论文
《Online Pseudo Label Generation by Hierarchical Cluster Dynamics
for Adaptive Person Re-identification》
因为没看到开源代码…有些读的不是很理解…先记录下理清的部分。
存在的问题
作者认为,领域迁移的reid任务基于聚类生成伪标签的方法中伪标签不准确性的主要原因是:伪标签的滞后更新和所采用的聚类方法的简单。
传统的伪标签的生成例如:kmeans、DBSCAN都是采用离线生成伪标签的形式,
主要贡献
- 提出层次聚类动态的自适应在线伪标签生成方法。
- 由标签传播引导的聚类拆分和聚类合并策略。
完整pipeline
这个方法主要是参考《LEARNING TO PROPAGATE LABELS: TRANSDUCTIVE PROPAGATION NETWORK FOR FEW-SHOT LEARNING》得来的,所以一些方法讲解不清楚得去原论文找。

该方法应该是在SPCL的基础上改进的,主要架构等同SPCL,输入的图片包括源域和目标域,源域有label目标域没有,通过网络F提取特征,采用DBSCAN进行目标域的聚类,在memorybank中存储源域每个类的类中心和目标域每个类的类中心,memorybank采用momentum更新,同时输入的minibatch采用作者提出的split-merge方法更新标签,最后计算对比损失:
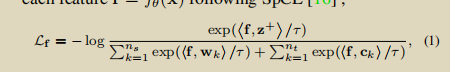
公式很简单,对于样本f,拉近f和同一类的距离,拉远和不同类的距离。
cluster split

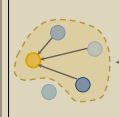
首先黄色应该是当前iter中的一个样本,蓝色则是这个样本属于的类中其他的一些样本,然后作者采用《LEARNING TO PROPAGATE LABELS: TRANSDUCTIVE PROPAGATION NETWORK FOR FEW-SHOT LEARNING》论文中的Density Peak(回头读读对应论文)方法挑选出了绿色和红色的两个样本,这个时候可以根据样本间的 相似度构建一个无向图:
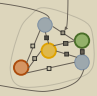
然后采用上述论文中的label propagation(回头读读对应论文)方法计算没有被density peak选中的两个蓝色样本的标签置信度:
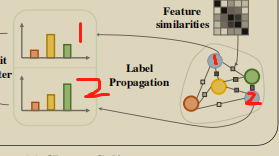
这时候可以看到,蓝色1的标签置信度认为它和黄色最相似,蓝色2的标签置信度和绿色最相似,因此将这个5个样本构成的聚类拆成下图:
cluster merge

merge和split的思想相似,都采用了label propagation来引导,首先对于当前iter中的黄色样本拿来对应类中的其他样本(蓝色表示),计算所有样本的相似度矩阵,这样可以构建一个无向图:
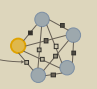
对相似度低于某个阈值的连接边进行舍弃得到如下无向图:
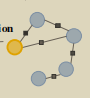
然后采用上述论文中的label propagation方法计算所有蓝色相对于黄色的label:
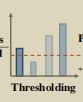
上图中的红色是阈值,低于阈值的样本从聚类中舍弃,因此最后的聚类结果:
Hierarchical Label Bank
如下图,作者在pipeline中进行了H次的split和merge

关于H次的消融实验:

论文效果

ICCV2021中的paper,但是指标感觉不是很高了,目前很多工作market1501上都有80+的mAP。