dataloader
-
- dataset
- Sampler
- collate_fn
- 数据增强
-
- torchvision和albumentations基本操作
- torchvision和albumentations实现自己的数据增强
整个pytorch数据读取顺序是Dataset、sampler产生indices、collate_fn根据indices对数据进行合并处理
class DataLoader(object):...def __next__(self):if self.num_workers == 0: indices = next(self.sample_iter) # Samplerbatch = self.collate_fn([self.dataset[i] for i in indices]) # Datasetif self.pin_memory:batch = _utils.pin_memory.pin_memory_batch(batch)return batch
从上边的代码快可以看到self.sample_iter提供图片列表的index,collate_fn是对图片和label进行合并操作。
dataset
class custom_dset(Dataset):def __init__(self,img_path,txt_path,img_transform=None,loader=default_loader):with open(txt_path, 'r') as f:lines = f.readlines()self.img_list = [os.path.join(img_path, i.split()[0]) for i in lines]self.label_list = [i.split()[1] for i in lines]self.img_transform = img_transformself.loader = loaderdef __getitem__(self, index):img_path = self.img_list[index]label = self.label_list[index]# img = self.loader(img_path)img = img_pathif self.img_transform is not None:img = self.img_transform(img)return img, labeldef __len__(self):return len(self.label_list)
主要是实现init,getitem和len函数
Sampler
Pytorch中已经实现的Sampler有如下几种
SequentialSampler
RandomSampler
WeightedSampler
SubsetRandomSampler
sampler的实现方式
class Sampler(object):r"""Base class for all Samplers.Every Sampler subclass has to provide an :meth:`__iter__` method, providing away to iterate over indices of dataset elements, and a :meth:`__len__` methodthat returns the length of the returned iterators... note:: The :meth:`__len__` method isn't strictly required by:class:`~torch.utils.data.DataLoader`, but is expected in anycalculation involving the length of a :class:`~torch.utils.data.DataLoader`."""def __init__(self, data_source):passdef __iter__(self):raise NotImplementedErrordef __len__(self):return len(self.data_source)
例子
class randomSequentialSampler(sampler.Sampler):def __init__(self, data_source, batch_size):self.num_samples = len(data_source)self.batch_size = batch_sizedef __iter__(self):n_batch = len(self) // self.batch_sizetail = len(self) % self.batch_sizeindex = torch.LongTensor(len(self)).fill_(0)for i in range(n_batch):random_start = random.randint(0, len(self) - self.batch_size)batch_index = random_start + torch.range(0, self.batch_size - 1)index[i * self.batch_size:(i + 1) * self.batch_size] = batch_index# deal with tailif tail:random_start = random.randint(0, len(self) - self.batch_size)tail_index = random_start + torch.range(0, tail - 1)index[(i + 1) * self.batch_size:] = tail_indexreturn iter(index)def __len__(self):return self.num_samples
主要是实现init、iter和len函数,主要是iter函数可以看出其主要通过iter输出一个batch的index
collate_fn
class alignCollate(object):def __init__(self, imgH=32, imgW=100, keep_ratio=False, min_ratio=1):self.imgH = imgHself.imgW = imgWself.keep_ratio = keep_ratioself.min_ratio = min_ratiodef __call__(self, batch):images, labels = zip(*batch)imgH = self.imgHimgW = self.imgWif self.keep_ratio:ratios = []for image in images:w, h = image.sizeratios.append(w / float(h))ratios.sort()max_ratio = ratios[-1]imgW = int(np.floor(max_ratio * imgH))imgW = max(imgH * self.min_ratio, imgW) # assure imgH >= imgWtransform = resizeNormalize((imgW, imgH))images = [transform(image) for image in images]images = torch.cat([t.unsqueeze(0) for t in images], 0)return images, labelsclass resizeNormalize(object):def __init__(self, size, interpolation=Image.BILINEAR):self.size = sizeself.interpolation = interpolationself.toTensor = transforms.ToTensor()def __call__(self, img):img = img.resize(self.size, self.interpolation)img = self.toTensor(img)img.sub_(0.5).div_(0.5)return img对于不定长的数据处理
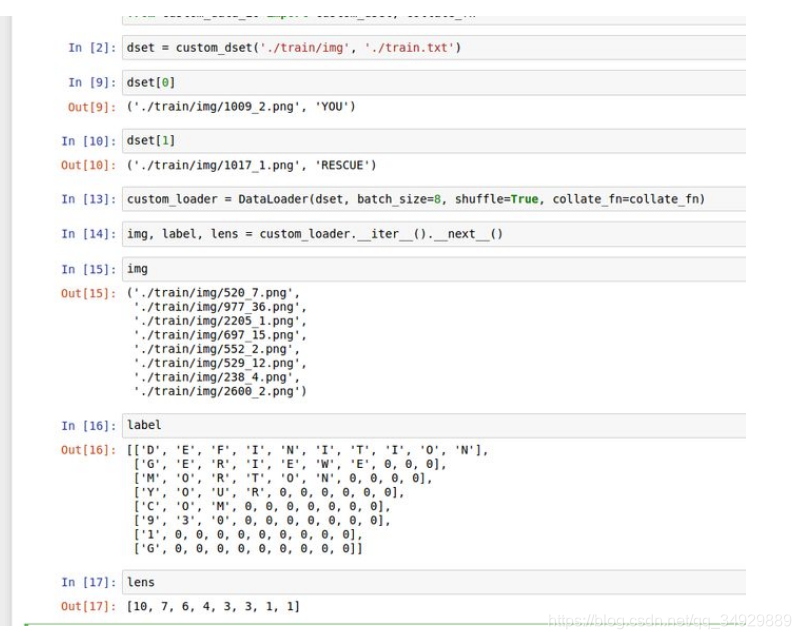
def collate_fn(batch):batch.sort(key=lambda x: len(x[1]), reverse=True)img, label = zip(*batch)pad_label = []lens = []max_len = len(label[0])for i in range(len(label)):temp_label = [0] * max_lentemp_label[:len(label[i])] = label[i]pad_label.append(temp_label)lens.append(len(label[i]))return img, pad_label, lens
最后的结果验证
数据增强
torchvision和albumentations基本操作
torchvision的输入可以是PIL和cv读取的图片,但是albumentations只能是numpy数组,并且格式是RGB 。两者使用没有很大的区别,据说albumentations要比torchvision处理速度快。
from torch.utils.data.dataset import Dataset
import PIL.Image as Image
import torchvision.transforms as transforms
from albumentations import (Resize,RandomCrop,HorizontalFlip,Normalize, IAAPerspective, ShiftScaleRotate, CLAHE, RandomRotate90,Transpose, ShiftScaleRotate, Blur, OpticalDistortion, GridDistortion, HueSaturationValue,IAAAdditiveGaussianNoise, GaussNoise, MotionBlur, MedianBlur, IAAPiecewiseAffine,IAASharpen, IAAEmboss, RandomBrightnessContrast, Flip, OneOf, Compose
)
import numpy as np
import cv2# 使用torchvision.transforms作数据增强与pytorch定义数据集连用
class TorchvisionDataset(Dataset):def __init__(self, file_paths, labels, transform=None):self.file_paths = file_pathsself.labels = labelsself.transform = transformdef __len__(self):return len(self.file_paths)def __getitem__(self, idx):label = self.labels[idx]file_path = self.file_paths[idx]# 读取图片使用 PIL 库image = Image.open(file_path)if self.transform:image = self.transform(image)return image, labeltorchvision_transform = transforms.Compose([transforms.Resize((256, 256)),transforms.RandomCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225],)
])torchvision_dataset = TorchvisionDataset(file_paths=['./images/image_1.jpg', './images/image_2.jpg', './images/image_3.jpg'],labels=[1, 2, 3],transform=torchvision_transform,
)class AlbumentationsDataset(Dataset):"""处理数据增强跟上面的 TorchvisionDataset 的一致"""def __init__(self, file_paths, labels, transform=None):self.file_paths = file_pathsself.labels = labelsself.transform = transformdef __len__(self):return len(self.file_paths)def __getitem__(self, idx):label = self.labels[idx]file_path = self.file_paths[idx]# Opencv 读取图片image = cv2.imread(file_path)# 默认OpenCV读取得到的是 BGR 图片# 转换 RGB 格式图片image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)if self.transform:augmented = self.transform(image=image)image = augmented['image']return image, labelalbumentations_transform = Compose([Resize(256, 256),RandomCrop(224, 224),HorizontalFlip(),Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225],),transforms.ToTensor(),# ToTensor()
])albumentations_dataset = AlbumentationsDataset(file_paths=['./images/image_1.jpg', './images/image_2.jpg', './images/image_3.jpg'],labels=[1, 2, 3],transform=albumentations_transform,
)class AlbumentationsPilDataset(Dataset):"""跟 TorchvisionDataset 一致"""def __init__(self, file_paths, labels, transform=None):self.file_paths = file_pathsself.labels = labelsself.transform = transformdef __len__(self):return len(self.file_paths)def __getitem__(self, idx):label = self.labels[idx]file_path = self.file_paths[idx]image = Image.open(file_path)if self.transform:# Convert PIL image to numpy arrayimage_np = np.array(image)# Apply transformationsaugmented = self.transform(image=image_np)# Convert numpy array to PIL Imageimage = Image.fromarray(augmented['image'])return image, labelalbumentations_pil_transform = Compose([Resize(256, 256),RandomCrop(224, 224),HorizontalFlip(),
])# Note that this dataset will output PIL images and not numpy arrays nor PyTorch tensors
albumentations_pil_dataset = AlbumentationsPilDataset(file_paths=['./images/image_1.jpg', './images/image_2.jpg', './images/image_3.jpg'],labels=[1, 2, 3],transform=albumentations_pil_transform,
)torchvision和albumentations实现自己的数据增强
对于在torchvision和albumentations上实现自己的数据增强操作,只需要明白是对什么格式的数据进行操作,并返回特格式的数据即可。一般的操作都是在totensor函数后,操作的对象是torch对象。下边提供两个例。
import math
import randomclass RandomErasing(object):""" Randomly selects a rectangle region in an image and erases its pixels.Args:probability: The probability that the Random Erasing operation will be performed.sl: Minimum proportion of erased area against input image.sh: Maximum proportion of erased area against input image.r1: Minimum aspect ratio of erased area.mean: Erasing value."""def __init__(self, probability=0.5, sl=0.02, sh=0.4, r1=0.3, mean=(0.4914, 0.4822, 0.4465)):self.probability = probabilityself.mean = meanself.sl = slself.sh = shself.r1 = r1def __call__(self, img):if random.uniform(0, 1) >= self.probability:return imgfor _ in range(100):area = img.size()[1] * img.size()[2]target_area = random.uniform(self.sl, self.sh) * areaaspect_ratio = random.uniform(self.r1, 1 / self.r1)h = int(round(math.sqrt(target_area * aspect_ratio)))w = int(round(math.sqrt(target_area / aspect_ratio)))if w < img.size()[2] and h < img.size()[1]:x1 = random.randint(0, img.size()[1] - h)y1 = random.randint(0, img.size()[2] - w)if img.size()[0] == 3:img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]img[1, x1:x1 + h, y1:y1 + w] = self.mean[1]img[2, x1:x1 + h, y1:y1 + w] = self.mean[2]else:img[0, x1:x1 + h, y1:y1 + w] = self.mean[0]return imgreturn imgA.HorizontalFlip(p=0.3),
# A.VerticalFlip(p=0.3),
# A.RandomRotate90(p=0.3),
# A.Cutout(num_holes=8, max_h_size=64,
# max_w_size=64, fill_value=0, p=0.5),
# A.Normalize(mean=MEAN, std=STD, max_pixel_value=255.0, p=1.0),
# ToTensorV2(p=1.0),
# RandomErasing()])
class Cutout(object):"""Randomly mask out one or more patches from an image.Args:n_holes (int): Number of patches to cut out of each image.length (int): The length (in pixels) of each square patch."""def __init__(self, n_holes, length=2):self.n_holes = n_holesself.length = lengthdef __call__(self, img):"""Args:img (Tensor): Tensor image of size (C, H, W).Returns:Tensor: Image with n_holes of dimension length x length cut out of it."""h = img.shape[1]w = img.shape[2]mask = np.ones((h, w), np.float32)for n in range(self.n_holes):y = np.random.randint(h)x = np.random.randint(w)y1 = int(h*0.9)y2 = hx1 = int(w*0.9)x2 = wmask[y1: y2, x1: x2] = 0.mask = torch.from_numpy(mask)mask = mask.expand_as(img)img = img * maskreturn imgtransform_aug = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.Resize((64, 64), interpolation=2),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),Cutout(n_holes=1)