来自云从,即将开源?
paper是做文本查询对应视频片段的工作,即给一个文本作为query,需要知道一段视频中,满足这个query描述的起止时间和终止时间。
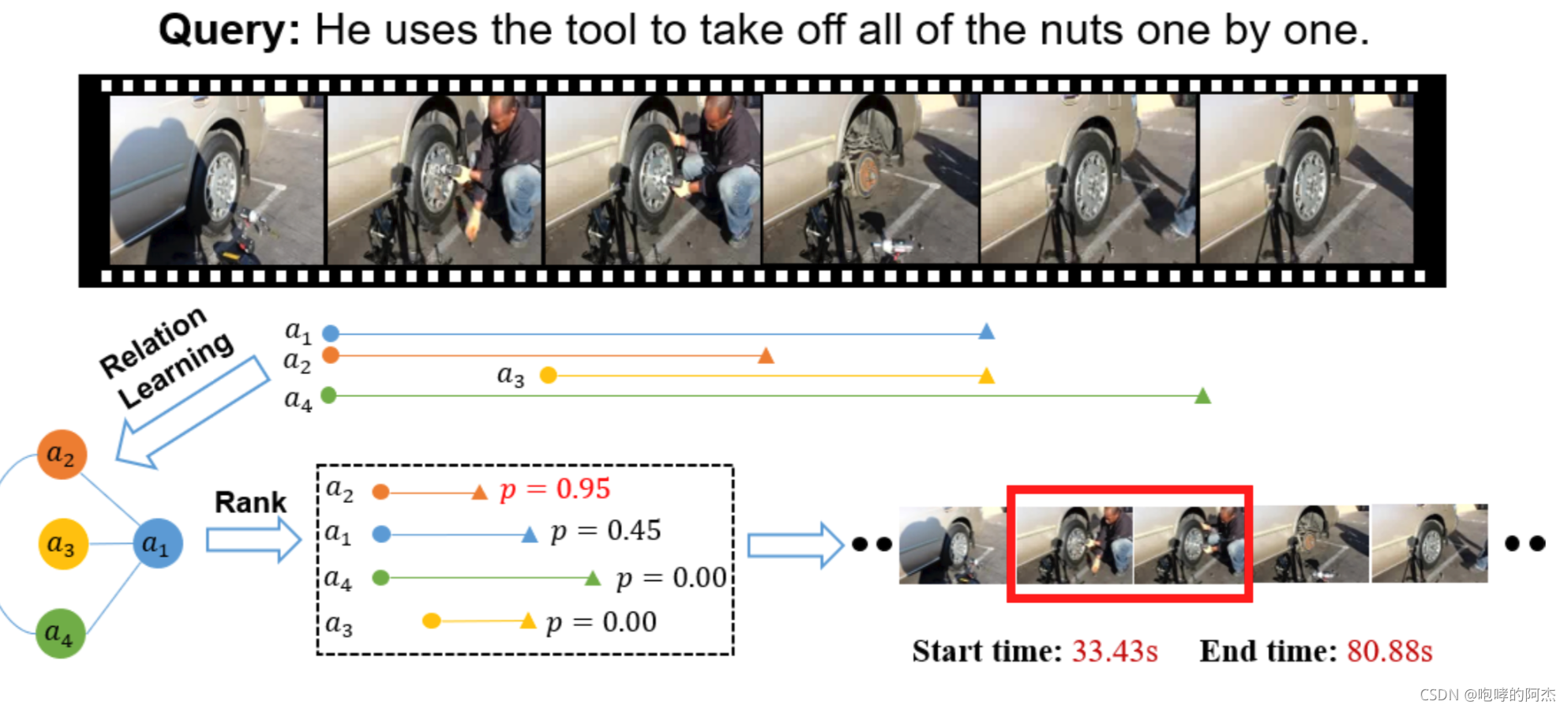
输出的时间戳满足属于连续时间段。如上图所示,红色框中起止和终止时间就是模型的预测输出。
背景
众多的temporal language grounding(TLG)方法,注重整个句子和视频的关系,而忽略了每个token和moment的关系,后者是一种更加细粒度的语言信息。而且还忽略了多个候选框之间的联系,暴力的采用ranking方法,单独处理每个候选框,这种方式忽略了不同候选框之间的时序和语义的依赖性(有点强行解释,没有给出一个例子,比如什么情况下,候选框之间的时序和语义存在依赖,以及二者到底是啥意思)。
paper提出relation-aware network(RaNet),使用从粗到细交互,不仅挖掘句子-moment的关系,还有token(词)-moment的关系。然后对多个候选框,使用GCN(图卷积网络)提取不同moment的关系。
整个模型分成5个部分:
- 文本特征提取器和视频特征提取器
- 多选择答案生成器(所有可能的答案都列出来)
- query和选择交互模块,进行多模态建模
- 多选择之间的关系挖掘模块:对多个候选框的关系信息进行挖掘
- 候选框rank模块:选择出匹配最好的候选框
文本 or 视频 特征提取器
视频提取器:先使用一些视频模型,如vgg,I3D,C3D得到snippets的特征,然后使用GC-NeXt提取出特征,得到V^∈RC×T\hat{V} \in R^{C \times T}V^∈RC×T。
文本提取器:用的3层bi-LSTM得到文本特征Q^∈RC×L\hat{Q} \in R^{C \times L}Q^?∈RC×L
多选择生成器(multi-choice)
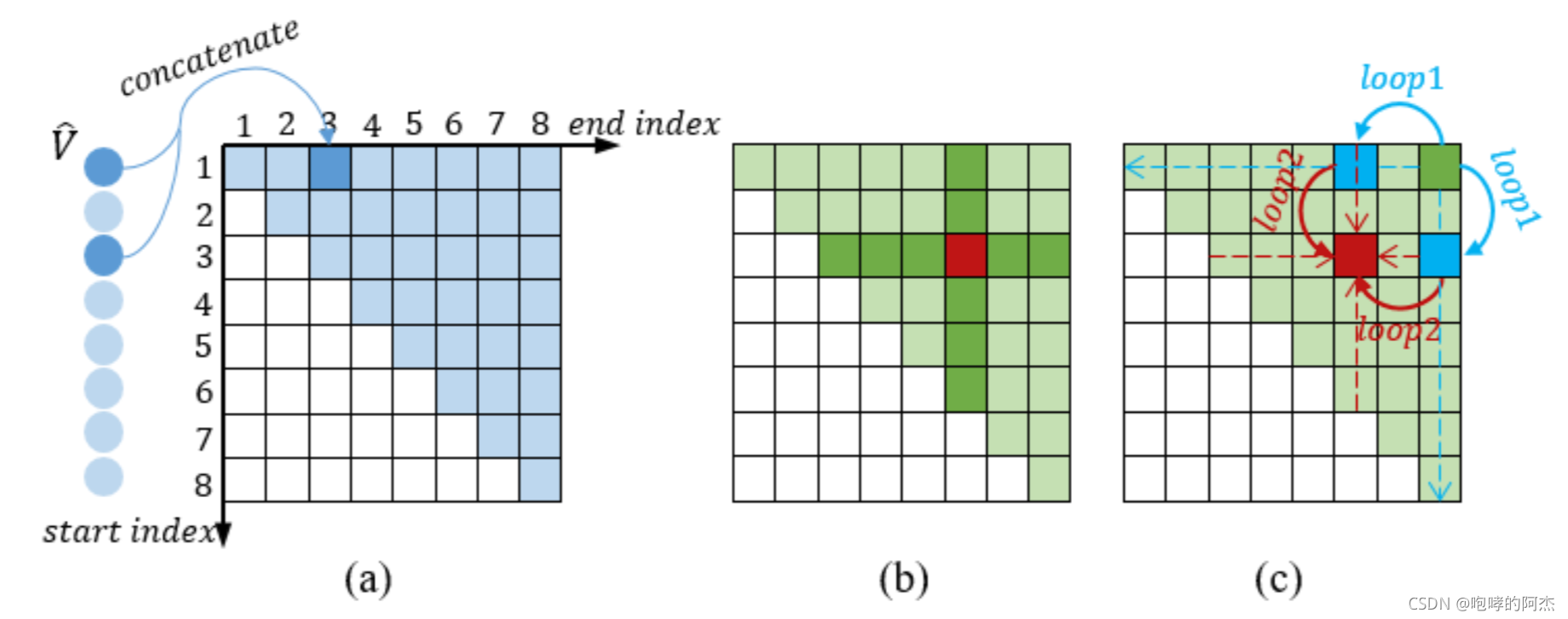
选择的意思就是候选框、多个answer。论文遍历了所有的有可能的答案:凡是起止时间小于终止时间的片段,都加入到一个集合A中,如图(a)中的蓝色块。其中(1,3)位置的深蓝色块代表了起止时间1,终止时间为3的候选结果。
接着要为每个候选结果初始化一个特征。初始化方式也很简单,就是把起止时间和终止时间对应的两个特征拼接在一起。因此得到集合A的特征FAF_AFA?:

Choice-Query Interactor
得到FAF_AFA?特征之后,还需要结合token-level和sentence-level的文本特征。
sentence-level特征用如下方式得到:

其中的Ψ\PsiΨ就是从文本特征中得到sentence-level特征的操作,具体是max pooling。
token-level特征采用Attention机制获得。计算文本特征Q^\hat{Q}Q^?和视频特征V^\hat{V}V^的相似矩阵R。然后用文本特征表示视频特征,得到F2F_2F2?
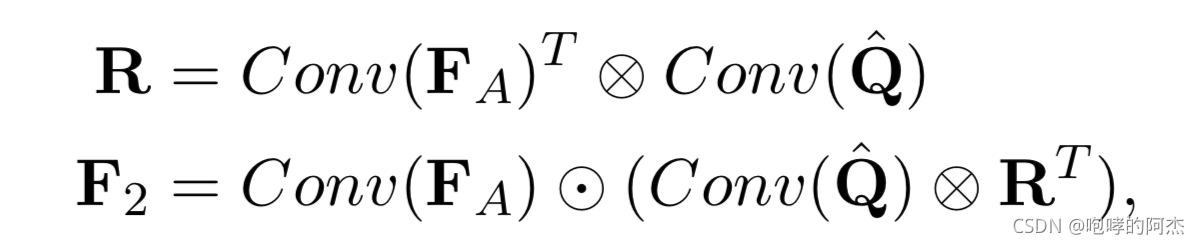
Multi-Choice Relation Constructor
使用GCN去聚合在时间上重叠的那些候选结果的特征,以此探索不同候选框之间的关系。既然需要使用GCN,则图的节点和边的构建方式必须说明一下:
- 节点:每个候选(t_s, t_e)都是图中的节点
- 边:凡是具有相同的起始时间或者终止时间的候选节点,都是相邻节点。
受到CCNet的启发,paper采用十字attention聚合方式降低计算量。
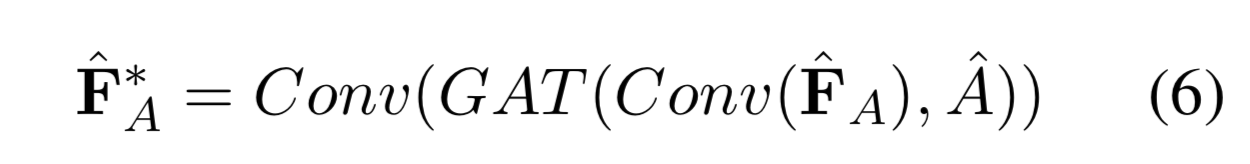
A^\hat{A}A^是邻接矩阵。
Answer Ranker
将答案集A的两个特征进行拼接,然后使用1层FC接sigmoid预测置信度,服务于候选框的排序。
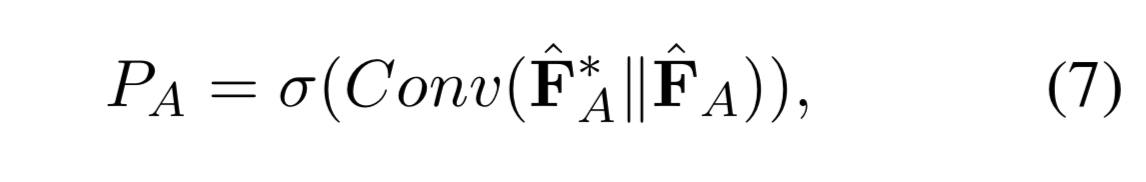
PAP_APA?就是A中每个候选框的质量打分。
损失函数
使用binary CE。标签的分配原则是:
- 如果候选框和GT的IOU大于阈值θmax\theta_{max}θmax?,则该候选框作为正例,标签为1
- 如果IOU在θmin\theta_{min}θmin?和θmax\theta_{max}θmax?之间,标签为x(见下图)
- 如果IOU低于θmin\theta_{min}θmin?,标签为0

个人看法
我觉得起码有3个点可以改进
- sentence-level特征使用max pooling获得,这个是否可以换成Cls token。不过bi-lstm没有cls token,因此语言模型可以使用Bert?
- 答案集A的特征初始化,只使用了起止特征,中间的特征完全没利用。中间时刻的特征应该也挺关键才对。
- 最终采用分类来训练,标签的分配使用IOU,这点和目标检测相似。但是否可以加上框回归的功能,使其对边界的分割更加准确。
最后,期待开源吧。