����Ŀ¼
-
- ժҪ
- ����
- ���巽������
-
- �������壺
- sentence encoder
- Selective Attention over Instances
- �ܽ�
ժҪ
�ִ����⣺Զ�̼ල�����һЩ�����ע������
���������ʹ�þ���������ӳ��������壬ʹ��attention���Ƽ������� ���ݵ�Ȩ�ء�
ʵ��֤�������壺ģ�Ϳ������þ��ӵ�������Ϣ�����Ҽ��ٴ���������Ӱ�졣
����
��״��
���KB������ʵ�����ʵ�����ʵ����Զ��Զ������Զ��Ĺ�ϵ��ȡ����Ҫ(��Ϊ���Բ���������ʵ��ȥ��)��
�������˹�����
Ŀǰ�������ϵ��ȡ���ǻ��ڴ������˹���ע�мලѧϰ��
��������¼��裨Ҳ��Զ�̼ල�Ķ��壩��
�������ʵ����KB��ij��ϵ����ô���еİ�����ʵ��Եľ��Ӷ�������ù�ϵ
��Ȼ�������׳��ַ�������ͳ������ȱ������������һ��end-to-end��ϵͳ������������tag,pos��һϵ�еIJ��������ͻ��ɴ˴�����
�������ѧϰ�ĸ��������ӽ���һƪ������˼���ǣ�
���ٴ���һ��������Щʵ��ľ��ӻ���ֳ����ǵĹ�ϵ��Ȼ��Ϊÿ��ʵ���ֻѡ�����п��ܵľ���������ѵ����Ԥ��
��Ȼֻѡ�����п��ܵľ��ӣ��ᶪʧ�������ӵ�����
�Լ��Ĺ�����
-
������ھ���ľ��������磨CNN��������Զ�̼�ع�ϵ����ȡ��
-
�ڶ��ʵ���Ͻ����˾��Ӽ���Ĺ�ע����̬������Щ����ʵ����Ȩ�أ���
-
���þ��Ӳ�ε�ע�������ƣ���ȡ���ϵ�����Ĺ�ϵ��
���巽������
�������壺
word:x={w1,w2..wm}x=\{w_1,w_2..w_m\}x={
w1?,w2?..wm?}(һ�����Ӻ���m����)
sentence:{x1,x2,x3...}\{x_1,x_2,x_3...\}{
x1?,x2?,x3?...}
relation:r
vocabulary size��V
��Ƕ���ά�ȣ�a
λ�þ����ά��:b
������ά�ȣ�d
��������ά�ȣ�dcd^cdc
�������ڳ��ȣ�l
�����ˣ�WjW_jWj?
����ȫ����S
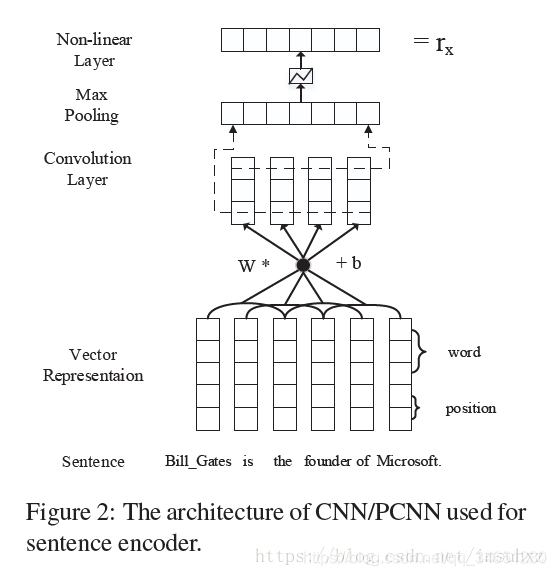
sentence encoder
word representation
- word embeddings: ��ͨ�Ĵ�Ƕ��ģ��
- position embeddings������CNN keep traceÿ������ǰ��ʵ���λ�ã�2��ʵ����ǰ�ͺ�
�������word vector(���ﻹ�Ǵʲ��Ǿ���):
wi��Rd(d=da+db��2)w_i\in R^d(d=d^a+d^b\times2)wi?��Rd(d=da+db��2)
����a�Ǵ�Ƕ���ά�ȣ�b��λ�þ����ά��
Convolution,Max-pooling and Non-linear layers
���������max-pooling�����ã�����������ʵ�أ��������ΪʲôNLP��������йأ�����һ��ͨ�õ����ã���
ά�Ƚ��ͺ���Ҫ
�����ˣ�W��Rdc��(l��d)W\in R^{d^c\times (l \times d)}W��Rdc��(l��d)
�������ڣ�qi=Rl��dq_i=R^{l\times d}qi?=Rl��d
qi=wi?l+1:iq_i=w_{i-l+1:i}qi?=wi?l+1:i?
����l�����ڣ�����һ���õ��ĸ����ʵ�����ƴ��(ˮƽ)
��˵�i���˲�����Ӧ��feature map�ǣ�
pi=[Wq+b]ip_i=[Wq+b]_ipi?=[Wq+b]i?
ע������qû���±꣬ʵ����Ӧ����(dc��l��d)X(l��d��m)(d_c \times l\times d)X(l \times d \times m)(dc?��l��d)X(l��d��m),���m���Ǵ��ڵ������������ӵĴ������ȳ����ȡ�
��˾���Ҫ���гػ���
[x]i=max(pi)[x]_i=max(p_i)[x]i?=max(pi?)
����һ�������Ժ���tanh,relu֮������������
����Ĺ��̾����£�
Selective Attention over Instances
���룺
- �����ض�ʵ��ľ��Ӽ���S
- �þ��Ӽ��Ͼ�����һ���ֵõ�������ʾ��S={x1,x2,x3}\{x_1,x_2,x_3\}{ x1?,x2?,x3?}
СĿ�꣺ϣ���õ��÷ָ��ʱ�ʾP(r�OS,��)P(r|S,\theta)P(r�OS,��)(����Sʵ����£�r�ĵ÷�)
��˾���Ҫ�Լ���S��������Ϊa real-valued vector s ��
- ����ƽ��Ȩ��
- ����ע��������
���̣�
ei=xiAre_i=x_iArei?=xi?Ar
��i=exp(ei)��kexp(ek)\alpha_i=\frac{exp(e_i)}{\sum_k exp(e_k)}��i?=��k?exp(ek?)exp(ei?)?
s=��i��ixis=\sum_i \alpha_ix_is=i��?��i?xi?
o=Ms+do=Ms+do=Ms+d
P(r�OS,��)=exp(or)��k=1nrexp(ok)P(r|S,\theta)=\frac{exp(o_r)}{\sum_{k=1}^{n_r}exp(o_k)}P(r�OS,��)=��k=1nr??exp(ok?)exp(or?)?
���У�A��һ��Ȩ�ضԽǾ���r�Ǵ����Ÿù�ϵ��������eʵ���Ͼ���ע�������ֺ��������ʵ���ϵ�������еľ��ӿ���ȡ�ø����ȡֵ��
�ܽ�
��ƪ���µĹ������ڴ�ͳ�۵㣬��Ϊ����ʵ�����ij�ֹ�ϵ����ô���а�����ʵ��Եľ��Ӷ���ʾ���ֹ�ϵ�����Ǵ�����������������ע�������ƶ�����ʵ��Եĸ������ӽ���Ȩ�ص�ѧϰ��ʹ������õı��ָù�ϵ��