之前的论文中涉及到了论述几种经典轻型网络的计算量问题(以及为什么可以减少计算量),但是忘记做一个整理,今天来聊一聊这个
参考:https://blog.csdn.net/hongbin_xu/article/details/82957426(MobileNet)
https://blog.csdn.net/mzpmzk/article/details/82976871(深度可分离卷积)
https://blog.csdn.net/moxibingdao/article/details/109685497(ghostnet)
https://blog.csdn.net/u014380165/article/details/75137111(ShuffleNet)
https://blog.csdn.net/intflojx/article/details/81222156(ShuffleNet)
深度分离卷积:Depthwise Separable Convolution
在进入经典网络的描述之前我们先来了解一下一种很神奇的卷积:Depthwise Separable Convolution,由depthwise卷积(后称dw卷积)和pointwise卷积(后称pw卷积)两部分组成。
标准卷积计算量
假设输入特征图维度为: DF × DF × M, DF为输入的宽/高, M为输入通道数。
假设输出特征图维度为: DG × DG × N,DG?为输出的宽/高, N为输出通道数。
假设卷积核尺寸为: Dk × Dk ,Dk?为卷积核的宽/高。

卷积核参数量: DK × Dk × M × N
计算量(只计算乘法): Dk × Dk × M × N × DF × DF
计算量(FLOPS,包括乘法和加法): ( Dk ×D k × M + Dk × Dk × M ? 1 ) × N × DF × DF
注:为简化起见,后面求解计算量时只考虑乘法,不考虑加法。
深度可分离卷积计算量
分为两部分:depthwise卷积和pointwise卷积。
depthwise卷积:对每个输入通道单独使用一个卷积核处理。
pointwise卷积: 1 × 1卷积,用于将depthwise卷积的输出组合起来。

depthwise卷积:
输入: DF × DF × M,输出: DF × DF × M,卷积核尺寸: Dk × Dk
卷积核参数:分开为 M通道看,每个通道都是 Dk × Dk × 1 × 1 ,共 Dk × Dk × M
计算量: Dk × Dk × M × DF × DF
理解:将输入的特征图(维度为: DF × DF × M)看做是 M个 DF × DF × 1的特征图;对这M个 DF × DF × 1的特征图分别进行普通卷积(卷积核为: Dk × Dk ,输入通道数为 1 ,输出通道数也为1)。实质上,这就是对卷积的通道数进行分组,然后对每组的特征图分别进行卷积,是组卷积(group convolution)的一种扩展,每组只有一个特征图。
pointwise卷积:
输入: DF × DF × M ,输出: DF × DF × N ,卷积核尺寸: 1 × 1
卷积核参数: 1 × 1 × M × N
计算量: 1 × 1 × M × N × DF × DF
理解:就是 1 × 1 卷积,是普通的卷积操作
总计算量:
Dk × Dk × M × DF × DF + 1 × 1 × M × N × DF × DF = ( Dk × Dk + N ) × M × DF × DF
标准卷积与深度可分离卷积计算量的比较
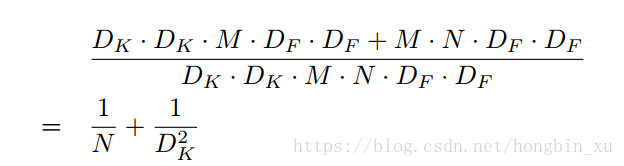
MobileNet
MobileNet使用的就是深度可分离卷积,通常MobileNet会使用卷积核为 3 × 3 的深度可分离卷积,上面这个式子的结果就接近于 1/9,大约可以比普通卷积减少了8到9倍的计算量。
GhostNet

GhostNet的图1特别有意思,它论证了针对一输入图片,ResNet-50中间的feature map,图中的30个feature map中,有一些feature map是很相似的,比如图中相同颜色标出的3组feature map。这种现象一定程度上说明了神经网络中feature map的冗余性,神经网络的冗余性有助于网络更全面地理解输入图片。与通过减少冗余性进行网络轻量化的工作不同,这篇文章并没有减少冗余性,而是采用一种新的、计算量小的方法生成冗余特征。
既然feature map具有冗余性,那么完全使用传统的卷积层生成这么冗余的特征是不是有点浪费计算资源了呢?考虑可以用一个输出feature map数量很少的卷积层和另外一个能增加冗余性、计算量小的操作去代替传统网络中的卷积层,既能保证特征冗余性从而保证精度,又能减少网络的整体计算量。

上图中图(b)所示即为作者提出的Ghost module。既然feature map有冗余性,大可不必使用很昂贵的传统卷积层产生所有的feature map;只需要使用传统卷积层产生一部分feature map,然后通过对这部分feature map做简单的线性变换,增加feature map的冗余性,应该可以“模拟”传统卷积层的效果。
因此Ghost module由两部分组成:其一为输出少量feature map的传统卷积层;其二为用于产生冗余feature map的轻量级线性变换层。
公式推导可见参考链接中的第3个
ShuffleNet
Shuffle没有采用深度可分离卷积操作,而是借助卷积的group操作来实现计算量的减少,其实思想上与深度可分离卷积很类似
channel shuffle的思想可以看下面的Figure 1。这就要先从group操作说起,一般卷积操作中比如输入feature map的数量是N,该卷积层的filter数量是M,那么M个filter中的每一个filter都要和N个feature map的某个区域做卷积,然后相加作为一个卷积的结果。假设你引入group操作,设group为g,那么N个输入feature map就被分成g个group,M个filter就被分成g个group,然后在做卷积操作的时候,第一个group的M/g个filter中的每一个都和第一个group的N/g个输入feature map做卷积得到结果,第二个group同理,直到最后一个group,如Figure1(a)。不同的颜色代表不同的group,图中有三个group。这种操作可以大大减少计算量,因为你每个filter不再是和输入的全部feature map做卷积,而是和一个group的feature map做卷积。但是如果多个group操作叠加在一起,如Figure1(a)的两个卷积层都有group操作,显然就会产生边界效应,什么意思呢?就是某个输出channel仅仅来自输入channel的一小部分。这样肯定是不行的的,学出来的特征会非常局限。于是就有了channel shuffle来解决这个问题,先看Figure1(b),在进行GConv2之前,对其输入feature map做一个分配,也就是每个group分成几个subgroup,然后将不同group的subgroup作为GConv2的一个group的输入,使得GConv2的每一个group都能卷积输入的所有group的feature map,这和Figure1(c)的channel shuffle的思想是一样的。

pointwise group convolutions,其实就是带group的卷积核为1*1的卷积,也就是说pointwise convolution是卷积核为1*1的卷积。在ResNeXt中主要是对3*3的卷积做group操作,但是在ShuffleNet中,作者是对1*1的卷积做group的操作,因为作者认为1*1的卷积操作的计算量不可忽视。可以看Figure2(b)中的第一个1*1卷积是GConv,表示group convolution。Figure2(a)是ResNet中的bottleneck unit,不过将原来的3*3 Conv改成3*3 DWConv,作者的ShuffleNet主要也是在这基础上做改动。首先用带group的1*1卷积代替原来的1*1卷积,同时跟一个channel shuffle操作,这个前面也介绍过了。然后是3*3 DWConv表示depthwise separable convolution。depthwise separable convolution可以参考MobileNet,下面贴出depthwise separable convolution的示意图。Figure2(c)添加了一个Average pooling和设置了stride=2,另外原来Resnet最后是一个Add操作,也就是元素值相加,而在(c)中是采用concat的操作,也就是按channel合并,类似googleNet的Inception操作。
