最近很多的方法都会说他用了自监督的学习方式。也有很多的学者表示自监督学习成为了流行是一种必然趋势,虽然在现实世界中,我们可以很容易采集到大量的数据,但是对数据进行标注并不是一项简单的工作,如何从大量无标注的数据中学习到有效的知识是现在乃至以后都非常重要的一个问题。
本文中,我想分为以下方面进行总结。
1、什么是自监督学习,这些方法为什么work。
2、总结每一类方法中几种比较出名的方法(如果太长,可能会每一类分一篇文章写一下)。
一、什么是自监督学习,自监督学习能学习到哪些信息(Self-Supervised Learning)
这一部分在一篇知乎中总结的很好:自监督学习的一些思考
自监督学习是无监督学习的一种方式,它的主要目的是在非人工标注的数据中通过自己监督自己来学习到有用的信息。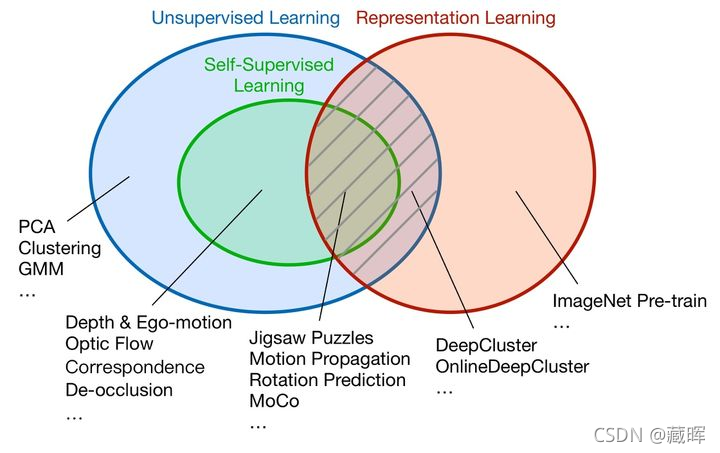
目前大多数文章会把自监督任务分为两个类别:1. Generative Methods;2. Contrastive Methods;
1、Generative Methods
Generative Methods是可以通过构建代理任务(proxy task)来进行自监督学习,其做法是将模型最后的输出依然是一个和原图相似大小的结果(模型本来的输出就是这个尺度或者通过GAN的方法还原),然后构建一个关于pixel的loss来完成自监督学习。这一类方法一般都针对于视频任务比较多,如去自监督光流,深度估计,图像关键点匹配,颜色等,即较容易通过上下两帧的信息来获取自监督信息。这类任务十分简洁直观的从未标注数据集中构建出了监督信号,但是其重建计算开销是非常大的(GAN的生成器),且GAN的训练本来就是一个很Challenge的任务,这也增加了任务的复杂程度。
在上述的文章总结中,作者提出了一个疑问:Inpainting的任务算不算自监督学习?因为我们知道在图像修复任务中,我们并不需要人工标注。以下是来自该文章中作者的看法:
判断一个工作是否属于自监督学习,除了无需人工标注这个标准之外,还有一个重要标准,就是是否学到了新的知识。举个简单的例子,例如image inpainting是否属于自监督学习?如果一篇image inpainting的论文,其主要目的是提升inpainting的效果,那么它就不属于自监督学习,虽然它无需额外标注。但是如果它的目的是借助inpainting这个任务来学习图像的特征表达,那么它就是自监督学习(参考论文:Context Encoders [1])。如下图,以自监督表征学习为例,我们通常需要设计一个自监督的proxy task,我们期望在解决这个proxy task的过程中,CNN能学到一些图像高级的语义信息。然后我们将训练好的CNN迁移到其他目标任务,例如图像语义分割、物体检测等等。
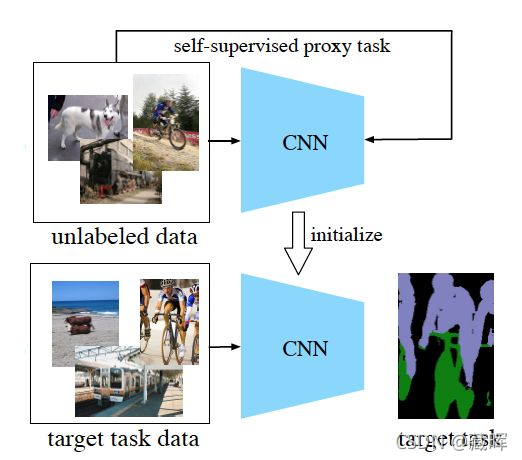
? 可以看到自监督学习的本质目的是学习一种通用的特征表示。
那么,Generative Methods为代表的这一类自监督学习方法是如何学习到新的信息的呢?
本质上还是如何去构建一种有利于我们任务的自监督约束。
?对于视频来说,我们很容易通过时序信息来进行自监督学习,比如:通过帧的相似性,一般情况下邻近帧之间的特征基本上不会有太大的变化,而距离比较远的两帧相似性较差,可以通过这一规则来构建自监督损失;可以通过一些无监督的方法来构建一些可学习的信号,比如光流,颜色相似性,点匹配的等等,然后通过这一部分特征来构建监督信号;此外视频中的一些视频顺序信息,可提取出来的物体移动信息,图像细节变化等都可以构建构建成相应的监督信号,这个也给自监督学习留足了想象空间。
?针对于图像任务来说可以借用的proxy task也很多,比如用图像修复的方法,先破环一张图片然后再用原图片来构建自监督信号;用超分辨率的思路,将一张图片先缩放,然后再用原图来做监督;做一些亮度调节,转灰度图,旋转,裁剪等等。更多的
关于图像的自监督proxy task在这篇文章中也提到了很多,可以了解一下:图解自监督学习,人工智能蛋糕中最大的一块。
2、Contrastive Methods
Contrastive Methods 与第一类方法不同,这类方法并不需要去重构原始输入,而是希望能够在高阶的特征空间中对不同的输入进行分辨,从而促使模型去学习一些通用的特征表示。具体来说,Contrastive Methods 通常对图片做各种变换,然后优化目标是同一张图片的不同变换在特征空间中尽量接近,不同图片在特征空间中尽量远离(如下图所示)。此外,在模型结构上,这类方法(如MoCo,SimCLR)通常会用到Siamese Network的结构。
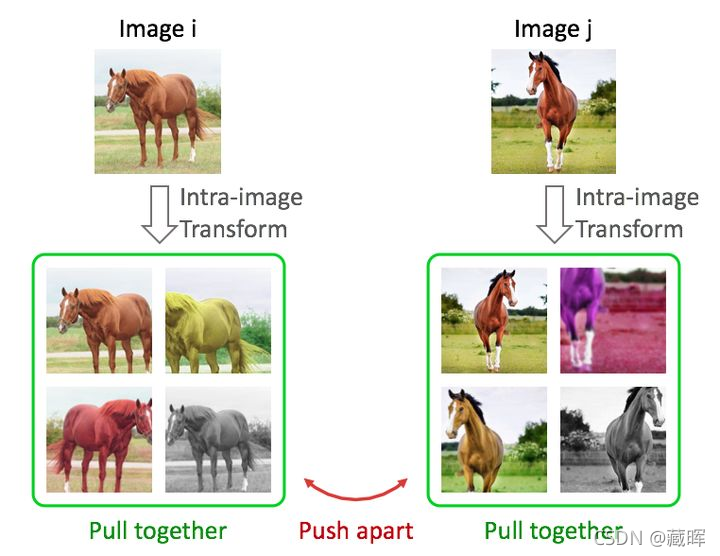
?与上一类方法不同,这一类方法是学习一个通用性表征,然后用于其他的下游任务,如分类,检测,分割等。目前基于contrastive的方法已经在分类任务(ImageNet)上取得了接近有监督学习的效果了,同时在一些文章中,用其做为pre-train的模型甚至超过了用有监督方式训练出来的方法。这类方法如何很火,代表有MoCo, SimCLR等等。
那么,Contrastive Methods为代表的这一类自监督学习方法是如何学习到新的信息的呢?
这一类方法都基于一个假设,就是物体的结构性和关联性。也就是说相似的两个物体在特征空间中应该是会相互靠拢的,而不是互相远离的。而这一类方法巧妙地利用了这样一种特性,从而学习到了通用性的特征表示。更形象地说,在以下的两种特征空间中,Contrastive Methods能学习到的会偏向于第二种特征空间而非第一种。
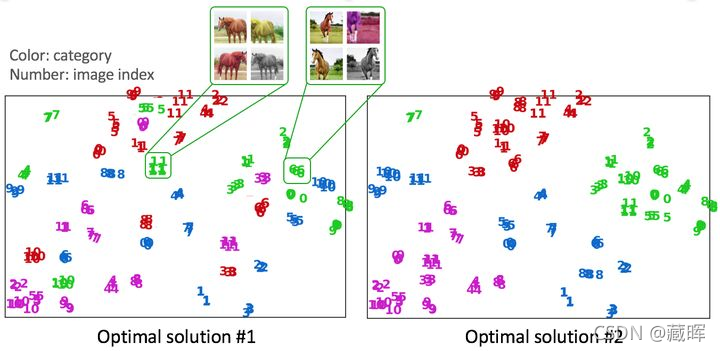
?在看这类方法的时候,我一开始的想法是,这个东西是怎么work的,并不是很理解。虽然这种结构关联性在一定程度上对这个问题给出了解答,但感觉并没有很直观的解释出通用性表征是怎么学习出来的(个人看法)。
关于自监督任务的设计问题
由于处在个人了解阶段,并没有什么实际操作经验,这部分参考了这篇文章(自监督学习的一些思考)中作者的观点。
1、捷径(shortcuts)
以jigsaw puzzles为例,如下图,如果我们让划分的patch之间紧密挨着,那么神经网络只需要判断patch的边缘是否具有连续性,就可以判断patch的相对位置,而不需要学到高级的物体语义信息。这就是一种捷径,我们在设计任务的过程中需要避免这样的捷径。
对于这种捷径,处理的方式也很简单,我们只需要让patch之间产生一些随机的间隔就行,如下图。
Solving jigsaw puzzles的其他捷径还包括色差、彗差、畸变、暗角等可以指示patch在图像中的相对位置的信息。解决方案除了想办法消除这些畸变外,还可以让patch尽量靠近图像中心。
2. 歧义性(Ambiguity)
大多数利用先验来设计的自监督任务都会面临歧义性问题。例如colorization中,一种物体的颜色可能是多种多样的,那么从灰度图恢复颜色这个过程就具有ambiguity;再例如在rotation prediction中,有的物体并没有一个通常的朝向(例如俯拍放在桌上的圆盘子)。有不少已有工作在专门解决特定任务的歧义性问题,例如CVPR 2019的Self-Supervised Representation Learning by Rotation Feature Decoupling。另外就是设计低熵的先验,因为低熵的先验也具有较低的歧义性。
3. 任务难度
神经网络就像一个小孩,如果给他太简单的任务,他学不到有用的知识,如果给他太难的任务,他可能直接就放弃了。设计合理的难度也是一个需要考虑的方面。


二、自监督学习相关工作
1. Generative Methods
[1] Xiaolong Wang, Abhinav Gupta. “Unsupervised leaning of visual representation using videos”. In: ICCV 2015.
[2] Carl Vondrick, Abhinav Shrivastava, Alireza Fathi, et al. “Tracking emerges by colorizing videos”. In: ECCV.
2018.
[3] Xiaolong Wang, Allan Jabri, and Alexei A Efros. “Learning correspondence from the cycle-consistency of
time”. In: CVPR. 2019.
[4] Xueting Li, Sifei Liu, Shalini De Mello, et al. “Joint-task self-supervised learning for temporal correspondence”.
In: NeurIPS. 2019.
[5] Ning Wang, Yibing Song, Chao Ma, et al. “Unsupervised Deep Tracking”. In: CVPR. 2019.
[6] Allan Jabri, Andrew Owens, and Alexei A Efros. “Space-time correspondence as a contrastive random walk”.
In: NeurIPS. 2020.
2. Contrastive Methods
[1] Aaron van den Oord, Yazhe Li, Oriol Vinyals. “Representation Learning with Contrastive Predictive Coding”.In: arXiv:1807.03748 . 2019.
[2] Zhirong Wu, Yuanjun Xiong, Stella X Yu, et al. “Unsupervised feature learning via non-parametric instance
discrimination”. In: CVPR. 2018.
[3] Mathilde Caron, Piotr Bojanowski, Armand Joulin, et al. “Deep clustering for unsupervised learning of visual
features”. In: ECCV. 2018.
[4] Kaiming He, Haoqi Fan, et al. Momentum Contrast for Unsupervised Visual Representation Learning (MoCov1) In: CVPR 2020 .
[5] Xinlei Chen, Haoqi Fan, Ross Girshick, et al. “Improved baselines with momentum contrastive learning (MoCov2)”. In:
arXiv:2003.04297. 2020.
[6] Xinlei Chen, Saining Xie, Kaiming He. “An Empirical Study of Training Self-Supervised Vision Transformers (MoCov3)”. In: CVPR 2021.
[7] Junnan Li, Pan Zhou, Caiming Xiong, et al. “Prototypical contrastive learning of unsupervised representations”.
In: ICLR. 2021.
[8] Ishan Misra and Laurens van der Maaten. “Self-supervised learning of pretext-invariant representations”. In:
CVPR. 2020.
[9] Ting Chen, Simon Kornblith, Mohammad Norouzi, et al. “A simple framework for contrastive learning of visual
representations (SimCLRv1)”. In: ICML. 2020.
[10] Ting Chen, Simon Kornblith, Kevin Swersky, et al. “Big Self-Supervised Models are Strong Semi-Supervised
Learners (SimCLRv2)”. In: arXiv:2006.10029. 2020.
[11] Mathilde Caron, Ishan Misra, Julien Mairal, et al. “Unsupervised learning of visual features by contrasting
cluster assignments”. In: NeurIPS. 2020.
[12] Yuki Markus Asano, Christian Rupprecht, and Andrea Vedaldi. “Self-labelling via simultaneous clustering and
representation learning”. In: ICLR. 2020.
[13] Yonglong Tian, Chen Sun, Ben Poole, et al. “What makes for good views for contrastive learning”. In: NeurIPS.
2020.
[14] Jean-Bastien Grill, Florian Strub, Florent Altché, et al. “Bootstrap your own latent: A new approach to self-supervised learning”. In: NeurIPS. 2020.
[15] Jure Zbontar, Li Jing, Ishan Misra, et al. “Barlow Twins: Self-Supervised Learning via Redundancy Reduction”.
In: arXiv:2103.03230. 2021.
[16] Zhenda Xie, Yutong Lin, Zheng Zhang, et al. “Propagate Yourself: Exploring Pixel-Level Consistency for
Unsupervised Visual Representation Learning”. In: CVPR. 2021.
[17] Enze Xie, Jian Ding, Wenhai Wang, et al. “DetCo: Unsupervised Contrastive Learning for Object Detection”.
In: arXiv:2102.04803. 2021.
参考:
1、Self-Supervised Learning 入门介绍
2、自监督学习的一些思考
3、图解自监督学习,人工智能蛋糕中最大的一块