ФПТМ
БГОА
APOD
ЦРЙР
ВЂааЛЏ
гХЛЏ
ВПЪ№
ЦРЙР
вьЙЙМЦЫу
ЩшБИЯЕЭГКЭжїЛњЯЕЭГЕФЧјБ№
ЯпГЬзЪдД
ЯпГЬ
ФкДц
gpuЩшБИЩЯдЫааЕФЖЋЮї
гІгУЗжЮі
ЗжЮі
ЫѕЗХ
ЧПЫѕЗХ
ШѕЫѕЗХ
гІгУ
ВЂааЛЏ
ВЂааЛЏПт
ВЂааЛЏБрвыЦї
ВЂааЛЏДњТы
ЕУЕНе§ШЗЕФНсЙћ
бщжЄ
ЕїЪд
Ъ§зжНсЙћЕФзМШЗадКЭОЋШЗЖШ
ЕЅОЋЖШКЭЫЋОЋЖШ
ИЁЕудЫЫуВЛТњзуНсКЯТЩ
ЕЅЫЋОЋЖШжЎМфЕФзЊЛЛ
IEEE 754
x86жа80ЮЛЕФМЦЫу
гХЛЏcudaгІгУ
Нсгя
БГОА
ЗХМйвЛжмЖрЃЌЯаЕУУЛЪТЖљЃЌМЬајЗжЯэЖдcudaЮФЕЕЕФЗвыЃЌЯШЩљУїЯТЮвЕФВтЪдЛЗОГЃКcuda10.0ЃЌubuntu16.04 x86_64ЃЌgcc/g++7.0
APOD
ЙйЗНЮФЕЕЬсГіЕФгІгУгХЛЏФЃаЭЮЊЦРЙР(Assess)ЁЂВЂааЛЏ(Parallelize)ЁЂгХЛЏ(Optimize)КЭВПЪ№(Deploy)ЃЌМђГЦAPODЃЌШчЯТЭМЫљЪО
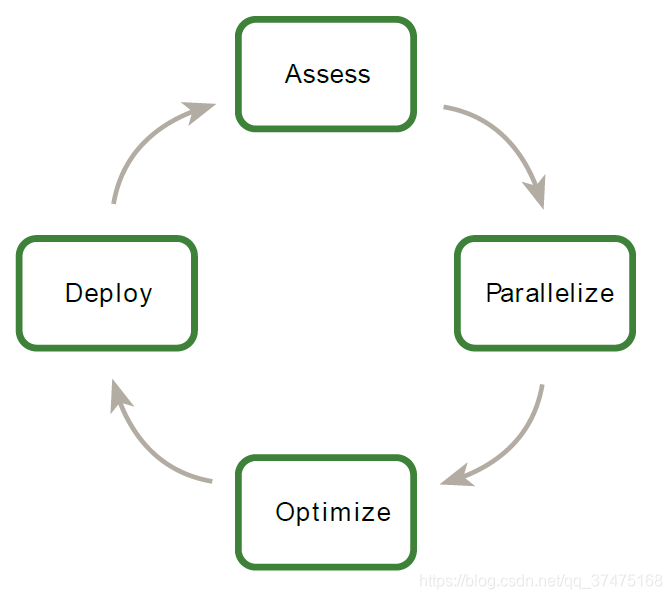
APODЪЧвЛИіЛЗаЮЕФЙ§ГЬЃКЯШЭЖШыЩйСПЕФОЋСІгыЪБМфДяЕНзюГѕЕФгХЛЏгыМгЫйЃЌШЛКѓВЛЖЯЕќДњ
ЦРЙР
ЖдгквЛИівбгаЕФЯюФПЃЌЕквЛВНЪЧЖдЦфНјааЦРЙРЃЌвдЖЈЮЛГіашвЊЯћКФДѓСПжДааЪБМфЕФДњТыЃЌвдБужЎКѓЖдЦфНјааВЂааЛЏКЭМгЫйЁЃСэЭтЃЌЭЈЙ§РэНтжеЖЫгУЛЇЕФашЧѓЁЂЯожЦЃЌдйгІгУАЂБШДяЖћЖЈТЩКЭЙХЫЙЫўЗђЩЖЈТЩЃЌПЊЗЂШЫдБПЩвдШЗЖЈБэЯжСІЬсИпЕФЩЯНчЃЌетжжЬсИпОЭЪЧРДздгкЖдЯюФПжИЖЈВПЗжЕФМгЫй
ВЂааЛЏ
ЖЈЮЛКУСЫШШЕуДњТыКЭЬсЩ§ФПБъЃЌПЊЗЂепОЭвЊЖдДњТыНјааВЂааЛЏЁЃИљОндЪМДњТыЕФВЛЭЌЃЌВЂааЛЏЗНЗЈгаСНжжЃКЕїгУЯжГЩЕФGPUгХЛЏПт(cuBLASЁЂcuFFTЛђThrust)КЭЬэМгдЄДІРэжИСю(hintЕШ)вдВЂааЛЏБрвыЦїЁЃ
СэЭтЃЌвЛаЉгІгУПЩФмвЊзівЛаЉЩшМЦЩЯЕФжиЙЙЃЌвдЬНЫїЛђПЊЗЂВЂааЖШЃЌЩѕжСCPUМмЙЙЮЊСЫЬсИпЛђепБЃГжЫГађгІгУЕФБэЯжСІЃЌвВвЊЖдВЂааЖШНјааЬНЫїЃЌЖјCUDAЕФВЂааБрГЬгябд(CUDAЕФc/c++ЁЂfortranЕШ)жМдкОЁПЩФмМђЕЅЕиУшЪіетжжВЂааЖШЃЌЭЌЪБдкжЇГжcudaЕФgpuЩшБИЩЯПЊЦєЖдгІЕФВйзївдзюДѓЛЏВЂааЭЬЭТСПЁЃ
гХЛЏ
ЕБУПвЛТжЕФгІгУВЂааЛЏЭъГЩКѓЃЌПЊЗЂепОЭПЩвдНјаагХЛЏвдЬсИпБэЯжСІСЫЁЃвђЮЊгХЛЏЗНЗЈКмЖрЃЌЫљвдПЊЗЂепашвЊРэНтгІгУЕФашЧѓЃЌетбљЛсБмУтКмЖрВЛБивЊЕФТщЗГЁЃгХЛЏЕФВуУцКмЖрЃЌАќРЈАбЪ§ОнДЋЪфКЭМЦЫуВЂааДІРэвЛТЗЯђЯТЕНЯИСЃЖШЕиЮЂЕїИЁЕуВйзїађСаЃЌДЫЪБгХЛЏЙЄОпОЭКмБІЙѓЃЌвђЮЊЫќУЧФмЖдПЊЗЂепЯТвЛВНЕФгХЛЏИјГіНЈвщЁЃ
ВПЪ№
ЭъГЩСЫЖдЯюФПвЛИіЛђЖрИіВПЗжЕФGPUМгЫйКѓЃЌОЭПЩвдБШНЯМгЫйЧАКЭМгЫйКѓЕФаЇЙћСЫЃЌвВПЩвдАбЕквЛВНЦРЙРжаЖЈГіЕФБэЯжСІЩЯНчФУГіРДзіЖдБШЁЃ
зюКѓЃЌжиЩъвЛБщЃЌзюКУвЛДЮжЛЖдЯюФПЕФФГИіВПЗжНјааAPODЙ§ГЬгХЛЏМгЫйЃЌШЛКѓдйгХЛЏБ№ЕФВПЗжЃЌетбљЕќДњНјааПЩвдЫѕЖЬНЛИЖжмЦкЁЃ
ЯТУцОЭЪЧЖдетAPODИќЯъЯИЕФНВНт
ЦРЙР
ДгГЌМЖМЦЫуЛњЕНжЧФмЪжЛњЃЌЯжДњДІРэЦїдНРДдНвРППВЂааЖШРДЬсЙЉКУЕФБэЯжСІЁЃДѓСПЕФКЫаФМЦЫуЕЅдЊЃЈАќРЈПижЦЦїЁЂдЫЫуЦїЁЂМФДцЦїКЭвЛаЉЛКДцЃЉКЭФкДцЯрСЌЃЌЮЊДњТыЪЕЯжВЂааЛЏЬсЙЉСЫЬѕМўЁЃ
ОЁЙмДІРэЦїе§ГЏзХЯђПЊЗЂепЬсЙЉИќМгЯИСЃЖШЕФВЂааЛЏЕФЗНЯђЗЂеЙЃЌЕЋЯждкКмЖргІгУЕФДњТыЛЙЪЧДЎааЛђепДжСЃЖШЕФВЂааЃЌР§ШчНЋЪ§ОнЗжГЩМИИіФмЙЛВЂааДІРэЕФЧјЃЌЧјжЎМфЪЙгУMPIЭЈаХЛђЙВЯэЪ§ОнЁЃЮЊСЫРћгУАќРЈGPUдкФкЕФЯжДњДІРэЦїМмЙЙЃЌЮвУЧЭЗвЛВНОЭЪЧЖдЯюФПНјааЦРЙРЃЌевГіШШЕуДњТыВЂХаЖЯЫќУЧФмВЛФмБЛВЂааЛЏЃЌвдМАЦРЙРЙЄзїСП
вьЙЙМЦЫу
cudaБрГЬЩцМААбДњТыЭЌЪБдкСНИіЦНЬЈдЫааЃКжїЛњЯЕЭГ(hostЃЌcpuЦНЬЈ)КЭЩшБИЯЕЭГ(deviceЃЌжЇГжcudaЕФгЂЮАДяgpu)ЁЃОЁЙмгЂЮАДяgpuОГЃИњЭМЯёЙиСЊдквЛЦ№ЃЌЕЋЫќУЧвВжЇГжВЂаадЫааЩЯЧЇИіЧсСПМЖЯпГЬРДНјааЪ§зждЫЫуЃЌетЪЙЕУгЂЮАДяgpuКмЪЪКЯвЊВЂаажДааЕФМЦЫугІгУЁЃЕЋЪЧЃЌЩшБИЯЕЭГЕФЩшМЦЪЧКЭжїЛњЯЕЭГДѓЯрОЖЭЅЕФЃЌвђДЫРэНтСНепЕФЧјБ№КЭЫќУЧШчКЮОіЖЈcudaгІгУЕФБэЯжСІЖдЮвУЧгааЇЪЙгУcudaДѓгаёдвц
ЩшБИЯЕЭГКЭжїЛњЯЕЭГЕФЧјБ№
жївЊЕФЧјБ№АќРЈЯпГЬФЃаЭКЭЮяРэФкДцСНЗНУц
ЯпГЬзЪдД
жїЛњЯЕЭГжЛФмжЇГжЩйСПЕФВЂааЯпГЬЃЌР§ШчгЕгаЫФИіЪЎСљНјжЦДІРэЦїЕФЗўЮёЦїжЛФмВЂаадЫаа24ИіЯпГЬЃЌШчЙћCPUжЇГжГЌЯпГЬЕФЛАЃЌОЭПЩвджЇГж48ИіЃЛ
ЕЋдкЯжДњгЂЮАДяgpuжаЃЌзюаЁЕФжДааЕЅдЊгЩ32ИіЯпГЬзщГЩЃЈГЦжЎЮЊЮБЯпГЬЃЌa warp of threadsЃЉЃЌШчЙћАќКЌЖрИіжДааЕЅдЊЕФвЛИіДІРэЦїПЩвджЇГж1536ИіЯпГЬВЂааЃЌФЧУДШчЙћга16ИіДІРэЦїЃЌФЧОЭПЩвдгаГЌЙ§2.4ЭђИіЯпГЬЭЌЪБдЫаа
ЯпГЬ
CPUЩЯЕФЯпГЬЭЈГЃЪЧжиСПМЖЕФЪЕЬхЃЌВйзїЯЕЭГЮЊСЫЬсЙЉЖрЯпГЬФмСІЃЌашвЊдкCPUжДааЭЈЕРПЊЦєКЭЙиБеЪБНјааЯпГЬЕФНЛЛЛЃЌЖјНЛЛЛСНИіЯпГЬЪ§ОнЪБЕФЩЯЯТЮФЧаЛЛЪЧЛКТ§ЕФЃЛ
ЯрБШжЎЯТЃЌGPUЕФЯпГЬОЭКмЧсСПМЖЁЃдквЛИіЕфаЭЕФЯЕЭГжаЃЌЩЯЧЇИіЮБЯпГЬ(УПИіЮБЯпГЬАќРЈ32ИіЯпГЬ)дкХХЖгЕШД§ЙЄзїЁЃШчЙћgpuвЛЖЈвЊЕШвЛИіЮБЯпГЬЭъГЩЃЌЫћОЭЛсжДааБ№ЕФЮБЯпГЬЁЃгЩгкЫљгаЕФЛюЖЏЯпГЬЖМБЛЗжХфСЫЖРСЂЕФМФДцЦїЃЌжБЕНЫќУЧЭъГЩШЮЮёЪБВХЪЭЗХЃЌЫљвдgpuЯпГЬжЎМфНЛЛЛЪ§ОнЪБВЛашвЊМФДцЦїЕФНЛНгЛђепБ№ЕФЙЄзїЁЃ
МђЖјбджЎЃЌcpuКЫЕФЩшМЦЪЧвЛДЮадЮЊвЛИіЛђСНИіЯпГЬзюаЁЛЏбгГйЃЌЕЋgpuЪЧгУРДДІРэДѓСПВЂЗЂЁЂЧсСПМЖЯпГЬвдзюДѓЛЏЭЬЭТСПЁЃ
ФкДц
жїЛњЯЕЭГКЭЩшБИЯЕЭГгЕгаЖРСЂЕФЮяРэФкДцЃЌЭЈЙ§PCIзмЯпЯрСЌЁЃСНПщФкДцБиаыЪБВЛЪБЯрЛЅНЛСїЃЌетвЛЕуЛсдкЯТвЛНкgpuЩшБИЩЯдЫааЕФЖЋЮїжаУшЪі
Г§СЫетМИЕуЕФжївЊВюБ№ЭтЃЌСэЭтвЛаЉВювьЛсдкГіЯжЪБНВНтЁЃЪЙгУGPU-CPUНјаавьЙЙЕФгІгУПЩвдзлКЯПМТЧжїЛњЯЕЭГКЭЩшБИЯЕЭГЃЌвдШУЫќУЧЖМФмЙЛИїОЁЦфд№ЃЌвВОЭЪЧШУCPUДІРэДЎааШЮЮёЃЌGPUДІРэВЂааШЮЮё
gpuЩшБИЩЯдЫааЕФЖЋЮї
ЕБОіЖЈФФаЉФкШнвЊдкgpuЩЯдЫааЪБЃЌОЭашвЊПМТЧЯТУцФкШнЃК
- ЩшБИЯЕЭГЪЪКЯЭЌЪБдкДѓСПЪ§ОндЊЫиЩЯжДааЕФМЦЫуЃЌАќРЈдкДѓаЭЪ§ОнМЏЃЈР§ШчОиеѓЃЉЩЯУцЕФЪ§бЇдЫЫуЃЌетжждЫЫувЊЭЌЪБдкЩЯЧЇЃЈЖјВЛЪЧЩЯАйЭђЃЉИіЪ§ОндЊЫиЩЯжДааЁЃвђДЫЃЌШчЙћЮвУЧЕФДњТыашвЊЪЙгУГЩЧЇЩЯЭђИіВЂааЯпГЬЪБЃЌОЭПЩвдПМТЧАбЫќУЧЗХЕНgpuЩшБИЩЯЃЛ
- дкЩшБИЯЕЭГжадЫааЕФЯрСкЯпГЬгІИУдкФкДцЗУЮЪЩЯгавЛаЉвЛжТадЁЃЙЬЖЈЕФФкДцЗУЮЪФЃАхПЩвдШУгВМўАбЖрзщЪ§ОнЕФЖСаДКЯВЂЕНвЛИіВйзїРяЃЌетУДзіЪЧвђЮЊЪ§ОнВЛФмВ№ЗжЃЌЖјЧвЪ§ОнСПДѓЕФЛАОЭУЛгазуЙЛЕФБОЕиадРДгааЇЪЙгУL1ЛђепЮЦРэЛКДцЃЌвджСгкНЕЕЭcudaЕФМгЫйадФмЃЛ
- ЪЙгУcudaЪБЃЌЪ§ОнжЕБиаыЭЈЙ§PCIзмЯпДгжїЛњИДжЦЕНЩшБИжаЁЃетжжИДжЦгаЫ№гкадФмвђДЫгІИУБЛзюаЁЛЏЃЌЗжЮЊвдЯТМИжжЧщПі
1ЁЂБЛЩйСПЯпГЬЖЬднЪЙгУЕФЪ§ОнВЛЪЪКЯдкжїЛњКЭЩшБИжЎМфРДЛиИДжЦЃЌвђЮЊПЊЯњДѓгкЪевцЁЃеце§гІИУИДжЦЪ§ОнЕФГЁОАгІИУЪЧЕБДѓСПЯпГЬжДааИДдгЙЄзїЪБЃЌВХНјааЪ§ОндкжїЛњКЭЩшБИжЎМфЕФИДжЦЁЃБШШчЖдгкСНИіN*NЕФОиеѓЃЌШчЙћвЊзіОиеѓМгЗЈЃЌФЧУДДгСНИідДОиеѓИДжЦИјcudaЕННсЙћОиеѓИДжЦЛижїЛњЃЌзмЙВга3N^2ИіЪ§ОнЛсНјааДЋЪфЃЌЖјОиеѓМгЗЈБОЩэЕФЪБМфИДдгЖШЪЧO(N^2)ЃЌвђДЫВйзїКЭЧЈвЦЕФЪБМфИДдгЖШБШЮЊ1:3ЁЃетИіБШжЕдНДѓЃЌЪ§ОнЧЈвЦДјРДЕФКУДІОЭдНУїЯдЃЌР§ШчАбОиеѓМгЗЈЛЛГЩОиеѓГЫЗЈЃЈЪБМфИДдгЖШЮЊO(N^3)ЃЉЃЌЪБМфИДдгЖШБШжЕОЭГЩСЫNЃЌетИіЪевцЛсЫцзХОиеѓЕФЙцФЃЕФдіДѓЖјдіДѓЁЃВЛЭЌЕФВйзїгаВЛЭЌЕФИДдгЖШЃЌвђДЫдкОіЖЈЪЧЗёвЊжДааЪ§ОндкжїЛњКЭЩшБИжЎМфЕФДЋЪфЪБЃЌвЊжДааЕФВйзїЪЧЮвУЧПМТЧЕФживЊвђЫижЎвЛЃЛ
2ЁЂ ШчЙћЗЂЩњСЫЪ§ОнЧЈвЦЃЌФЧУДЪ§ОндкЩшБИЩЯЭЃСєЕФЪБМфдНГЄдНКУЃЈвВОЭЪЧЪ§ОнДЋЪфВЛвЊЬЋЦЕЗБЃЉЁЃГЬађдкЖрИіКЫЩЯВйзївЛзщЪ§ОнЪБЃЌгІИУдкСНИіКЫКЏЪ§ЕїгУжЎМфШУЪ§ОнвЛжБСєдкЩшБИЩЯЃЌЖјВЛЪЧНЋжаМфНсЙћдкжїЛњКЭЩшБИМфРДЛиЧЈвЦЁЃЖдгкЧАУцЕФР§згЃЌШчЙћвЊЯрМгЕФСНИіОиеѓЪЧЧАжУМЦЫуЕФНсЙћЃЌЛђепЯрМгЕФНсЙћвЊБЛКѓајМЦЫуЪЙгУЃЌФЧУДОиеѓМгЗЈгІИУдкЩшБИЩЯБЛБОЕижДааЁЃМДБуађСаМЦЫужаЕФФГвЛВНдкжїЛњЩЯжДааИќПьЃЌЮвУЧвВвЊОЁСПБмУтЪ§ОнЕФЧЈвЦЃЌвђЮЊЪ§ОнЧЈвЦДјРДЕФадФмЫ№ЪЇПЩФмЛсЕжЯћЮЊСЫФГвЛВНИќПьЕФМЦЫуЖјДјРДЕФЪевцЃЌИќЯъЯИЕФНВНтЧыВЮМћжїЛњКЭЩшБИжЎМфЕФЪ§ОнЧЈвЦвЛеТЁЃ
гІгУЗжЮі
вЛИігІгУПЩвдЗжЮЊЪ§ИіФЃПщЃЌУПИіФЃПщгУвЛаЁЖЮДњТыЭъГЩвЛИіЙІФмЁЃЪЙгУЗжЮіЦїЃЌПЊЗЂепПЩвдЪЖБ№ГіШШЕуДњТыДгЖјПЊЪМБрвыКђбЁЖдЯѓЃЌвдЙЉВЂааЛЏЕФЪЕЯж
ЗжЮі
ЪзЯШЮвУЧвЊЪЙгУЙЄОпШЅЗжЮіЮвУЧЕФПЩжДааГЬађЃЌР§ШчПЩвдЪЙгУLinuxздДјЕФgprofЁЃвджЎЧАБрвыЕФrodiniaВтЪдбљР§ЮЊР§ЃЌНВНтвЛЯТдѕУДЪЙгУЫќЁЃЪЙгУgprofЪБЃЌвЊЯШдкБрвыбЁЯюжаМгШы-pgВЮЪ§(ПЩвдаоИФMakefileЃЌвВПЩвддкgccЛђg++КѓУцЬэМг-pg)
CC_FLAGS = -g -fopenmp -O2 -pgШЛКѓе§ГЃБрвыЃЌдЫаа(БиаыЯШдЫааВХФмЗжЮі)
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# gcc -g -fopenmp -O2 -c kmeans.c
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# make
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# ./kmeans -i ../../data/kmeans/204800.txtДЫЪБЛсдкЕБЧАФПТМЯТЩњГЩgmon.outЃЌетОЭЪЧЗжЮіКУЕФЮФМў
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# ll
total 2104
drwxrwxrwx 2 root root 4096 11дТ 2 20:30 ./
drwxrwxrwx 25 root root 4096 11дТ 2 08:59 ../
-rwxrwxrwx 1 root root 7712 12дТ 11 2015 cluster.c*
-rw-r--r-- 1 root root 10440 11дТ 2 20:29 cluster.o
-rwxrwxrwx 1 root root 39978 12дТ 11 2015 getopt.c*
-rwxrwxrwx 1 root root 6854 12дТ 11 2015 getopt.h*
-rw-r--r-- 1 root root 4920 11дТ 2 20:29 getopt.o
-rw-r--r-- 1 root root 3527 11дТ 2 20:30 gmon.out
-rwxr-xr-x 1 root root 65344 11дТ 2 20:29 kmeans*
-rwxrwxrwx 1 root root 13058 12дТ 11 2015 kmeans.c*
-rwxrwxrwx 1 root root 8621 12дТ 11 2015 kmeans_clustering.c*
-rw-r--r-- 1 root root 12304 11дТ 2 20:29 kmeans_clustering.o
-rwxrwxrwx 1 root root 10890 12дТ 11 2015 kmeans_cuda.cu*
-rwxrwxrwx 1 root root 5739 12дТ 11 2015 kmeans_cuda_kernel.cu*
-rw-r--r-- 1 root root 25024 11дТ 2 20:29 kmeans_cuda.o
-rwxrwxrwx 1 root root 3463 12дТ 11 2015 kmeans.h*
-rw-r--r-- 1 root root 1790384 11дТ 2 20:29 kmeans.h.gch
-rw-r--r-- 1 root root 29352 11дТ 2 20:29 kmeans.o
-rwxrwxrwx 1 root root 755 11дТ 2 20:28 Makefile*
-rwxrwxrwx 1 root root 2145 12дТ 11 2015 Makefile_nvidia*
-rw-r--r-- 1 root root 6169 11дТ 2 20:30 profile.txt
-rwxrwxrwx 1 root root 591 12дТ 11 2015 README*
-rwxrwxrwx 1 root root 3031 12дТ 11 2015 rmse.c*
-rw-r--r-- 1 root root 15152 11дТ 2 20:29 rmse.o
-rwxrwxrwx 1 root root 42 12дТ 11 2015 run*
-rwxrwxrwx 1 root root 28418 12дТ 11 2015 unistd.h*ШЛКѓЪЙгУgprofЖдИеИедЫааЕФПЩжДааЮФМўНјааЗжЮіЃЌАбНсЙћжиЖЈЯђЕНprofile.txtжа
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# gprof ./kmeans > profile.txtзюКѓВщПДвЛЯТНсЙћ
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# cat profile.txt
Flat profile:Each sample counts as 0.01 seconds.% cumulative self self total
time seconds seconds calls Ts/call Ts/call name
100.06 0.01 0.01 kmeansCuda0.00 0.01 0.00 1 0.00 0.00 cluster0.00 0.01 0.00 1 0.00 0.00 kmeans_clustering
....Call graph (explanation follows)granularity: each sample hit covers 2 byte(s) for 99.94% of 0.01 secondsindex % time self children called name<spontaneous>
[1] 100.0 0.01 0.00 kmeansCuda [1]
-----------------------------------------------0.00 0.00 1/1 setup [16]
[2] 0.0 0.00 0.00 1 cluster [2]0.00 0.00 1/1 kmeans_clustering [3]
-----------------------------------------------0.00 0.00 1/1 cluster [2]
[3] 0.0 0.00 0.00 1 kmeans_clustering [3]
-----------------------------------------------
....
Index by function name[2] cluster [1] kmeansCuda [3] kmeans_clustering
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans#ПЩвдПДЕНИїИіКЏЪ§ЕФжДааЧщПіЃЌУїАкзХkmeansCudaМИКѕеМгУСЫШЋВПЕФжДааЪБМфЃЌвђДЫетИіКЏЪ§ОЭЪЧЮвУЧЕФШШЕуДњТыЁЃ
дЫаадкcudaЩЯЕФгІгУГЬађЕФадФмЬсЩ§ЭъШЋШЁОігкЫќЕФВЂааЛЏГЬЖШЃЌвђДЫВЛФмГфЗжВЂааЛЏЕФДњТыгІИУдЫаадкCPUЩЯЃЌГ§ЗЧетУДзіЛсЕМжТCPUКЭGPUжЎМфЭЈаХДјРДЕФЖюЭтПЊЯњЁЃ
ЫѕЗХ
РэНтгІгУПЩвдШчКЮЫѕЗХгаРћгкЮвУЧЩшжУЦкЭћВЂЙцЛЎГідіСПВЂааЛЏЕФМЦЛЎЁЃгІгУЫѕЗХЗжЮЊЧПЫѕЗХКЭШѕЫѕЗХЁЃ
ЧПЫѕЗХ
ЧПЫѕЗХгУРДВтСПдкЮЪЬтЙцФЃЙЬЖЈЕФЧщПіЯТЃЌНтОіЗНАИЕФКФЪБЪЧШчКЮЫцзХДІРэЦїЕФдіМгЖјМѕЩйЕФЁЃБэЯжЮЊЯпадЧПЫѕЗХЕФгІгУЕФМгЫйаЇЙћПЩвдЫцзХДІРэЦїЕФЪ§СПЕФдіМгЖјдіМгЁЃ
ЧПЫѕЗХЭЈГЃКЭАЂБШДяЖћЖЈТЩСЊЯЕдквЛЦ№ЁЃАЂБШДяЖћЖЈТЩжИУїСЫЭЈЙ§ВЂааЛЏвЛИіДЎааГЬађЕФВЛЭЌВПЗжПЩвдДяЕНЕФзюДѓМгЫйЦкЭћжЕSЃЌЦфЙЋЪНШчЯТЭМЫљЪО
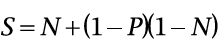
ЦфжаЃЌPБэЪОећИіДЎааГЬађжаПЩВЂааДњТыЕФжДааЪБГЄЃЌNБэЪОДІРэЦїЪ§СПЁЃЯдШЛЃЌNдНДѓЃЌP/NдНаЁЃЌШчЙћNЗЧГЃДѓЃЌSОЭГЩСЫ1/(1 - P)ЁЃФЧУДДЫЪБЃЌШчЙћЕБЧАЕФДЎааГЬађжага3/4ПЩвдБЛВЂааЛЏЃЌЦфзюДѓМгЫйжЕSОЭЮЊ4ЁЃ
жЛПЩЯЇЃЌЯжЪЕжаЕФгІгУВЂВЛБэЯжЮЊЭъШЋЕФЯпадЧПЫѕЗХЃЌгІгУРяБэЯжЮЊЯпадЧПЫѕЗХЕФВПЗжвВВЛЖрЁЃЕЋМДБуШчДЫЃЌЮвУЧвВПЩвдДгАЂБШДяЖћЖЈТЩжаЗЂЯжЃЌГЬађжаПЩВЂааВПЗжеМШЋВПДњТыЕФБШТЪPдНДѓЃЌМгЫйжЕОЭдНДѓЁЃШчЙћPКмаЁЃЌДІРэЦїЪ§СПNдйЖрвВЪЧЭїШЛЁЃвђДЫЃЌЖдгквЛИіЙЬЖЈЙцФЃЕФЮЪЬтЃЌЮвУЧгІИУдіДѓPжЕЃЌвВОЭЪЧОЁПЩФмШУЮвУЧГЬађжаПЩВЂаажДааЕФВПЗждіЖрЁЃ
ШѕЫѕЗХ
гаЧПОЭгаШѕЃЌШѕЫѕЗХгУРДВтСПзмЬхЮЪЬтЙцФЃЫцзХДІРэЦїЪ§СПЕФдіМгЖјдіДѓЕФЧщПіЯТЃЌНтОіЗНАИКФЪБЕФБфЛЏЧщПіЁЃзЂвтгавЛИіЧАЬсЃЌФЧОЭЪЧЫфШЛзмЬхЮЪЬтЕФЙцФЃЫцзХДІРэЦїЪ§СПЕФдіМгЖјдіДѓЃЌЕЋЪЧЕЅИіДІРэЦївЊДІРэЕФЮЪЬтЙцФЃЪЧВЛБфЕФЁЃ
ШѕЫѕЗХЭЈГЃКЭЙХЫЙЫўЗђЩЖЈТЩСЊЯЕдквЛЦ№ЁЃЙХЫЙЫўЗђЩЖЈТЩжИУїСЫдкЮЪЬтЙцФЃЫцзХДІРэЦїЪ§СПЕФдіДѓЖјдіДѓЪБЃЌзюДѓМгЫйжЕSЕФБфЛЏЧщПіЃЌЦфЙЋЪНШчЯТЭМЫљЪО
PКЭNЕФКЌвхЛЙЪЧКЭАЂБШДяЖћЖЈТЩжаЕФвЛбљЃЌЗжБ№БэЪОећИіДЎааГЬађжаПЩВЂааДњТыЕФжДааЪБГЄКЭДІРэЦїЪ§СПЁЃ
ЙХЫЙЫўЗђЩЖЈТЩБэУїЃЌЫцзХЯЕЭГЙцФЃЕФдіДѓЃЌЯожЦЮвУЧЕФВЛЪЧЮЪЬтЙцФЃЖјЪЧжДааЪБМфЁЃСэЭтЃЌЙХЫЙЫўЗђЩЖЈТЩМйЩшПЩВЂаажДааДњТыеМзмГЬађЕФБШжиЪЧЙЬЖЈЕФЃЌДгЖјЗДгГСЫУцЖдЙцФЃНЅГЄЕФЮЪЬтЪБВњЩњЕФЖюЭтЕФЩшжУКЭДІРэПЊЯњ
гІгУ
ЖдгквЛИігІгУЖјбдЁЃРэНтЫќЪЪКЯФФжжЫѕЗХЖдгкЦРЙРЫќЕФзюДѓМгЫйжЕКмживЊЁЃЖдгквЛаЉЮЪЬтЙцФЃВЛБфЕФгІгУЃЌЯдШЛжЛЪЪгУЧПЫѕЗХЃЌвЛИіР§згОЭЪЧЮЊСНИіЗжзгМфЕФЗДгІНЈФЃЃЌетРяЮЪЬтЙцФЃЯдШЛЪЧЙЬЖЈЕФЃЛЖдгкСэЭтвЛаЉЮЪЬтЃЌЫќУЧЕФЙцФЃЛсЫцзХДІРэЦїЕФдіМгЖјдіДѓЃЌР§ШчАбСїЬхЛђНсЙЙЬхНЈФЃГЩЭјИёЛђЭјТчЃЌВЂНјаавЛаЉУЩЬиПЈТхФЃФтЃЌДЫЪБЮЪЬтЙцФЃЕФдіМгЛсЬсЙЉИќИпЕФОЋШЗЖШЁЃ
ЕБЮвУЧЩњГЩВЂЗжЮіКУСЫЮвУЧЕФГЬађКѓЃЌЮвУЧОЭгІИУЗжЮіШчЙћДІРэЦїЪ§СПИФБфЃЌЮвУЧЕФЮЪЬтЙцФЃЛсШчКЮБфЛЏЃЌДгЖјгІгУАЂБШДяЖћЛђепЙХЫЙЫўЗђЩЖЈТЩРДМЦЫуМгЫйжЕЕФЩЯЯоЁЃ
ВЂааЛЏ
ЖЈЮЛКУСЫШШЕуДњТыКЭЬсЩ§ФПБъЃЌПЊЗЂепОЭвЊЖдДњТыНјааВЂааЛЏЁЃИљОндЪМДњТыЕФВЛЭЌЃЌВЂааЛЏЗНЗЈгаСНжжЃКЕїгУЯжГЩЕФGPUгХЛЏПт(cuBLASЁЂcuFFTЛђThrust)КЭЬэМгдЄДІРэжИСю(hintЕШ)вдВЂааЛЏБрвыЦїЁЃ
СэЭтЃЌвЛаЉгІгУПЩФмвЊзівЛаЉЩшМЦЩЯЕФжиЙЙЃЌвдЬНЫїЛђПЊЗЂВЂааЖШЃЌЩѕжСCPUМмЙЙЮЊСЫЬсИпЛђепБЃГжЫГађгІгУЕФБэЯжСІЃЌвВвЊЖдВЂааЖШНјааЬНЫїЃЌЖјCUDAЕФВЂааБрГЬгябд(CUDAЕФc/c++ЁЂfortranЕШ)жМдкОЁПЩФмМђЕЅЕиУшЪіетжжВЂааЖШЃЌЭЌЪБдкжЇГжcudaЕФgpuЩшБИЩЯПЊЦєЖдгІЕФВйзївдзюДѓЛЏВЂааЭЬЭТСПЁЃ
ЮвУЧПЩвдЪЙгУвЛаЉЙиМќВпТдРДНЋДЎааДњТыВЂааЛЏЃЌЕЋЪЧОпЬхШчКЮгІгУОЭЪЧвЛИіИДдгЧвОпЬхЕФЮЪЬтСЫЃЌетРяЖдетаЉВпТдНјааМђНщ
ВЂааЛЏПт
НЋгІгУВЂааЛЏЕФзюжБНгЗНЗЈОЭЪЧЪЙгУcudaЬсЙЉЕФЯжГЩПтЃЌетаЉПтЪЙгУСЫгЂЮАДяЕФВЂааМмЙЙЁЃcudaЙЄОпАќЬсЙЉСЫДѓСПгУРДдкгЂЮАДяgpuЩЯНјааЖдЯюФПЯИСЃЖШЕїећЕФПтЃЌБШШчcuBLASЁЂcuFFTЕШЁЃЕБетаЉПтЭъУРЦЅХфгІгУЕФашЧѓЪБЃЌЫќУЧЕФгУДІОЭКмДѓЁЃР§ШчЃЌЪЙгУСЫБ№ЕФBLASПтЕФГЬађПЩвдКмШнвзЕизЊЕНcuBLASЃЌОЁЙмЛљБОВЛЪЙгУЯпадДњЪ§ЕФгІгУвВВЛдѕУДЪЙгУcuBLASЁЃЭЌбљЃЌcuFFTКЭFFTWвВгазХЯрЫЦЕФНгПкЁЃ
СэЭтвЛИіжЕЕУзЂвтЕФЪЧThrustЃЌетЪЧвЛИіКЭБъзМC++ФЃАхПтЯрЫЦЕФВЂааC++ФЃАхПтЃЌЫќЬсЙЉСЫДѓСПЪ§ОнВЂааВйзїБШШчscanЁЂsortЁЂreduceЕШЃЌЮвУЧПЩвдАбетаЉКЏЪ§зщКЯдквЛЦ№РДгУМђУїПЩЖСЕФДњТыЪЕЯжИДдгЕФЫуЗЈЁЃЭЈЙ§гУетаЉИпГщЯѓЕФКЏЪ§РДУшЪіЮвУЧЕФЫуЗЈЃЌЮвУЧПЩвдШУThrustздЖЏбЁдёзюгааЇЕФЪЕЯжЁЃНсЙћОЭЪЧЃЌЮвУЧПЩвдЪЙгУThrustРДбИЫйЙЙдьcudaгІгУЕФдаЭЃЌЭЌЪББЃжЄДњТыЕФБэЯжСІКЭТГАєад
ВЂааЛЏБрвыЦї
ВЂааЛЏДЎааДњТыЕФСэвЛжжГЃгУЗНЗЈОЭЪЧЪЙгУВЂааБрвыЦїЃЌвЛАуетвтЮЖзХЮвУЧвЊЪЙгУЛљгкжИСюЕФЗНЗЈЃЌетаЉЗНЗЈШУГЬађдБЪЙгУ#pragmaЛђепЦфЫћРрЫЦЕФзЂНтРДИјБрвыЦїжИУїФФаЉДњТыдкВЛгУаоИФЕФЧщПіЯТОЭПЩвдЪЙгУВЂааБрвыЃЌШЛКѓБрвыЦїОЭЪЙгУЯрЙижИСюРДАбМЦЫугГЩфЕНВЂааМмЙЙжа
OpenACCБъзМЬсЙЉСЫвЛЯЕСаЕФБрвыжИСюРДАбC/C++ЁЂFortranжаЕФбЛЗКЭДњТыЖЮДгCPUжааЖдиЕНCUDA GPUетбљЕФМгЫйЦїжаЃЌЕЋЯрЙиЯИНкБЛвўВидкСЫжЇГжOpenACCЕФБрвыЦїКЭдЫааЛЗОГжа
ВЂааЛЏДњТы
ЖдгкФЧаЉвЊЧѓЯжДцВЂааПтЛђВЂааБрвыЦїВЛФмЬсЙЉЕФКЏЪ§ЕФгІгУЃЌЮвУЧПЩвдЪЙгУВЂааБрГЬгябдБШШчcuda c/c++РДАбЯжгаДњТыЮоЗьзЊЛЛГЩВЂааДњТыЁЃвЛЕЉЮвУЧдкгІгУЗжЮіжаЖЈЮЛСЫШШЕуДњТыВЂЧвШЗЖЈаоИФДњТыЪЧзюКУЕФЗНЗЈЃЌЮвУЧПЩвдЪЙгУcuda c/c++РДАбЮвУЧЕФШШЕуДњТыВЂааЛЏЮЊcudaКЫЁЃЖјКѓЮвУЧПЩвдАбетИіКЫЦєЖЏЕНgpuЩЯЃЌШЛКѓдкВЛашвЊЖдЪЃЯТДњТыНјааДѓСПжиаДЕФЧщПіЯТЛёЕУНсЙћЁЃ
ЕБЮвУЧЕФгІгУдЫааЪБМфДѓВПЗжЛЈдкМИИіЯрЖдЖРСЂЕФВПЗжЩЯЪБЃЌетИіЗНЗЈЪЧзюЮЊжБНгЕФЁЃЯрЗДЃЌЖдгкФЧаЉдкВЛЭЌВПЗжЩЯдЫааКФЪБЯрЖдЦНОљЕФгІгУЃЌетИіЗНЗЈОЭВЛЬЋКУЪЙЁЃЖдгкетжжЧщПіЃЌвЛЖЈГЬЖШЩЯЕФДњТыжиЙЙПЩвдАяжњЮвУЧЬсИпВЂааадЃЌЕЋМЧзЁетжжжиЙЙЙЄзїгІИУгаРћгкЫљгаМмЙЙЕФЮДРДЗЂеЙЃЌВЛНіЪЧCPUМмЙЙЃЌвВвЊПМТЧGPUМмЙЙЁЃ
ЕУЕНе§ШЗЕФНсЙћ
ЫљгаЕФМЦЫуШЮЮёЖМЪЧЮЊСЫЕУЕНе§ШЗЕФНсЙћЃЌЕЋЪЧдкВЂааЯЕЭГжаЃЌЮвУЧПЩФмгіЕНдкДЎааЯЕЭГжаВЛдјгіЕНЕФЮЪЬтЃЌАќРЈЃКЯпГЬЮЪЬтЁЂгЩгкИЁЕужЕМЦЫуЗНЗЈЖјЕМжТЕФвьГЃжЕЁЂвдМАВйзїCPUКЭGPUЗНЪНЕФВЛЭЌЖјв§ЗЂЕФЮЪЬтЕШЃЌетвЛеТНЋЛсМьбщетаЉгАЯьЗЕЛиЪ§Оне§ШЗадЕФЮЪЬтЃЌВЂжИГіКЯЪЪЕФНтОіЗНЗЈ
бщжЄ
ЖдгкШЮКЮГЬађаоИФЃЌвЛИіе§ШЗадбщжЄЕФЙиМќЗНЗЈОЭЪЧНЈСЂвЛаЉЛњжЦЃЌдкетжжЛњжЦжаЃЌЮвУЧПЩвдЪЙгУжЎЧАОпгаДњБэадЕФЪфШыВњЩњЕФе§ШЗЪфГіРДКЭаТЕФНсЙћзїБШНЯЁЃдкУПвЛДЮДњТыИќИФКѓЃЌЮвУЧЖМвЊБЃжЄдкФГИібщжЄЛњжЦЯТЃЌЪЙгУШЮКЮЦРХаБъзМЖМПЩвдЕУЕНЦЅХфЕФНсЙћЁЃгаЪБашвЊЪЕМЪжЕКЭдЄЦкжЕгаЮЛМЖБ№ЕФЯрЕШЃЌОЁЙметдкЪЙгУИЁЕудЫЫуЪБОЭгаЕуЖљВЛЯжЪЕЁЃБ№ЕФЫуЗЈОЭПЩФмвЊЧѓЪЕМЪжЕКЭдЄЦкжЕдквЛЖЈЗЖЮЇФкЯрЕШМДПЩЃЌвВОЭЪЧгавЛЖЈЕФШнДэЖШЁЃ
ЩЯУцЙигкбщжЄЪ§зжНсЙћЕФЗНЗЈвВПЩвдБЛРЉеЙЕНбщжЄБэЯжадЕФНсЙћЩЯЃЌвВОЭЪЧЫЕЮвУЧвЊШЗЖЈЮвУЧзіЕФУПИіИФБфВЛЕЋЪЧе§ШЗЕФЃЌЖјЧвЬсИпСЫБэЯжСІЃЈгаЪБЛЙашвЊСПЛЏЃЉЁЃдкЮвУЧЕФAPODбЛЗжаЧЖШыетаЉМьВщгажњгкШЗБЃЮвУЧОЁПьЕиДяЕНдЄЦкаЇЙћ
Г§СЫБШНЯНсЙћКЭБэЯжСІЃЌЮвУЧПЩвдЮЂЙлЕНдкДњТыНсЙЙжаНјааЕЅдЊВтЪдЁЃР§ШчЃЌЮвУЧПЩвдАбКмЖр__device__КЏЪ§аДГЩвЛИіcudaКЫ(ЖјВЛЪЧвЛИіДѓЕФ__global__КЏЪ§)ЃЌетбљУПИі__device__КЏЪ§ПЩвддкАбЫќУЧећКЯЕНвЛЦ№жЎЧАНјааЖРСЂЕФВтЪдЁЃ
Р§ШчЃЌаэЖрКЫГ§СЫзїЪЕМЪЕФМЦЫуЭтЃЌЛЙгаКмЖрИДдгЕФШЁжЗТпМРДВйзїФкДцЁЃШчЙћЮвУЧдкжДааМЦЫуВПЗжЧАОЭЗжБ№ЕиВтЪдСЫШЁжЗТпМЃЌКѓајЕФЕїЪдЙЄзїОЭПЩвдБЛМђЛЏЁЃзЂвтЃЌШчЙћШЮКЮ__device__КЏЪ§УЛгаЭљШЋОжФкДцжааДШыЪ§ОнЕФЛАЃЌЫќОЭЛсБЛcudaБрвыЦїШЯЮЊЪЧПЩвдКіТдЕФЫРЭіДњТыЃЌвђДЫЮвУЧБиаыжСЩйАбЮвУЧЕФШЁжЗТпМЕФНсЙћаДЕНШЋОжФкДцжаЃЌетбљвВПЩвдДяЕНЕїЪдШЁжЗТпМЕФФПЕФЁЃ
ИќНјвЛВНЃЌШчЙћКЏЪ§БЛЖЈвхЮЊ__host__ __device__ЖјВЛЪЧжЛга__device__ЃЌетОЭвтЮЖзХЫќдкCPUКЭGPUЩЯЖМПЩвдБЛВтЪдЃЌДгЖјЮвУЧПЩвдЖдКЏЪ§НсЙћЕФе§ШЗадИќгааХаФЃЌвђЮЊДЫЪБвьГЃжЕГіЯжЕФИХТЪЛсИќДѓЃЌаоИФжЎКѓДњТыЕФе§ШЗадвВОЭИќДѓЁЃЭЌЪБЃЌетжжЩљУївВМѕЩйСЫЮвУЧГЬађжаЕФжиИДДњТыЃЌвђЮЊ__host__ __device__КЏЪ§ПЩвдБЛcpuДњТыКЭgpuДњТыЕїгУЃЌетОЭБмУтСЫСНИіКЏЪ§жЛгаЩљУїВЛвЛбљ(вЛИіЪЧ__device__ЃЌвЛИіЪЧ__host__)ЕФЧщПіЃЌДгЖјМђЛЏДњТыЁЃ
ЕїЪд
CUDA-GDBЪЧGNUЕїЪдЦїЕФвЛВПЗжЃЌЯъЧщВЮМћhttp://developer.nvidia.com/cuda-gdb
Ъ§зжНсЙћЕФзМШЗадКЭОЋШЗЖШ
ВЛе§ШЗЕФЪ§жЕНсЙћжївЊЪЧвђЮЊИЁЕуЪ§МЦЫуКЭДцДЂЗНЪНЕМжТЕФИЁЕуЪ§ОЋЖШЮЪЬтв§ЗЂЕФЃЌетвЛНкНЋНВНтЩцМАЕФжївЊЗНУцЃЌвВПЩвдВЮПМCUDA C PRAGRAMMING GUIDEжаFeatures and Technical SpecficationsеТНк
ЕЅОЋЖШКЭЫЋОЋЖШ
МЦЫуФмСІ>=1.3ЕФЩшБИЬсЙЉСЫЫЋОЋЖШИЁЕужЕЕФБОЕижЇГжЃЌЪЙгУЫЋОЋЖШМЦЫуЕУЕННсЙћЭЈГЃЛсКЭЪЙгУЕЅОЋЖШМЦЫуЕУЕНЕФНсЙћВЛЭЌЃЌетЪЧгЩЫЋОЋЖШгаИќИпЕФОЋШЗадвдМАЯрЙиЕФЩсШыЖјЕМжТЕФЁЃвђДЫЃЌЮвУЧгІИУБШНЯдкЯрЭЌОЋШЗЖШЯТЕФЕФжЕЃЌВЂЧввЊгавЛЖЈЕФШнДэадЁЃ
ИЁЕудЫЫуВЛТњзуНсКЯТЩ
гЩгкУПИіИЁЕудЫЫуВйзїЖМАќКЌвЛЖЈСПЕФЩсШыЃЌвђДЫжДаадЫЫуВйзїЕФЫГађОЭИёЭтживЊЁЃШчЙћAЃЌBЃЌCЪЧИЁЕуЪ§ЃЌФЧУД(A + B) + CВЛФмБЃжЄЕШгкA + (B + C)ЃЌвђДЫЕБЮвУЧВЂааЛЏМЦЫуЪБЃЌвЛЕЉЮовтжаИФБфВйзїЕФЫГађЃЌФЧУДПЩФмОЭЛсЕМжТКЭДЎаажДааНиШЛВЛЭЌЕФНсЙћЁЃетЪЧИЁЕудЫЫуЕФЙЬгаЪєадЃЌВЂВЛОжЯогкcuda
ЕЅЫЋОЋЖШжЎМфЕФзЊЛЛ
ЕББШНЯИЁЕуБфСПдкжїЛњКЭЩшБИЩЯЕФдЫЫуНсЙћЪБЃЌШчЙћГіЯжашвЊдкжїЛњЩЯДгЕЅОЋЖШзЊЛЛЕНЫЋОЋЖШЕФЧщПіЃЌШЗБЃетвЛЕуВЛЛсЖдНсЙћВњЩњгАЯьЁЃР§ШчЃЌШчЙћДњТыfloat a; ....; a = a * 1.02;дкМЦЫуФмСІ<=1.2ЛђепМЦЫуФмСІ>1.2ЕЋУЛгаПЊЦєЫЋОЋЖШжЇГжЕФЛАЃЌГЫЗЈВйзїОЭЛсдкЕЅОЋЖШЩЯжДааЁЃЕЋЪЧШчЙћетЖЮДњТыдкжїЛњЩЯжДааЃЌзжУцСП1.02ОЭЛсБЛНтЪЭГЩЫЋОЋЖШЃЌБфСПaвВЛсДгЕЅОЋЖШзЊЛЛГЩЫЋОЋЖШЃЌГЫЗЈОЭЫцжЎЛсдкЫЋОЋЖШЯТжДааЃЌЕЋгЩгкaБОЩэЪЧЕЅОЋЖШЃЌвђДЫГЫЗЈЕФНсЙћгжЛсБЛзЊЛЛЛиЕЅОЋЖШЃЌДгЖјПЩФмЕМжТНсЙћгаЫљВЛЭЌЁЃЕЋЪЧЃЌШчЙћАб1.02ИФГЩ1.02fЃЌФЧУДдкЫљгаЧщПіЯТЩЯУцЕФЕЅЫЋОЋЖШзЊЛЛОЭВЛЛсЗЂЩњЃЌвђДЫдкЩцМАЕЅОЋЖШдЫЫуЕФЪБКђЃЌвЛЖЈвЊЪЙгУНсЮВДјfЕФзжУцСПЁЃ
СэЭтЃЌЕЅЫЋОЋЖШжЎМфЕФзЊЛЛЛЙЛсЖдадФмВњЩњВЛРћЕФгАЯьЃЌОпЬхЧыВЮМћжИСюгХЛЏвЛеТ
IEEE 754
ЫљгаЕФcudaМЦЫуЩшБИЖМзёбIEEE 754БъзМРДБэЪОЖўНјжЦИЁЕуЪ§ЃЌвВгавЛаЉаЁЕФР§ЭтЃЈВЮМћCUDA C PRAGRAMMING GUIDEжаFeatures and Technical SpecficationsеТНкЃЉЃЌетаЉР§ЭтПЩФмЛсЕМжТВњЩњЕФНсЙћКЭжїЛњЩЯбЯИёзёбIEEE 754БъзМВњЩњЕФНсЙћВЛЭЌ
ЦфжавЛИіживЊЕФЧјБ№ОЭЪЧГЫМгЛьКЯжИСюFMAЃЌетИіжИСюАбГЫЗЈМгЗЈВйзїКЯВЂЕНСЫвЛЬѕжИСюжаЃЌЦфНсЙћОГЃКЭЗжБ№жДааСНЬѕжИСюЕФНсЙћТдгаВЛЭЌ
x86жа80ЮЛЕФМЦЫу
x86ДІРэЦїдкжДааИЁЕудЫЫуЪБПЩвдЪЙгУ80ЮЛЕФРЉеЙЫЋОЋЖШБэЪОЗНЗЈЃЌЦфНсЙћЭЈГЃКЭдкcudaЩшБИЩЯНјааЕФДП64ЮЛдЫЫуВЛЭЌЁЃЮЊСЫОЁСПМѕЩйВювьЃЌПЩвдЪЙгУFLDCW x86ЛуБржИСюЛђепЕШаЇЕФЯЕЭГapiРДНЋx86ЕФCPUДІРэЦїЩшжУГЩГЃЙцЕЅЫЋОЋЖШ
гХЛЏcudaгІгУ
ЕБУПвЛТжЕФгІгУВЂааЛЏЭъГЩжЎКѓЃЌЮвУЧПЩвдзЊЯђгХЛЏгІгУЕФЪЕЯжРДЬсИпадФмЁЃгЩгкгХЛЏЗНЗЈКмЖрЃЌе§ШЗЕиРэНташЧѓПЩвдАяжњЮвУЧЩйзпвЛаЉЭфТЗЁЃШЛЖјЃЌвђЮЊAPODЪЧвЛИіећЬхЃЌЯюФПгХЛЏвВЪЧвЛИіЕќДњЕФЙ§ГЬЃЌЦфжаАќРЈШЗШЯФмЗёгХЛЏЁЂгІгУгХЛЏЁЂВтЪдгХЛЏЁЂбщжЄМгЫйЪЧЗёДяЕНетвЛбЛЗЁЃЕќДњЃЌвтЮЖзХПЊЗЂепВЛБиЛЈЗбДѓСПЕФЪБМфГЂЪдЫљгаЕФПЩФмЕФгХЛЏВпТдРДДяЕНКУЕФМгЫйаЇЙћЃЌЯрЗДЃЌгХЛЏВпТдПЩвдЫцзХЮвУЧЕФбЇЯАЖјБЛдіСПЕигІгУЁЃ
гХЛЏЕФВуУцКмЖрЃЌАќРЈАбЪ§ОнДЋЪфКЭМЦЫуВЂааДІРэвЛТЗЯђЯТЕНЯИСЃЖШЕиЮЂЕїИЁЕуВйзїађСаЃЌДЫЪБгХЛЏЙЄОпОЭКмБІЙѓЃЌвђЮЊЫќУЧФмЖдПЊЗЂепЯТвЛВНЕФгХЛЏИјГіНЈвщЁЃ
Нсгя
ЯТвЛЦЊЮФеТЗвыЕк8ЕН15еТЃЌФкШнЛсИќЖр