来源:http://mocom.xmu.edu.cn/article/show/587f103faa2c3f280956e7b6/0/1
Word2Vec 是一种著名的 词嵌入(Word Embedding) 方法,它可以计算每个单词在其给定语料库环境下的 分布式词向量(Distributed Representation,亦直接被称为词向量)。词向量表示可以在一定程度上刻画每个单词的语义。如果词的语义相近,它们的词向量在向量空间中也相互接近,这使得词语的向量化建模更加精确,可以改善现有方法并提高鲁棒性。词向量已被证明在许多自然语言处理问题,如:机器翻译,标注问题,实体识别等问题中具有非常重要的作用。
? Word2vec是一个Estimator,它采用一系列代表文档的词语来训练word2vecmodel。该模型将每个词语映射到一个固定大小的向量。word2vecmodel使用文档中每个词语的平均数来将文档转换为向量,然后这个向量可以作为预测的特征,来计算文档相似度计算等等。
? Word2Vec具有两种模型,其一是 CBOW ,其思想是通过每个词的上下文窗口词词向量来预测中心词的词向量。其二是 Skip-gram,其思想是通过每个中心词来预测其上下文窗口词,并根据预测结果来修正中心词的词向量。两种方法示意图如下图所示:
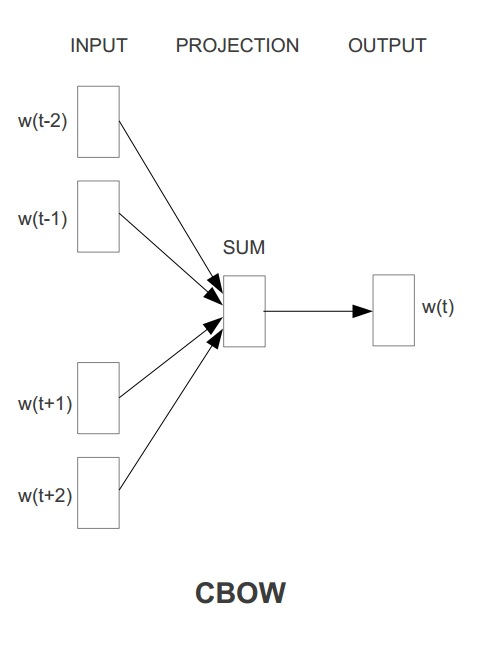
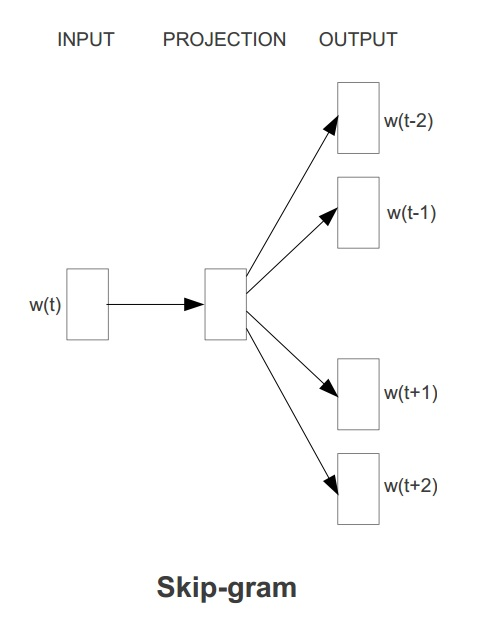
在ml库中,Word2vec 的实现使用的是skip-gram模型。Skip-gram的训练目标是学习词表征向量分布,其优化目标是在给定中心词的词向量的情况下,最大化以下似然函数: 1TT∑t=1sumj=kj=?klogp(wt+j|wt)1T∑t=1Tsumj=?kj=klogp(wt+j|wt) 其中,w1w1 .... wtwt 是一系列词序列,这里 wtwt 代表中心词,而 wt+j(j∈[?k,k])wt+j(j∈[?k,k]) 是上下文窗口中的词。 这里,每一个上下文窗口词 wiwi 在给定中心词 wjwj 下的条件概率由类似 Softmax 函数(相当于Sigmoid函数的高维扩展版)的形式进行计算,如下式所示,其中 uwuw 和 vwvw 分别代表当前词的词向量以及当前上下文的词向量表示:
p(wi|wj)=exp(uwiTvwj)sumVl=1exp(uTlvwj)p(wi|wj)=exp(uwiTvwj)suml=1Vexp(ulTvwj)
? 因为Skip-gram模型使用的softmax计算较为复杂,所以,ml与其他经典的Word2Vec实现采用了相同的策略,使用Huffman树来进行 层次Softmax(Hierachical Softmax) 方法来进行优化,使得 logp(wi|wj)log?p(wi|wj) 计算的复杂度从 O(V)O(V) 下降到 O(log(V))O(log(V))。
? 在下面的代码段中,我们首先用一组文档,其中一个词语序列代表一个文档。对于每一个文档,我们将其转换为一个特征向量。此特征向量可以被传递到一个学习算法。
? 首先,导入Word2Vec所需要的包:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.Word2Vec
? 接下来,根据SparkContext来创建一个SQLContext,其中sc是一个已经存在的SparkContext;然后导入sqlContext.implicits._来实现RDD到Dataframe的隐式转换。
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@225a9fc6scala> import sqlContext.implicits._
import sqlContext.implicits._
? 然后,创建三个词语序列,每个代表一个文档。
scala> val documentDF = sqlContext.createDataFrame(Seq(| "Hi I heard about Spark".split(" "),| "I wish Java could use case classes".split(" "),| "Logistic regression models are neat".split(" ")| ).map(Tuple1.apply)).toDF("text")
documentDF: org.apache.spark.sql.DataFrame = [text: array]
? 新建一个Word2Vec,设置相应的参数,这里设置特征向量的维度为3。具体的参数描述可以参见http://spark.apache.org/docs/1.6.2/api/scala/index.html#org.apache.spark.ml.feature.Word2Vec。
scala> val word2Vec = new Word2Vec().| setInputCol("text").| setOutputCol("result").| setVectorSize(3).| setMinCount(0)
word2Vec: org.apache.spark.ml.feature.Word2Vec = w2v_e2d5128ba199
? 读入训练数据,用fit()方法生成一个Word2VecModel。
scala> val model = word2Vec.fit(documentDF)
model: org.apache.spark.ml.feature.Word2VecModel = w2v_e2d5128ba199
? 利用Word2VecModel把文档转变成特征向量。
scala> val result = model.transform(documentDF)
result: org.apache.spark.sql.DataFrame = [text: array, result: vector]scala> result.select("result").take(3).foreach(println)
[[0.018490654602646827,-0.016248732805252075,0.04528368394821883]]
[[0.05958533100783825,0.023424440695505054,-0.027310076036623544]]
[[-0.011055880039930344,0.020988055132329465,0.042608972638845444]]
? 我们可以看到文档被转变为了一个3维的特征向量,这些特征向量就可以被应用到相关的机器学习方法中。