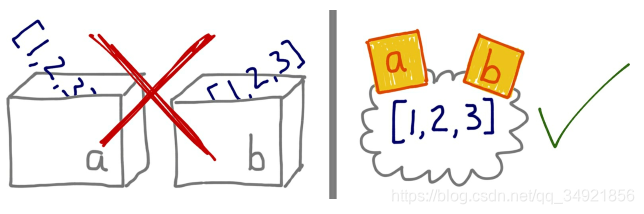
先介绍一下本章的内容吧。本章的主题是对象和对象名称之间的区别。名称不是对象,而是单独的东西。Python的变量是标注,而不是盒子。如果你不知道引用式变量是什么,可以像这样对别人解释别名。
然后本章讨论对象标识,值和别名等概念。随后,本章会揭露元组的一个神奇特性:元组是不可变的,但是其中的值可以改变,之后就引申到浅复制和深复制。接下来的话题是引用和函数参数:可变的参数默认值导致的问题,以及如何安全地处理函数的调用者传入的可变参数。
本章最后一节讨论垃圾回收,del 命令,以及如何使用弱引用“记住”对象,而无需对象本身存在。
本章内容很重要!因为这些话题是解决Python程序中很多不易察觉的bug的关键!
变量不是盒子
Python 变量类似于Java中的引用式变量,因此最好把他们理解成附加在对象上的标注。
一个例子
>>> a = [1,2,3]
>>> b = a
>>> a.append(4)
>>> b
[1, 2, 3, 4]
- 赋值方式的正确说法是“把变量s分配给seesaw”,而不是“把seesaw分配给变量s”。对引用式变量来说,把变量分配给对象更合理,反过来说就有问题。毕竟,对象在赋值之前就创建了。
标识,相等性和别名
Lewis Carroll 是 Charles Lutwidge Dodgson 教授的笔名。Carroll 先生就是 Dodgson 教授,二者是同一个人。
>>> charles = {
'name': 'Charles L. Dodgson', 'born': 1832}
>>> lewis = charles
>>> lewis is charles
True
>>> id(charles), id(lewis)
(140605013386448, 140605013386448)
>>> lewis['balance'] = 90
>>> charles
{
'born': 1832, 'balance': 90, 'name': 'Charles L. Dodgson'}
这时如果来了一个冒充者alex,他的信息和Charles一样。
>>> alex = {
'born': 1832, 'balance': 90, 'name': 'Charles L. Dodgson'}
>>> alex == lewis
True
>>> alex is lewis
False
这个例子体现了别名。在这段代码中,lewis 和 charles 是别名, 即两个变量绑定同一个对象。而 alex 不是 charles 的别名,因为二者绑定的是不同的对象。alex 和 charles 绑定的对象具有相同的值(== 比较的就是值),但他们的标识不同。
每个变量都有标识,类型和值。对象一旦创建,它的标识绝不会变;你可以把标识理解为对象在内存中的地址。 is 运算符比较两个对象的标识; id() 函数返回对象标识的整数表示。
对象 ID 的真正意义在不同的实现中有所不同,但 ID 一定是唯一的数值标注,而且在对象的生命周期中绝不会变。
在 == 和 is 之间选择
==运算符比较两个对象的值(对象中保存的数据), 而is比较对象的标识。is运算符比==速度快,因为它不能重载,并且是比较两个整数ID。而a == b是语法糖,等同于a.__eq__(b)。
元组的相对不可变性
元组与多数Python集合(列表,字典,集,等等) 一样,保存的是对象的引用,如果引用的元素是可变的,即使元组本身不可变,元素依然是可变的。也就是说,元组的不可变性其实是指 tuple 数据结构的物理内容(即保存的引用) 不可变,与引用的对象无关。
一个例子
>>> t1 = (1, 2, [30, 40])
>>> t2 = (1, 2, [30, 40])
>>> t1 == t2
True
>>> t1 is t2
False
>>> t1[-1].append(90)
>>> t1
(1, 2, [30, 40, 90])
>>> id(t1)
140605013341040
>>> t1[-1].append(90)
>>> t1
(1, 2, [30, 40, 90, 90])
>>> id(t1)
140605013341040
默认做浅复制
复制列表(或多数内置的可变集合) 最简单的方式是使用内置的类型构造方法,但这些构造方法做的是浅复制(即复制了最外层容器,副本的元素是源容器中元素的引用)。如果所有元素都是不可变的,那么这样没有问题,还能节省内存。但是如果有可变的元素,可能就会导致意想不到的问题了。
一个例子
>>> l1 = [3, [55, 44], (7, 8, 9)]
>>> l2 = list(l1)
>>> l1 == l2
True
>>> l1 is l2
False
>>> l2[1].append(23)
>>> l2
[3, [55, 44, 23], (7, 8, 9)]
>>> l1
[3, [55, 44, 23], (7, 8, 9)]
函数的参数作为引用时
Python 唯一支持的参数传递模式是共享传参,共享传参指函数的各个形式参数获得实参中各个引用的副本。也就是说,函数内部的形参是实参的别名。
这种方案的结果是,函数可能会修改作为参数传入的可变对象。
一个例子
>>> def f(a, b):
... a += b
... return a
...
>>> x = 1
>>> y = 2
>>> f(x, y)
3
>>> x, y
(1, 2)
>>> a = [1, 2]
>>> b = [3, 4]
>>> f(a, b)
[1, 2, 3, 4]
>>> a
[1, 2, 3, 4]
不要使用可变类型作为参数的默认值
当这个可变类型的默认值发生改变时,后续的函数调用都会受到影响。
一个例子
>>> def f(a, b=[]):
... print b
... b.append(a)
... return b[0]
...
>>>
>>> f(1, [2, 3])
[2, 3]
2
>>> f(1)
[]
1
>>> f(2)
[1]
1
del 和垃圾回收
- 对象绝不会自行销毁; 然而,无法得到对象时,可能会被当做垃圾回收。
del 语句删除名称,而不是对象。del 命令可能会导致对象被当做垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或者无法得到对象时。重新绑定也可能会导致对象的引用数量归零,导致对象被销毁。
- tips: 如果两个对象相互引用,当它们的引用只存在二者之间时,垃圾回收程序会判定它们都无法获取,进而它们都销毁。
- 有个
__del__特殊方法,但是它不会销毁实例,不应该在代码中调用。即将销毁实例时,Python 解释器会调用__del__方法,给实例最后的机会,释放外部资源。
在 CPython 中,垃圾回收使用的主要算法是引用计数。实际上,每个对象都会统计有多少引用指向自己。当引用计数归零时,对象立即就被销毁: CPython 会在对象上调用 __del__ 方法(如果定义了),然后释放分配给对象的内存。CPython 2.0 增加了分带垃圾回收算法,用于检测引用循环中涉及的对象组,如果一组对象之间全是相互引用,即使再出色的引用方式也会导致组中的对象不可获取。Python的其他实现有更复杂的垃圾回收程序,而且不依赖引用计数,这意味着,对象的引用计数为零时可能不会立即调用 __del__ 方法。
为了演示对象声明结束时的情形,我们可以使用 weakref.finalize 注册一个回调函数,在销毁对象时调用。
>>> import weakref
>>> s1 = {
1, 2, 3}
>>> s2 = s1
>>> def bye():
... print("bye")
...
>>> ender = weakref.finalize(s1, bye)
>>> ender.alive
True
>>> del s1
>>> ender.alive
True
>>> s2 = "aaa"
bye
>>> ender.alive
False弱引用
正是因为有引用,对象才会在内存中存在。当对象的引用数量归零后,垃圾回收程序会把对象销毁。但是,有时需要引用对象,而不让对象存在的时间超过所需时间。这经常用在缓存中。
弱引用不会妨碍对象被当做垃圾回收,弱引用在缓存应用中很有用,因此我们不想仅因为被缓存引用着而始终保存缓存对象。
下面展示了如何使用 weakref.ref 实例获取所指对象。如果对象存在,调用弱引用可以获取对象;否则返回 None。
- 该示例是一个控制台会话,Python控制台会自动把
_变量绑定到结果不为None的表达式结果上。这对我想演示的行为有影响,不过却凸显了一个实际问题:微观管理内存时,往往会得到意外的结果,因为不明显的隐式赋值会为对象创建新引用。控制台中的_变量是一例。调用跟踪对象也常导致意料之外的引用。
>>> import weakref
>>> a_set = {
0, 1}
>>> wref = weakref.ref(a_set)
>>> wref
<weakref at 0x7ffa4dd67098; to 'set' at 0x7ffa4dbd6e48>
>>> wref()
{
0, 1}
>>> a_set = {
2,3,4}
>>> wref()
{
0, 1}
>>> wref()
{
0, 1}
>>> 123
123
>>> wref()
>>> wref() is None
True
WeakValueDictionary 简介
WeakValueDictionary 类实现的是一种可变映射,里面的值是对象的弱引用。被引用的对象在程序中的其他地方被当做垃圾回收后,对应的键会自动从WeakValueDictionary 中删除。因此 WeakValueDictionary 经常用于缓存。
一个例子
import weakrefstock = weakref.WeakValueDictionary()class Cheese:def __init__(self, kind):self.kind = kinddef __repr__(self):return 'Cheese(%r)' % self.kindcatalog = [Cheese('Red'), Cheese('Blue'), Cheese('Yellow')]
for val in catalog:stock[val.kind] = valprint(sorted(stock.keys()))
del catalog
print(sorted(stock.keys()))
del val
print(sorted(stock.keys()))
弱引用的局限
不是每个Python对象都可以作为弱引用的目标(或称所指对象)。基本的 list 和 dict 实例不能作为所指对象,但是它们的子类可以轻松地解决这个问题。
import weakref
class MyList(list):"""list的子类, 实例可以作为弱引用的目标"""a_list = MyList(range(10))
wref_to_a_list = weakref.ref(a_list)
set实例可以作为所指对象,用户定义的类型也没问题。但是 int 和 tuple 实例不能作为弱引用的目标,甚至它们的子类也不行。
这些局限基本上是 CPython 的实现细节,在其他Python解释器中情况可能不一样。
Python 对不可变类型施加的把戏
>>> t1 = (1,2,3)
>>> t2 = tuple(t1)
>>> t2 is t1
True
>>> t3 = t1[:]
>>> t3 is t1
True
对于元组来说,构造函数或[:]表达式都不创建副本,而是返回同一个对象的引用。
str, bytes, 和 frozenset 实例也有这种行为。注意,frozenset 实例不是序列,因此不能使用 fs[:] (fs 是一个 frozenset 实例)。但是, fs.copy() 具有相同的效果:它会欺骗你,返回同一个对象的引用,而不是创建副本。
>>> s1 = 'ABC'
>>> s2 = 'ABC'
>>> s1 is s2
True
s1 和 s2 竟然指代的同一个字符串! 共享字符串字面量是一种优化措施,称为驻留(interning)。 CPython 还会在小的整数上使用这个优化措施,防止重复创建“热门”数字,如0,-1,和42.注意,CPython 不会驻留所有字符串和整数,驻留的条件是实现细节,而且没有文档说明。
- 千万不要依赖字符串或整数的驻留!比较字符串或整数是否相等时,应该使用
==而不是is。驻留是Python解释器内部使用的一个特性。
终于又干完一章了!接下来我们进入第九章,“符合Python风格的对象”。