本文是关于MRT-to-CT。
首先,提出一个基本的三维FCN结构来估计从MRI得到的CT图像。三维操作可以更好地对三维空间信息进行建模,从而可以解决切片间的不连续问题。其次,利用对抗式训练策略对所设计的网络进行训练。还在生成器的损失函数中加入了一个图像梯度差项(image gradient difference),目的是保持产生的CT的锐度。最后,使用Auto-Context模型对生成器的输出进行迭代细化。
一、文中提到的loss:
1. adversarial loss:
判别器D的 loss 函数:
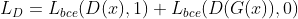
x:输入的MRI图像
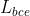 :二元交叉熵loss,
:二元交叉熵loss,
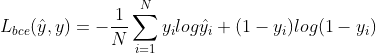 ,
,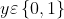 ,
,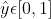
N:一个minibatch中的样本数量
生成器G的 loss 函数:
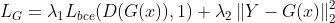
包括一个adversarial term和一个reconstruction error,其中,Y是相对应的真实CT。
2. gradient difference loss(gdl)
首先要了解图像梯度的概念:https://blog.csdn.net/image_seg/article/details/78790968
为了处理L2损失函数(G的loss)造成的固有模糊预测,在生成器训练中嵌入图像梯度差损失函数。
生成的CT与真实CT的梯度差损失(gdl):
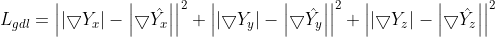
Y是真实图像,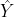 是生成的图像。这个损失函数试图最小化预测图像和真实CT之间梯度大小的差异。这样,预测的数据将尝试保留具有强梯度的区域(例如边缘),以便有效地补偿L2项。最后,将用于训练生成器G的总损失定义为所有项的加权和,如下式所示:
是生成的图像。这个损失函数试图最小化预测图像和真实CT之间梯度大小的差异。这样,预测的数据将尝试保留具有强梯度的区域(例如边缘),以便有效地补偿L2项。最后,将用于训练生成器G的总损失定义为所有项的加权和,如下式所示:
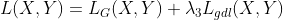
二、训练方式:
训练以交替的方式进行:首先,通过获取一小批真实CT数据和一小批生成的(G的输出)数据来更新D。然后,使用另一小批样本(包括MRI及其对应的CT)更新G。
三、网络结构:
在体系结构方面,使用了批处理规范化,并且避免使用池化层,因为池化层降低了特征图的空间分辨率。虽然这一特性在某些任务中是可取的,例如图像分类,但在图像预测任务中不可取,因为在预测过程中需要精确捕捉细微的图像失真。
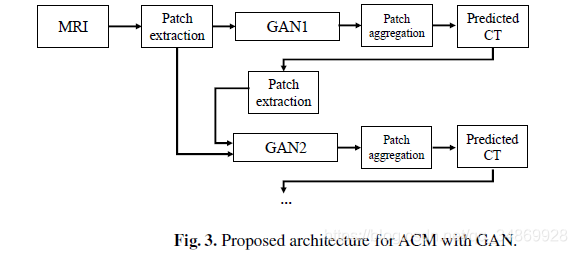
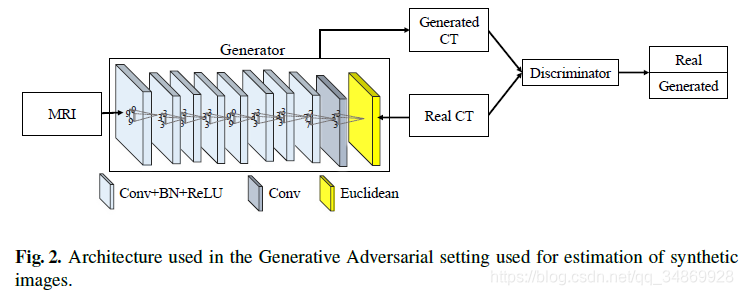
下图展示了该网络的体系结构。
1. 生成器具有上面提到的约束,其中数字表示过滤器的大小。该网络以MRI图像为输入,并尝试生成相应的CT图像。它有8个阶段,分别包含卷积、批处理标准化和ReLu操作,过滤器数量分别为32、32、32、64、64、64、32、32。最后一层仅包含32个卷积滤波器,其输出被认为是估计的CT。
2. 判别器是一个典型的CNN架构,包括三个阶段――卷积+批规范化+ ReLu + Max池化以及一个卷积层和三个全连接层的结合,前两个用ReLu激活函数,最后一个使用sigmoid。滤波器大小为5×5×5,卷积层的滤波器个数为32、64、128和256,全连通层的输出节点个数为512、128和1。
3. Auto-Context 模型(ACM)
由于该网络是基于patch的,所以每个训练样本的上下文信息在patch中是有限的,这影响了网络的建模能力。利用医学图像分析中常用的Auto-Context模型来扩展训练过程中的上下文。其思想是对多个分类器进行迭代训练,每个分类器不仅用特征数据进行训练,还用前一个分类器得到的概率图进行训练,从而为分类器提供额外的上下文信息。
在测试时,每个分类器将一个接一个地处理特征,将概率映射连接到输入特征。在这篇论文中,没有构建几个分类器,而是使用生成器网络,也没有连接概率图,而是连接上一个生成器网络的输出。具体来说,反复训练若干个GAN神经网络,输入 MRI patch,并估计相应的 CT patch。这些 patch 作为 MRI patch 中的第二通道连接起来,并将这些新数据作为下一个GAN训练的输入。该方案的示意图如下图所示: