Lite-HRNet: A Lightweight High-Resolution Network
这个Lite版本的轻型网络在论文中给的指标对于模型压缩量极其可观,值得复现一下,故于此学习。
先写重要的
LiteNRNet的修改中关于条件加权通道是怎么实现的
其实这个想法很自然,Shuffle block在利用channel shuffle之后明显的减少了计算量,但是仍存在1x1卷积,HRNet是一个多分支、同时多分支信息交叉融合带来准确率提升的模型,自然而然的就想到了把1x1的卷积用信息交叉来替换,保证准确率的同时进一步减少压缩模型减少计算量
条件加权通道由交叉分辨率加权函数和空间加权函数两部分组成
H,也就是条件加权部分本质上就是收集HRNet中其他给分支分辨力的特征图并将他们加权后融合,权重由各分支的特征图的尺寸计算,这是在根据信息的含量决定融合的强弱。
F,这里其实完全可以仍然使用1x1的卷积,F的这种操作可能本质上是想多一些可训练参数,进而提升网络的表达能力。因为F本质上是一个全局池化加卷积加卷积的过程,这部分最大作用很可能就是为了引入这两个卷积。但由于是在分支上做卷积,输入输出的特征图都比较小,所以没有增加太多的计算量
摘要
我们提出了一种用于人体姿态估计的高效的高分辨率网络Lite-HRNet。我们首先直接将ShuffleNet中的高效shuffle模块应用到HRNet(高分辨率网络),与流行的轻量级网络(例如 MobileNet、ShuffleNet 和 Small HRNet)相比展现了更强的性能。我们发现在shuffle块中大量使用pointwise (1x1)卷积成为了计算瓶颈。我们引入了一个轻量级单元:条件通道加权,来替换shuffle块中昂贵的pointwise (1x1)卷积。通道加权的复杂度与通道数量成线性关系,并且低于pointwise (1x1)卷积的二次时间复杂度。我们的解决方案从所有通道和多个分辨率中学习权重,这些权重在HRNet的并行分支中很容易获得。它使用权重作为跨通道和跨分辨率交换信息的桥梁,补偿pointwise (1x1)卷积所起的作用。Lite-HRNet展示了优于现下流行的轻量级网络的人体姿态估计结果。此外,Lite-HRNet可以以相同的轻量化方式轻松被应用于语义分割任务中。代码和模型已在 https://github.com/HRNet/Lite-HRNet 上公开提供。
图解

图1. 构建模块(a) shuffle模块 (b) 我们的条件通道加权模块。虚线表示从一个分辨率和分布权重到其他分辨率。H=交叉分辨率加权函数。F=空间加权函数。

图2. 小型 HRNet 架构的图示。第一阶段由一个高分辨率的主干组成,之后逐渐介入由高到低分辨率的流作为主体。主体有一系列阶段,每个阶段包含并行的多分辨率流和重复的多分辨率融合。详细信息在第 3 节中给出。

图3. COCO姿态估计的定性结果示例:包含视点变化、遮挡和多人情况

图4. COCO val和MPII val数据集的复杂性和准确性比较的图示。(a) 256x192输入大小下在COCO val集上的比较。 (b) 256x256输入大小下MPII val集上的比较。MBV2=MobileNet V2。SFV2= ShuffleNet V2。 SHR=Small HRNet-W16。 (W)LH=(Wider)Lite-HRNet。

表1. Lite-HRNet 的结构。主干包含一个stride=2的3x3卷积和一个shuffle模块。主体分为三个阶段,每个阶段都有一系列模块组成。每个模块由两个条件通道权重模块(conditional channel weight blocks)和一个融合(fusion block)模块组成。Lite-HRNet-N中的N表示层数。分辨率分支表示该阶段包含对应分辨率的特征流。ccw = 条件信道权重。

表2. 计算复杂度对比:1x1 convolution vs. conditional channel weight. Xs属于R^(Hs x Ws x Cs)是s分辨率的输入通道特征图,X1是最高的分辨率。Ns = HsWs。例如X1和X2的形状是64x64x40和32x32x80。single/cross-resolution是single/cross 分辨率信息交换。

表3. 在COCO val数据集上的对比。pretrain表示在ImageNet数据集上与训练的backbone。#Params和FLOPs是为姿态估计网络计算的,其中不包括人体检测和关键点分组部分。
梳理网络-预备知识
caffe中的BN+Scale=PyTorch中的BN:https://blog.csdn.net/u011668104/article/details/81532592
卷积后尺寸的计算:Wo=(Wi + 2P -F)/S+1, Ho=(Hi + 2P -F)/S+1, C通道观察卷积类型可知。
不整除时,卷积向下取整,池化向上取整。因卷积向上取整没有对应信息,池化向上取整会有对应信息。
看到stride为1的时候,当kernel为 3 padding为1或者kernel为5 padding为2 卷积前后尺寸不变
DWConv就是组卷积(Group Conv),不改变通道
native Lite-HRNet是指将shauffle moudle直接应用于HRNet
论文精读
introduction
人体姿态估计需要高分辨率表示[3, 2, 26, 41, 45]以实现高性能。受对模型效率日益增长的需求的推动,本文研究了在计算资源有限的情况下开发高效高分辨率模型的问题。现有的高效网络[5, 6, 53]主要是从两个角度设计的。一种是借用分类网络的设计,例如MobileNet[17, 16]和ShuffleNet[28, 57],以减少矩阵向量乘法中的冗余,其中卷积运算占据矩阵向量运算主要消耗。另一种是通过各种技巧来调解空间信息丢失,例如编码器-解码器架构[2, 26]和多分支架构[53, 59]。我们首先通过简单地结合ShuffleNet中的shuffle block和HRNet[41]中的高分辨率设计模式来研究一个朴素(native)的轻量级网络。 HRNet在位置敏感问题(positionsensitive problems)的大型模型中表现出更强的能力,例如语义分割、人体姿态估计和对象检测。目前尚不清楚高分辨率是否有助于小模型。我们凭经验表明,直接组合优于ShuffleNet、MobileNet和Small HRNet1。为了进一步实现更高的效率,我们引入了一个高效的单元,称为条件通道加权,执行跨通道的信息交换,以取代shuffle块中昂贵的逐点(1x1)卷积。这就是进一步压缩(或者说Lite-HRNet如此有效)的原因,即channel shuffle已经减少了计算量,现在连1x1的卷积也被取代了。通道加权方案非常有效:复杂度与通道数量成线性关系,并且低于逐点卷积的二次时间复杂度。例如,通过64x64x40和32x32x80的多分辨率特征,条件通道加权单元可以将shuffle块的整个计算复杂度降低80%。与作为模型参数学习的常规卷积核权重不同,所提出的方案权重以输入图为条件,并通过轻量级单元跨通道计算(Unlike the regular convolutional kernel weights learned as model parameters, the proposed scheme weights are conditioned on the input maps and computed across channels through a lightweight unit.)。因此,它们包含所有信道映射中的信息,并作为通过信道加权交换信息的桥梁。此外,我们从易于获得的HRNet并行多分辨率通道映射计算权重,以便权重包含更丰富的信息并得到加强。我们将生成的网络称为Lite-HRNet。
卷积权重生成和混合(Convolutional weight generation and mixing)
动态滤波器网络[21]动态生成以输入为条件的卷积滤波器。元网络[29]采用元学习器来生成权重以学习跨任务知识。CondINS[40]和SOLOV2[43]将此设计应用于实例分割任务,为每个实例生成掩码子网络的参数。CondConv[48]和Dynamic Convolution[5]学习一系列权重以混合每个样本的相应卷积核,增加模型容量。注意机制[19, 18, 44, 54]可以看作是一种条件权重生成。SENet[19]使用全局信息来学习激发或抑制通道映射的权重。GENet[18]通过收集本地信息来利用上下文相关性对此进行了扩展。CBAM[44]利用通道和空间注意力来细化特征。提出的条件通道加权方案在某种意义上可以被视为条件通道的1x1卷积。除了其廉价的计算之外,我们还利用了一个额外的效果并使用条件权重作为跨通道交换信息的桥梁。
条件架构(Conditional architecture)
与普通网络不同,条件架构可以实现动态的宽度、深度或内核。SkipNet[42]使用门控网络跳过一些卷积块以选择性地降低复杂性。空间变换网络[20]学习以输入为条件扭曲特征图。Deformable Convolution[11,61]学习以每个空间位置为条件的卷积核的偏移量。
native LiteHRNet的产生
我们采用shuffle块替换Small HRNet的stem中的第二个3x3卷积,替换掉所有正常的残差块(由两个3×3卷积组成)。多分辨率融合中的正常卷积被可分离卷积替换[9],从而产生了一个朴素的Lite-HRNet。 注意这里是用shuffle替换掉了两处,第2个3x3常规卷积和残差。
1x1卷积代价高昂(1x1 convolution is costly)
1x1卷积在每个位置执行矩阵向量乘法:其中X和Y是输入和输出映射,W 是1x1卷积核。它在跨通道交换信息方面起着关键作用,因为 shuffle 操作和深度卷积对跨通道的信息交换没有影响。1x1卷积的二次时间复杂度(O(C2))相对于数量(C)渠道。3x3深度卷积具有线性时间复杂度(O(9C)3)。在shuffle块中,两个1x1卷积的复杂度比depthwise卷积的复杂度高很多:O(2C2) > O(9C),对于通常的情况C > 5。表2给出了1x1之间复杂度比较的例子卷积和深度卷积。
条件信道加权(Conditional channel weighting)
我们建议使用element-wise加权操作来替换naive Lite-HRNet中的1x1卷积,它在第s阶段有s个分支。第s个分辨率分支的逐元素加权运算写为: Ys = Ws ●Xs; (2) 其中Ws是权重图,大小为Ws x Hs x Cs的3-d张量,并且是逐元素乘法运算符。复杂度与通道数 O(C) 呈线性关系,远低于shuffle块中的1x1卷积。我们通过使用单个分辨率的通道和所有分辨率的通道来计算权重,如图1(b)所示,并表明权重起到了跨通道和分辨率交换信息的作用。
跨分辨率权重计算(Cross-resolution weight computation)
考虑第s个阶段,有s个并行分辨率,s个权重图W1,W2,.....Ws,分别为对应的分辨率。我们使用轻量级函数Hs(·) 计算跨分辨率的所有通道的权重图,Hs(·)过程是先使用adaptive average pooling (AAP)在{X1, X2, X3,...Xs}上计算:X1' =AAP(X1),X2' =AAP(X2),Xs' =AAP(Xs),其中AAP将任何输入大小池化为给定的输出大小Ws x Hs,然后我们将 {X1, X2, .....Xs} 和 Xs 连接在一起,然后是 1x1 卷积、ReLU、1x1卷积和sigmoid的序列,生成由s个分支{W1, W2, .. ...Ws}(每个用于一个分辨率)。
这里,每个分辨率的每个位置的权重取决于来自平均池化的多分辨率通道图中相同位置的通道特征。这就是我们称该方案为跨分辨率权重计算的原因。 s-1 权重图 {W1',W2',.....Ws-1'} 被上采样到相应的分辨率,输出 {W1,W2,.....Ws-1},用于后续逐元素通道加权。我们展示了权重图作为跨渠道和分辨率信息交换的桥梁。位置 i 处的权重向量 wsi 的每个元素(来自权重图 Ws)在同一池化区域接收来自所有 s 个分辨率的所有输入通道的信息,这很容易从等式 4 中的操作中验证。通过这样一个权重向量,这个位置的每个输出通道,ysi = wsi ● xsi;接收来自所有分辨率相同位置的所有输入通道的信息。换句话说,通道加权方案在交换信息方面起到了和 1x1 卷积一样的作用。另一方面,函数Hs(·)应用于小分辨率,因此计算复杂度很轻。表 2 说明整个单元的复杂度远低于 1x1 卷积。
重点是Ys = Ws ● Xs公式(●是逐点点乘),Xs是上一步的输出,也就是这一步的输入,Ws的计算是条件加权模块的主要任务之一。Ws是一个ws x hs x cs3-d的向量,由公式{W1, W2, W3,...Ws}=Hs{X1, X2, X3,...Xs}计算得到,Hs具体过程是上面所述。文中给出的结论是:“通过这样一个权重向量,这个位置的每个输出通道,ysi = wsi ● xsi;接收来自所有分辨率相同位置的所有输入通道的信息。换句话说,通道加权方案在交换信息方面起到了和 1x1 卷积一样的作用”,同时减少了计算量。这里提到的1x1卷积的通道交换信息能力比较笼统,应该指得是C通道之间的信息交换,而不是后面DW的通道交换核融合部分。
空间权重计算(Spatial weight computation)
对于每个分辨率,我们还计算与空间位置同构的空间权重:所有位置的权重向量wsi都相同。权重取决于单一分辨率下输入通道的所有像素:ws = Fs(Xs),这里,函数 Fs(·) 实现为:Xs - GAP - FC - ReLU - FC - sigmoid - ws.全局平均池化(GAP)算子的作用是从所有位置收集空间信息。通过使用空间权重对通道进行加权,ys =ws x si,输出通道中的每个元素都接收来自所有输入通道的所有位置的贡献。我们在表2中比较了1x1卷积和条件通道加权单元之间的复杂性。
0804更新:注意跨通道和跨分辨率是不一样的
条件通道加权方案与条件卷积[48]、动态滤波器[21]和挤压激发网络[19]具有相同的原理。这些工作通过以输入特征为条件的子网络学习卷积核或混合权重,以增加模型容量。相反,我们的方法利用了一个额外的效果,并使用从所有通道中学到的权重作为跨通道和分辨率交换信息的桥梁。它可以替代轻量级网络中昂贵的1x1卷积。此外,我们引入了多分辨率信息来促进权重学习。
也就是说上面所述的1x1卷积具有通道信息交换能力是对的,至于分辨率交换是我们的条件加权模块所标新立异的点之一。
测试(test)
额外的半身数据增强(additional half body data augmentation)在人体姿态估计中很常见
对于COCO遵循[46, 7, 33],我们采用两阶段自顶向下范式(通过人员检测器检测人员实例并预测关键点)以及SimpleBaseline[46]提供的人员检测器。对于MPII我们采用标准测试策略来使用提供的人员框。 我们通过后高斯滤波器估计热图,并对原始和翻转图像的预测热图进行平均。在从最高响应到第二高响应的方向上应用四分之一偏移以获得每个关键点位置。
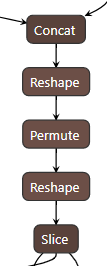
caffe中的permute层(该层的功能是交换维度)之所以能取得与shuffle操作相同的效果,是因为在进行permute操作时,会取出每个原维度的对应位置(相同位置)的元素归并为同一个新的维度。可以参照这个链接中的图片:https://www.zhihu.com/question/269160464
然后在变化后的维度上直接合并,就完成了通道交换的操作结合论文和caffemodel图这次才真正看懂了整个LiteHRNet结构
这部分是条件选择通道(下图),对应的是文中的{X1, X2, X3,...Xs}->Conv->ReLU->Conv->sigmoid->{W1, W2, W3,...Ws}过程,
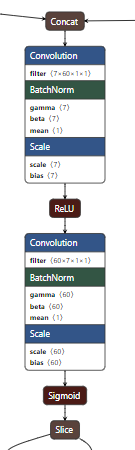
这部分是空间权重计算通道,对应的是文中的Xs ->GAP ->FC ->ReLU ->FC ->sigmoid ->ws过程
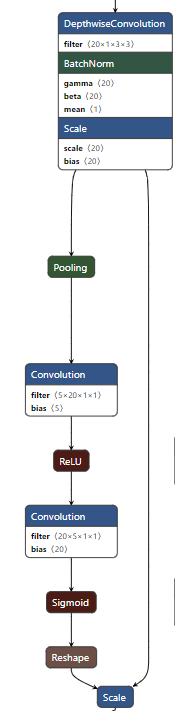
两部分之间经过Eltwise层之后进行连接,这个在文中也提到过,就是点乘
shuffle channel层的实现是借助Condcat->Reshape->Premute->Reshape-Slice组合而成
上面的两个权重操作加上shuffle channel操作,共同构成了一个完成的替代shuffle层的条件加权层,也就是图1
之后要做的就是各个不同分辨率之间的融合以及相同模块的叠加,从而构成整个完整网络。