为了开发时的方便和不时之需;研究下不需要SQL Server,直接打开MDF数据库文件的软件;
1 SQL MDF Viewer
这是一个好工具;偶不得不说;不错;没有SQL Server的情况下,成功打开了MDF文件;
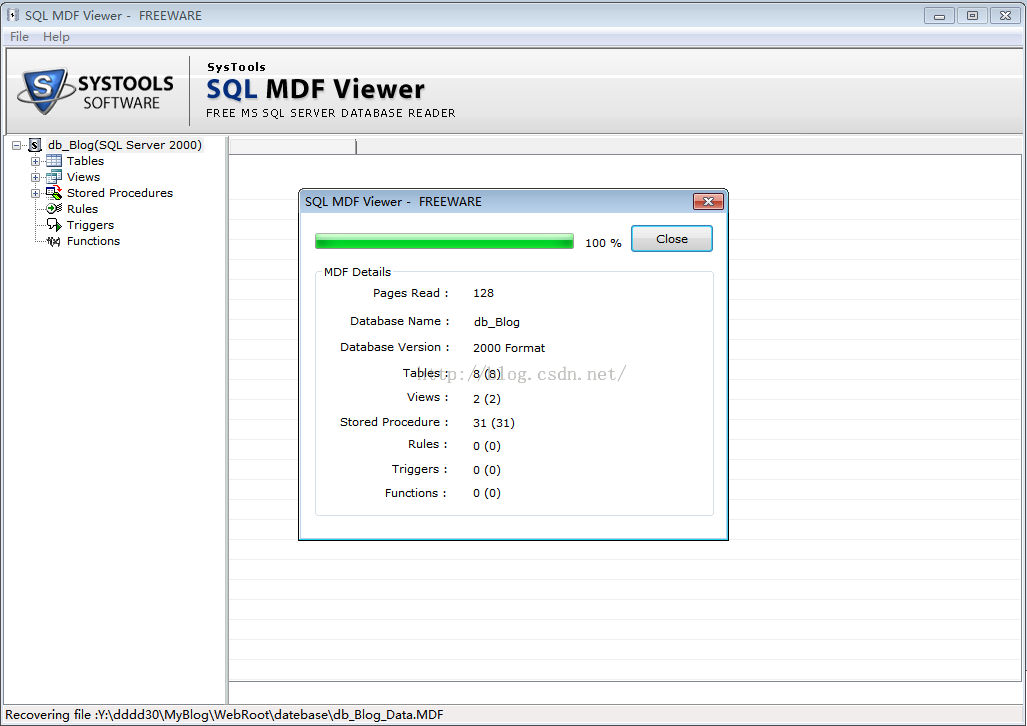

可以显示记录和数据库结构;不过看不到存储过程的代码,视图的代码能看到;
2 网际数据库浏览器
先安装,
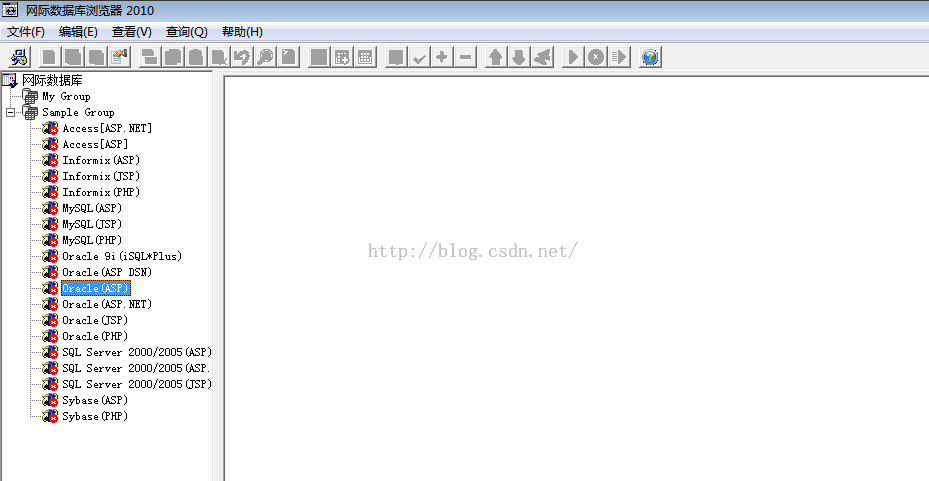
界面;
登录要用户名密码;那么就是需要Sql Server 运行才能打开MDF 文件了;
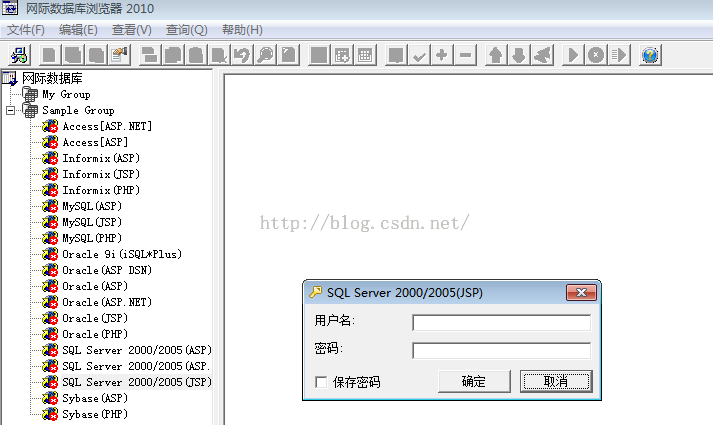
如下图,原来此软件是用不同开发语言和数据库的连接字符串语法去连接数据库然后查询数据,可连多种语言和数据库的搭配;

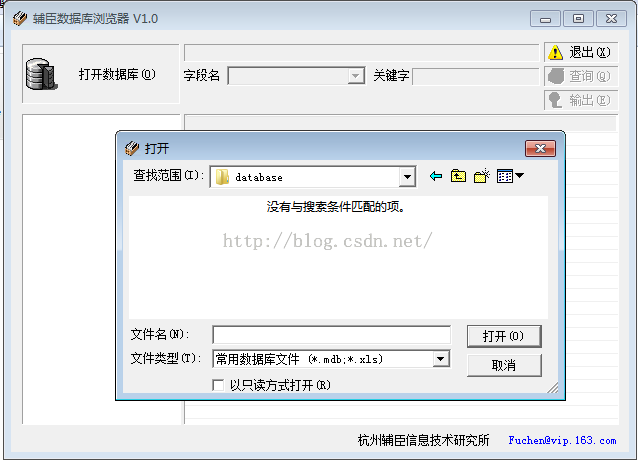
3 辅臣数据库浏览器
介绍说可打开MDF,下载后发现原来是可打开MDB和XLS,羊头狗肉啊;
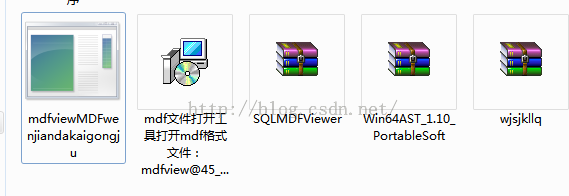
4 这个不厚道
又下了个如下图最左的软件;谁知运行起来后不是MDF文件查看工具,而是自动安装了一个叫风行的东西;真是不厚道;
5 恢复/修复SQL Server的MDF文件
下面将主要讨论一下后者的备份与恢复。本文假定您 能熟练使用SQL Server Enterprise Manager(SQL Server企业管理器)和SQL Server Quwey Analyser(SQL Server查询分析器)
..首先:如果备份的数据库有两个文件,分别是.LDF 和 .MDF,打开企业管理器,在实例上右击---所有任务--附加数据库,然后选择那个.MDF文件,就可以了。
或者在查询分析器中输入:
复制代码 代码如下:sp_attach_db "数据库名称","路径\文件名.ldf","路径\文件名.MDF"
SQL Server数据库备份有两种方式,一种是使用BACKUP DATABASE将数据库文件备份出去,另外一种就是直接拷贝数据库文件mdf和日志文件ldf的方式。下面将主要讨论一下后者的备份与恢复。本文假定您 能熟练使用SQL Server Enterprise Manager(SQL Server企业管理器)和SQL Server Quwey Analyser(SQL Server查询分析器)。
1.正常的备份、恢复方式0
正常方式下,我们要备份一个数据库,首先要先将该数据库从运行的数据服务器中断开,或者停掉整个数据库服务器,然后复制文件。
卸下数据库的命令:Sp_detach_db 数据库名
复制代码 代码如下:
连接数据库的命令:Sp_attach_db或者sp_attach_single_file_db
s_attach_db [@dbname =] 'dbname',
[@filename1 =] 'filename_n' [,...16]
sp_attach_single_file_db [@dbname =]
'dbname', [@physname =] 'physical_name'
使用此方法可以正确恢复SQL Sever7.0和SQL Server 2000的数据库文件,要点是备份的时候一定要将mdf和ldf两个文件都备份下来,mdf文件是数据库数据文件,ldf是数据库日志文件。
例子:
假设数据库为test,其数据文件为test_data.mdf,日志文件为test_log.ldf。下面我们讨论一下如何备份、恢复该数据库。
代码如下:
卸下数据库:sp_detach_db 'test'
连接数据库:sp_attach_db 'test','
C:\Program Files\Microsoft SQL Server\MSSQL
\Data\test_data.mdf','C:\Program Files
\Microsoft SQL Server\MSSQL\Data\test_log.ldf'
sp_attach_single_file_db 'test','
C:\Program Files\Microsoft SQL Server\MSSQL
\Data\test_data.mdf'
2.只有mdf文件的恢复技术
由于种种原因,我们如果当时仅仅备份了mdf文件,那么恢复起来就是一件很麻烦的事情了。
如果您的mdf文件是当前数据库产生的,那么很侥幸,也许你使用sp_attach_db或者sp_attach_single_file_db可以恢复数据库,但是会出现类似下面的提示信息:
设备激活错误。
代码如下:
物理文件名 'C:\Program Files\Microsoft SQL Server
\MSSQL\data\test_Log.LDF' 可能有误。
已创建名为 'C:\Program Files\Microsoft SQL Server
\MSSQL\Data\test_log.LDF' 的新日志文件。
但是,如果您的数据库文件是从其他计算机上复制过来的,那么很不幸,也许上述办法就行不通了。你也许会得到类似下面的错误信息:
代码如下:
服务器: 消息 1813,级别 16,状态 2,行 1
服务器: 消息 1813,级别 16,状态 2,行 1未能打开新数据库 'test'。CREATE DATABASE 将终止。
设备激活错误。物理文件名 'd:\test_log.LDF' 可能有误。
怎么办呢?别着急,下面我们举例说明恢复办法。
A.我们使用默认方式建立一个供恢复使用的数据库(如test)。可以在SQL Server Enterprise Manager里面建立。
B.停掉数据库服务器。
C.将刚才生成的数据库的日志文件test_log.ldf删除,用要恢复的数据库mdf文件覆盖刚才生成的数据库数据文件test_data.mdf。
D.启动数据库服务器。此时会看到数据库test的状态为“置疑”。这时候不能对此数据库进行任何操作。
E.设置数据库允许直接操作系统表。此操作可以在SQL Server Enterprise Manager里面选择数据库服务器,按右键,选择“属性”,在“服务器设置”页面中将“允许对系统目录直接修改”一项选中。也可以使用如下语句来实现。
F.设置test为紧急修复模式
代码如下:
update sysdatabases set status=-32768
where dbid=DB_ID('test')
此时可以在SQL Server Enterprise Manager里面看到该数据库处于“只读\置疑\脱机\紧急模式”可以看到数据库里面的表,但是仅仅有系统表
G.下面执行真正的恢复操作,重建数据库日志文件:
代码如下:
dbcc rebuild_log('test','C:\Program Files\Microsoft
SQL Server\MSSQL\Data\test_log.ldf')
执行过程中,如果遇到下列提示信息:
服务器: 消息 5030,级别 16,状态 1,行 1
未能排它地锁定数据库以执行该操作。
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
说明您的其他程序正在使用该数据库,如果刚才您在F步骤中使用SQL Server Enterprise Manager打开了test库的系统表,那么退出SQL Server Enterprise Manager就可以了。
正确执行完成的提示应该类似于:
警告: 数据库 'test' 的日志已重建。已失去事务的一致性。应运行 DBCC CHECKDB 以验证物理一致性。将必须重置数据库选项,并且可能需要删除多余的日志文件。
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
此时打开在SQL Server Enterprise Manager里面会看到数据库的状态为“只供DBO使用”。此时可以访问数据库里面的用户表了。
H.验证数据库一致性(可省略)
dbcc checkdb('test')
一般执行结果如下:
CHECKDB 发现了 0 个分配错误和 0 个一致性错误(在数据库 'test' 中)。
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
I.设置数据库为正常状态
代码如下:sp_dboption 'test','dbo use only','false'
如果没有出错,那么恭喜,现在就可以正常的使用恢复后的数据库啦。
J.最后一步,我们要将步骤E中设置的“允许对系统目录直接修改”一项恢复。
6 SQLserver数据文件(MDF)的页面文件头结构剖析
先执行一下以下SQL语句,我的测试环境为SQL2005
dbcc traceon(3604)
go
dbcc page(master,1,0,2)
可以看到MDF文件的一些物理结构信息,其中包括重要的头96个字节。也就是第一个页面的文件头。
........
PAGE HEADER:
Page @0x03FA0000
m_pageId = (1:0) m_headerVersion = 1 m_type = 15
m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x8
m_objId (AllocUnitId.idObj) = 99 m_indexId (AllocUnitId.idInd) = 0 Metadata: AllocUnitId = 6488064
Metadata: PartitionId = 0 Metadata: IndexId = 0 Metadata: ObjectId = 99
m_prevPage = (0:0) m_nextPage = (0:0) pminlen = 0
m_slotCnt = 1 m_freeCnt = 7937 m_freeData = 3059
m_reservedCnt = 0 m_lsn = (149:448:1) m_xactReserved = 0
m_xdesId = (0:0) m_ghostRecCnt = 0 m_tornBits = -1073741694
........
DATA:
Memory Dump @0x62FEC000
62FEC000: 010f0000 08000000 00000000 00000000 ?................
62FEC010: 00000000 00000100 63000000 011ff30b ?........c.......
62FEC020: 00000000 01000000 95000000 c0010000 ?................
62FEC030: 01000000 00000000 00000000 820000c0 ?................
62FEC040: 00000000 00000000 00000000 00000000 ?................
62FEC050: 00000000 00000000 00000000 00000000 ?................
以上蓝色的文字就是文件头的一些信息。如果这些信息损坏将会造成严重的后果。
经过简单的逐个字节分析,中间借助了windows计算器和c#的BitConverter.GetBytes函数。得出了如下文件结构图,其中每行4个字节,一共分析了文件头的前64个字节。
00:0F m_headerVersionm_type m_typeFlagBitsm_level
m_flagBits m_indexId
m_prevPage(2)
m_prevPage(1) pminlen
10:1F m_nextPage(2)
m_nextPage(1) m_slotCnt
AllocUnitId.idObj
m_freeCnt m_freeData
20:2F m_pageId(2)
m_pageId(1) m_reservedCnt
m_lsn(1)
m_lsn(2)
30:3F m_lsn(3)m_xactReserved
m_xdesId(2)
m_xdesId(1) m_ghostRecCnt
m_tornBits
在数据库的头96个字节中第0x40开始直道0x5F应该都是0。
我发现只有测试页的m_pageId 的冒号前面的数字不为1时才在0x40到0x5f写入数据。但是具体代表什么还没有看出来。
姑且认为数据库第一个页面的0x00-0x3f就如上图所示,0x40-0x5f都为0(不正确的话请纠正一下)
这张图有什么用呢,如果你理解了上述参数的意义,用二进制编辑器打开一个头文件损坏的mdf文件就有可能恢复这个已经损坏的数据库。
偶不是dba也不是专业恢复数据的,只是个普通的开发人员,怎么恢复还请有经验人士补充一下。
有情提醒,这些东西非常危险,请不要随意测试,最好找一个没用的数据库来研究。
参数的意义
m_pageId
This identifies the file number the page is part of and the position within the file. (1:143) means page 143 in file 1.
m_headerVersion
This is the page header version. Since version 7.0 this value has always been 1.
m_typea
This is the page type. The values you're likely to see are:
1 - data page. This holds data records in a heap or clustered index leaf-level.
2 - index page. This holds index records in the upper levels of a clustered index and all levels of non-clustered indexes.
3 - text mix page. A text page that holds small chunks of LOB values plus internal parts of text tree. These can be shared between LOB values in the same partition of an index or heap.
4 - text tree page. A text page that holds large chunks of LOB values from a single column value.
7 - sort page. A page that stores intermediate results during a sort operation.
8 - GAM page. Holds global allocation information about extents in a GAM interval (every data file is split into 4GB chunks - the number of extents that can be represented in a bitmap on a single database page). Basically whether an extent is allocated or not. GAM = Global Allocation Map. The first one is page 2 in each file. More on these in a later post.
9 - SGAM page. Holds global allocation information about extents in a GAM interval. Basically whether an extent is available for allocating mixed-pages. SGAM = Shared GAM. the first one is page 3 in each file. More on these in a later post.
10 - IAM page. Holds allocation information about which extents within a GAM interval are allocated to an index or allocation unit, in SQL Server 2000 and 2005 respectively. IAM = Index Allocation Map. More on these in a later post.
11 - PFS page. Holds allocation and free space information about pages within a PFS interval (every data file is also split into approx 64MB chunks - the number of pages that can be represented in a byte-map on a single database page. PFS = Page Free Space. The first one is page 1 in each file. More on these in a later post.
13 - boot page. Holds information about the database. There's only one of these in the database. It's page 9 in file 1.
15 - file header page. Holds information about the file. There's one per file and it's page 0 in the file.
16 - diff map page. Holds information about which extents in a GAM interval have changed since the last full or differential backup. The first one is page 6 in each file.
17 - ML map page. Holds information about which extents in a GAM interval have changed while in bulk-logged mode since the last backup. This is what allows you to switch to bulk-logged mode for bulk-loads and index rebuilds without worrying about breaking a backup chain. The first one is page 7 in each file.
m_typeFlagBits
This is mostly unused. For data and index pages it will always be 4. For all other pages it will always be 0 - except PFS pages. If a PFS page has m_typeFlagBits of 1, that means that at least one of the pages in the PFS interval mapped by the PFS page has at least one ghost record.
m_level
This is the level that the page is part of in the b-tree.
Levels are numbered from 0 at the leaf-level and increase to the single-page root level (i.e. the top of the b-tree).
In SQL Server 2000, the leaf level of a clustered index (with data pages) was level 0, and the next level up (with index pages) was also level 0. The level then increased to the root. So to determine whether a page was truly at the leaf level in SQL Server 2000, you need to look at the m_type as well as the m_level.
For all page types apart from index pages, the level is always 0.
m_flagBits
This stores a number of different flags that describe the page. For example, 0x200 means that the page has a page checksum on it (as our example page does) and 0x100 means the page has torn-page protection on it.
Some bits are no longer used in SQL Server 2005.
m_objId
m_indexId
In SQL Server 2000, these identified the actual relational object and index IDs to which the page is allocated. In SQL Server 2005 this is no longer the case. The allocation metadata totally changed so these instead identify what's called the allocation unit that the page belongs to (I'll do another post that describes these later today).
m_prevPage
m_nextPage
These are pointers to the previous and next pages at this level of the b-tree and store 6-byte page IDs.
The pages in each level of an index are joined in a doubly-linked list according to the logical order (as defined by the index keys) of the index. The pointers do not necessarily point to the immediately adjacent physical pages in the file (because of fragmentation).
The pages on the left-hand side of a b-tree level will have the m_prevPage pointer be NULL, and those on the right-hand side will have the m_nextPage be NULL.
In a heap, or if an index only has a single page, these pointers will both be NULL for all pages.
pminlen
This is the size of the fixed-length portion of the records on the page.
m_slotCnt
This is the count of records on the page.
m_freeCnt
This is the number of bytes of free space in the page.
m_freeData
This is the offset from the start of the page to the first byte after the end of the last record on the page. It doesn't matter if there is free space nearer to the start of the page.
m_reservedCnt
This is the number of bytes of free space that has been reserved by active transactions that freed up space on the page. It prevents the free space from being used up and allows the transactions to roll-back correctly. There's a very complicated algorithm for changing this value.
m_lsn
This is the Log Sequence Number of the last log record that changed the page.
m_xactReserved
This is the amount that was last added to the m_reservedCnt field.
m_xdesId
This is the internal ID of the most recent transaction that added to the m_reservedCnt field.
m_ghostRecCnt
The is the count of ghost records on the page.
m_tornBits
This holds either the page checksum or the bits that were displaced by the torn-page protection bits - depending on what form of page protection is turnde on for the database.
http://blog.csdn.net/jinjazz/article/details/1951174
7 解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
http://www.cnblogs.com/lyhabc/p/4026253.html
当我最初开始开发OrcaMDF的时候我只有一个目标,比市面上大部分的书要获取MDF文件内部的更深层次的知识
随着时间的推移,OrcaMDF确实做到了。在我当初没有计划的时候,OrcaMDF 已经可以解析系统表,元数据,甚至DMVs。我还做了一个简单UI,让OrcaMDF 更加容易使用。
这很好,但是带来的代价是软件非常复杂。为了自动解析元数据 例如schemas, partitions, allocation units 还有其他的东西,更不要提对于堆表和索引的细节的抽象层了,抽象层需要很多代码并且需要更多的数据库了解。鉴于不同SQLSERVER版本之间元数据的改变,OrcaMDF 目前仅支持SQL Server 2008 R2。然而,数据结构是相对稳定的,元数据的存储方式只有一点不同,使用DMVs暴露数据等等。要让OrcaMDF 正常运行,需要元数据是完好无损的,这就导致当SQLSERVER损坏的时候OrcaMDF 也是一样的。遇到损坏的boot page吗?无论SQLSERVER还是 OrcaMDF 都不能解析数据库
向RawDatabase问好
我在憧憬OrcaMDF 的未来 和如何使用他才是最有用的。我能够不断增加新的特性进去以使SQLSERVER支持什么功能他也支持,最终使得他能100%解析MDF文件。但是意义何在?当然,这是一个很好的学习机会,不过重点是,你使用软件读取数据,SQLSERVER能比你做得更好。所以,该如何选择?
RawDatabase, 参照Database 类,他不会尝试解析任何东西除非你让他去解析。
他不会自动解析schemas。他不知道系统表。他不知道DMVs。然而他知道SQLSERVER数据结构和给他一个接口他可以直接读取MDF文件。
让RawDatabase 只解析数据结构意味着他可以跳过损坏的系统表或者损坏的数据
例子
这个工具还在开发的早起,不过让我展示一下使用RawDatabase能够做什么东西。
当我运行LINQPad上的代码,他很容易的显示出结果,结果只是标准的.NET 对象。
所有的例子都在AdventureWorks 2008R2 LT (Light Weight)数据库上运行
获取单个页面
很多时候,我们只需要解析单个页面
// Get page 197 in file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.GetPage(1, 197).Dump();
解析页头
现在我们获取到页面,我们如何把页头dump出来
// Get the header of page 197 in file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.GetPage(1, 197).Header.Dump();
解析行偏移阵列
就像页头那样,我们也可以把页尾的行偏移阵列条目dump出来
// Get the slot array entries of page 197 in file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.GetPage(1, 197).SlotArray.Dump();
解析数据记录
当获取到行偏移条目的原始数据,你通常想看一下数据行记录的内容。幸运的是,这也很容易做到
// Get all records on page 197 in file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.GetPage(1, 197).Records.Dump();
从记录中检索数据
一旦你得到记录,你现在可以利用FixedLengthData 或者 VariableLengthOffsetValues 属性
去获取原始的定长数据内容和变长数据内容。然而,你肯定只想获取到实际的已解析的数据值。
对于解析,OrcaMDF会帮你解析,你只需要为他提供schema.
// Read the record contents of the first record on page 197 of file 1
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
RawPrimaryRecord firstRecord = (RawPrimaryRecord)db.GetPage(1, 197).Records.First();
var values = RawColumnParser.Parse(firstRecord, new IRawType[] {
RawType.Int("AddressID"),
RawType.NVarchar("AddressLine1"),
RawType.NVarchar("AddressLine2"),
RawType.NVarchar("City"),
RawType.NVarchar("StateProvince"),
RawType.NVarchar("CountryRegion"),
RawType.NVarchar("PostalCode"),
RawType.UniqueIdentifier("rowguid"),
RawType.DateTime("ModifiedDate")
});
values.Dump();
RawColumnParser.Parse方法做的事情是 跟他一个schema,他帮你自动将raw bytes转换为Dictionary<string, object>,key就是从schema 那里获取到的列名,
而value就是数据列的实际值,例如int,short,guid,string等等。让你的用户给定schema, OrcaMDF 可以跳过大量的依赖的元数据进行解析,因此可以忽略可能的元数据错误带来的数据读取失败。
由于页头已经给出了 NextPageID 和 PreviousPageID属性 ,这能够让软件简单的遍历链表中的所有页面,并解析这些页面里面的数据 --他基本上是根据给定的allocation unit来进行扫描
过滤页面
除非检索一个特定的页面,RawDatabase 也有一个页面属性能够枚举数据库中的所有页面。
使用这个属性,举个例子,获取数据库中所有的IAM页面的列表
// Get a list of all IAM pages in the database
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.Pages
.Where(x => x.Header.Type == PageType.IAM)
.Dump();
并且由于这是使用LINQ技术,这很容易去设计你想要的属性。
举个例子,你可以获取所有的 index pages 和他们的 slot counts 就像这样:
// Get all index pages and their slot counts
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.Pages
.Where(x => x.Header.Type == PageType.Index)
.Select(x => new {
x.PageID,
x.Header.SlotCnt
}).Dump();
或者假设你想获得如下条件的页面
1、页面里面至少有一条记录
2、free space空间至少有7000 bytes
下面是page id, free count, record count 和 平均记录大小的输出
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
db.Pages
.Where(x => x.Header.FreeCnt > 7000)
.Where(x => x.Header.SlotCnt >= 1)
.Where(x => x.Header.Type == PageType.Data)
.Select(x => new {
x.PageID,
x.Header.FreeCnt,
RecordCount = x.Records.Count(),
RecordSize = (8096 - x.Header.FreeCnt) / x.Records.Count()
}).Dump();
最后一个例子,,假设你只有一个MDF文件并且你已经忘记了有哪些对象存储在MDF文件里面。
不要紧,我们只需要查询系统表sysschobjs !sysschobjs 系统表包含了所有对象的数据
并且幸运的是,他的object ID 是 34。利用这些信息,我们可以把所有属于object ID 34的数据页面
过滤出来,并且从这些页面里读取记录并只需要解析这个表的前两列(你可以定义一个分部schema, 只要你在最后忽略列)
最后我们只需要把名称dump出来(当然我们可以把表里的所有列都查询出来,如果我们想的话)
SELECT * FROM sys.sysschobjs
var db = new RawDatabase(@"C:\AWLT2008R2.mdf");
var records = db.Pages
.Where(x => x.Header.ObjectID == 34 && x.Header.Type == PageType.Data)
.SelectMany(x => x.Records);
var rows = records.Select(x => RawColumnParser.Parse((RawPrimaryRecord)x, new IRawType[] {
RawType.Int("id"),
RawType.NVarchar("name")
}));
rows.Select(x => x["name"]).Dump();
兼容性
可以看到 RawDatabase并不依赖于元数据,这很容易兼容多个版本的SQLSERVER。
因此,我很高兴的宣布:RawDatabase 完全兼容SQL Server 2005, 2008, 2008R2 , 2012.
这也有可能兼容2014,不过我还未进行测试。说到测试,所有的单元测试都是自动运行的
在测试期间使用AdventureWorksLT for 2005, 2008, 2008R2 and 2012 。
现在有一些测试demo来让OrcaMDF RawDatabase去解析AdventureWorks LT 数据库里面每个表的每条记录
数据损坏
其中一个有趣的使用RawDatabase 的方法是用来附加损坏的数据库。你可以检索特定object id的所有页面然后硬解析每个页面
无论他们是否是可读的。如果元数据损坏,你可以忽略他,你手工提供schema (输入表的每个列的列名)并且只需要沿着页面链表
或者解析IAM页面去读取堆表里面的数据。接下来的几个星期我将会 写一些关于OrcaMDF RawDatabase 的使用场景的博客,其中包括数据损坏
源代码和反馈
我非常兴奋因为最新的RawDatabase 已经添加到OrcaMDF 里面并且我希望不单只只有我一个见证他的威力。
如果你也想试一试,或者有任何想法,建议或者其他反馈,我都很乐意接受。
如果你想试用,在GitHub上签出OrcaMDF项目。一旦这个工具做得比较完美了,我会把他放上去NuGet 。
就好像OrcaMDF一样,在GPL v3 licensed 下发布
工具下载:
http://pan.baidu.com/s/1skFeGVj