在使用neo4j创建知识图谱时,有时会有这样的场景:从大量数据中读取,生成大量同类型节点。
使用py2neo似乎没有那么容易。
于是便采用这样一种思路。
将获得的数据经过预处理,生成CSV文件,然后使用neo4j自带的Cypher中的LOAD CSV语句进行批量创建。
这里首先我们创建一个CSV文件,(comma-separated values)逗号分割值文件。
该文件利用换行符分割两行数据。以逗号分隔两个列。
csv的首行是列名。
我们这里来演示一下:
Id,Name,Location,Email,BusinessType1,Neo4j,San Mateo,contact@neo4j.com,P2,AAA,,info@aaa.com,3,BBB,Chicago,,G
然后将其放到neo4j安装目录下的import文件夹中,这是官方手册的要求:

这里我们遵从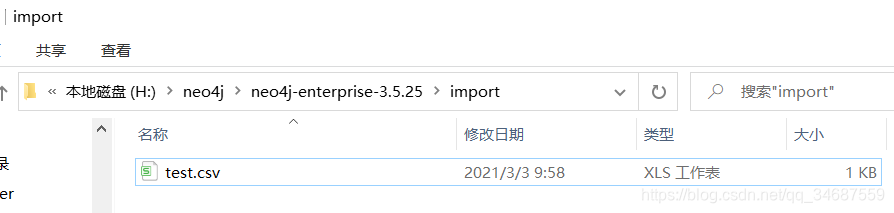
然后打开了neo4j的7474端口的网页控制端,执行如下语句:
LOAD CSV WITH HEADERS FROM 'file:///test.csv' AS row
WITH row WHERE row.Id IS NOT NULL
MERGE (c:Company{
companyid:row.Id,location:coalesce(row.Location,"Unknown"),email:coalesce(row.Email,"Unknow")});
第一行的意思是载入我们的csv文件,它的默认文件路径就上刚刚提到的import文件夹
然后第二行是一个where条件语句(这里类似于sql),将Id为空的过滤掉
然后最后一行是merge语句:
- 关于merge语句:MERGE命令在图中搜索给定模式,
- 如果存在,则返回结果
- 如果它不存在于图中,则它创建新的节点/关系并返回结果
这里一定要注意,row作为一个变量,然后它的属性,一定大小写弄清楚,写错了就加不进去。
然后这里的coalesce(a,b)意思类似于hashmap的getOrdefault(a,b)一样,如果a为null,则返回b,相当于给属性一个默认值,这里建议都这么写。
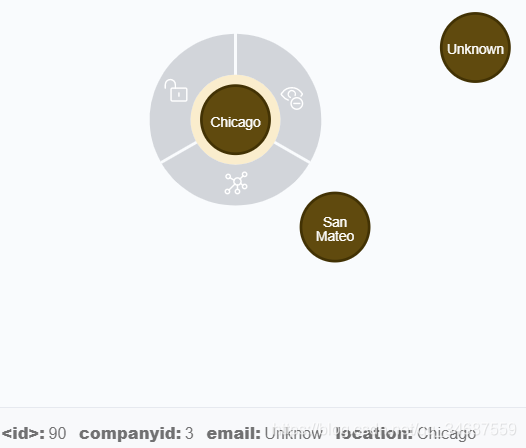
执行之后,便可以批量生成节点。
LOAD CSV的方式比较适合10M条以下的数据,如果更多。则需要采用其他方式。
生成效果: