1. Network Organization
Faster R-CNN主要解决了两个问题:第一,使用RPN网络提取可能包含目标的regions;第二,计算每个regions的类别概率,并将类别概率最大值作为分类结果。Faster R-CNN网络主要包括三部分:
- Head
- Region Proposal Network (RPN)
- Classification Network
- 首先,“Head”网络使用预训练的分类网络,如Resnet50, VGG16,来提取图像特征从而得到convolutional feature maps;
- 然后,convolutional feature maps进入由卷积层和全连接层构成的RPN网络,RPN网络将会根据feature maps提取图像中可能包含目标前景的regions,并在feature maps中裁剪出这些regions,这称为“Crop Pooling”;
- 最后,将裁剪得到的regions送入分类网络
1.1 Network Architecture
下图显示了上述三个分网络的各个组件。我们展示了每个网络层的输入和输出的维度,这有助于理解网络的每个层如何转换数据。w和h表示输入图像的宽度和高度(在预处理之后)。

2. Implementation Details: Training
在本节中,我们将详细描述训练R-CNN所涉及的步骤。一旦了解了训练的工作原理,理解预测部分就会轻松得多,因为它只是简单地使用了训练中涉及的一部分步骤。训练的目标是调整RPN和分类网络中的权重并微调头部网络的权重(这些权重从预先训练的网络(如ResNet)初始化)。回想一下,RPN网络的工作是产生有前景的ROI,分类网络的工作是为每个ROI分配对象类分数。因此,为了训练这些网络,我们需要相应的基础ground truth,即图像中存在的对象的边界框坐标和对象的类。ground truth 来自免费使用的图像数据库,每个图像附带一个注释文件。此注释文件包含边界框的坐标和图像中存在的每个对象的对象类标签(对象类来自预定义对象类的列表)。这些图像数据库已被用于支持各种对象分类和检测挑战。两个常用的数据库是:
- PASCAL VOC: The VOC 2007 database contains 9963 training/validation/test images with 24,640 annotations for 20 object classes.
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
- COCO (Common Objects in Context): The COCO dataset is much larger. It contains > 200K labelled images with 90 object categories.
下面将简单介绍在目标检测领域经常使用的两个概念:“边界框回归系数”和“边界框重叠”。
Bounding Box Regression coefficients. 它也被称为“regression coefficients” and “regression targets”. One of the goals of R-CNN is to produce good bounding boxes that closely fit object boundaries. R-CNN通过采用给定的边界框(由左上角的坐标,宽度和高度定义)并通过应用一组“回归系数”来调整其左上角,宽度和高度来生成这些边界框。 让目标和原始边界框的左上角的x,y坐标分别由T_x,T_y,O_x,O_y表示,目标和原始边界框的宽度/高度分别由T_w,T_h,O_w,O_h表示。 然后,回归目标(将原始边界框转换为目标框的函数的系数)给出如下:

Intersection over Union (IoU) Overlap. 我们需要测量给定边界框与另一个边界框的接近程度,该边界框与所使用的单位(像素等)无关,以测量边界框的尺寸。该度量应该是直观的(两个重合的边界框应该具有1的重叠,并且两个非重叠的框应该具有0的重叠)并且快速且易于计算。常用的重叠度量是“联合交叉(IoU)重叠,计算如下所示”:

下图是Faster R-CNN网络的训练步骤,它分为多个层,一个层封装了一系列逻辑步骤:

Anchor Generation Layer. 该层通过生成9个不同比例和纵横比的锚框(边界框),然后通过在输入图像上跨越均匀间隔的网格点来复制这些锚框。
Proposal Layer. 根据边界框回归系数变换(平移,缩放)锚框以生成变换后的锚框。然后通过使用锚框作为前景区域的概率应用非最大抑制(参见附录)来修剪锚框的数量。
Anchor Target Layer. 锚目标层的目的是产生good anchors,以及相应的前景/背景标签和目标回归系数,来训练RPN网络。由anchor generation layer产生的锚框,锚目标层可以识别出可能含有前景或背景的锚框。可能含有前景的锚框会与某些ground truth box重叠且大于一个阈值;可能含有背景的锚框将会与所有ground truth box的重叠值小于一个阈值。锚目标层还会生成边界框回归量(x,y,w,h),并用它来衡量anchor与最近ground truth box之间的距离,但这些回归量只对包含前景的anchor有意义,而对那些包含背景的anchor没有最近ground truth box之说。
RPN Loss. RPN损失函数会在训练RPN网络时进行最小化。该损失函数包括两个部分:第一,RPN网络生成的anchors被正确分类为前景/背景;第二,预测回归系数和目标回归系数之间的距离度量。
Proposal Target Layer. 提议目标层的目标是修剪由proposal layer产生的锚框列表,并生成特定类的边界框回归目标,这些可以用来训练分类层以生成good类标签和回归目标。
ROI Pooling Layer. 实现空间变换网络(spatial transformation network)。在提议目标层(proposal target layer)产生的区域提议的边界框坐标的情况下,该网络对输入的特征图进行采样。这些坐标通常不是整数,因此需要基于插值的采样。
Classification Layer. 分类层将由ROI池化层输出的特征图传递给一系列卷积层。输出的特征图再进入两个全连接的层:第一层为每个区域提议生成类别概率分布,第二层生成一组特定于类的边界框回归量(x,y,w,h)。
Classification Loss. 与RPN损失函数类似,分类损失函数会在训练分类网络时进行最小化。在反向传播期间,误差梯度也流向RPN网络,因此训练分类层也会修改RPN网络的权重。我们稍后会谈到这一点。 分类损失同样包括两个部分:第一,RPN生成的边界框被正确分类(作为正确的对象类);第二,预测回归系数和目标回归系数之间的距离度量。
2.1 Anchor Generation Layer

2.2 Region Proposal Layer
R-CNN使用selective search to generate region proposal. Faster R-CNN使用基于“sliding window”技术生成一组密集候选区域,然后区域提议网络RPN根据包含前景对象区域的概率对区域提议进行排名。Region proposal layer有两个目标:
- 从锚框列表中,识别前景/背景锚框
- 通过应用一组“回归系数”来修改锚框的位置,宽度和高度,以提高锚框的质量(例如,使它们更好地适应对象的边界)
Region proposal layer由RPN网络和三个层组成,即proposal layer,anchor target layer和proposal target layer。
2.2.1 Region Proposal Network

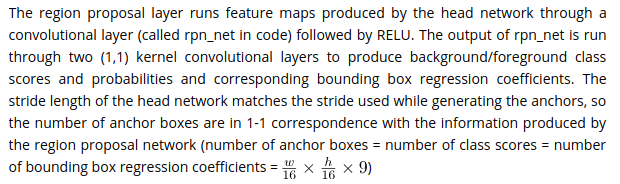
2.2.2 Proposal Layer

2.2.3 Anchor Target Layer
Anchor target layer的目的是选择可以训练RPN网络的锚框,从而能够识别出前景/背景,以及为前景框产生good框回归系数。
2.2.4 Proposal Target Layer
Proposal target layer将从proposal layer产生的ROIs列表中选出promising ROIs. These promising ROIs will be used to perform crop pooling from the feature maps produced by the head layer and passed to the rest of the network (head_to_tail) that calculates predicted class scores and box regression coefficients.
Similar to the anchor target layer, it is important to select good proposals (those that have significant overlap with gt boxes) to pass on to the classification layer. Otherwise, we’ll be asking the classification layer to learn a “hopeless learning task”.