本章主要讨论两个内容:
- 子类化内置类型的缺点
- 多重继承和方法解析顺序
子类化内置类型很麻烦
在 Python2.2 之前,内置类型(如list 或 dict) 不能子类化。在 Python2.2 之后,内置类型可以子类化了,但是有个重要的注意事项:内置类型(使用C语言编写)不会调用用户定义的类覆盖的特殊方法。
至于内置类型的子类覆盖的方法会不会隐式调用,CPython 没有指定官方规则。基本上,内置类型的方法不会调用子类覆盖的方法。例如,dict 的子类覆盖的 __getitem__() 方法不会被内置类型的 get() 方法调用。
class DoppeDict(dict):def __setitem__(self, key, value):super().__setitem__(key, [value] * 2)dd = DoppeDict(one=1)
print(dd)
dd['two'] = 2
print(dd)
dd.update(three=3)
print(dd)
""" output {'one': 1} {'one': 1, 'two': [2, 2]} {'one': 1, 'two': [2, 2], 'three': 3} """
原生类型的这种行为违背了面向对象编程的一个基本原则:始终应该从实例(self)所属的类开始搜索方法,即使在超类实现的类中调用也是如此。在这种糟糕的局面中, __missing__ 方法却能按预期方式工作,不过这只是特例。
直接子类化内置类型(如dict, list 或 str) 容易出错,因为内置类型的方法通常会忽略用户覆盖的方法。不要子类化内置类型,用户自己定义的类应该继承collections 模块中的类,例如 UserDict, UserList, UserString, 这些类做了特殊设计,因此易于扩展。
import collectionsclass DoppeDict2(collections.UserDict):def __setitem__(self, key, value):super().__setitem__(key, [value] * 2)dd = DoppeDict2(one=1)
print(dd)
dd['two'] = 2
print(dd)
dd.update(three=3)
print(dd)class AnswerDict2(collections.UserDict):def __getitem__(self, key):return 42ad = AnswerDict2(a='foo')
print(ad['a'])
d = {
}
d.update(ad)
print(d['a'])
print(d)
""" output: {'one': [1, 1]} {'one': [1, 1], 'two': [2, 2]} {'one': [1, 1], 'two': [2, 2], 'three': [3, 3]} 42 42 {'a': 42} """
多重继承和方法解析顺序
任何实现多重继承的语言都要处理潜在的命名冲突,这种冲突由不相关的祖先类实现同名方法引起。这种冲突称为“菱形问题”
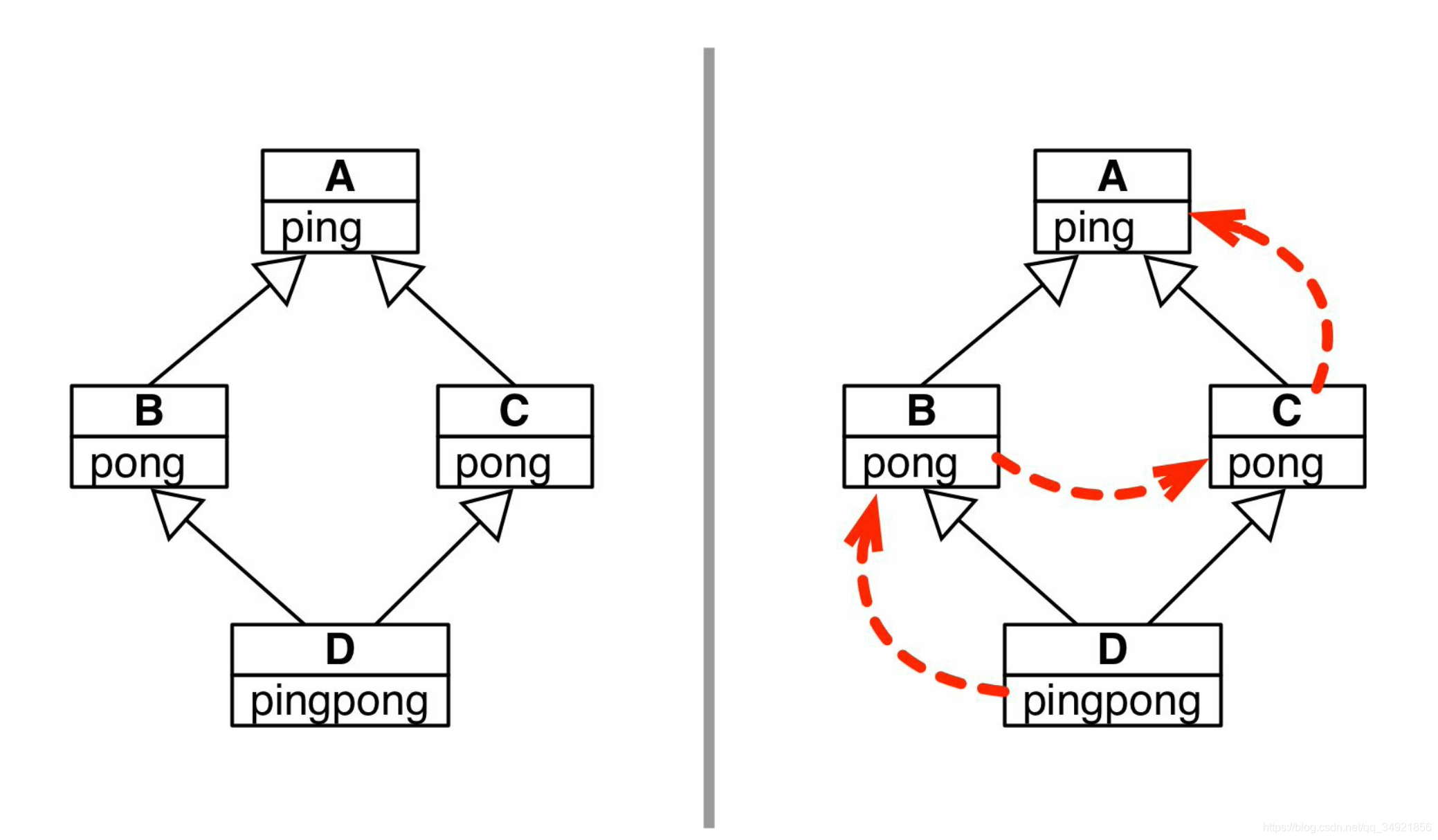
(左) 说明”菱形问题“的 UML 类图;(又) 虚线箭头是下例使用的方法解析顺序
class A:def ping(self):print('ping:', self)class B(A):def pong(self):print("pong", self)class C(A):def pong(self):print("PONG", self)class D(B, C):def ping(self):super().ping()print("post-ping", self)def pingpong(self):self.ping()super().ping()self.pong()super().pong()C.pong(self)d = D()
d.pong()
C.pong(d)
""" output: pong <__main__.D object at 0x10cf14790> PONG <__main__.D object at 0x10cf14790> """
Python 能区分 d.pong() 调用的是哪个方法,是因为 Python 会按照特定的顺序遍历继承图。这个顺序叫方法解析顺序(Method Resolution Order, MRO)。类都有一个名为 __mro__ 属性,它的值是一个元祖,按照方法解析顺序列出各个超类,从当前类一直向上,直到 object 类, D 类的 __mro__ 属性如下:
print(D.__mro__)
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
- tips:方法解析顺序使用 C3算法计算。Michele Simionato 的论文 ”The Python 2.3 Method Resolution Order“(https://www.python.org/download/releases/2.3/mro/) 对 Python 方法解析顺序使用的 C3算法做了权威论述。
处理多重继承
如 Alan Kay 所言,继承有很多用途,而多重继承增加了可选方案和复杂度。使用多重继承容易得出令人费解和脆弱的设计。我们还没有完整的理论,下面是避免把类图搅乱的一些建议。
-
把接口继承和实现继承区分开
使用多重继承时,一定要明确一开始为什么创建子类。主要原因可能有:- 继承接口,创建子类型,实现”是什么“关系
- 继承实现,通过重用避免代码重复
其实这两条经常同时出现,不过只要可能,一定要明确意图。通过继承重用代码是实现细节,通常可以换用组合和委托模式。而接口继承则是框架的支柱。
-
使用抽象基类显式表示接口
现代的 Python 中,如果类的作用是定义接口,应该明确把它定义为抽象基类。Python3.4及以上的版本中,我们要创建abc.ABC或其他抽象基类的子类。 -
通过混入重用代码
如果一个类的作用是为多个不相关的子类提供方法实现,从而实现重用,但不体现”是什么“关系,应该把那个类明确地定义为混入类(mixin class)。从概念上讲,混入不定义新类型,只是打包方法,便于重用。混入类绝对不能实例化,而且具体类不能只继承混入类。混入类应该提供某方面的特定行为,只实现少量关系非常紧密的方法。 -
在名称中明确指明混入
因为在 Python 中没有把类声明为混入的正规方式,所以强烈推荐在名称中假如…Mixin 后缀。 -
抽象基类可以作为混入,反过来则不成立
抽象基类可以实现具体方法,因此也可以作为混入使用。不过,抽象基类会定义类型,而混入做不到。此外,抽象基类可以作为其他类的唯一基类,而混入决不能作为唯一的超类,除非继承另一个更具体的混入—真实的代码很少这样做。抽象基类有个局限是混入没有的:抽象基类中实现的具体方法只能与抽象基类及其超类中的方法协作。这表明,抽象基类中具体方法只是一种便利措施,因为这些方法所做的一切,用户调用抽象基类中的其他方法也能做到。
-
不要子类化多个具体类
具体类可以没有,或最多只有一个具体超类。也就是说,具体类的超类中除了这一个具体超类之外,其余的都是抽象基类或混入。例如,在下述代码中,如果 Alpha 是具体类,那么 Beta 和 Gamma 必须是抽象基类或混入:class MyConcreteClass(Alpha, Beta, Gamma): """这是一个具体类,可以实例化""" -
为用户提供聚合类
如果抽象基类或混入的组合对客户代码非常有用,那就提供一个类,使用易于理解的方式把他们结合起来。 -
优先使用对象组合,而不是类继承
组合和委托可以代替混入,把行为提供给不同的类,但是不能取代接口继承去定义类型层次结构。