cs224n作业 神经网络前向传播后向传播
原来只是自己没有往后看,后面视频解释了前向和后向传播。
前向传播网络
一个简单的网络:
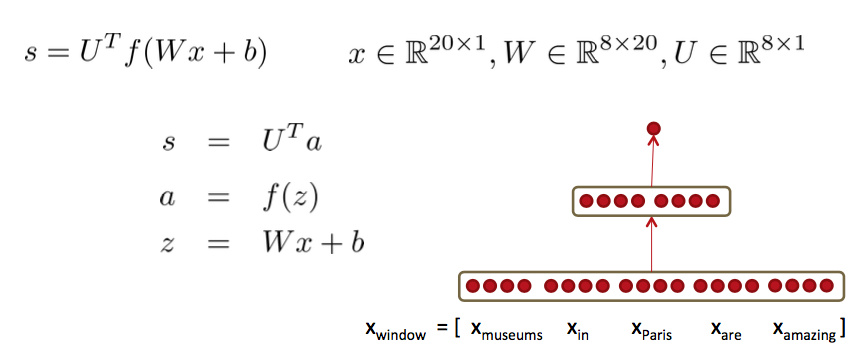
我看不懂这个红点图,同层神经元组与组之间的空格意味着什么?希望有大神赐教一下
后向传播网络
对于后向传播网络,从视频里的多种方式,我觉得最好理解的还是FLOW CHART,就是后向传播的时候,像流水一样一层一层的往后走。
核心:后向的时候记录下每一层的梯度,然后不断往后流动
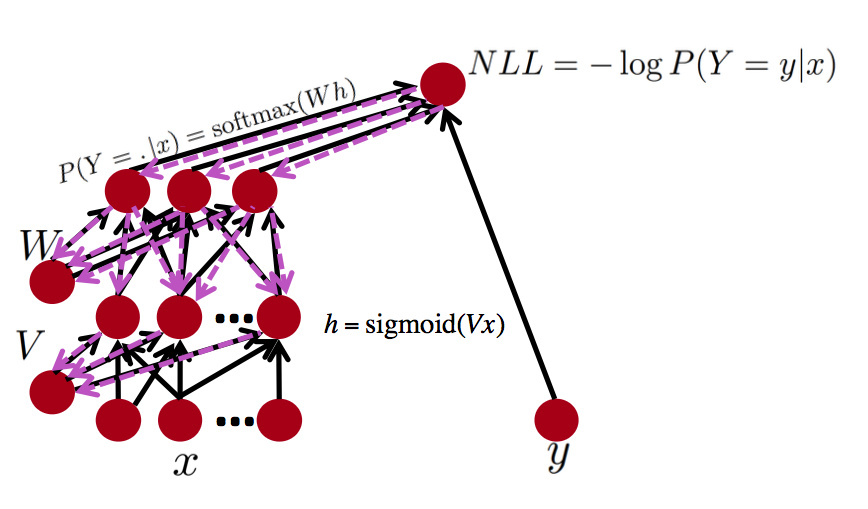
当前梯度=Localgradint?highergradient当前梯度=Local gradint*higher gradient当前梯度=Localgradint?highergradient
??看完(前两讲)视频做这个作业的时候,可卡住我好一会,这里特此记录一下。其实神经网络前向后向推导不难,难就在于网上很多教程没有把特征和维数讲清楚,以致于在具体写代码实现的过程中卡壳,同样也反映了自己目前思考问题还是平面,没有达到空间思考的程度。
?? 其实首先不是去思考前向传播时什么,后向传播是什么,首先应该思考这每一层的维数,即shape是什么 。
基本定义:
激活函数:第一层为sigmod,第二层为softmax
n:样本数量
DxD_xDx?:第一层的特征数
H:第二层的特征数
DyD_yDy?:第三层的特征数
xj(i)x^{(i)}_jxj(i)? :第j个样本的第i个特征
很明显,下图就存在这样的维度转化:
(n,Dx)×(Dx,H)?(n,H)×(H,Dy)?(n,Dy)(n, D_x)\times(D_x,H)-(n,H)\times(H,D_y)-(n,D_y)(n,Dx?)×(Dx?,H)?(n,H)×(H,Dy?)?(n,Dy?)
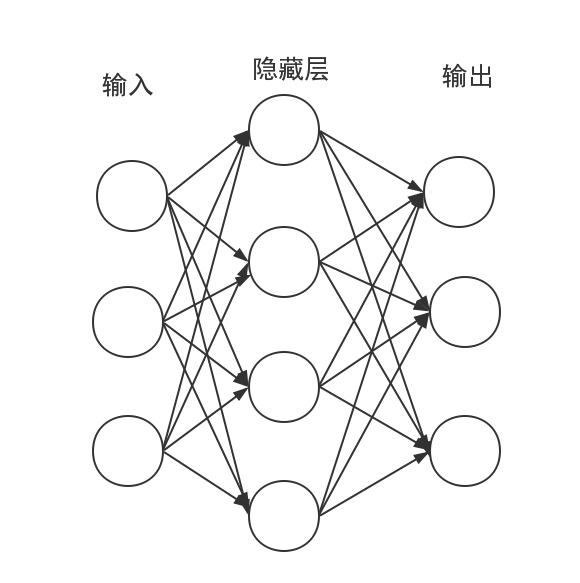
知道了具体的维度,然后我们来推前向和后向传播的公式
前向传播很容易理解,就是按照公式得到下一层结果,不需要求导什么的复杂公式。这里我们定义第一层是sigmod函数,第二层是softmax函数。
前向传播:
z2=xW1+b1h=sigmoid(z2)z3=hW2+b2y^=softmax(hW2+b2)z_2=xW_1+b_1\\ h=sigmoid(z_2)\\ z_3=hW_2+b_2\\ \hat y= softmax(hW_2+b_2)z2?=xW1?+b1?h=sigmoid(z2?)z3?=hW2?+b2?y^?=softmax(hW2?+b2?)
反向传播
反向传播实际上就是一系列的链式求导法则,这里有一些常识需要补充一下
θ\thetaθ:通常是代指整个公式中涉及到的所有参数的代名词,并不是指公式中真的需要有一个参数叫θ\thetaθ,比如说这里的W,b(代码里他们是放到一个数组里面,需要的时候再按需取不同位置的参数)
交叉熵函数:为什么使用交叉熵函数是有一番讲究的,我了解到的,一个是求导后的形式好用,另一个是求导后的导数比单纯L2变化更快。具体可以参考https://blog.csdn.net/u012162613/article/details/44239919
这里反向传播没有用上正则项,后面用上了再补。
定义损失函数:
J(θ)=?1n∑i∑jyi(j)log?y^i(j)J(\theta)=-\frac{1}{n}\sum_i\sum_j y_i^{(j)}\log\hat y_i^{(j)}J(θ)=?n1?i∑?j∑?yi(j)?logy^?i(j)?
注意i是样本数,j是具体的特征维数,理解清楚这里的下标非常重要
我们先关注内层的求和公式,即交叉熵函数(因为外层的求和跟我们求导的参数其实无关,只是对各个样本求导后的平均值)
自己踩的一坑就是没有把形式写清楚就取摸索求导过程了,一开始应该先把形式过程写清楚
推导第二层:
?J?W2=?J?z??z?W2?J?b=?J?z??z?b2?J?h=?J?z??z?h\frac{\partial J}{\partial W2}=\frac{\partial J}{\partial z}*\frac{\partial z}{\partial W2}\\ \frac{\partial J}{\partial b}=\frac{\partial J}{\partial z}*\frac{\partial z}{\partial b2}\\ \frac{\partial J}{\partial h}=\frac{\partial J}{\partial z}*\frac{\partial z}{\partial h}\\ ?W2?J?=?z?J???W2?z??b?J?=?z?J???b2?z??h?J?=?z?J???h?z?
推导第一层(形式是类似的),为什么叫反向传播,就是每一层推导都保存了$ \frac{\partial J}{\partial h$,方便下一层的推导
?J?W1=?J?h??h?W1?J?b=?J?h??h?b1\frac{\partial J}{\partial W1}=\frac{\partial J}{\partial h}*\frac{\partial h}{\partial W1}\\ \frac{\partial J}{\partial b}=\frac{\partial J}{\partial h}*\frac{\partial h}{\partial b1} ?W1?J?=?h?J???W1?h??b?J?=?h?J???b1?h?
具体函数求导的过程这里不详细展开,主要说明一下,关于交叉熵函数的求导
CE(y,y^)=?∑iyilog?eθi∑jeθjCE(y,\hat y)=- \sum_i y_i\log{\frac{e^{\theta_i}}{\sum_j e^{\theta_j}}} CE(y,y^?)=?i∑?yi?log∑j?eθj?eθi??
这里的i和j都是指特征维数,这就导致对第k维进行求导的时候,会存在两种形式,一个可以忽略softmax的分子,一个不可以忽略
?CE?θk=?(?∑i≠kyilog?eθi∑jeθj?yklog?eθk∑jeθj)?θk\frac{\partial CE}{\partial \theta_k}=\frac{\partial ( - \sum_{i\neq k} y_i\log{\frac{e^{\theta_i}}{\sum_j e^{\theta_j}}} -y_k\log{\frac{e^{\theta_k}}{\sum_j e^{\theta_j}}})}{\partial \theta_k}?θk??CE?=?θk??(?∑i??=k?yi?log∑j?eθj?eθi???yk?log∑j?eθj?eθk??)?
?CE?θi=y^i?yi\frac{\partial CE}{\partial \theta_i}=\hat y_i-y_i?θi??CE?=y^?i??yi?
这里的i是指针对某一维的参数进行求导。
具体其他函数的求导过程可以百度,以下给出代码形式:
# 变量还是要写清楚维度,不然写代码的时候很容然忘记转置
#前向传播layer1=np.dot(data,W1)+b1layer1_a=sigmoid(layer1)layer2=np.dot(layer1_a,W2)+b2probs=softmax(layer2)
#后向传播cost = -np.sum(np.sum(labels*np.log(probs),axis=1)) /N#这里要注意矩阵乘法的时候就把n个样本的值加再一起了,所以不需要sum直接除NgradW2=np.dot(layer1_a.T,probs-labels)/N#这里要注意sum,因为损失函数还有外层对每个样本求导后的平均值gradb2=np.sum((probs-labels),axis=0)/N# 记录下当前层的导数,便于下一层计算dlayer2=np.dot(probs-labels,W2.T)/Ndlayer1 = (1-layer1_a)*layer1_a*dlayer2gradW1 = np.dot(data.T, dlayer1)gradb1 = np.sum(dlayer1,axis =0)