(����Ӧ����ȫ����һƪ����FEELVOS�IJ����ˣ����龫�����ҽ���ĺ�ϸ�£�����ò�����ͬѧ��������O(��_��)O��ת����ע��������
��ƪ��CVPR2019��������ƵĿ��ָ���·������÷���ע�ؿ��ٺͼ���������¼����ص㣺
- �������磬single pass
- Ѹ�٣�����Ҫʹ�õ�һ֡����
- �˵��ˣ����ڶ�Ŀ��ָ����֧�ֶ˵��˵�ѵ��
- ³���ԣ���DAVIS2017����֤���ϣ�J&F��65%
��ƪ���Ŀ�������Ϊ�����������������ܶ�˼·����Դ��֮ǰ�Ĺ����������ԱȲ���Ҫ���ķ�����Ч��ȷʵ������ͬʱҲ�����ߺȸ���������ģ�ʹ�õ�ͬһ�ҵ�����mobilenet���ᵽ����ȷ����������ֵ�ó����ǣ���Դ��TensorFlow���롣
���ĵ�ַ��FEELVOS
TF��Դ���룺here
���ĵ�����
- �ǵ�һƪ�����Ƶ��Ŀ��ָ�ͬʱ���Ƕ˵���ѧϰ�����硣
- ���һ��ѧϰembedding�����ķ�����ʹ��global matching��local matching��ʹ��ѧϰembedding�����ķ����Ƕ˵��˵ġ�
����
����
- ����DeepLabv3+��ȥ����������㣩���������Ϣ����������һ��embeeding��������ȡembedding ������
- ����embedding������ͨ��global matching�� local matching�õ�����distance map��
- ������distance map��DeepLabv3+�����������ǰһ֡��Ԥ����һ���ĸ��ɷֵ������룬���뵽һ��dynamic segmentation head�У����ͷ���籾����4����ȷ��������stack��Ȼ��õ�Ԥ������
- ���Ϲ��̶�֡�е�ÿһ��ʵ��������һ�Σ���������ʱ��������ʵ������Ŀ�������ӵġ�
�����������ݾͰ��������ᵽ��ÿ�����̣��ֳ�4�����֡�
�������
���ĵ�һ��������embedding��������������ͨ����DeepLabv3+���Ƴ�����㣩���ټ���һ��embedding��õ��ġ�
���������������������ص����������
- �������������ͬһ��ģ���ô���������ض�Ӧ��embedding����֮��ľ����ܽӽ���
- ����������ز�����ͬһ�࣬��ô���������ض�Ӧ��embedding�����ľ����Զ��
���Բ��Ѳ²⣬���embedding����ͼ����ʽ���Ǹ����������������ͼ��embedding�������г���������
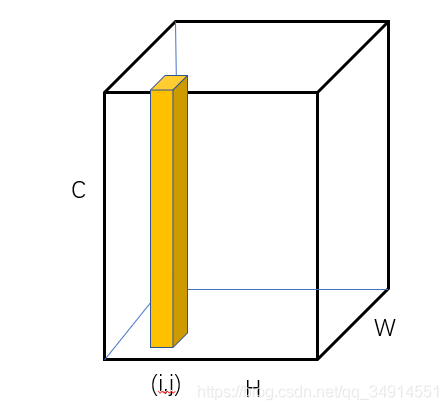
��ɫ����ǵ�(i,j)����embedding������
��������������embedding������ľ��롣
d(p,q)=1?21+exp(�O�Oep?eq�O�O2)d(p,q)=1-\frac{2}{1+exp(||e_p-e_q||^2)}d(p,q)=1?1+exp(�O�Oep??eq?�O�O2)2?
epe_pep?�Ƕ�Ӧ������p��embedding������d(p,q)d(p,q)d(p,q)��������p��q��embedding�ռ�ľ��롣����ԽС��˵��p��q������һ�࣬��֮��Ȼ��
������ͬ�������أ����ǿ��Ժ����ɵ����d��ֵӦ�úܽӽ�0����Ϊ0�����IJ�ͬ�������أ�d�ӽ�1����Ϊ1����ֵ������Լ�ԭ�����£�


������embedding layer��ϸ�ڣ�����һ����ȷ��������
ֵ��ע����ǣ�����p��q���Բ�ͬ�����롣����һ�����أ����Ǽ���Ϊp��p�������Ե�һ֡��embedding ���أ�Ҳ��������ǰһ֡��embedding���أ�����һ��q���������Ե�ǰ֡��embedding���ء�����p�IJ�ͬ����������distance map��Global distance map�� Local distance map���ֱ��õ�global matching��local matching��
Global matching
��һ֡�ͽ����������Ϊ�˻������embedding��������Ϊreference map�����Dz�����Ҫ�Ե�һ֡��Ԥ�⣬��Ϊ��һ֡�Ľ������֪�ġ�������VOS����Ļ���Ҫ�����ظ�һ�£����ⲻ�˽�VOS��ͬѧ����������
��ǰ֡�ͽ�deeplabv3+�õ�embedding������������Լ�����ţ�
- PtP_tPt?������t֡���������ؼ��ϡ�
- Pt,o?PtP_{t,o} \subseteq P_tPt,o??Pt?��������t֡���������O�����ؼ��ϡ�
- p��Ptp\in P_tp��Pt?������ǰ֡�е�һ�����ء���������һ���ֵı���Ƿ��ģ�����������ԭ�ģ�
- Gt,o(p)G_{t,o}(p)Gt,o?(p)����p������ض�Ӧ��global matching distance map��ֵ
��
Gt,o(p)=G_{t,o}(p)=Gt,o?(p)=
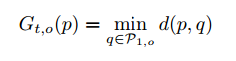
������Ҫ�õ�������global matching distance map����Ҫ�ѵ�ǰ֡���е����ص��embedding���������͵�һ֡������ͬһ���embedding������֮ǰ������������빫ʽ���㣬Ȼ��ȡ��С�ľ���ֵ��
���������ʵ�൱��ʱ�䡣���������������СΪ465x465�����㾭��deeplabv3+�õ�����4��������ͼ����������Ȼ�ܴ���Ȼ��������0.5��һ֡��
Local previous Frame Matching
����p����ǰһ֡�����ء����㹫ʽ��Ȼ��ȫ��ƥ�����ͼ�ķ��������ơ�
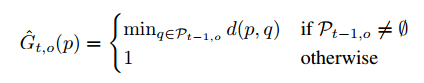
ע�ǰһ֡����û��Ŀ��ģ������и�otherwiseѡ����ǰһ֡û��Ŀ�꣬��ô�õ���map����1��
����ǰһ֡�͵�ǰ֡��Ŀ����ƶ�һ���Ǻ�С�ģ�û�б�Ҫ��ȥ�õ�ǰembedding feature��һ�����������еĵ�һ֡��embedding����������롣�ܵ�Flownet��������������һ��k����Ĵ�С�м�����롣Ҳ������һ��2*k+1�Ĵ���Լ��q��λ�á�����ʵ����ʹ�õ�������Ĺ�ʽ��
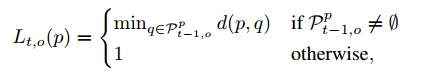
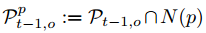
N������p��x��y����������k�����ؾ�������ؼ��ϡ�ע�������p��ʵ��q�������н������p��һ���Է��ţ�����������һ֡����q����ǰһ֡�����ء�
Dynamic �ָ�ͷ���磨head��
���ҷ��ֽ��������ij�����backbone��head�������ʻ㣩
��������������������distance map��ǰһ֡��Ԥ��������ǰ֡��deeplabv3+���������ͼ������embedding layer��
���ͷ����ṹ�����ĸ���ȷ��������ɣ�����һ��һά��feature map����Ԥ�����ע�����map����Ϊһ��Ŀ��Ԥ�����logits����֮ǰҲ���ˣ�����ʵ��Ŀ�궼Ҫ�����������������̡�����ÿ��ʵ������õ�һ��һά��feature map��������stackһ��ʹ��softmax����һ�������غ�labelѵ����

��������������ͼ��ʾ��
������Ϊ���������ÿһ��Ŀ�궼��Ҫ�����ָ����磬��������ʱ��ĵط�����backbone����ȡ��������һ�����ǹ����ģ�ֻ��һ�Ρ�
�����Ƿָ�ͷ����ľ���ϸ�ڡ�

ʵ��ϸ��
֮ǰ�ᵽ��global matching�е�ǰ֡��ÿ�����ض�Ҫ�͵�һ֡�����ص�embedding vector������룬���·�����ʵ��������Ϊÿһ��Ŀ���ز�������1024�����ص㡣
lossʹ�� bootstrapped cross entropy��
local matching��kΪ15
ʵ��
����ѵ��������ģ�ͣ��ֱ�ΪFEELVOS��ours����FEELVOS��ours��youtobe-vos���������������ѵ�����ݼ�����һ��ģ�ͽ�ʹ��DAVIS2017 trainset���ڶ���ģ�ͼ�ʹ��DAVIS2017 trainset��Ҳʹ��youtobe-vos dataset��
����ʵ��
�ָ�ͷ�������ĸ����룬���߷ֱ�disable����һЩ���룬����6��ʵ�顣֤����local matching��global matching����Ҫ���������ǻᵼ�����ܵĴ���½���
��������

����ֻ��ע���һ�С���������è�ı���û�б�dz���������Ϊ��һ֡è����̬û�б������������ܴӷָ�����лָ���������һ��maskTrack����������ԭ�����global matchingʹ�õ�ǰ֡���ں͵�һ֡����ϵ����������������֡��
��Ҫ���

ʵ���кܶ࣬����ʵ����ֻ��ϸ������ԭ�ģ������������ܷ��������Կ���FEELVOS����ٶȺ;��ȡ�
�ܽ�
FEELVOS������ʱ����Ϣ���������ݼ�����ʹ��һ��ķָ����ݼ���Ҳ���Dz���masktrack�Ƚ�֡��Ϊ��̬ͼ��
��ȻFEELVOS��global matching�����Ż���Ҳ�ᵽ�˽�Ϊһ��Ŀ�����1024�����ص�ʵ�ʺ�ȫ������û�д�����ܽ��ͣ�����û�и��õİ취�ᵽglobal matching���Ͼ���Ȼ��ʱ�䡣
δ����ĵط�
embedding layer����������յ������С��ԭͼ��1/4������ô��global matching��local matching�����֪������ͼ��map��ÿ��embedding���������ĸ�����أ���Щ��Ҫ��Դ����ܵ�֪��