YOLO 系列:YOLO V2
- 论文标题:YOLO9000: Better, Faster,Stronger (CVPR 2017)
- 作者使用Pascal Voc与ImageNet数据集进行一个联合训练,最终可检测类别超过9000.
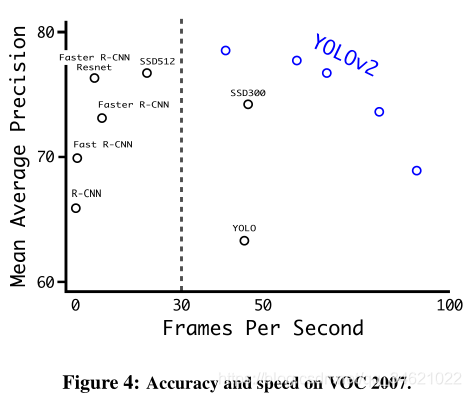
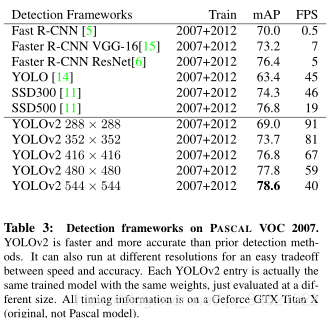
- 模型性能:
- YOLO V2中的各种尝试:
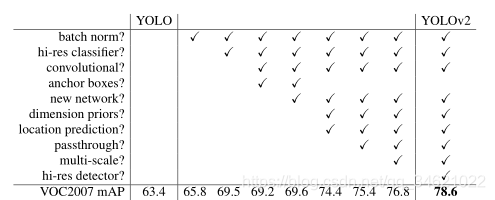
- Batch Normalization:帮助训练收敛,帮助模型正则化,可不再使用Dropout层,提升约2%mAP。
- High Resolution Classifier:输入尺寸变为448×\times× 448,更高的分辨率提升4%mAP。
- Convolution With Anchor Boxes:YOLO V1定位方式效果较差且不准确,使用基于anchor偏移的方式比直接去预测坐标可简化预测过程,使网络更好的去学习。论文中提到,不使用anchor方法模型mAP为69.5%,召回率为81%;使用anchor的方法模型mAP为69.2%,召回率为88%。mAP虽然有下降,但召回率有很大的提升,意味着模型有更大的提升空间。
- Dimension Cluster:使用K-mean聚类算法获取anchor,基于训练集中所有边界框,获得最合适的priors。
- Direct location prediction:根据Faster RCNN中计算坐标的公式使用x=(tx×wa)+xax = (t_x \times w_a) + x_ax=(tx?×wa?)+xa? 与 y=(ty×ha)+yay = (t_y \times h_a) + y_ay=(ty?×ha?)+ya?可以得到预测框的中心坐标,其中w,h为高和宽,t为训练得到的回归参数,由于t没有任何限制,如下图所示:黄色框本来对应预测第一个grid cell的object,但得出的t没有限制,可能会使其跑到其它grid cell上预测,这会在很大程度上降低模型的运算效果与速度。

为此,作者提出以下公式对回归参数进行限制(在此篇文章中x,y不再指中心点坐标,而指左上角坐标)。
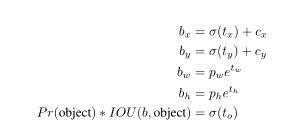
上图中tot_{o}to?就是指真实目标与预测目标的IOU值。
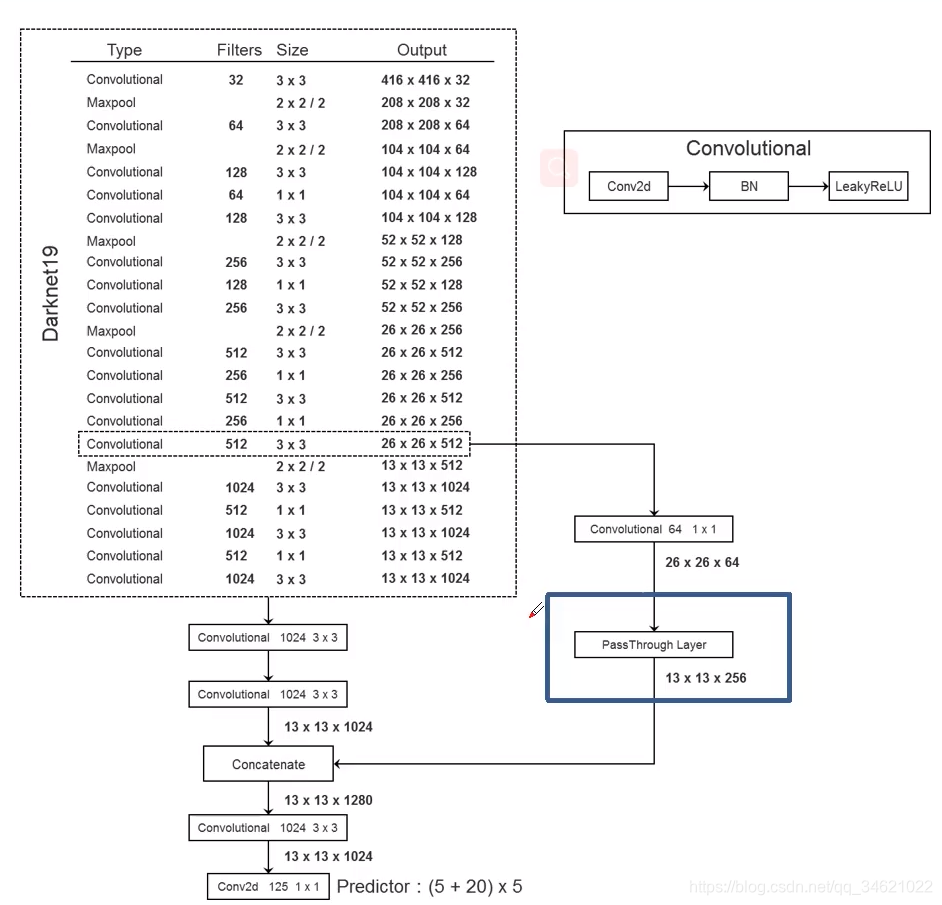
sigmoid函数限制每个anchor去负责预测目标中心落在某个grid cell区域内的目标,使网络更易学习,更加稳定,提升5%。 - Fine-Grained Features:作者将高层信息与低层信息进行融合。通过pass through layer融合,提升小目标的检测效果。
pass through layer融合:低层特征图宽度与高度都减半,通道数变为原来的4倍。再与高层特征图直接concatent,提升了1%。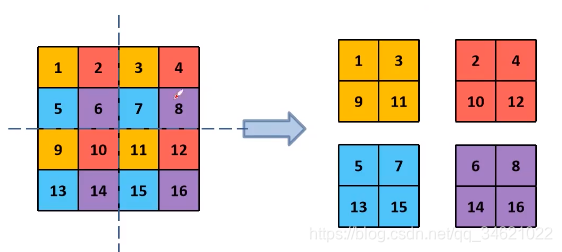
- Multi-scale Training:为了提升模型的鲁棒性,作者将输入的图片进行了缩放,每迭代10个batch,选择一个新的image dimension size。模型缩放因子32(416/13),image size属于{320,352,…,608}
-
BackBone:Darknet-19(19个卷积层)
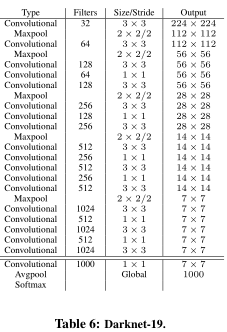
224×\times× 224作为输入,5.58 billion operations 处理图像,再ImageNet上达到72.9% top-1 accuracy,91.2% top-5 accuracy。 -
YOLO V2模型架构图