1. ��ʶ�ලѧϰ
�ලѧϰ���������⣬��һЩ������ȷ�𰸵�ѵ������ͨ����С�� Cost ������ϵͳ����ô�ලѧϰ����ô�������أ�ʵ���ϣ��ලѧϰҲ��ͨ����С�� Cost ������ϵͳ�ģ����忴һ���㷨��
2. K-means ����
�ලѧϰ�㷺���ڷ��������У�K-means�����㷨����һ�����ලѧϰ�㷨��
����ԭ���ǣ�����һ�����ݣ�ʹ��K-means�㷨�����ݽ��� K �����ֵĻ��֡�
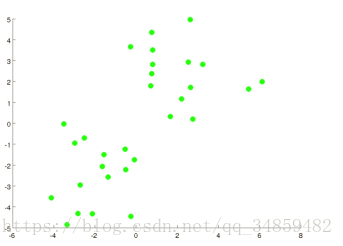
���ǿ��Ժ����ķ�����������Ӧ�÷�Ϊ���ࡣ��ô K-means �㷨������ҳ���������أ������������ѡ�����㣬��1��Ȼ��������ݵ㵽����ѡ��������ľ��벢�����ݵ�����ھ���������Ǹ��㣬��2�����������㵽��������ľ����ƽ���͵ľ�ֵ����ʵ����Cost�����ظ���1���ͣ�2����ֱ��Cost��������������ij���Ϊֹ����ͼ��
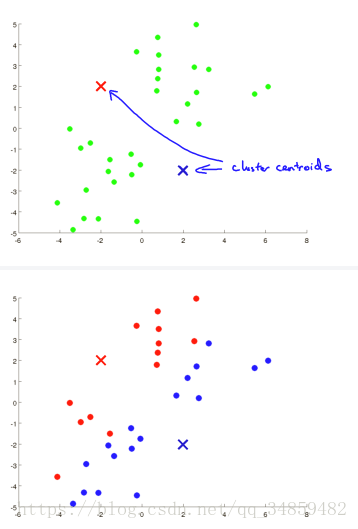
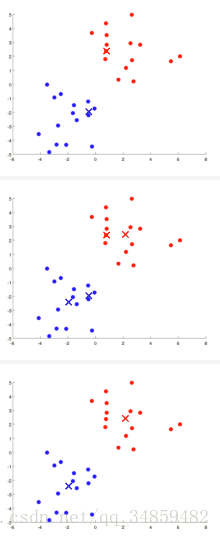
���Կ����������㷨�ͳɹ��ķ����ˡ�
���ǽ������㷨����α����ķ�ʽ������һ�飺
�����ʼ�� K �������(cluster centroid)Repeat{for i = 1 to mC(i) := index(from 1 to K) of cluster centroid closest to x(i)for k = 1 to Ku(k) := average(mean) of points assigned to cluster k
}3. K-means �Ż�
���������ʼ�� K ��������ʱ��������Ҫע���������
- K < m
- �����ѵ������ѡ K ������Ϊ�����
- ������K-Means��������ֲ����ŵ��������������ͨ����K-means����1-100�Σ������� Cost ��Ȼ��ѡ��ӵ����С Cost ���Ǹ�K���㡣
���ȷ�� K ������֪�� K Խ��ʱ��Cost ԽС����ô K ��Խ��Խ��������Բ��ǵģ�������Ҫһ���ʵ��� K ֵ����������ȷ����ʱ��ͨ�� Elbow ������ȷ�� K �Ĵ�С������ͼ��
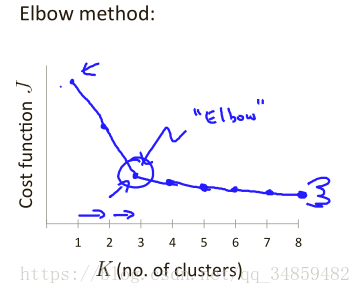
Ҳ��ͨ����ͼ�ó�������ѡ����ؽڡ���Kֵ����Ϊ֮������K������ Cost�ı仯�Ѿ�����ô���ԡ�
4.��ά
��ά���ǽ�����Ϊά���½������� ��ά��һά����ά��Ŀ��������ѹ���������ݿ��ӻ�������Ŀ�����ö������ԡ�
4.1���ɷַ���
Ϊʲô�����ɷַ����أ���Ϊ��ά�������кܶ�����������ģ�������һ����άͼ��ͼ�����п������ݵ㶼��ͬһ��ƽ����߸������������ʱ�����ǾͿ���ʹ�����ɷַ��������ݽ��н�ά�ˡ��������ʹ�����ɷַ����IJ��裺
1.����Ԥ������
ͨ����������ʹ������ʱ��������ݵ�ȡֵ���ܴ����Ƕ�������ݽ������滯������
2.�������
3.��������������
#Python ���Ѿ�����svd�İ�
from numpy import linalglinalg.svd(Sigma)4.�����������
�����U �� N*N ���������N��ԭ������ά�ȣ����ǻ�ȡ�������Ĺ�ʽ�ǣ�
Z�������ǻ�õ��������������� K ά�ġ�
5.�ع����ݣ�
��ʱ��������Ҫ�õ�֮ǰnά�����ݣ�������Ҫ����Z���¹����nά�����ݡ����µĹ�������������Ǹ�֮ǰ��һ���ģ�������һ������ġ�
6.���ѡ�� k �����ɷֵĸ�����?
����������ʽ�����ǿ���֪�����������DZ������ˣ������ʽС�ڵ�0.1�����Ǿ���Ϊ�� 90% ����������������������ѡ�� k ���鷳����Ҫ����� xapproxxapprox ������ĵȼ۵Ĺ�ʽ���Ը�����ļ�������������ȡ�
���� 99%������������������ѡ��k��ʱ��������������������ʽ�����¾����ܴ�� k ֵ�����ᄀ���ܴ���ָ�����Ⱦ����ܴ�
7.Ӧ��PCA������
- �ලѧϰ���٣�����ά�Ƚ��ˣ���Ȼ�ܹ�����
- ����ѹ��
- ���ݿ��ӻ�
������ʹ��PCA֮ǰ������Ҫ���ǣ���δʹ��PCAǰ�����ǵ�ϵͳ��ԭ�����ϱ��ֵ���Σ�ֻ�ܵ����ָ�����Ԥ�ڵIJ�һ��ʱ������ȥ����ʹ��PCA��