘөДЙёСЎМхјюЈ¬ТӘ»сИЎ¶©өҘИХЖЪФЪ1998-01-01ҝӘКјөҪ1998-01-07ДЪөДЦө»тХЯ1998-01-04ҝӘКјөҪ1998-01-10ДЪөДЦөЈЁІ»°ьә¬ҝӘКјИХЖЪЈ©
ХвАпУГөДВЯјӯОҪҙКОӘЈәOR...ЖдКөТІҫНөИН¬УЪОТГЗЗ°ГжРҙөДIN
ө«КЗОТГЗХвАпФЩ·ЦОцТ»ПВЈ¬Дг»б·ўПЦХвБҪёцКұјд¶ОКЗЦШөюөД

ХвёцЦШёҙөДЗшјдЦөЈ¬Из№ыУГөҪЗ°ГжөДЦұҪУЛчТэІйХТЈ¬ФЪХв¶ОЗшјдЦ®ДЪөДЛСЛчіцАҙөД·¶О§ЦөҫНКЗЦШёҙөДЈ¬ЛщТФОӘБЛұЬГвХвЦЦОКМвЈ¬SQL ServerУЦТэИлБЛ“әПІўјдёф”ХвёцФЛЛг·ыЎЈ
ЖдКөЈ¬ҫӯ№эЙПГжөД·ЦОцЈ¬ОТГЗТСҫӯ·ЦОціцХвЦЦ¶ҜМ¬ЛчТэІйХТөДУЕИұөгБЛЈ¬УРКұәтОТГЗОӘБЛұЬГвХвЦЦёҙФУөДЦҙРРјЖ»®ЙъіЙЈ¬К№УГЧојтөҘөД·ҪКҪҫНКЗЦұҪУҙ«ЦөҪшИлУпҫдЦРЈЁөұИ»ХвАпРиТӘЦШұаТлЈ©Ј¬өұИ»ҙуІҝ·ЦөДЗйҝцОТГЗРҙөДіМРт¶јКЗЦ»¶ЁТеөДІОКэЈ¬И»әуҪшРРөДФЛЛгЎЈҝЙДЬҙшАҙөДВй·іҫНКЗЙПГжөДОКМвЈ¬өұИ»УРКұәтІОКэ¶аБЛЈ¬ОӘБЛәПІўјдёфЛщУҰУГөДЕЕРтҫНПыәДөДДЪҙжҫН»бФціӨЎЈФхГҙК№УГЈ¬ёщҫЭіЎҫ°ЧФјәЧГЗй·ЦОцЎЈ
¶юЎўЛчТэБӘәП
ЛщОҪөДЛчТэБӘәПЈ¬ҫНКЗёщҫЭҫНКЗёщҫЭЙёСЎМхјюөДІ»Н¬Ј¬Ір·ЦіЙІ»Н¬өДМхјюЈ¬ИҘЖҘЕдІ»Н¬өДЛчТэПоЎЈ
ҫЩёцАэЧУ
SELECT OrderID FROM ORDERSWHERE OrderDate BETWEEN '1998-01-01' AND '1998-01-07'OR ShippedDate BETWEEN '1998-01-01' AND '1998-01-07'
Хв¶ОҙъВлКЗІйСҜіц¶©өҘЦРөД¶©өҘИХЖЪФЪ1998Дк1ФВ1ИХөҪ1998Дк1ФВ7ИХөД»тХЯ·ў»хИХЖЪН¬СщФЪ1998Дк1ФВ1ИХөҪ1998Дк1ФВ7ИХөДЎЈ
ВЯјӯәЬјтөҘЈ¬ОТГЗЦӘөАФЪХвЦЦұнАпГжХвБҪёцЧЦ¶О¶јУРЛчТэПоЎЈЛщТФХвёцІйСҜФЪSQL ServerЦРҫНУРБЛБҪёцСЎФсЈә
1ЎўТ»ҙОРФөДАҙёцЛчТэЙЁГиёщҫЭЖҘЕдҪб№ыПоКдіцЈ¬ХвСщјтөҘУРР§Ј¬ө«КЗИз№ы¶©өҘұнКэҫЭБҝұИҪПҙуөД»°Ј¬РФДЬҫН»бәЬІоЈ¬ТтОӘҙуІҝ·ЦКэҫЭҫНёщұҫІ»КЗОТГЗПлТӘөДЈ¬»№ТӘАЛ·СКұјдИҘЙЁГиЎЈ
2ЎўҫНКЗНЁ№эБҪБРөДЛчТэЧЦ¶ОЦұҪУІйХТ»сИЎХвІҝ·ЦКэҫЭЈ¬ХвСщҝЙТФЦұҪУјхЙЩКэҫЭұнөДЙЁГиБҝЈ¬ө«КЗҙшАҙөДОКМвҫНКЗЈ¬Из№ы·ЦҝӘЙЁГиЈ¬УРТ»Іҝ·ЦКэҫЭҫНКЗЦШёҙөДЈәДЗР©Н¬КұФЪ1998Дк1ФВ1ИХөҪ1998Дк1ФВ7ИХөД¶©өҘЈ¬·ў»хИХЖЪТІФЪХв¶ОКұјдДЪЈ¬ТтОӘБҪёцЙЁГиПо¶ј°ьә¬Ј¬ЛщТФФЩКдіцөДКұәтРиТӘҪ«ХвІҝ·ЦЦШёҙКэҫЭИҘөфЎЈ
ОТГЗАҙҝҙSQL ServerИзәОСЎФс
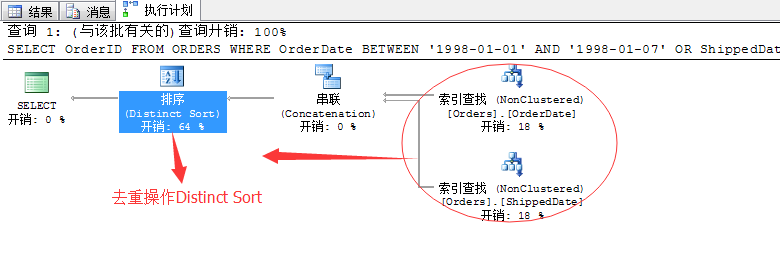
ҝҙАҙSQL Serverҫӯ№эЖА№АСЎФсБЛөЪ2ЦР·Ҫ·ЁЎЈө«КЗЙПГжөД·Ҫ·ЁТІІ»ҫЎНкГАЈ¬ІЙУГИҘЦШІЩЧчәД·СБЛ64%өДЧКФҙЎЈ
ЖдКөЈ¬ЙПГжөД·Ҫ·ЁЈ¬ОТГЗёщҫЭЙъіЙөДІйСҜјЖ»®ҝЙТФұдНЁөДК№УГТФПВВЯјӯЈ¬ЖдР§№ыәНЙПГжөДУпҫдКЗТ»СщөДЈ¬ІўЗТЙъіЙөДІйСҜјЖ»®ТІТ»Сщ
SELECT OrderID FROM ORDERSWHERE OrderDate BETWEEN '1998-01-01' AND '1998-01-07'UNION SELECT OrderID FROM ORDERSWHERE ShippedDate BETWEEN '1998-01-01' AND '1998-01-07'
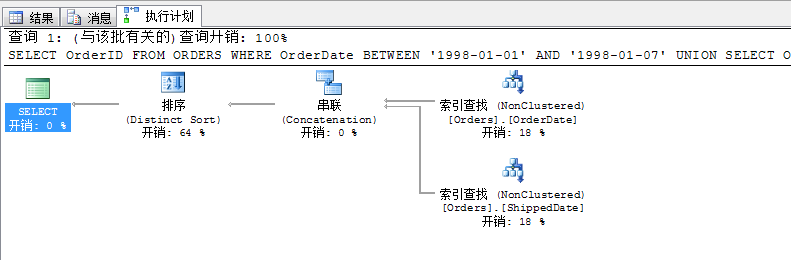
ОТГЗФЩАҙҝҙТ»ёцЛчТэБӘәПөДАэЧУ
SELECT OrderID FROM ORDERSWHERE OrderDate = '1998-01-01' OR ShippedDate = '1998-01-01'
ОТГЗҪ«ЙПГжөДBetween andІ»өИКҪЙёСЎМхјюёДіЙөИКҪЙёСЎМхјюЈ¬ОТГЗАҙҝҙТ»ПВХвСщРОіЙөДЦҙРРјЖ»®
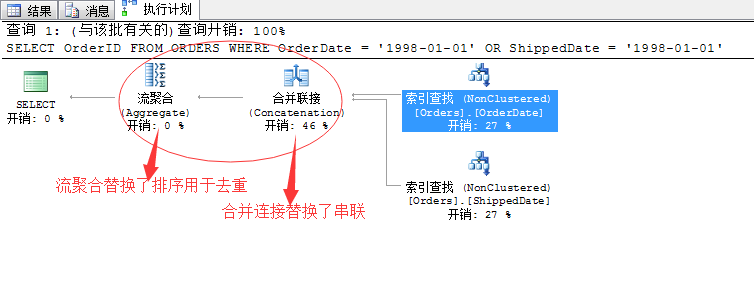
»щұҫПаН¬өДУпҫдЈ¬Ц»КЗОТГЗёДұдБЛІ»Н¬өДІйСҜМхјюЈ¬ө«КЗЙъіЙөДІйСҜјЖ»®»№КЗұд»ҜВщҙуөДЈ¬УРјёөгІ»Н¬Ц®ҙҰЈә
1ЎўЗ°ГжөДУГbetween...and өДЙёСЎМхјюЈ¬НЁ№эЛчТэІйХТ·ө»ШөДЦөҪшРРЧйәПКЗУГөДҙ®БӘөД·ҪКҪЈ¬ЛщОҪөДҙ®БӘҫНКЗБҪёцКэҫЭјҜЖҙҙХФЪТ»ЖрҫНРРЈ¬ОЮЛщОҪЛіРтБ¬ҪУКІГҙөДЎЈ
2ЎўЗ°ГжөДУГbetween...and өДЙёСЎМхјюЈ¬НЁ№эҙ®БӘЖҙҙХөДҪб№ыјҜИҘЦШөД·ҪКҪЈ¬КЗЕЕРтИҘЦШЈЁSort DistinctЈ©...ІўЗТәД·СБЛҙуБҝөДЧКФҙЎЈХвАпІЙУГБЛБчҫЫәПАҙёЙХвёцКВЈ¬»щұҫІ»ПыәД
ОТГЗАҙ·ЦОцТФПВІъЙъЧЕБҪөгІ»Н¬өДФӯТтУРДДР©Јә
КЧПИЎўХвАпёДұдБЛЙёСЎМхјюОӘөИКҪБ¬ҪУЈ¬ЛщНЁ№эЛчТэІйХТЛщІъЙъөДҪб№ыПоКЗЕЕРтөДЈ¬ІўЗТ°ҙХХОТГЗЛщТӘІйСҜөДOrderIDБРЕЕРтЈ¬ТтҙЛФЪБҪёцКэҫЭјҜҪшРР»гЧЬөДКұәтЈ¬ХэККәПәПІўБ¬ҪУөДМхјюЈЎРиТӘМбЗ°ЕЕРтЎЈЛщТФХвАпЧоУЕөД·ҪКҪҫНКЗІЙУГәПІўБ¬ҪУЈЎ
ДЗГҙЗ°ГжОТГЗУГbetween...and өДЙёСЎМхјюНЁ№эЛчТэІйХТ»сИЎөДҪб№ыПоТІКЗЕЕРтөДЈ¬ө«КЗХвАпЛьГ»УР°ҙХХOrderIDЕЕРтЈ¬ЛьКЗ°ҙХХOrderDate»тХЯShippedDateБРЕЕРтөДЈ¬¶шОТГЗөДҪб№ыКЗТӘOrderIDБРЈ¬ЛщТФХвАпөДЕЕРтКЗГ»УГөД......ЛщТФSQL ServerЦ»ДЬСЎФсТ»ёцҙ®БӘІЩЧчЈ¬Ҫ«Ҫб№ы»гҫЫөҪТ»ЖрЈ¬И»әуФЪЕЕРтБЛ......ОТПЈНыХвАпОТТСҫӯҪІГч°ЧБЛ...
ЖдҙОЎў№ШУЪИҘЦШІЩЧчЈ¬әБОЮТЙОКІЙУГБчҫЫәПЈЁAggregateЈ©ХвЦЦ·ҪКҪЧоәГЈ¬ПыәДДЪҙжЙЩЈ¬ЛЩ¶ИУЦҝм...ө«КЗЗ°МбКЗТӘМбЗ°ЕЕРт...З°ГжСЎУГөДЕЕРтИҘЦШЈЁSort DistinctЈ©ҙҝКфОЮДОЦ®ҫЩ...
ЧЬҪбПВЈәОТГЗФЪРҙУпҫдөДКұәтДЬИ·¶ЁОӘөИКҪБ¬ҪУЈ¬ЧоәГІЙУГөИКҪБ¬ҪУЎЈ»№УРҫНКЗИз№ыДЬИ·¶ЁКдіцМхјюөДЧоәГДЬРҙИлЈ¬ұЬГв¶аУаөДКйЗ©ІйХТЈ¬»№УРНт¶сөДSELEECT *....
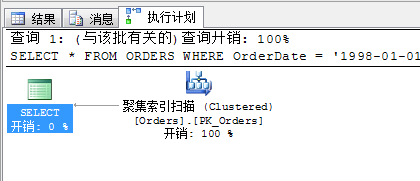
Из№ыРҙБЛНт¶сөДSELECT *...ДЗГҙДгЛщРҙөДУпҫд»щұҫЙПҫНҝЙТФәН·ЗҫЫјҜЛчТэІйХТёжұрБЛ....¶Ҙ¶аҫНКЗҫЫјҜЛчТэЙЁГи»тХЯRIDІйХТ...
ітітТФПВУпҫд
SELECT * FROM ORDERSWHERE OrderDate = '1998-01-01' OR ShippedDate = '1998-01-01'
ЧоәуЈ¬·оЙПТ»ёцANDөДТ»ёцБ¬ҪУОҪҙКөДІЩЧч·ҪКҪЈ¬Хвёц·ҪКҪұ»іЖОӘЈәЛчТэҪ»ІжЈ¬ТвЛјҫНКЗЛөИз№ыБҪёц»т¶аёцЙёСЎМхјюИз№ыІЙУГөДЛчТэКЗҪ»ІжҪшРРөДЈ¬ДЗГҙК№УГТ»ёцҫНҝЙТФҪшРРІйСҜЎЈ
АҙҝҙёцУпҫдҫНГч°ЧБЛ
SELECT OrderID FROM ORDERSWHERE OrderDate = '1998-01-01' AND ShippedDate = '1998-03-05'
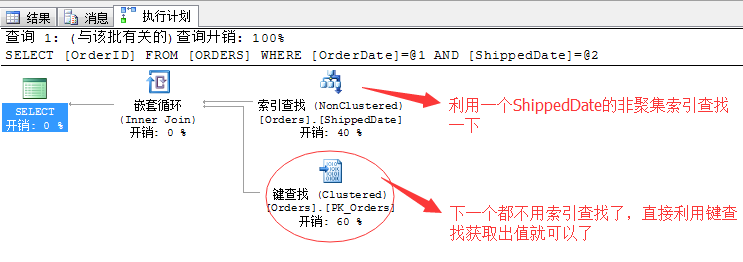
ХвАпОТГЗІЙУГБЛөДОҪҙКБ¬ҪУ·ҪКҪОӘANDЈ¬ЛщТФФЪКөјКЦҙРРөДКұәтЈ¬ЛдИ»БҪБР¶јҙжФЪ·ЗҫЫјҜЛчТэЈ¬АнВЫ¶јҝЙТФК№УГЈ¬ө«КЗОТГЗЦ»ТӘСЎТ»ёцЧоУЕөДЛчТэҪшРРІйХТЈ¬БнНвТ»ёцЦұҪУК№УГКйЗ©ІйХТіцАҙҫНҝЙТФЎЈКЎИҘБЛЗ°ГжҪйЙЬөДёчЦЦЙсВнЕЕРтИҘЦШ....БчҫЫәПИҘЦШ....өИөИІ»ИЛРФөДІЩЧчЎЈ
ҝҙАҙANDБ¬ҪУ·ыКЗТ»ёцәЬЛ§өДФЛЛг·ы...ЛщТФәЬ¶аКұәтОТГЗФЪіўКФРҙORөДЗйҝцПВЈ¬І»Из»»ёцЛјВ·ёДУГANDёьёЯР§ЎЈ
ІОҝјОДПЧ
- ОўИнБӘ»ъҙФКйВЯјӯФЛЛг·ыәНОпАнФЛЛг·ыТэУГ
- ІОХХКйј®Ў¶SQL.Server.2005.јјКхДЪД»Ў·ПөБР
ҪбУп
ҙЛЖӘОДХВЦчТӘҪйЙЬБЛЛчТэФЛЛгөДТ»Р©·ҪКҪЈ¬ЦчТӘКЗГиКцБЛОТГЗЖҪіЈФЪРҙУпҫдөДКұәтЛщУҰУГөД·ҪКҪЈ¬ІўЗТҫЩБЛјёёцАэЧУЈ¬ЛгЧчЕЧЧ©ТэУс°ЙЈ¬ЖдКөОТГЗЖҪіЈЛщРҙөДУпҫдЦРОЮ·ЗТІҫНұҫЖӘОДХВЦРҪйЙЬөДёчЦЦ·ҪКҪөДёьёДЈ¬ЖҙҙХЎЈ¶шЗТёщҫЭҙЛЈ¬ОТГЗёГФхСщҪЁБўЛчТэТІЧчОӘТ»ёцЦёөјПоЎЈ
ПВТ»ЖӘОТГЗҪйЙЬЧУІйСҜТ»ПөБРөДДЪИЭЈ¬УРРЛИӨҝЙМбЗ°№ШЧўЈ¬№ШУЪSQL ServerРФДЬөчУЕөДДЪИЭЙжј°ГжәЬ№гЈ¬әуРшОДХВЦРТАҙОХ№ҝӘ·ЦОцЎЈ
УРОКМвҝЙТФБфСФ»тХЯЛҪРЕЈ¬ЛжКұ№§әтУРРЛИӨөДНҜР¬јУИлSQL SERVERөДЙоИлСРҫҝЎЈ№ІН¬С§П°Ј¬Т»ЖрҪшІҪЎЈ
ОДХВЧоәуёшіцЙПјёЖӘөДБ¬ҪУЈ¬ҝҙАҙУРұШТӘХыАнТ»ЖӘДҝВјБЛ.....
SQL ServerөчУЕПөБР»щҙЎЖӘЈЁіЈУГФЛЛг·ыЧЬҪбЈ©
SQL ServerөчУЕПөБР»щҙЎЖӘЈЁБӘәПФЛЛг·ыЧЬҪбЈ©
SQL ServerөчУЕПөБР»щҙЎЖӘЈЁІўРРФЛЛгЧЬҪбЈ©
SQL ServerөчУЕПөБР»щҙЎЖӘЈЁІўРРФЛЛгЧЬҪбЖӘ¶юЈ©
Из№ыДъҝҙБЛұҫЖӘІ©ҝН,ҫхөГ¶ФДъУРЛщКХ»сЈ¬ЗлІ»ТӘБЯШДДъөД“НЖјц”ЎЈ
- 4ВҘwy123
- ¶Ҙ°ЎЈ¬ҝҙАҙЦ»ТӘКЗУРorІйСҜМхјюөДЈ¬ҝУ¶а¶а°ЎЈ¬Ј¬ТФЗ°ТІЦӘөАТ»Р©ЦҙРРјЖ»®Ј¬БЛҪвөДәЬҙЦЈ¬ВҘЦчХвТ»ПөБРөДПё»Ҝ¶аБЛ
- Re: ЦёјвБчМК
- @wy123Ј¬¶аР»НЖјц...РЦөЬЖАВЫ№»ј°КұөД...
- 3ВҘuoou
- ¶аР»ВҘЦч·ЦПнЈ¬С§П°БЛЈ¬І»№эОТТІёшҙујТ·ЦПнТ»ёцГв·СЖҪМЁ°ЙЈ¬НјБй»ъЖчИЛЈ¬ҫЭЛөКЗЦРОДУпҫіПВЦЗДЬ¶ИЧоёЯөД»ъЖчИЛЈ¬ИҘ№ЩНшЙПМеСйБЛПВІъЖ·Ј¬ЧцөДНҰІ»ҙнөДЈ¬№©ДЫҪУҪь500ЦЦЈ¬ЛжТвУГЈ¬ЧФјәҙоҪЁБЛёц»ъЖчИЛНжНжЈ¬НҰ¶әөДЈ¬Ц»ТӘөјИлЧФјәөДЦӘК¶ҝвҫНДЬ°С»ъЖчИЛұдіЙДгПлТӘіЙОӘөДөчөчЈ¬»№ҝЙТФЧцЦЗДЬҝН·юЈ¬ҪУИлјтөҘЈ¬·ЗҝӘ·ўХЯ¶ј»бЈ¬»№УРёзГЗҪиЦъЖҪМЁЧцБЛёцТфАЦНЖјцАаөДІъЖ·ВфБЛ100НтЈ¬№»ЕЈөД°ЙЈ¬УРПл·ЁөДёПҪфКФКФ°Йhttp://www.tuling123.com/openapi/cloud/proexp.jsp
- Re: ЦёјвБчМК
- @uoouЈ¬ёзГЗКЗАҙЧц№гёжөД°Й...
- 2ВҘsuperunusa
- ORТІКЗГ»УР°м·ЁЎЈЈ¬Из№ыORМ«¶аҫНПлПлҝЙІ»ҝЙТФ·ЕөҪұнұдБҝ»тХЯБЩКұұнАп°ЙЎЈДЗСщ»бәГөгЎЈ
- Re: ЦёјвБчМК
- @superunusaЈ¬Ј¬аЕЈ¬Ҫ«OR№ШјьЧЦРОіЙөДҪб№ыјҜ·ЕИлБЩКұұнЦРЈ¬ХвАпЙФНЖјцНЖјцБЩКұұнЈ¬ҙуІҝ·ЦУГУлЧУІйСҜЦР...БЩКұұнёьәГУГөгЎЈ
- 1ВҘ20121221
- Хв№гёжЧцөДЎЈ
- Re: ЦёјвБчМК
- @20121221Ј¬әЗәЗ..№гёжМщ...