这是CVPR19年的论文,通过语义流找寻两张图像中相同类别的目标(但不同实例)的对应点。
官方代码
首先说明两点,不同于一些特征点匹配的方法,该方法是找不同场景下(两种图像)中具有相同类别的目标之间的对应点。基于特征点匹配,比如superglue,是在同一场景下(视频的不同帧)中找寻点对点的关系。但SFNet是不同场景下。
比如下图,前两列给出两个场景,都包含人物和摩托车。后两张就是语义相似的点到点的连线。

简单解释语义流
SFNet不是第一篇提到语义流的文章。语义流自然和语义相关。在SFNet中,通过特征的矩阵相乘得到source image和target image 所有pairs的相似性。这一点和Attention是类似的,只不过矩阵相乘的两个对象来自不同的图像。语义流中的语义搞清楚了,无非就是用特征的语义相似性做匹配。那“流”是啥。我们知道光流,残差流,流是用来表示位置offset的向量,向量中含有x和y坐标的偏移量。那么语义流中的流就是两张图像中对应点的offset,即匹配之后的坐标差。
这个语义流的作用是啥呢。 注意上图的第三张图像,我没有介绍**,它的来源就是根据source 和target的语义流,把source图像warp(grid sample)到了target坐标下**。可以注意第三张的图像中,摩托车和人物的位置以及尺度都和第二张图像中的目标极其相似。根据语义流提供的offset, 可以通过grid_SAMPLE操作warp图像。 还可以用语义流把对应的mask也warp过来。

网络结构
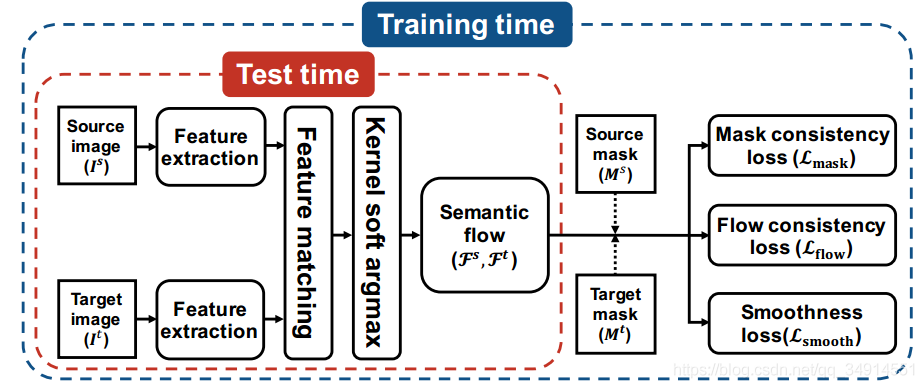
两张图像,一张是source,一张是target,它们通过一个resnet101网络得到res3和res4。backbone没有使用dilation conv,由于input size是320320。所以res3是2020的。 res4是1010的(个人觉得使用dilation conv效果会更好)。
然后res4上采样到2020。 两张图像的res3特征经过reshape,通过矩阵相乘得到corr_1;res4也同样,得到corr_2
corr_feat3 = self.matching_layer(src_feat3, tgt_feat3) # corr_1corr_feat4 = self.matching_layer(src_feat4, tgt_feat4) # corr_2corr_S2T = corr_feat3 * corr_feat4 # 把两个corr map 融合corr_S2T = self.L2normalize(corr_S2T) # 向量单位化, 除以模值
注意,通过转置corr map,我们可以从srouce到target的相似度和从target到source的相似度。
corr_S2T描述的是source 上每一点和target上所有位置的相似程度。 而我们想找的就是 source 上一点P和target上一点Q。其中Q是和P语义相似度最大的位置,也就是corr_S2T[q,p]是corr_S2T[:, p]中最大的值对应的位置。
那大家可能知道了,这不就是个argmax的事情吗。没错,在测试阶段,确实可以用argmax直接找到语义最相似的位置,但是训练阶段,argmax是不可求导的,如果使用argmax,网络没法端到端的训练。
接下来就是核心操作:kernel soft argmax、
kernel soft argmax
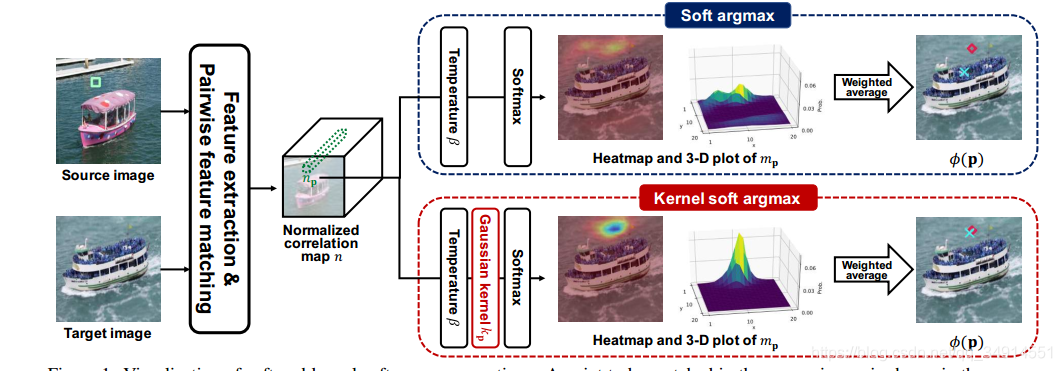
soft argmax是支持求导的,但是受到多峰值的影响。我们只关注和p点最相似的q点,但实际情况,p点对应的corr map,必定不止一个峰值点,而是存在一些和p点相似度大的非q点,亦或是一些由于网络的错判。但我们只关注q点。希望通过一种操作,能得到和p最相似的q点,亦或是接近q点的点。 因此作者提出kernel soft argmax,通过引入高斯核实现。整个模块是end to end的,完全可导。
从backbone中,我们已经获得了一个corr map(20x20)。对其做L2 normalization。接着使用argmax找到p位置对应另一张图的q的位置(x,y坐标)。p和q满足
q=argmaxcorr[p,...]q = argmax \quad corr[p,...]q=argmaxcorr[p,...]
然后根据得到的p对应的q的位置,得到以q为中心的高斯函数。即q的位置是1,其他位置的值逐渐降低。
idx = corr.max(dim=1)[1] # b x h x w get maximum value along channelidx_y = (idx // w).view(b, 1, 1, h, w).float()idx_x = (idx % w).view(b, 1, 1, h, w).float()x = self.x.view(1,1,w,1,1).expand(b, 1, w, h, w)y = self.y.view(1,h,1,1,1).expand(b, h, 1, h, w)# 高斯函数gauss_kernel = torch.exp(-((x-idx_x)**2 + (y-idx_y)**2) / (2 * sigma**2))gauss_kernel = gauss_kernel.view(b, hw, h, w)
然后用高斯核加权corr map,相当于把不属于最相似的位置的相似值用小于1的权值抑制了。
接着对corr map做softmax,同时用β\betaβ作为系数。作者提到β\betaβ越大,softmax就变成单峰值的分布函数。

另外有一些细节,为了softmax这步的数值是稳定的,作者是把corr MAP 减去了corr map(axis=1)的最大值
M, _ = x.max(dim=d, keepdim=True)x = x - M # subtract maximum value for stability # 所有值都小于0 指数运算的值就会都小于1 数值范围很稳定exp_x = torch.exp(beta*x)exp_x_sum = exp_x.sum(dim=d, keepdim=True)
接着就是执行公式2。用最终得到的M,加权每个坐标。就能得到在源图中的点p(坐标),与目标图中的哪个点最相似(坐标)。
我们可以理解为。kernel soft argmax希望让极值点对应的坐标,放大其影响。1.先是用高斯核加权,来降低其他峰值的数值;2. 然后用softmax进一步取极值(通知控制β\betaβ的大小。默认为50。 然后在采用soft argmax的做法,对坐标加权。得到的坐标就是q点了。
损失函数
SFNet的训练方法同样很关键。
作者采用了三个损失函数
- Mask consistency loss
- Flow consistency loss
- Smoothness loss.
Mask consistency loss
在我们得到了两张图的correspondences之后,我们当然想让其很准确,但如何能说明他们准确呢。作者使用了目标的mask来辅助。得到的correspondences可以用来做warp(同光流做warp),通过把target的mask warp到source,后者source warp到target域。然后用MSE优化
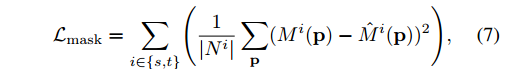
Flow consistency loss、
对得到的FLow offset也是如法炮制,使用得到的correspondences做warp。但我们更注重前景区域,所以需要mask作为系数。同时从source到target和从target到source的flow 场是相反的,所有这里是加号。当二者求和为0达到最优。即二者能对的上。

Smoothness loss.
对flow的x和y方向,求导。然后用mask加权
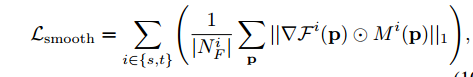
我对这个函数的理解是,希望能让网络对齐两个域(source and targer)中前景区域的流场的相对位置。
因为函数的优化方向是前景位置的导数为0。即流场中的x和y坐标在前景区域是大片大片都是一样的值。
数据来源
作者说,因为没有特别多的数据,所有backbone是固定的,只训练自定义的adaptive layer。
而且训练所需要的target和source组成 pair,都是来自同一张图像,采用了affine transform得到(参见数据集模块的代码)。

def affine_transform(self, x, theta):theta = theta.view(-1, 2, 3)grid = F.affine_grid(theta, x.size())x = F.grid_sample(x, grid)return x
我自己的实验
我试着复现他们top 60的点对应的图。但是不知道这部分正确的代码是啥,作者没有释放。我就自己写了一个,但目前效果不好,github上已经提了issue,但还没有回复。
