ЛљБОЛЗОГУшЪіЃК
centos6.8+sqoop1.4.6
ДЫЭтsqoopашвЊвРРЕгкhadoopЁЃдкетРяашвЊгУЕНhbaseЃЈашвЊвРРЕzookeeperЃЉЁЂhiveгыmysqlЙиЯЕЪ§ОнПтжЎМфЕФЪ§ОнЕМШы/ЕМГіЃЌдкДЫЛљБОЕФвРРЕЛЗОГЖМвбДюНЈКУЁЃ
вЛЁЂsqoopАВзАХфжУ
1 аоИФsqoop-env.sh(mv from sqoop-tmplate-env.sh)ЃЌОпЬхИљОнздМКЕФЛЗОГвдМАашЧѓРДХфжУЁЃ
export HADOOP_COMMON_HOME=/usr/SFT/hadoop-2.7.2
export HADOOP_MAPRED_HOME=/usr/SFT/hadoop-2.7.2
export HIVE_HOME=/usr/SFT/hive-1.2.1
export ZOOKEEPER_HOME=/usr/SFT/zookeeper-3.4.12
export ZOOCFGDIR=/usr/SFT/zookeeper-3.4.12
export HBASE_HOME=/usr/SFT/hbase-1.3.1
2 НЋmysql-connector jarАќПНБДЕНlibФПТМЯТ
3 ВтЪдЪЧЗёАВзАГЩЙІ
bin/sqoop help
4 ВтЪдЪЧЗёФмЙЛСЌНгЕНmysqlЃЌФмЯдЪОГіФПБъЪ§ОнПтЯрЙиаХЯЂБэУївбОПЩвдГЩЙІСЌНгСЫ
/usr/SFT/sqoop-1.4.6/bin/sqoop list-databases --connect jdbc:mysql://chdp11:3306/ --username root --password root
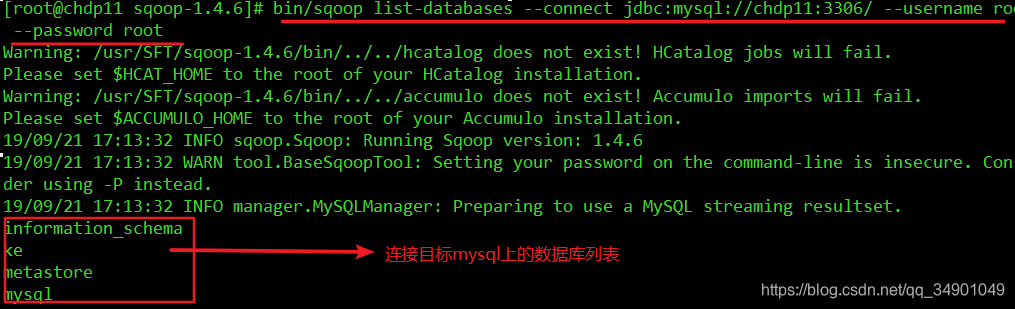
ЯШРДолвЛолЯрЙиИХФюЃЈsqoopЪЧHadoopДѓЪ§ОнЬхЯЕеѓгЊЕФЃЌШчДЫОЭШнвзБцЮіФкЭтСЫЃЉ
ЕМШыЃЈimportЃЉЪ§ОнДгЙиЯЕаЭЪ§ОнПтЃЈШчmysqlЃЉЕМШыЕНДѓЪ§ОнДцДЂМмЙЙЃЈhive hbaseЃЉ ЕМГіЃЈexportЃЉЪ§ОнДгДѓЪ§ОнДцДЂМмЙЙЕМЕНЙиЯЕаЭЪ§ОнПтЃЈШчmysqlЃЉ
ЖўЁЂЛљБОВйзї
1ЁЂmysqlЪ§ОнзМБИ
ДДНЈБэЃЌВхШыЪ§Он
create table stu(
id varchar(10) primary key auto_increment ,
name varchar(20),
age int(10)
);
ЫГБуИДЯАЯТmysqlЃЌгУШ§жжЗНЪНВхШыЪ§ОнЃЌИіШЫШЯЮЊБШНЯбЯНїЕФЗНЗЈЪЧжИЖЈСаВхШыЁЃ
insert into stu values(null,'wangwu' , 13);
insert into stu(id,name,age) values(null,'alex' , 16);
insert into stu(name,age) values('tom' , 14);
2 ШЋБэЕМШыЕНhdfs(ШєжИЖЈФПТМВЛДцдкЛсздЖЏДДНЈ)
#load all of data frome target table
bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--target-dir /sqoop/data \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
ПЩвдПДЕНЦєЖЏСЫMRШЮЮё
3 ВПЗжБэЪ§ОнВщбЏЕМШыЕНhdfs(зЂвтЪЧМђЕЅВщбЏ)
#зЂвт$дкБЛЫЋв§КХАќЙќЪБЕФзжЗћзЊвхЮЪЬт
#query table to import , usingЃЈmustЃЉ $CONDITIONS in where clause to remain data orderly
bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--query 'select name,age from stu where age<=15 and $CONDITIONS;'
--target-dir /sqoop/data \
--delete-target-dir \
--num-mappers 1 \
4 жИЖЈСа ЁЂааЙ§ТЫЕМШыЕНhdfsЃЈЪЕМЪгУЕФБШНЯЩйЃЉ
bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--columns name,age \
--where id="1" \
--target-dir /sqoop/data \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
5 ЕМШыЕНhive
bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table sq_stup
зЂЃК
1 Ъ§ОнЕМШыЪБЯШНЋЪ§ОнЩЯДЋЕНhdfsЕФСйЪБФПТМЃЌЖјКѓвЦЖЏЕНhiveдЊЪ§ОнЖдгІЕФЪ§ОнФПТМ,
гывЛДЮЕМШыЯрБШаЇТЪЯрВюВЂВЛЛсЬЋДѓЃЌвђЮЊЕкЖўДЮвЦЖЏЪ§ОнЃЈmvЃЉЪБжЛЪЧаоИФnamenode
дЊЪ§ОнЃЌЖјВЛЛсвЦЖЏЪЕМЪЪ§ОнДцЗХЕФЮЛжУЁЃ
2 дкЪ§ОнЕМШыжаШєhiveВЛДцдкжИЖЈБэдђЛсздЖЏДДНЈЁЃ
6 ЕМШыЕНhbase
#split by жИЖЈЖрИіrowkeyЦДНгЪБЕФЗжИєЗћЃЌШчЯТrowkeyЛсБЛзщКЯГЩЁАid-ageЁБЕФФЃЪН/usr/SFT/sqoop-1.4.6/bin/sqoop import \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--columns "id,name,age" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id","age" \
--hbase-table "sq_stup" \
--num-mappers 1 \
--split-by "_"
зЂЃК
КЭhiveЕФБэздЖЏДДНЈВЛЭЌЃЌsqoop1.4.6жЛжЇГжHBase1.0.1жЎЧАЕФАцБОздЖЏДДНЈБэ
етРягУЕФЪЧhbase-1.3.1ЃЌЫљвддкДЫжЎЧАЯШДДНЈвЛЯТБэАЩ
hive (default)>create 'sq_stup','info'
7 Ъ§ОнЕМГіЕНmysql
HIVE/HDFSЕНRDBMS/usr/SFT/sqoop-1.4.6/bin/sqoop export \
--connect jdbc:mysql://chdp11:3306/test \
--username root \
--password root \
--table stu \
--columns "name,age" \
--num-mappers 1 \
--export-dir /sqoop/data \
--input-fields-terminated-by "\t"
зЂЃК
1ЁЂMysqlжаШчЙћБэВЛДцдкЃЌВЛЛсздЖЏДДНЈЃЌЙЪЖјвЊздааДДНЈ
2ЁЂдкДЫЕМШыЪ§ОнЙ§ГЬжаШєГіЯжДэЮѓгаЪБВЛЛсдкПижЦЬЈДђгЁЃЌжЛФмВщПДРњЪЗЗўЮёЦїСЫЃЈМЧЕУЦєЖЏyarnРњЪЗЗўЮёЦїЃЉ
3ЁЂзЂвтЕМГідЪ§ОнвЊКЭФПБъЪ§ОнЕФСаЪ§ОнРраЭвЛвЛЖдгІвдМАСаЪ§СПашвЊЯрЕШЃЌзюКУжИЖЈвЊЕМГіЕФЪ§ОнСа
SqoopЕМШыЕМГіNullДцДЂвЛжТадЮЪЬт
4ЁЂHiveжаЕФNullдкЕзВуЪЧвдЁА\NЁБРДДцДЂЃЌЖјMySQLжаЕФNullдкЕзВуОЭЪЧNullЃЌЮЊСЫБЃжЄЪ§ОнСНЖЫЕФвЛжТадЁЃдкЕМГіЪ§ОнЪБВЩгУЈCinput-null-stringКЭЈCinput-null-non-stringСНИіВЮЪ§ЁЃЕМШыЪ§ОнЪБВЩгУЈCnull-stringКЭЈCnull-non-stringЁЃ
5ЁЂSqoopЪ§ОнЕМГівЛжТадЮЪЬт
ШчSqoopдкЕМГіЕНMysqlЪБЃЌЪЙгУ4ИіMapШЮЮёЃЌЙ§ГЬжага2ИіШЮЮёЪЇАмЃЌФЧДЫЪБMySQLжаДцДЂСЫСэЭтСНИіMapШЮЮёЕМШыЕФЪ§ОнЃЌДЫЪБРЯАхе§КУПДЕНСЫетИіБЈБэЪ§ОнЁЃЖјПЊЗЂЙЄГЬЪІЗЂЯжШЮЮёЪЇАмКѓЃЌЛсЕїЪдЮЪЬтВЂзюжеНЋШЋВПЪ§Оне§ШЗЕФЕМШыMySQLЃЌФЧКѓУцРЯАхдйДЮПДБЈБэЪ§ОнЃЌЗЂЯжБОДЮПДЕНЕФЪ§ОнгыжЎЧАЕФВЛвЛжТЃЌетдкЩњВњЛЗОГЪЧВЛдЪаэЕФЁЃ
ЙйЭјЃКhttp://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html
Since Sqoop breaks down export process into multiple transactions, it is possible that a failed export job may result in partial data being committed to the database. This can further lead to subsequent jobs failing due to insert collisions in some cases, or lead to duplicated data in others. You can overcome this problem by specifying a staging table via the --staging-table option which acts as an auxiliary table that is used to stage exported data. The staged data is finally moved to the destination table in a single transaction.
ЈCstaging-tableЗНЪН
sqoop export --connect jdbc:mysql://192.168.137.10:3306/user_behavior --username root --password root --table stu --columns username,password --fields-terminated-by ЁА\tЁБ --export-dir ЁА/user/hive/warehouse/tmp.db/stu${day}ЁБ --staging-table stu --clear-staging-table --input-null-string ЁЎ\NЁЏ
Ш§ЁЂНХБОДђАќ
ЪЙгУНХБОПЩвдЗНБуЖЈЪБШЮЮёЕФХфжУжДаа
1 ДДНЈвЛИі.optЮФМўБраДsqoopНХБО
#sq_expToMysql.optexport
--connect jdbc:mysql://chdp11:3306/test
--username root
--password root
--table stu
--columns "name,age"
--num-mappers 1
--export-dir /sqoop/data
--input-fields-terminated-by "\t"
2 ЪЙгУsqoopЙЄОпжДааИУНХБО
/usr/SFT/sqoop-1.4.6/bin/sqoop --options-file sq_expToMysql.opt
ЫФЁЂДэЮѓећРэ
1ЁЂsqoop exportЕМГіЪ§ОнЪБГіДэЃЌ CanЁЏt export data, please check failed map task logЁNoSuchElementException
2ЁЂ ERROR sqoop.Sqoop: Error while expanding arguments