进阶篇―TD3(Twin Delayed DDPG)
这篇文章研究了actor-critic类算法里面消除overestimation bias的方法。同时,还研究了target network在TD update中消除累积误差的作用。
1、消除overestimation bias
与Double DQN类似,使用两个网络交替更新
由于agent每次都会选择价值高的动作,因此高估的估计误差会累积起来,因此,我们宁可低估不可高估
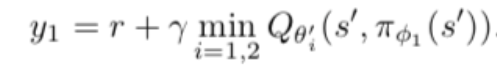
2、target network
当policy固定不变的时候,是否使用target network其价值函数都能最后收敛到正确的值;但是actor和critic同步训练的时候,不用target network可能使得训练不稳定或者发散。算法的中critic的更新目标都由target network计算出来,因此采用了delayed policy update,即以较高的频率更新价值函数,以较低的频率更新policy。
3、使用target policy smoothing regularization
希望学到的价值函数在action的维度上更平滑,因此价值函数的更新目标每次都在action上加一个小扰动
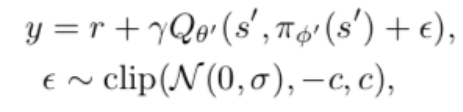
把以上三个改进综合起来,得到TD3
结果
代码参见我的GitHub
