tensorflow基础入门
这是cs224n上的视频教程,后续自己也会继续往这里面补充自己对tensorflow的理解。
包括基础的概念,代码的实例,变量共享,以及一些小技巧
tensorflow的三个重要概念:
- keyidea:express a numerical computation as a graph
- graph nodes:operations which have any number of input and output
- graph edges:tensor flow between nodes
总觉得英文比起汉字的翻译要有意蕴一点。。。
tensorflow数据类型
variable:
- stateful nodes which output their current value
- 默认会自动求梯度
- 可以保存起来,供其他人使用
placeholder:
- nodes whose value is fed in at execution time
- 需要提供的是(type,shape)
mathematical operation:
- tensorflow 内置的mathmatical operation
例子如下
variable:b,w
placeholder:x
mathematical operation:MatMul,ReLU,Add
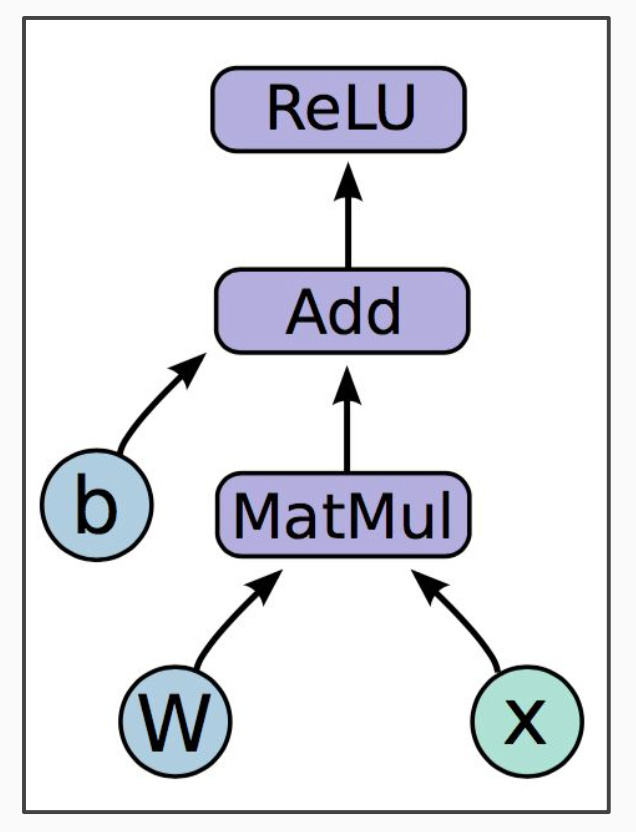
代码实例说明
定义图中各个的节点:

session 绑定
session就是到某个软硬件执行环境的绑定。
其中sess.run(fetches,feeds)
fetches:graph node
feeds:dictionary mapping from graph node to concrete values
返回值: return 是fetches的执行结果,如果fetches是一个元素就返回一个值,如果是一个字典就返回同key的结果字典,如果是list就返回list
为什么只给一个节点就可以返回结果:因为图是连通的,给我一个节点总可以找到所有节点。
tf.initialize_all_variables()目前已经改为tf.global_variables_initialize()可以理解为这是内置的函数,依旧符合sess.run的语法要求

训练模型
定义损失函数:
prediction = tf.nn.softmax(...) #Output of neural network
label = tf.placeholder(tf.float32, [100, 10])
cross_entropy = -tf.reduce_sum(label * tf.log(prediction), axis=1)
计算梯度
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
这里梯度会做两个事情:
- 会自动计算所有variable的梯度
- 会进行梯度更新
batch 更新:

实例共享
有时候我们想要生成一张图的多个实例,或者在多机多个GPU上训练同一个模型,就会带来同一个变量在不同位置出现。如何在不同位置共享同一个变量呢?
我其实困惑就在于,这缺乏一个实际的情景来说明,为什么需要实例共享,共享后有什么好处?
下方例子来自:https://www.cnblogs.com/max-hu/p/7113554.html
比如,我们创建了一个简单的图像滤波器模型。如果只使用tf.Variable,那么我们的模型可能如下
def my_image_filter(input_images):conv1_weights = tf.Variable(tf.random_normal([5, 5, 32, 32]),name="conv1_weights")conv1_biases = tf.Variable(tf.zeros([32]), name="conv1_biases")conv1 = tf.nn.conv2d(input_images, conv1_weights,strides=[1, 1, 1, 1], padding='SAME')relu1 = tf.nn.relu(conv1 + conv1_biases)conv2_weights = tf.Variable(tf.random_normal([5, 5, 32, 32]),name="conv2_weights")conv2_biases = tf.Variable(tf.zeros([32]), name="conv2_biases")conv2 = tf.nn.conv2d(relu1, conv2_weights,strides=[1, 1, 1, 1], padding='SAME')return tf.nn.relu(conv2 + conv2_biases)
这个模型中有4个不同的变量:conv1_weights, conv1_biases, conv2_weights, and conv2_biases
当我们想再次使用这个模型的时候出现问题了:在两个不同的图片image1和image2上应用以上模型,当然,我们想这两张图片被相同参数的同一个滤波器处理。如果我们两次调用my_image_filter()的话,则会创建两个不同的变量集,每个变量集中各4个变量。
# First call creates one set of 4 variables.
result1 = my_image_filter(image1)
# Another set of 4 variables is created in the second call.
result2 = my_image_filter(image2)
共享变量的一种常见方法是在单独的代码段中创建它们,并将它们传递给使用它们的函数。 例如通过使用字典:
variables_dict = {
"conv1_weights": tf.Variable(tf.random_normal([5, 5, 32, 32]),name="conv1_weights")"conv1_biases": tf.Variable(tf.zeros([32]), name="conv1_biases")... etc. ...
}def my_image_filter(input_images, variables_dict):conv1 = tf.nn.conv2d(input_images, variables_dict["conv1_weights"],strides=[1, 1, 1, 1], padding='SAME')relu1 = tf.nn.relu(conv1 + variables_dict["conv1_biases"])conv2 = tf.nn.conv2d(relu1, variables_dict["conv2_weights"],strides=[1, 1, 1, 1], padding='SAME')return tf.nn.relu(conv2 + variables_dict["conv2_biases"])# Both calls to my_image_filter() now use the same variables
result1 = my_image_filter(image1, variables_dict)
result2 = my_image_filter(image2, variables_dict)
但是像上面这样在代码外面创建变量很方便, 破坏了封装
构建图形的代码必须记录要创建的变量的名称,类型和形状。
代码更改时,调用者可能必须创建更多或更少或不同的变量。
解决问题的一种方法是使用类创建一个模型,其中类负责管理所需的变量。 一个较简便的解决方案是,使用TensorFlow提供variable scope机制,通过这个机制,可以让我们在构建模型时轻松共享命名变量。
如何实现共享变量
tensorflow中的变量共享是通过 tf.variab_scope() 和 tf.get_variable() 来实现的
tf.variable_scope(<scope_name>): 管理传递给tf.get_variable()的names的命名空间
tf.get_variable(, , ): 创建或返回一个给定名字的变量
为了看下tf.get_variable()如何解决以上问题,我们在一个单独的函数里重构创建一个卷积的代码,并命名为conv_relu:
def conv_relu(input, kernel_shape, bias_shape):# Create variable named "weights".weights = tf.get_variable("weights", kernel_shape,initializer=tf.random_normal_initializer())# Create variable named "biases".biases = tf.get_variable("biases", bias_shape,initializer=tf.constant_initializer(0.0))conv = tf.nn.conv2d(input, weights,strides=[1, 1, 1, 1], padding='SAME')return tf.nn.relu(conv + biases)
此这个函数使用“weights”和“biases”命名变量。 我们希望将它用于conv1和conv2,但变量需要具有不同的名称。 这就是tf.variable_scope()发挥作用的地方:它为各变量分配命名空间。
def my_image_filter(input_images):with tf.variable_scope("conv1"):# Variables created here will be named "conv1/weights", "conv1/biases".relu1 = conv_relu(input_images, [5, 5, 32, 32], [32])with tf.variable_scope("conv2"):# Variables created here will be named "conv2/weights", "conv2/biases".return conv_relu(relu1, [5, 5, 32, 32], [32])
然后要注意如果需要共享变量,需要这样子写,否则共享会报冲突错误
with tf.variable_scope("foo",reuse=True):
注意点
- 所有的操作都要用tensorflow内置的函数
- 关于tensorflow更详细的教程,我发现课件要比视频详细很多
http://vedio.leiphone.com/5b32eff053cd7.pdf
小技巧
后续补充