精读 Recommending Outfits from Personal Closet
- 研究成果
- 1. 研究背景与意义
- 2. 国内外研究现状
- 3. 本文研究过程
-
- 3.1 数据收集
- 3.2 数据清洗
- 3.3 P/N样本创建
- 3.4 Train/Test数据集划分
- 3.5 服装分类流程
- 3.6 模型设置
- 4. 研究结果
论文链接:Recommending Outfits from Personal Closet
研究成果
- 本文可以对任意item组成的一套服装进行打分,并基于测试用例可以达到84%的准确率;
- 基于人为评估也可以达到91%的匹配率;
- 根据用户给定的一定数量item,然推荐服装;
- 构建了Polyvore409k 数据集
1. 研究背景与意义
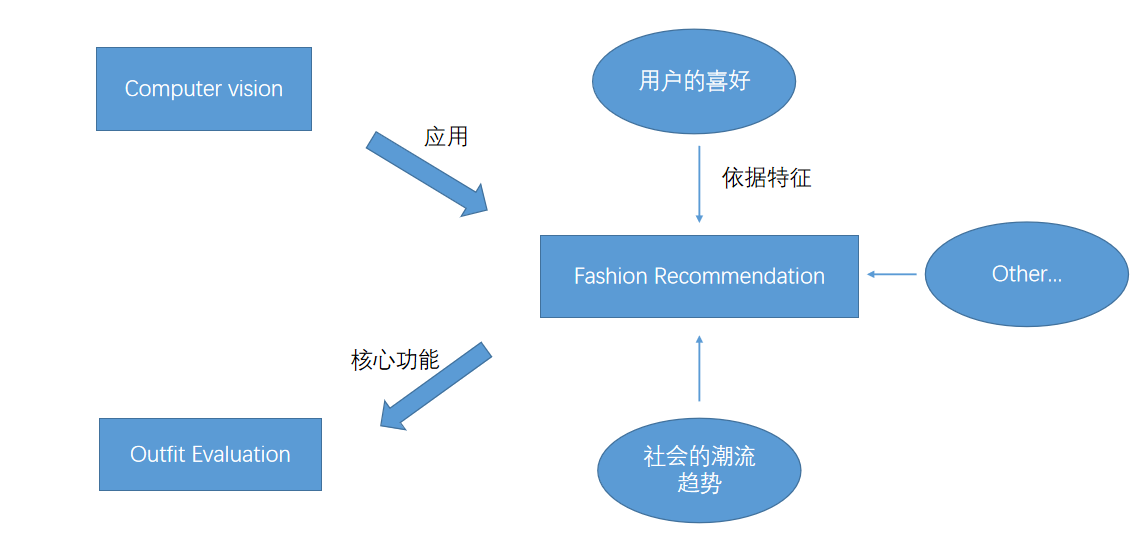
当今社会计算机视觉技术越来越"style", 而本文研究的Fashion Recommendation是它最热门的应用领域之一。
根据用户的喜好、社会的潮流趋势等一些特征,从而对时尚进行推荐。而推荐核心就是能够对Fashion进行评估,得出可靠的评价。也就是本文研究的重点Outfit Evaluation。
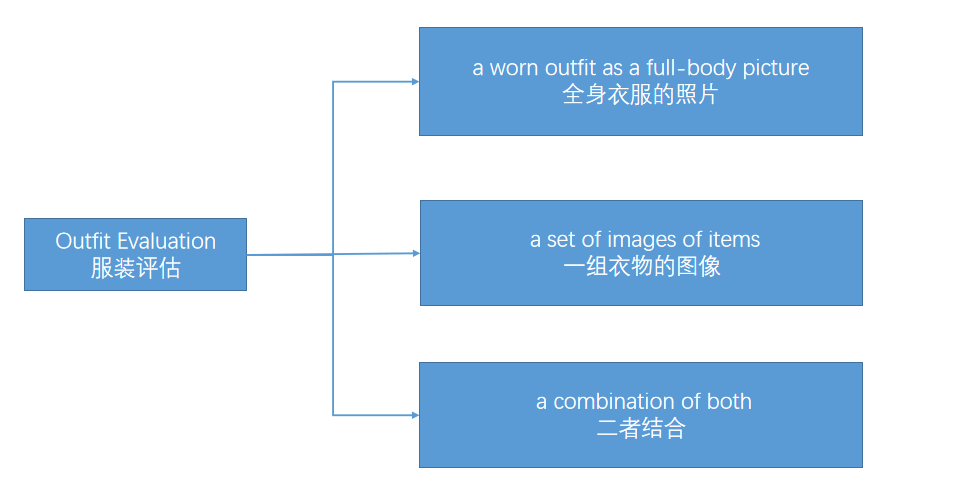
服装评估的输入标准有2大类(也可以说是三种类型),如图所示:
- a worn outfit as a full-body picture(全身衣服的照片)
- a set of images of items(一组衣物的图像)
- a combination of both(二者结合)
具体形式是什么意思呢?请看下图
左边是第一种(全身衣服的照片),右边是第二种(一组衣物的图像)


2. 国内外研究现状
- paper1:根据所要求的场合和该套装中现有的物品,从而推荐出组合套装中的物品。
- paper2:主要是基于polyvore.com的账户和相关联的服装学习私人对时尚的偏好。
- paper3:根据套装中每一件衣物的name、image、category ,并通过已经选择过的 item 的这些属性,推荐一个新的item。
现有成果:Amazon automatic style assistant :Echo Look
缺点分析:
- 只考虑了单件的数量,没有考虑整套衣服的结构完整性。
- 模棱两可的分类,没有进行归类。比如:“连衣裙”和“带裙上衣”分类错误。
- 不能确定,每个单品对整体风格的重要性可能与服装形象中单品的尺度是否有关。
3. 本文研究过程
3.1 数据收集
数据来源:polyvore.com
数据大小:644,192件不同的衣物随
机组合出409,776套不同的套装。
每一件套装都包含: 1. 标题2. 套装中的物品3. 组合图像4. 行为数据(例如来自其他用户的喜欢和评论)组成。
注:和传统的风格识别不同,本文中收集的衣物为一件件独立存在,而不是包含模特本身穿着衣服对应的图片(可以理解为之前提到的输入标准中的第二种方法)。
3.2 数据清洗
根据单品衣物部位不同划分为6类:
- 外衣:大衣,外套,派克大衣
- 上半身:女衬衫,衬衫,马球衫
- 下半身:裤子,牛仔裤,裙子,慢跑裤
- 连体衣:礼服,连身裤,长袍
- 足:鞋、靴、平底鞋等
- 装饰物:包,手套,项链,耳环等
因此不满足这写分类的单品当做脏数据进行删除:
- logo
- 化妆品
- 用于演示目的的背景图像等
针对于本文,服装还有其他还有一些要求:
- 套装的定义:是涵盖身体上部和下部的集合,前5个类别中的每个类别最多具有一个件,而装饰物最多三件。
- 可见性:只考虑外衣和上衣,而不考虑多件外衣。
- 划分情况:我们将毛衣、针织衫等考虑作为外-上混和种类产品。
(1)如果其他部件存在外套,那么就属于上衣;
(2)如果其他部件没有外套,那么就属于外套;
3.3 P/N样本创建
正样本:
- 至少有一个赞的套装,则认为是正样本.
- 总共212623条.
负样本:
- 将通过任意组合物品的服装作为负样本。
- 根据每一个正样本创建两个负样本(即通过将原来正样本中的某个部件替换为来自同一训练/测试部件池中相同部分的随机部件得到负样本)
3.4 Train/Test数据集划分
算法作用:将数据集划分为训练集和测试集
算法核心:保证训练集和测试集中的任意两个套装中,不存在有item相交。

大概思路:
- 首先输入包含所有套装的集合O
- 输出为三个集合A、B、C
- 初始化A、B、C集合为空集
- A ∪ {O0} 表示将套装总数据集集合的第一件服装赋值放入A集合
- i=1,则表示从第二件套装开始遍历O
1)每轮遍历都把Oi赋值给o
2)将当前A集合中的所有套装包含的单品items,都放入集合itemsA
3)将当前B集合中的所有套装包含的单品items,都放入集合itemsB
4)将当前所遍历的套装Oi包含的单品items,都放入集合itemsO
5)求itemsA和itemsO的交集
6)求itemsB和itemsO的交集
7)如果itemsA和itemsO存在交集,且itemsB和itemsO存在交集,表示当前服装Oi无论是放在A还是B都会使得A集合和B集合最终存在item相交,不满足我们的要求,故放入C集合中。
如果如果itemsA和itemsO存在交集,且itemsB和itemsO不存在交集,则放入A集合当中;
如果如果itemsA和itemsO不存在交集,且itemsB和itemsO存在交集,则放入B集合当中;
如果A中也没出现过、B中也没出现过,那么就表示当前服装中的item为从未出现过,则按照训练集和测试集比例需要为2:1的思想,(这里可以猜到A其实就是训练集,B其实就是测试集)把当前一套Outfit并入对应的集合。
3.5 服装分类流程

- 将一套衣服中的每一件衣物都分别划分到6大部位中;
- 通过ResNet-50模型获取每一件item的2048维嵌入表示(对于缺失的部位,会给定一个图像均值进行填充,这类似卷积神经网络中的0填充);
- 并将各自衣物的嵌入表示按照固定的顺序进行连接,组成整套服装的表征。
Φ(O) ≡ [φouter, φupper, ・ ・ ・ , φaccessory2]
最终每一套服装都由5个部位和3个装饰品组成
服装最终表示:5 * part+3 * accessories = 16384 维 - 将服装表示进行质量评分,得到一个[0 , 1]范围的分值。
3.6 模型设置
- one fc4096: 一层4096维度的全连接层
- one fc128 : 一层128维度的全连接层
- two fc128 : 两层128维度的全连接层
每一个全连接层都批次归一化处理,然后通过 Relu 激活函数进行dropout(更好的拟合数据)。

把所有的负值都变为0,而正值不变,这种操作被称为单侧抑制。

使得神经网络中的神经元也具有了稀疏激活性
就是只关注真正起作用的神经元。
4. 研究结果
从下表可知,one_fc4096效果最好:
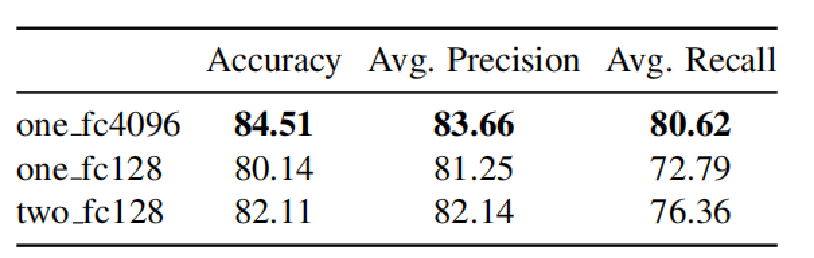
下表中可知训练集的精确度、回召率、F1-score出于99%以上,但是测试集缺不尽人意,说明是出现了过拟合现象。

为此,在one_4096fcd的基础上,又进行了一些其他的特征选取实验:
- (1) item type
- (2) 4-color palette
- (3)(1)+(2)
- (4) ResNet-50 features from grayscale images
- (5)ResNet-50 features from RGB images
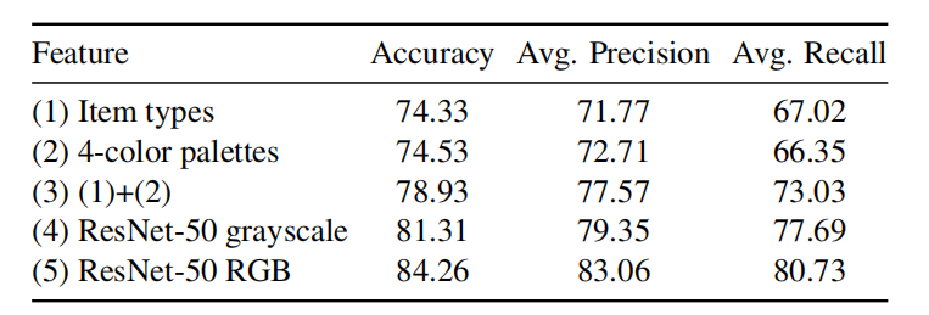
结论:
Item types和 color 分类效果几乎一致;但是结合使用效果会有一定提升。
ResNet-50 能够有更好的实验效果,如果添加上颜色信息,那么会继续有约3%的准确度提升。
还有其他的一些实验后续再进行补充吧。
AI Fashion, Go Go GO!