Visualizing and Understanding Convolutional Networks
文章是由Yann LeCun的学生Mathew所写。
刚接触,文章仅供参考,错误的地方欢迎大家指出。
1. 论文综述
1.论文讲解什么问题
- 为什么很多CNN模型可以在图像分类上发挥这么好的效果。
- 怎样能够使模型更优。
2.论文主要工作
- 论文提出了一个新颖的可视化技术使得我们能够了解中间特征层的功能和分类器的作用。使用这个方法可以使我们在ImageNet分类基准上找到更好的模型结构。
- 作者还进行了消融研究(ablation study)来发现不同模型层的性能贡献。
3.用的什么方法
文章是使用Krizhevsky等人提出的模型作为基础模型(共8层),对其进行改进:将第一层卷积核大小由1111调整为77,2.将卷积跨度由4调整为2。
2. 论文主要概述
2.1 引言
文章先介绍了几个最近提出的优化模型:
- Ciresan等人提出的模型在数据集NORB和CIFAR-10上达到最优水平。
- Krizhevsky等人提出的卷积模型错误率到达16.4%,第二名是26.1%。
- Girshick等人提出的模型在PASCAL VOC数据集上展现出最好水平。
作者总结现在使模型性能显著提高的几个因素:
- 大数据集的出现和成千上万的标签样本。
- 强大的GPU
- 出现了很好的模型优化策略,比如正则化。
作者阐述自己提出的技术优势:
- 提出的可视化模型可以告诉我们模型中任意一层中激发单个特征映射的输入刺激。
- 可视化技术也能让我们在训练过程中观察特征的演变,从而诊断出模型潜在的问题。
- 可视化技术利用Zelier等人提出的多层反卷积网络将特征激活投影到输入像素空间。
- 通过遮挡输入图像的部分来对分类器的输出进行敏感性分析,解释图像中那些部分对于分类来说是重要的。
作者将这种方式归类为监督前训练方式,与Hinton等人推广的非监督前训练方式形成对比。
2.2 实现方法
2.2.1 反卷积实现可视化
使用Zeiler等人提出的反卷积神经网络完成特征到输入像素的映射。
具体做法:
为了检查一个卷积神经网络需要在它的每一层都附加了一个反卷积神经网络,提供返回图像像素的连续路经。
具体方法:
- 首先将输入图像输入给卷积神经网络,并计算各层的特征。
- 为了检查给定卷积网络的激活值,我们将该层中其他的激活值设置为0,并将产生的特征映射作为输入传递到附加的反卷积网络层中。
- 依次进行unpool、rectify、filter来重建这层下面引起选择激活(应该指的是stimuli)的活动。
- 重复上述活动直到达到输入象素那层。
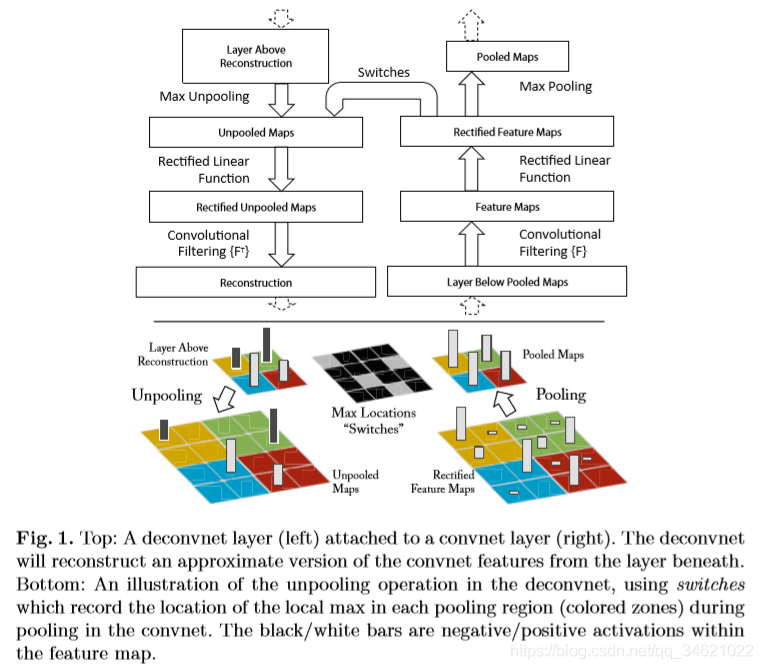
- Unpooling:在convnet中,最大池化操作是不可逆的,但是我们可以通过记录最大池化过程中每个最大值的位置(记录在switch表格中,如Fig1下部所示)来获得一个近似的逆。
- Rectification:卷积神经网络采使用非线性激活函数relu来保证所有的输出都是正数,这样是为了在每层获得有效的重建特征。
- Filter:卷积网络中过滤器与上一层的输出做卷积操作,在反卷积网络中使用相同的过滤器的转置作为核,与矫正后的特征进行卷积操作。
文章使用的数据集ImageNet2012作为训练集,数据的处理与模型的初始参数设置不再赘述。‘
注意:文章中提到为了避免出现训练得到的第一层卷积核其中有一部分核数值过大,采取如下策略:均方根超过0.1的核重新进行归一化,时期均方根为0.1。(核数值过大造成什么影响?为什么均方根选择为0.1?)
2.3 卷积可视化
下图展示了训练结束后,每个隐藏层提取出的特征。在给定输出特征的情况下,反卷积产生的最强的9个输入特征。将计算所得的特征用像素空间表示后,可以看出:一组特定的输入特征(经过上述过程重构的2.2.1所述),能够刺激卷积网产生一个固定的输出特征,这也恨到的解释了为什么输入存在一定畸变时,网络的输出结果保持不变。
(文章提到重构特征只包含那些具有判别能力纹理结构,举例图中层 5第一行第2列第9张输入图片各不相同,差异很大,但对应的重构输入特征都显示了背景中的草地,没有一些凌乱的前景。没有理解)

特征在训练过程中的演化:当输入的图片中的最强刺激源发生变化时,对应的输出特征轮廓发生跳变。经过一定次数的迭代后,底部特征趋于稳定,但高层的特征则需要更多的迭代才能收敛(约40~50周期)。这表明:只有模型中所有层都收敛时,分类模型才能使用。
特征不变性:图片被平移、旋转和缩放对第一层来说影响较大,很细小的变化都会导致输出特征明显变化,但是层数越高,这些变化对输出结果的影响越小。总体来说,卷积网无法对旋转操作产生不变性,除非物体具有很强的对称性。
2.3.1 选取结构
反卷积网络可视化技术可以帮助我们发现网络模型的一些问题,如图4a,d所示,第一层卷积核混杂了大量的高频和低频信息,缺少中频信息;第2层卷积选择4作为步长,产生了混乱无用的特征。为解决这些问题,文章所提出的模型:1.将第一层卷积核大小由1111调整为77,2.将卷积跨度由4调整为2;如图4c,e所示,新的模型不但保留了1、2层绝大部分的有用特征,还提高了最终分类性能。
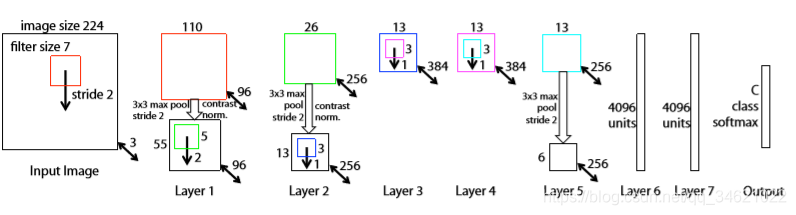
图3 文章使用8层卷积网络模型,输入为由原始图像裁剪而来的224224的3通道RGB图像。层1所示有96个卷积核,每个核的大小为77,x,y方向步长为2。获得的卷积图进行下面的操作:1.通过矫正函数relu(x)=max(x,0),使得所有卷积值均不小于0;2.进行max pooling操作(33区域,跨度为2);3.对比度归一化操作,最终产生96个不同的特征模板,大小为5555.层2、3、4、5都是类似操作,层5输出256个66的特征图,最后两层网络为全连接,最终输出层是一个C类的softmax函数,C为类别个数,所有卷积核与特征图均为正方形。
图4 (a)表示Layer1输出的特征,还未经过尺度约束操作,每张图片中有一个特征占主导地位;(b):Krizhevsky提出模型第一层产生的特征;?:本文模型第一层产生的特征,这个模型具有更小的跨度(stride= 2,krizhevsky提出的是4),更小的内核(filter = 77,krizhevsky提出的是11*11),从而产生了更具辨识度的特征和更少的无用特征;(d):krizhevsky第2层产生的特征;(e):本文模型第2层产生的特征,比(d)中的清晰

图5 模型特征逐层演化的过程,每层的列代表特定迭代次数下的结果。每块展示的是在随机选定一个具体输出特征时,计算重构输入特征在第1、2、5、10、20、30、40、64次迭代时的输出。途中所有显示效果都进行了人工色彩增强。
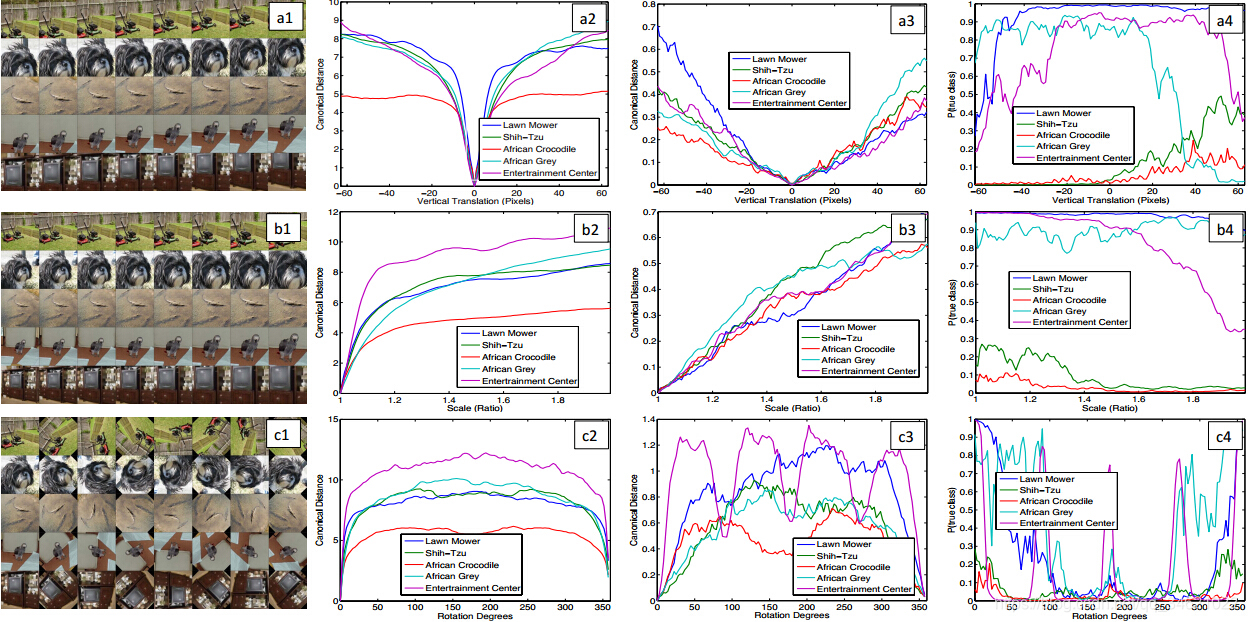
图6 图像进行a(垂直移动)、b(旋转)、c(尺寸变化)以及卷积网络模型中相应特征的不变性。第一列:对图像的各种变形,列2、3:原始图片和变形图片分别在层1和层7所产生特征间的欧式距离。列4:真实类别在输出中的概率。
2.3.2 遮挡敏感性
这一部分主要讲解:如何了解分类器使用了什么信息实现分类,是图像中具体位置的像素还是图像中的上下文。图7中使用了一个灰色的矩形对输入图像的每个部分进行遮挡,测试在不同遮挡情况下,分类器的输出结果。可以看到,当关键区域被遮挡后分类器性能急剧下降。图7也展示了最上层卷积网的最强响应特征,展示了遮挡位置和响应强度之间的关系:当遮挡发生在关机物体出现的位置时响应急剧下降,图也反应了输入什么刺激会使得系统产生某个特定的输出特征,这种方法可以查找出图2、4中的特定特征的最佳刺激。
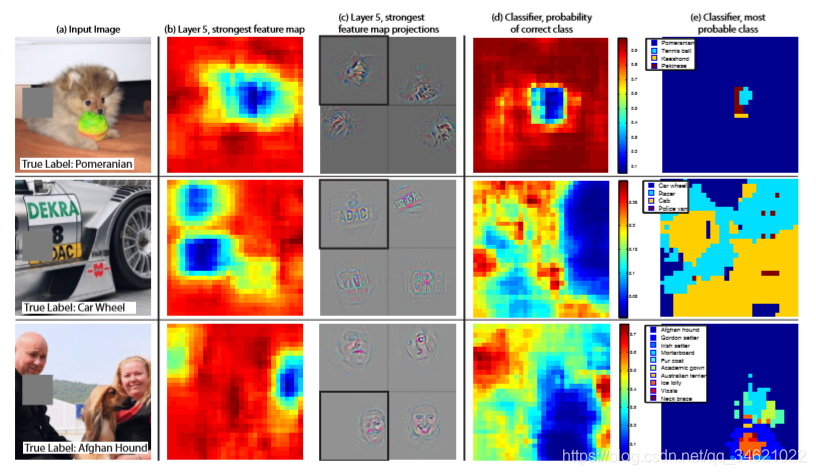
图7 (a):灰色矩形对图片不同部分进行遮挡;(b):图像遮挡对第五层特定输出强度的影响;?:将第五层特定输出特征投影到像素空间的情形;(d):正确的分类对应的概况,关于遮挡位置的函数,当小狗的面部被遮住时,分类效果最差;(e):最有可能的分类结果图
其中文章还对狗的五官进行选择性的进行遮挡,来测试狗不同部位的相关性。
结果如下:
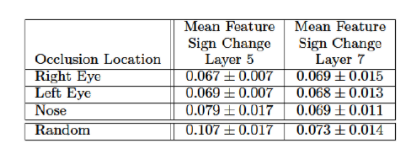
表1 遮挡狗的不同部位测试不同部位的相关性;在第五层中,遮挡眼睛和鼻子得分更低,表明网络开始产生相关性,第7层得分差异不大,说明高层网络开始关注分类特征而不是局部特征。
2.4 实验内容
实验使用的数据集为ImageNet2012,其中训练集/验证集/测试集,大小分别为130/5/10万张。
文章重构krizhevsky等人2012年提出的模型,重构模型错误率与文章提出模型错误率误差在0.1%。
本文将第一层卷积核大小调整为7*7,第一、二层步长改为2,与原文章模型相比错误率提高了0.5个百分点。
文章还测试了模型的泛化能力,不改变1~7层的参数,仅对softmax层进行重新训练。
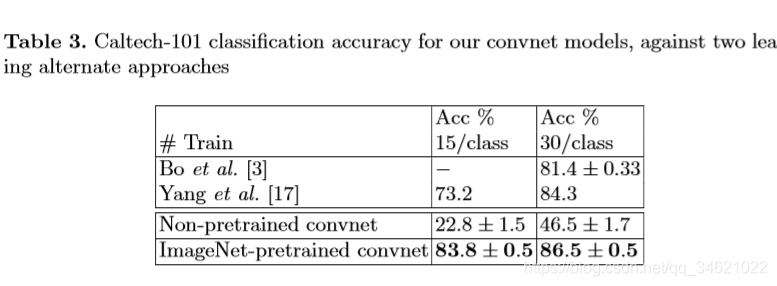
表3
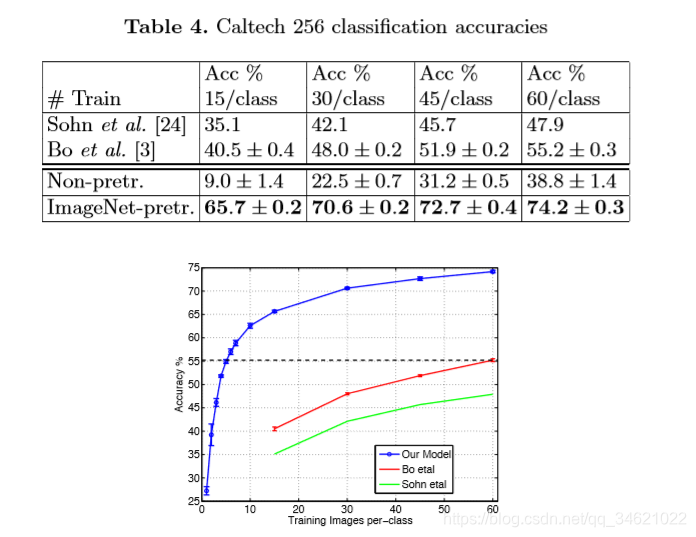
表4 第一part:分别选择了15、30、45、60个训练图像,表中显示了每个类的平均准确率,表中显示ImageNet-pre模型以显著的优势击败了Bo等人获得的最先进的结果。第二part:Caltech-256分类性能随着每个类的训练图像数量的变化而变化。使用我们预训练的特征提取器,每个类只使用6个训练示例,我们超过了Bo等人的最佳报告结果。
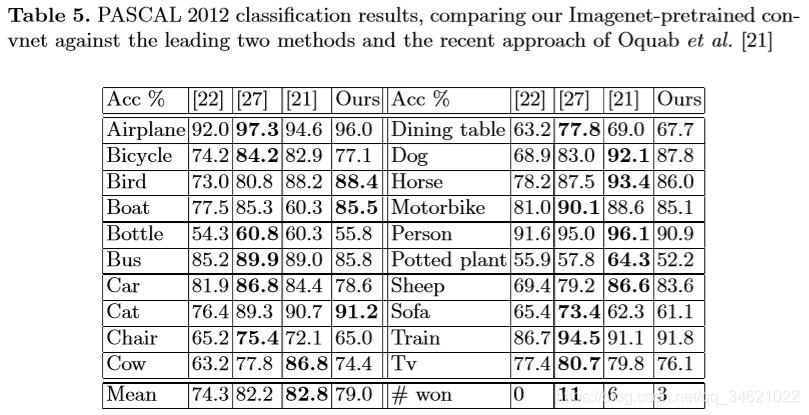
表5 PASCAL 2012库:本文使用标准的训练方法来训练softmax分类器。因为PASCAL库中测试图片有可能一张包含多个物体,但是文中模型对一张图片只有一个预测,因此没有超过历史最好记录,大约落后了3.2%,但是文章模型仍然在5个类别上超越了他们。
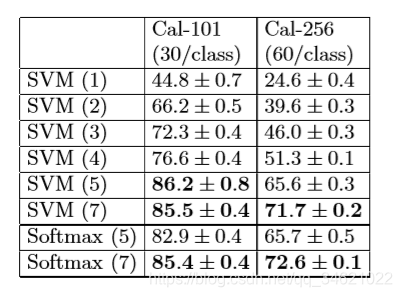
表 6 保留训练后模型的前n层,后端连接线性SVM或softmax分类器,表7显示基于Caltech101和Caltech256两个库的分类结果。可以看出模型学习到的特征同样适用于SVM分类器,另外随着保留层的增多,分类能力稳步上升,当保留全部层时,分类效果达到最好。证明深度越深,网络可以学到更好的特征。
疑问
- 对图像进行旋转、缩放部分计算特征间的欧式距离的图没有看懂,计算欧式距离什么意义?
