一、最小二乘法
狭义的最小二乘,指的是在线性回归下采用最小二乘准则(或者说叫做最小平方),进行线性拟合参数求解的、矩阵形式的公式方法。所以,这里的「最小二乘法」应叫做「最小二乘算法」或者「最小二乘方法」,百度百科「最小二乘法」词条中对应的英文为「The least square method」。狭义的最小二乘方法,是线性假设下的一种有全局最优的闭式解的参数求解方法,最终结果为全局最优;
而广义的最小二乘,指的是上文提到过的最小二乘准则,本质上是一种evaluation rule或者说objective funcion,这里的「最小二乘法」应叫做「最小二乘法则」或者「最小二乘准则」,英文可呼为LSE(least square error)。
这两种方法的目的相同,并且对于损失函数的定义都是相同的--求得损失函数的最小值,使得假设函数能够更好的拟合训练集数据。但是明显也是有区别的:
计算上,最小二乘法直接计算损失函数的极值,而梯度下降却是给定初始值,按照梯度一步步下降的方式取得局部最小值,之后再选定其他初始值,计算-比较。
数学上,最小二乘法直接使用极值,将极值作为最小值。其假定有二:1,损失函数中极值就是最小值。2,损失函数具有极值。而梯度下降则不同,梯度下降并没有什么假定,是利用函数中某一点的梯度,一步步寻找到损失函数的局部最小值,之后对多个局部最小值进行比较(选定不同的初始值),确定全局最小值。
总体来说:最小二乘法计算简单,但梯度下降法更加通用!
最小二乘法是所有有数学思维的人面对这个问题第一想到的方法,最直接最不拐弯抹角的方法。就是求多元函数极值,这就是最小二乘法的思想!其实根本不用把最小二乘法想的多么高大上,不就是求极值嘛~
学过大学高等数学的人应该都知道求极值的方法:就是求偏导,然后使偏导为0,这就是最小二乘法整个的方法了,so easy啊~

最后使所有的偏导等于0

然后解这个方程组就可以得到各个系数的值了
二、梯度下降法
我们注意到最小二乘法最后一步要求p个方程组,是非常大的计算量,其实计算起来很难,因此我们就有了一种新的计算方法,就是梯度下降法,梯度下降法可以看作是 更简单的一种 求最小二乘法最后一步解方程 的方法
虽然只是针对最后一步的改变,不过为了计算简便,仍然要对前面的步骤做出一些改变:
recall上面的最小二乘法,我们有一个这样子的式子,就是所有误差的平方和:

假设有m个数据,2个系数(θ?和θ?),我们要对最小二乘法的Q稍加改变,变成代价函数J,虽然用不同的字母表示了,但是他们的含义是一模一样的啦~
前面的1/2m系数只是为了后面求导的时候,那个平方一求导不是要乘一个2嘛,然后和1/2m的2抵消就没了,变成如下:

然后θ?和θ?分别是这样子被计算出来的(其中:=为赋值的意思):

这个计算方法其实理解起来比较难,那么我们先来看看这个J函数的图像吧,J函数是关于θ?和θ?的函数,因此是三维的,为了使J的值最小,也就是高度最。相当于一个人要下山,下到海平面最低的地方,在图中就是蓝色部分,那就是最低的地方
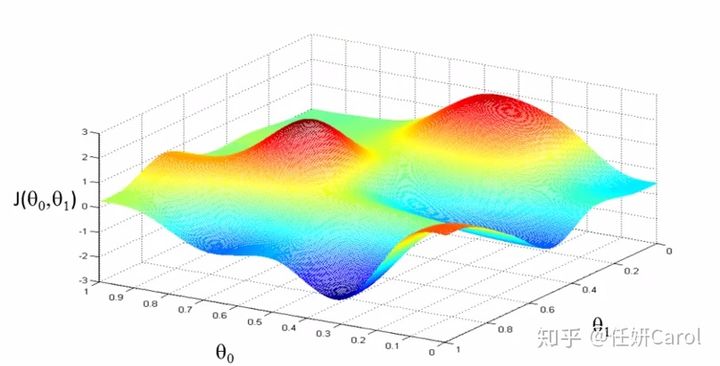
再想象这个人,要下到海平面最低的地方有很多条路啊,他可以绕着山头一圈一圈的下,像盘山公路一样(但没有人这样下山的,要走的距离也太长了8),最省力的方法就是按照梯度的方向下山,如图所示:
梯度:梯度是一个向量,梯度的方向就是最快下山,或者说沿着变化率最大的那个方向
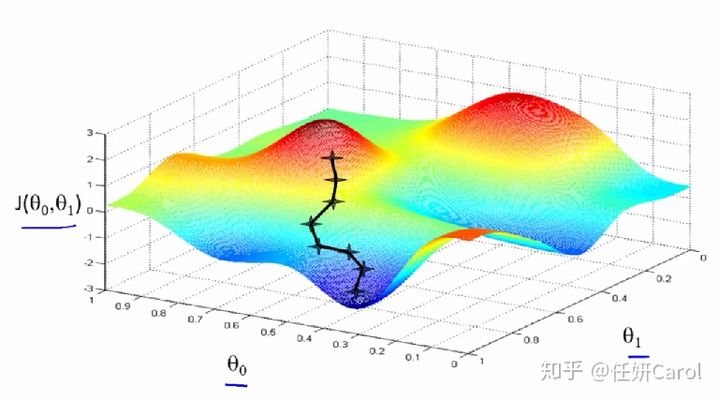
我们再来看一下

这个一个反复迭代的式子,就是初始的时候,先找一个点(θ?,θ?)(可以随便找),然后在这个点沿着梯度下降的方向,即这个向量的方向
![]()
梯度下降方法的问题:
每一步走的距离在极值点附近非常重要,如果走的步子过大,容易在极值点附近震荡而无法收敛。
解决办法:将alpha设定为随着迭代次数而不断减小的变量,但是也不能完全减为零。
最小二乘法的目标:求误差的最小平方和,对应有两种:线性和非线性。线性最小二乘的解是closed-form即 ,而非线性最小二乘(构造的拟合函数是非线性的,如神经网络,同时使用的损失函数是均方差。)没有closed-form,通常用迭代法求解。
,而非线性最小二乘(构造的拟合函数是非线性的,如神经网络,同时使用的损失函数是均方差。)没有closed-form,通常用迭代法求解。
迭代法,即在每一步update未知量逐渐逼近解,可以用于各种各样的问题(包括最小二乘),比如求的不是误差的最小平方和而是最小立方和。
梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。
牛顿法是另一种经常用于求解非线性最小二乘的迭代法。
还有一种叫做Levenberg-Marquardt的迭代法用于求解非线性最小二乘问题,就结合了梯度下降和高斯-牛顿法。
三、最小二乘法VS最大似然估计

极大似然需要满足一个假设,即:数据中的每一个样本都是独立同分布的。
- 不同
对于最小二乘法,当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使模型最好地拟合样本数据,也就是使估计值和观测值之差的平方和最小。而对于最大似然法,当从模型中随机抽取n组样本观测值之后,最合理的参数估计量应该使得从模型中抽取的该n组样本观测值的概率最大。显然,这是从不同的原理出发的两种参数估计方法。
- 相同
在最大似然法中,通过选择参数,使已知数据在某种意义下最有可能出现,而某种意义通常指似然函数最大,而似然函数又往往指数据的概率分布函数。与最小二乘法不同的是,最大似然法需要已知这个概率分布函数,这在实践中是很困难的。一般假设其满足正态分布函数的特性,在这种情况下,最大似然估计和最小二乘估计相同。
最小二乘法以估计值与观测值的差的平方和作为损失函数,极大似然法则是以最大化目标值的似然概率函数为目标函数
处理线性回归并假设单一样本的概率函数为正太分布时,通过极大似然估计法得到的模型优化的目标函数和最小二乘法下的目标函数是相同的。
参考:
https://blog.csdn.net/lu597203933/article/details/45032607
https://blog.csdn.net/FrankieHello/article/details/81432769
最大似然估计和最小二乘法怎么理解? https://www.zhihu.com/question/20447622
四、牛顿法
如何通俗易懂地讲解牛顿迭代法? https://blog.csdn.net/ccnt_2012/article/details/81837154
https://www.jianshu.com/p/0f864a4c3b38
牛顿法一般用来求解方程的根和求解极值。
数值优化算法除了梯度下降法外还有比较常用的一种方法是牛顿法。对于非线性方程,可以用牛顿迭代法进行求解,它收敛速度快。
基本思想是:对于非线性函数f(x),根据泰勒公式得到x附近某个点xkxk展开的多项式可用来近似函数f(x)的值,该多项式对应的函数为F(x),求得F(x)的极小值作为新的迭代点,然后继续在新的迭代点泰勒公式展开,直到求得的极小值满足一定的精度。
牛顿法的原理
基本牛顿法是一种是用导数的算法,它每一步的迭代方向都是沿着当前点函数值下降的方向。 “切线法”找下一次的迭代点
我们主要集中讨论在一维的情形,对于一个需要求解的优化函数,求函数的极值的问题可以转化为求导函数。
当应用于求解最大似然估计的值时,变成?′(θ)=0的问题。这个与梯度下降不同,梯度下降的目的是直接求解目标函数极小值,而牛顿法则变相地通过求解目标函数一阶导为零的参数值,进而求得目标函数最小值。



牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;(牛顿法比梯度下降法速度要快)
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
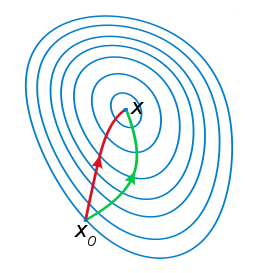
注:红色的牛顿法的迭代路径,绿色的是梯度下降法的迭代路径。
五、共轭梯度法(Conjugate Gradient)
共轭梯度法是介于最速下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
梯度下降法及其实现 https://www.jianshu.com/p/c7e642877b0e 很好地讲解了梯度下降法的原理
最小二乘法与梯度下降的区别
https://www.cnblogs.com/yuzhen233/p/8520142.html
https://www.zhihu.com/question/20822481
https://blog.csdn.net/sinat_27652257/article/details/80657397 还讲解了最小二乘与极大似然的区别
常见的几种最优化方法 https://www.cnblogs.com/shixiangwan/p/7532830.html