1��case��end �������值��
case������值���൱��c#�е�switch case
ע�⣺case�����������������when���������值����Ϊ������
-----------------case--end---��ṹ---------------------select name , --ע�ⶺ�� case level --case������� when 1 then '�ǻ�' when 2 then '��Ϻ' when 3 then'����' end as'ͷ��'from [user]
2��case��end ������
case ������值���൱��c#�е�if��else if��else��.
ע�⣺case������
------------------case---end--------------------------------select studentId, case when english between 80 and 90 then '��' when english between 60 and 79 then '��' else '��' end from Score------------------case---end--------------------------------select studentId, case when english >=80 then '��' when english >=60 then '��' else '��' end from Score-----------------------------------------------------select *, case when english>=60 and math >=60 then '��格' else '����格' endfrom Score
3��if��eles
IF(��������ʽ) BEGIN --�൱��C#���{ ���1 ���� END --�൱��C#���}ELSE BEGIN ���1 ���� END--����ƽ����������������ƽ����������������ɼ���ߵ�����ѧ���ijɼ������������������ѧ��declare @avg int --�������select @avg= AVG(english) from Score --Ϊ������值select 'ƽ���ɼ�'+CONVERT(varchar,@avg) --��ӡ������值 if @avg<60 begin select 'ǰ����' select top 3 * from Score order by english desc end else begin select '������' select top 3 * from Score order by english end4��whileѭ��
WHILE(��������ʽ) BEGIN --�൱��C#���{ ��� ���� BREAK END --�൱��C#���}--�������格���˳�������(�����������)�����ÿ�������ӷ�select * from Scoredeclare @conut int,@failcount int,@i int=0 --�������select @conut =COUNT(*) from Score --ͳ��������select @failcount =COUNT(*) from Score where english<100 --ͳ��δ��格������while (@failcount>@conut/2) begin update Score set english=english+1 select @failcount=COUNT(*) from Score where english<100 set @[email protected]+1 endselect @iupdate Score set english=100 where english >1005������
ʹ����������߲�ѯЧ�ʣ���������Ҳ��ռ�ݿռ�ģ��������ӡ����¡�ɾ�����ݵ�ʱ��Ҳ��Ҫͬ��������������˻ή��Insert��Update��Delete���ٶȡ�ֻ�ھ����������ֶ���(Where)����������
1���ۼ�����������Ŀ¼�еĺ�Ŀ¼�ж�Ӧ�����ݶ�����˳��ġ�
2���Ǿۼ�����������Ŀ¼��˳�洢��������û��˳��ġ�
--�����Ǿۼ�����CREATE NONCLUSTERED INDEX [IX_Student_sNo] ON student( [sNo] ASC)
6���Ӳ�ѯ
��һ����ѯ�����Ϊһ�������������SQL���ʹ�ã�����ʹ����ͨ�ı�һ����������������IJ�ѯ��䱻��Ϊ�Ӳ�ѯ�����п���ʹ�ñ��ĵط�����������ʹ���Ӳ�ѯ�����档
select * from (select * from student where sAge<30) as t --����ѯ���ӱ������б���where t.sSex ='��' --���ӱ��е���ɸѡ
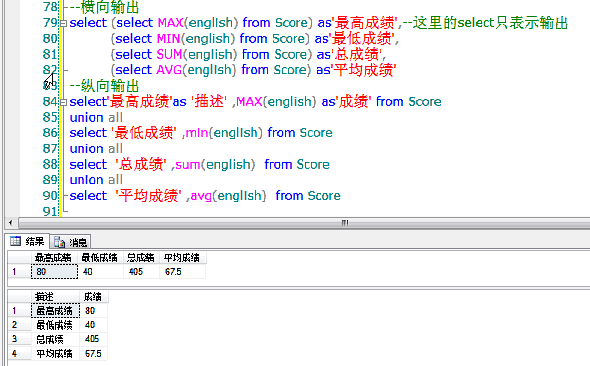
ת��Ϊ��λС����CONVERT(numeric(10,2), AVG(english))
ֻ�з����ҽ�����һ�С�һ�����ݵ��Ӳ�ѯ���ܵ��ɵ�值�Ӳ�ѯ��
select 'ƽ���ɼ�', (select AVG(english) from Score) --���Գɹ�ִ��select '����', (select sName from student) --������Ϊ��������ֻ��һ�У����ӱ��������ж���select * from student where sClassId in(select cid from Class where cName IN('��һһ��','�߶�һ��')) --�Ӳ�ѯ�ж�值ʱʹ��in7����ҳ
--��ҳ1select top 3 * from student where [sId] not in (select top (3*(4-1)) [sid] from student)--4��ʾҳ��select *, row_number() over(order by [sage] desc ) from student-- row_number() over (order by..)��ȡ�к�--��ҳ2select * from (select *, row_number() over(order by [sid] desc ) as num from student)as twhere num between (Y-1)*T+1 and Y*Torder by [sid] desc
--��ҳ3select * from (select ROW_NUMBER() over( order by [UnitPrice] asc) as num,* from [Books] where [publisherid]=1 )as t where t.num between 1 and 20 --Ҫ��ѯ�Ŀ�ʼ�����ͽ�������
8������
select sName,sAge, case when english <60 then '����格' when english IS null then 'ȱ��' else CONVERT(nvarchar, english) end as'Ӣ��ɼ�'from student as sleft join Score as c on s.sid =c.sid������ inner join...on... ��ѯ����on�������������� ������ ������ left join...on... �Ȳ������е��������� ��ʹ��on��������������ݹ��� ������ right join...on... �Ȳ���ұ��е��������� ��ʹ��on��������������ݹ��� ȫ���� full join ...on... ��*���������� cross join û��on ��һ������ÿһ�кͺ������ÿһ�н������� û�����������������ӵĻ���
9.��ͼ
�ŵ㣺
- ɸѡ���е���
- ��ֹδ�����ɵ��û�������������
- �������ݿ�ĸ��ӳ̶�
������ͼ
create view v_Demoasselect ......
10���ֲ�����
---------------------------------�ֲ�����----------------------------��������:ʹ��declare�ؼ��֣�[email protected]��@ֱ�����ӱ�����,�м�û�п�格������ָ�����������ͣ�ͬʱ���������������ͬ���͵ı�����declare @name nvarchar(30) ,@age int--������值��--1��ʹ��set ��������值,ֻ�ܸ�һ��������值set @age=18set @name ='Tianjia'select @age,@name --���������值--2��ʹ��select ����ͬʱΪ���������值select @age=19,@name='Laoniu'--3���ڲ�ѯ�����Ϊ������值declare @sum int =18 --Ϊ��������值select @sum= SUM(english) from Score --��ѯ����и�值select @sum --�������值--4��������Ϊ����ʹ��declare @sname nvarchar(10)='����' declare @sage intselect @sage=sage from student where [email protected]select @sage--5��ʹ��print�������值��һ��ֻ�����һ��������值,���Ϊ�ı���ʽprint @sage
11��ȫ�ֱ���
--------------------------ȫ�ֱ�����ϵͳ������----------------------------------select * from student0 select @@error --���һ��T-SQL����Ĵ����select @@max_connections--��ȡ������ͬʱ���ӵ������Ŀselect @@identity --�������һ�β���ı��
12������
����ͬ������
ָ���ʲ����ܸ������ݿ��и����������һ������ִ�е�Ԫ(unit)�CҲ�����ɶ��sql�����ɣ�������Ϊһ������ִ��
��Щsql�����Ϊһ������һ����ϵͳ�ύ��Ҫô��ִ�С�Ҫô����ִ��
����裺
- ��ʼ����BEGIN TRANSACTION
- �����ύ��COMMIT TRANSACTION
- ����ع���ROLLBACK TRANSACTION
�ж�ij�����ִ���Ƿ������
ȫ�ֱ���@@ERROR��
@@ERRORֻ���жϵ�ǰһ��T-SQL���ִ���Ƿ��д���Ϊ���ж�����������T-SQL����Ƿ��д���������Ҫ�Դ�������ۼƣ�
---------------------------ģ��ת��----------------------------declare @sumError int=0 --��������begin tranupdate bank set balance=balance-1000 where cId='0001'set @[email protected]+@@error update bank set balance=balance+1000 where cId='0002'set @[email protected]+@@errorif (@sumError=0)commit tran --�ύ�ɹ�,�ύ����else rollback tran --�ύʧ��,�ع�����
13���洢����
�洢���̡��������ݿ������з���(����)
��C#��ķ���һ�����ɴ洢������/�洢���̲������/�����з��ؽ����
ǰ��ѧ��if else/while/����/insert/select �ȣ��������ڴ洢������ʹ��
�ŵ㣺
- ִ���ٶȸ��� �C �����ݿ��б���Ĵ洢������䶼�DZ������
- ����ģ�黯������� �C ��似�����ĸ���
- ���ϵͳ��ȫ�� �C ��ֹSQLע��
- ����������ͨ�� �C ֻҪ���� �洢���̵�����
ϵͳ�洢����
��ϵͳ���壬�����master���ݿ���
�����ԡ�sp_����ͷ��xp_����ͷ
�����洢���̣�
����洢���̵�� CREATE PROC[EDURE] �洢������ @����1 �������� = Ĭ��值 OUTPUT, @����n �������� = Ĭ��值 OUTPUT AS SQL������˵����������ѡ������Ϊ���������������� �������������Ĭ��值EXEC ������ [����]----------------------��--------------------------if exists (select * from sys.objects where name='usp_GroupMainlist1')drop proc usp_GroupMainlist1gocreate proc usp_GroupMainlist1 @pageIndex int, --ҳ�� @pageSize int, --���� @pageCount int output--���������ҳas declare @count int --������������ select @count =count(*) from [mainlist] --��ȡ�˱��������� set @pageCount=ceiling(@[email protected]) select * from (select *,row_number() over(order by [date of booking] desc) as 'num' from [mainlist]) as t where num between(@pageSize*(@pageIndex-1)+1) and @[email protected] order by [date of booking] desc---------------------------------------------------------------------------------------------���� declare @page intexec usp_GroupMainlist1 1,100,@page outputselect @page
14�����ú���
1��ISNULL(expression,value) ���expression��Ϊnull����expression����ʽ��值������value��值
2���ۺϺ���
avg() -- ƽ��值 ͳ��ʱע��null���ᱻͳ�ƣ���Ҫ����isnull(������0)sum() -- ���count() -- ������ min() -- ����С值max() -- �����值
3���ַ�����������
LEN() --�����ַ������� LOWER() --תСд UPPER () --��д LTRIM() --�ַ������Ŀ�格ȥ�� RTRIM () --�ַ����Ҳ�Ŀ�格ȥ�� LTRIM(RTRIM(' bb ')) LEFT()��RIGHT() -- ��ȡȡ�ַ��� SUBSTRING(string,start_position,length) -- ����stringΪ���ַ�����start_positionΪ���ַ��������ַ����е���ʼλ�ã���1��ʼ����lengthΪ���ַ�������ȡ�SELECT SUBSTRING('abcdef111',2,3) REPLACE(string,oldstr,newstr)Convert(decimal(18,2),num)--������λС��4��������غ���
GETDATE() --ȡ�õ�ǰ����ʱ�� DATEADD (datepart , number, date )--���������Ժ�����ڡ�����dateΪ����������ڣ�����numberΪ����������datepartΪ������λ����ѡ值����ע��DATEADD(DAY, 3,date)Ϊ��������date��3�������ڣ���DATEADD(MONTH ,-8,date)Ϊ��������date��8����֮ǰ������ DATEDIFF ( datepart , startdate , enddate ) --������������֮��IJ� datepart Ϊ������λ����ȡ值�ο�DateAdd��-- ��ȡ���ڵ�ijһ���� �� DATEPART (datepart,date)--����һ�����ڵ��ض����� ���� DATENAME(datepart,date)--����������ָ������ �ַ��� YEAR() MONTH() DAY()
15��sql���ִ��˳��
5>��Select 5-1>ѡ����,5-2>distinct,5-3>top 1>��From �� 2>��Where ���� 3>��Group by �� 4>��Having ɸѡ���� 6>��Order by ��
��Ȩ��������ӭת�أ�ϣ������ת�ص�ͬʱ������ԭ�ĵ�ַ��лл���