昨天晚上看完了这篇论文。不得不说,这篇工作确实很棒,使用一个统一的模型,却能解决很多视觉任务。而且方式也是很简单,不需要设立各式各样复杂的condition。
论文和项目地址
updated on 2019.12.2
我之前一直以为SinGAN的训练是从原图crop出一些样本,用这些样本以及这些样本的下采样图像进行训练。今天再次读了论文,发现大错特错啊!!!所以做一些更正。
总览
先大致说下这篇论文是做什么的,以及如何做。
SinGAN在仅仅一张图像上训练,这张图片既是训练样本也是测试样本。在这张图像上训练完了之后,同样在这样图片上测试。如果你想换一张图像测试,就必须先在那张图像上训练,这是有异于其他GAN的。
~但不是整个图像送进网络,而是在一张图片上crop出可以重叠的patches~。
作者把原图按照一定的比例下采样,得到很多的下采样版本的图像,作者称这些样本为patch,用这些patches训练。patch的意思一般都是指从原图crop,就这一点把我误导了
SinGAN采用无条件GAN方式设计,而且是级联式的Generator-Discriminator pair的形式。每一个G-D都负责一种尺度**。作者发现,通过学习patch内部的数据分布,网络最终能在测试时输出保留原图中目标的结构以及形象,但是又不同于原图的真实图像。**
在下图就是作者举的例子。随着噪声z的不同,生成了一系列不同于原图,但保留原图结构的新图。看上去就是同一个相机在相同的风景区,在不同视角不同地方下进行一连串的拍摄。

创新点
- 一种统一的结构,能解决一些完全不一样的视觉任务: 绘制,编辑, 融合, 超分辨, 动画化。仅仅依赖一张图片。
- 产生高质量的,且能保留训练样本内部数据分布同时赋予输出图像新的模样的图像
- 所有的G和D都是相同的结构,网络简单。
从下图我们可以看出方法的用途,如果我们在一张风景图像训练,然后送入一张画图,然后网络将原图的数据分布赋予到由画图生成的新图像上,同时新图像还保留画图的样式。
如果我们在原图上crop出一个不同长宽比的patch,把这个patch直接粘贴到原图上,送进用原图训练好的网络测试,就能把细长的目标拉伸。
以及等等其他用途。太神奇了。

提出背景
GAN在最开始提出就是学习图像分布然后生成和训练图像类别相同的图像,那么这就有第一个限制,训练集的类别是具体的(Specific),一些无条件GAN通常都是这样的训练方式,在class-specific的数据集上训练,同时如果类别众多,性能就会出现下降。比如一些生成人脸的GAN用ImageNet训练,生成那些多种多样的类别的图像,效果其实很差的(这方面我做过实验),所以一般要加入其它条件来帮助训练,一般都是指定图像的类别送进网络作为条件(condition)。
另外一个限制就是图像需要很多张。如果我们仅仅在一张图片上训练, 非条件GAN中,目前这样的方法只适用于具体任务,比如超分辨,纹理扩展(? texture expansion)。
作者提出SInGAN,打破了两个限制。SinGAN就在一张图像上训练,不在乎图像的类别,不管数据集都单类的人脸数据等,还是多类的分类数据等,都只在一张图像上训练,自然不在乎图像的类别的。采用Unconditional GAN能处理很多种任务同样是首创。
另一方面, 从新的角度上诠释了生成图像。以往的GAN,往往都在提供了某一类的众多的图像作为训练集,然后生成器学习到这些样本中的相同特征的分布。,比如说人脸都有眼睛嘴巴等。那么我就用人脸举例子。然后测试的时候,输入噪声,网络就能输出带有人脸特征的人脸了。但SinGAN从新的角度,不去学习人脸类的共同特征,转而学习单一人脸图像的数据分布,这样网络可以生成这个人的脸,同时可能有不同视角下的这个人的脸。
以上我都是用人脸图像举例,实际上可以是任意图像,不限制类别。作者在论文中也没有使用人脸图像作为例子。
方法
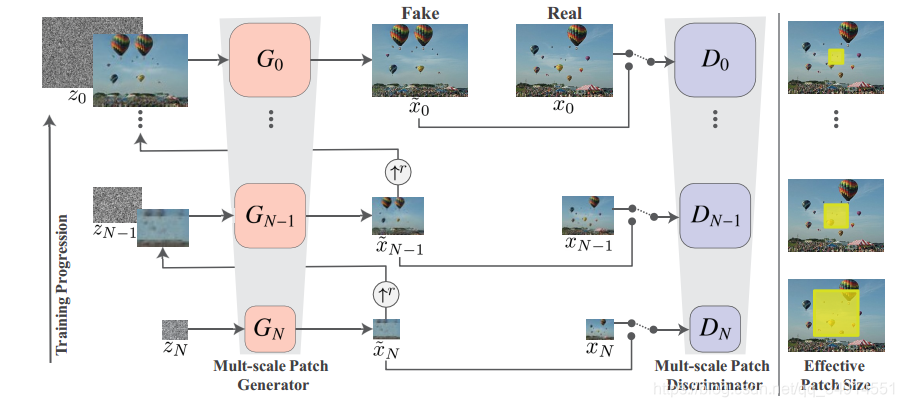
上图的结构乍一看很复杂,其实很简单,从最下面看开始看。
假设有N个尺度,最下面的第N个尺度是最粗糙的,最上面的尺度是最细的(finest)。
最下面的G的输入是高斯噪声z_N,输出
w~N=GN(zN)\tilde{w}_N = G_N(z_N) w~N?=GN?(zN?)
然后w~N\tilde{w}_Nw~N?上采样得到w~N↑r\tilde{w}_N \uparrow^rw~N?↑r, 送到GN?1G_{N-1}GN?1?中,同时送进GN?1G_{N-1}GN?1?还有zN?1z_{N-1}zN?1?,再往上都是这个套路。
再看另一边,生成的假图像w~\tilde{w}w~和经过resize的patch xxx送到D中,和普通GAN的思路是一致的。论文采用的D是马尔科夫判别器。
G和D的结构是相同的(我在想D不是要输出置信度吗,怎么会是全卷积的,但是马尔科夫D可能有特殊之处吧)。有5个3x3的卷积层构成,所以感受野是11x11。同时G输出的是后一个尺度(更粗糙尺度)所丢失的细节(残差学习),输出的丢失细节加上上采样得到的更粗糙的图,就变成了更细化更具体的图。
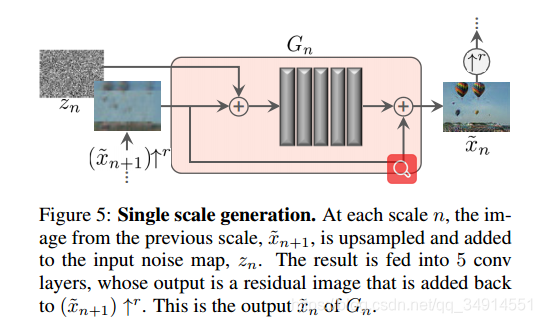
另外还有一些细节,,~诸如effective patch size是什么意思~,尺度N和上采样比例的关系,我没有细看。
effective patch size 的意思很好理解。最粗的那一个尺度上,输入的是原图经过下采样最小的patch,经过固定的11*11的感受野,因为输入的图像是原图缩小到很小的patch,即便是网络仅有很小的感受野,也能覆盖掉输入图像很大的区域,对应回原图,就是很大的区域。而越往细的尺度上,由于输入图像越来越大,感受野不变,能覆盖的尺度会越来越小。所以effective patch size越来越小,但也越关注细节,所以输出图像的细节更加丰富,逼真。
另外作者在论文第三页指明了,小的感受野的好处:
The GANs have small receptive fields and limited capacity, preventing them from memorizing the single image.
训练
总的损失函数分为两个部分
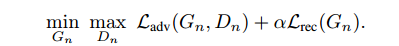
前面那一部分就是对抗损失,G和D互相博弈。
后面的部分是重构损失,其作用是确保有一组噪声图能产生xnx_nxn?, 是很重要的属性(给出了补充材料)
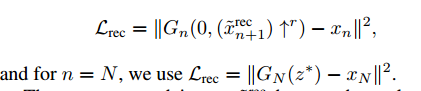
大致意思是,不加噪声生成的图像要和patch做L2loss,就是内容上重构。
另外有一些细节,如噪声方差的选取,我并没有看懂。
实验
作者实验部分写的非常详细。我只说两点。
作者开头探讨了在测试和训练中,选取尺度的问题。
在测试中的尺度影响
因为网络是多级的,在训练中有N个尺度,但是在测试中,可以使用更少的尺度,或者改变所使用的的尺度,来控制生成图像的变化。比如从第N-2个尺度开始,就会生成一些更真实的样本。下图的对比中,可以发现,从第N个尺度生成的斑马,有很多条腿。但是从第N-1个尺度开始,生成的样本就很真实了。而且对于细节保留的更多。
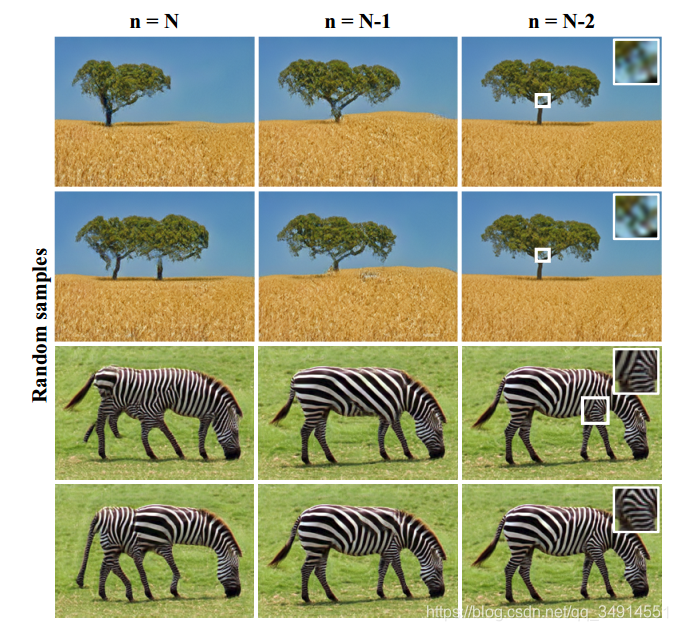
在训练中尺度的影响

选择更丰富的尺度,能捕获全局的结构,也是因为感受野大了。
尺度数目越小(意味着本身就从一个很细化的patch开始训练),仅仅能捕获到局部的纹理细节。丢失了全局的结构内容。
更多的应用请参见论文。就不一一叙述了。