��л����С���ģ���ע + ���� + �ٿ������Բ����Ŀ϶����ᶽ�ٲ���������������������ʵս���ݣ�����

1.��ƪ-���Ľṹ

��������˵
��������������������ĸ���~
32ƪԭ������
���ں�
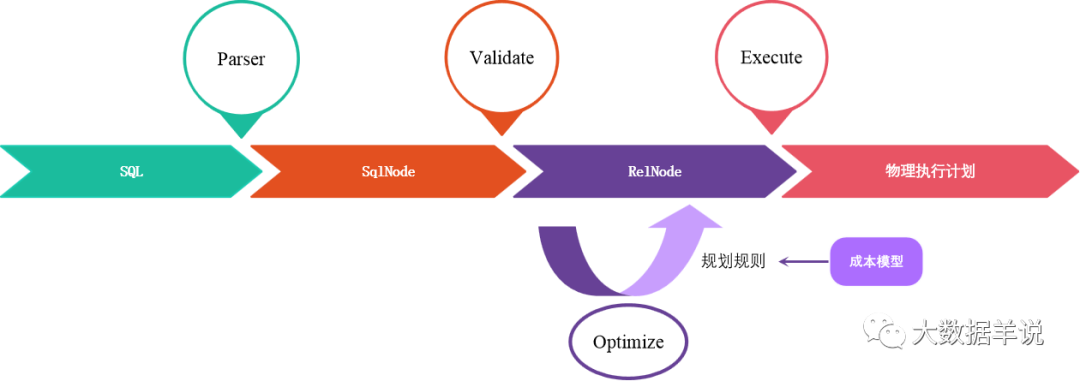
������Ҫ���� flink sql �� calcite ֮��Ĺ�ϵ��flink sql �Ľ�����Ҫ���� calcite��
������ͨ��������ש�������������� flink sql �ڽ��������������� calcite �ģ��Լ� flink sql ���������̣�sql parser ������ݡ�ϣ���Դ������������
����ͨ�����¼��ڽ��н��ܣ���ij���½ڸ���Ȥ�Ŀ���ֱ�ӻ�����Ӧ�½ڡ�
- ����ƪ-һ�� flink sql ��ִ�й���
-
�����Լ���������
-
���� flink ��ʵ��
- ���ƪ-calcite ���ݵĽ�ɫ
-
calcite ��ɶ��
-
flink sql Ϊɶѡ�� calcite��
- ����ƪ-calcite ������������
-
������ calcite
-
��ϵ����
-
calcite ��֪�Ļ��� model
-
calcite �Ĵ������̣��� flink sql Ϊ����
-
calcite ��ô������ôͨ�ã�
- ԭ������ƪ-calcite �� flink sql �д�չ����
-
FlinkSqlParserImpl
-
FlinkSqlParserImpl ������
- �ܽ���չ��ƪ
2.����ƪ-һ�� flink sql ��ִ�й���
�����ȸ���Ҵ�������һ�� flink sql ��ִ�й��������˽���ϸ���ݲ�Ҫ������Ҫ���˽��������̣�����ȫ���ӽ�֮����������ϸ�ڡ�
�ڽ���һ�� flink sql ��ִ�й���֮ǰ���������� flink datastream �����ִ�й��̣��������һ�� flink sql ��ִ�й����кܴ�İ�����
-
datastream��datastream ��ʹ��ʱҪ�� flink datastream api �ṩ�ĸ��� udf������ flatmap��keyedprocessfunction �ȣ����Զ��崦�����������ҵ��ִ���������ô��롢 java �ļ�д�ģ�Ȼ������� jvm ��ִ�У��ͺ�һ����ͨ�� main ����Ӧ��һģһ�������̡���Ϊ����ִ���������Լ�д�ģ�������һ������Ժ����⡣
-
sql��java ����������ʶ��ͱ���һ�� sql ����ִ�У���ôһ�� SQL ��զִ�е��أ�
2.1.�ȷ����Լ���������
��������˼ά���п��ǣ��������һ�� flink sql �������ǵ�Ԥ���� jvm ��ִ�У���Ҫ��Щ���̡�
-
������˵���ο� datastream����� jvm ��ִ�� datastream java code ������ class �ļ�����ô��һ�� sql �����㣬�ܽ� sql ������Ϊ datastream �ĸ������ӣ�Ȼ�����ִ�в��� vans �ˡ�
-
sql parser�����ȵ���һ�� sql parser �ɣ�������ʶ�� sql ����� sql �ת��Ϊ AST������Ĺ�ϵ������
-
��ϵ������ datastream ���ӵ�ӳ����sql ������Ϊ datastream����Ҫ��һ��������ӳ�����ɡ�sql �ǻ��ڹ�ϵ�����ģ�����ά��һ�� sql �е�ÿ����ϵ���������� datastream �ӿڵ�ӳ���ϵ��������Щӳ���ϵ���ǾͿ��Խ� sql ӳ���һ�ο�ִ�е� datastream ���롣�ٸ����ӣ�����Խ���
-
sql select xxx ����Ϊ���� datastream �е� map
-
where xxx ����Ϊ filter
-
group by ������ keyby
-
sum��xx����count��xxx�����Խ���Ϊ datastream �е� aggregate function
-
etc��
-
�������������� sql AST��sql �� datasretam ���ӵ�ӳ���ϵ֮��Ҫ���о���Ĵ��������ˡ�����ȥ���� sql AST �о�����Щ�ֶ����� where ������Щ�ֶ����� group by������Ҫ���ɶ�Ӧ����� datastream ���롣
-
������������������֮�Ϳ��Խ�һ�� sql �����һ�� datastream ��ҵ�ˣ�happy ��ִ�С�
����ͼ��ʾ���������������
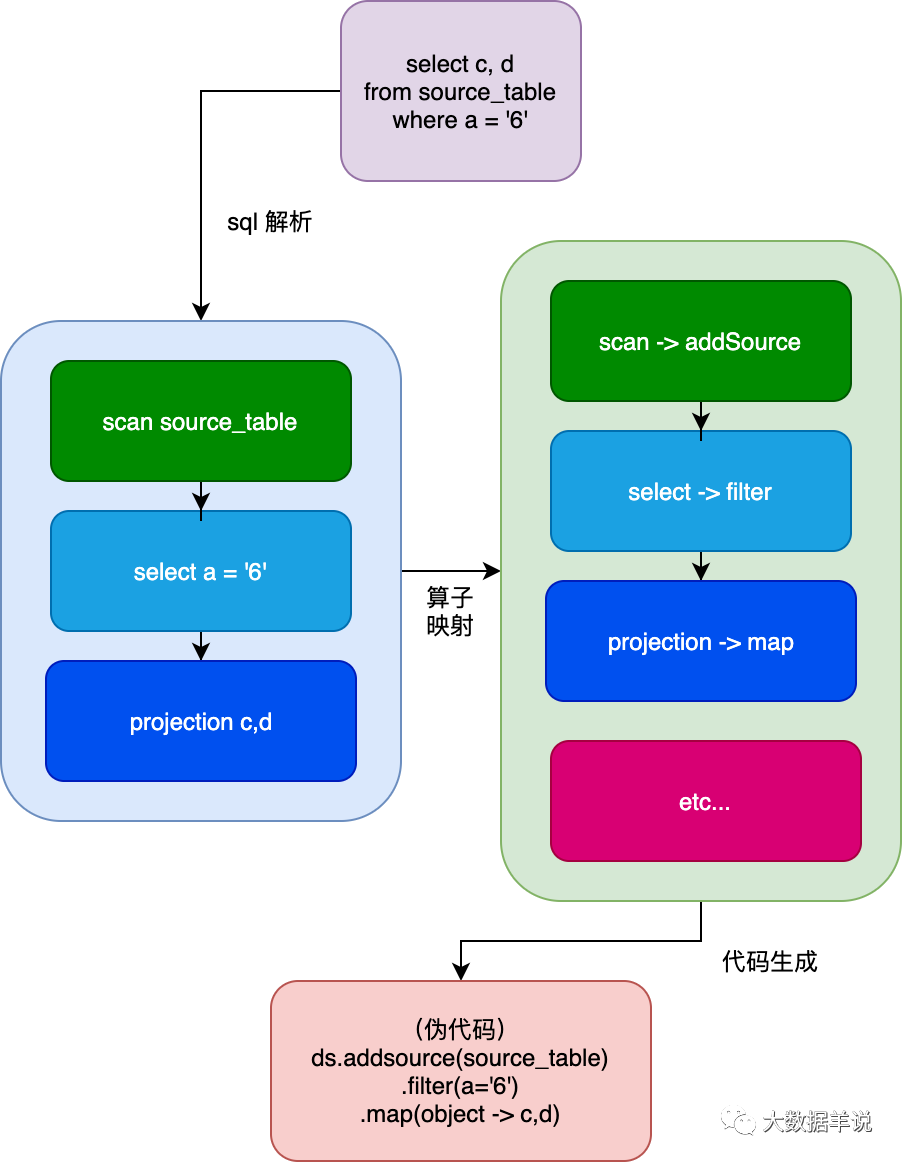
12
��ô����� flink ʵ��ʵ����ɶ��ͬ�أ�
flink �������������ģ����� flink �������м仹��һЩ���������̣������İ汾Ҳ���ǻ��� datastream����������Ĵ��������Ǻ�����һ�µġ�
���Բ��˽��������̵�ͬѧ�����Ȱ����������̽������⡣
���� �������Զ� ���ܽ�һ�� sql ��ʹ�����ǣ�sql -> AST -> codegen(java code) -> ������ run ��������
2.2.���� flink ��ʵ��
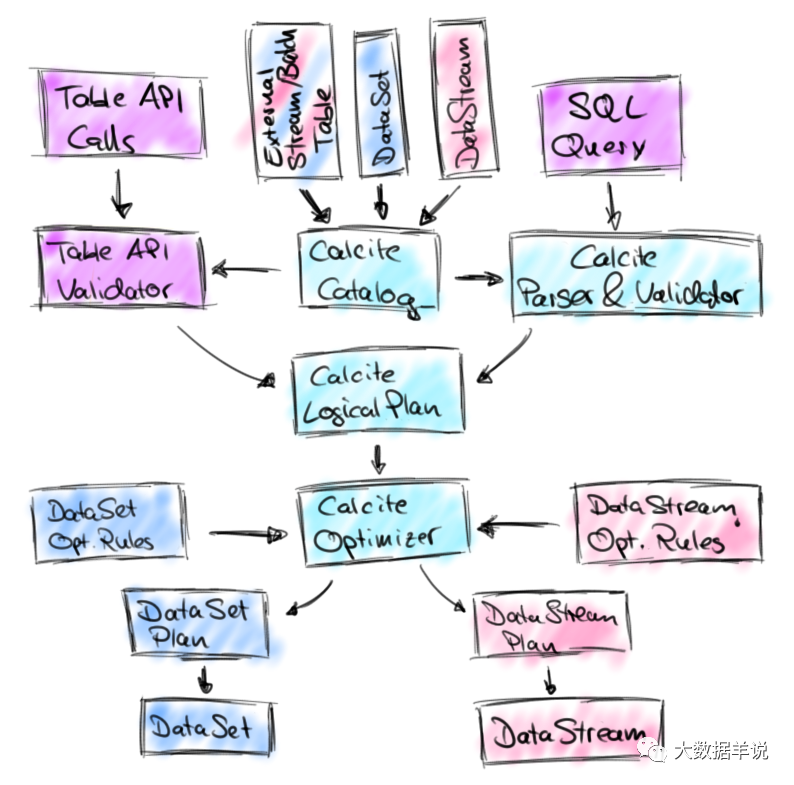
26
�����ֻ���ܿ����壬��������ͼ�������
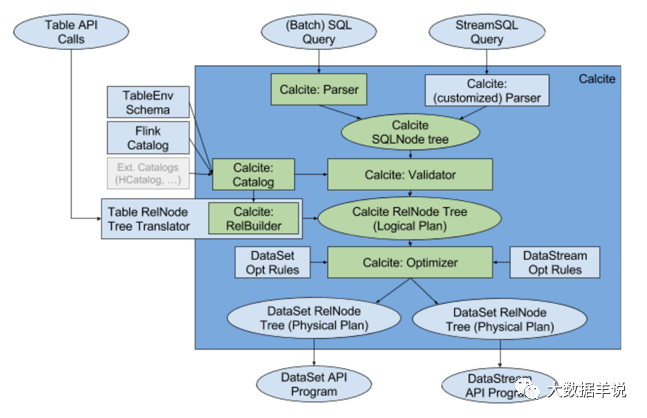
28
����һ�� flink sql �����������������£�
Notes���տ�ʼ�����е� SqlNode��RelNode ������ܱȽ�ģ�����������������̣���������ϸ������Щ���
-
sql ��������calcite parser ������sql -> AST��AST �� SqlNode Tree��
-
SqlNode ��֤����calcite validator У�飨SqlNode -> SqlNode���������ʽ������Ϣ��
-
�����������SqlNode ת��Ϊ RelNode��RelNode �� Logical Plan��SqlNode -> RelNode��
-
�Ż�����calcite optimizer �Ż���RelNode -> RelNode����֦��ν�����Ƶȣ�
-
�����ƻ����ɽ���Logical Plan ת��Ϊ Physical Plan����ͬ�� RelNode ת���� DataSet\DataStream API��
-
�������������� datastream һ��
���Է��� flink ��ʵ�� �� �������Զ� ������Ҫ���������һ�µġ�������IJ�����Ҫ�� SqlNode ��֤�����Ż�����
3.���ƪ-calcite �� flink sql �еĽ�ɫ
�����˽��� һ�� flink sql ���������� ֮������������ calcite ��������� flink �����Щɶ��
���������ܽ���˵ calcite �� flink sql �е����� sql ��������֤���Ż����ܡ�
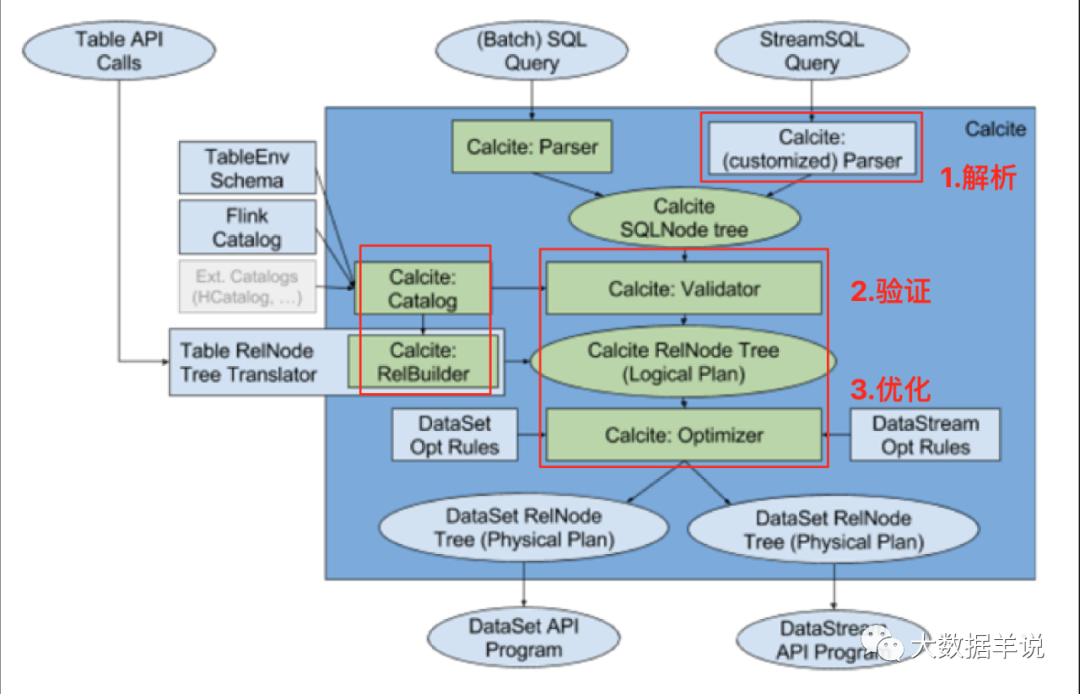
30
���� calcite ������ô���£��� calcite �Ǹ�ɶ���������Ķ�λ��ɶ��
3.1.calcite ��ɶ��
calcite ��һ����̬���ݵĹ�����ܣ������������������ݿ�ϵͳ�IJ�ͬ�Ľ�����ģ�飬���������������ݴ洢���ݴ����ȹ��ܡ�
calcite ��Ŀ����һ�ַ�������Ӧ���е�������ϣ����Ϊ��ͬ����ƽ̨������Դ�ṩͳһ�� sql �������棬������ֻ���ṩ��ѯ���棬��û��������ȥ�洢��Щ���ݡ�
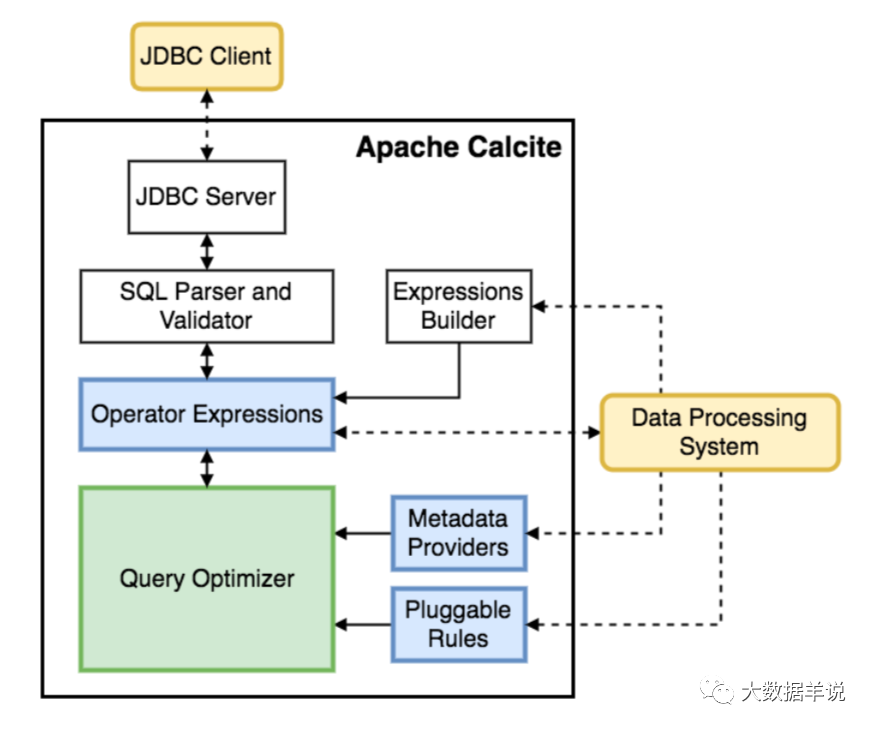
61
��ͼ��Ŀǰʹ���� calcite ���������������Ҳ�ɼ����� https://calcite.apache.org/docs/powered_by.html ��
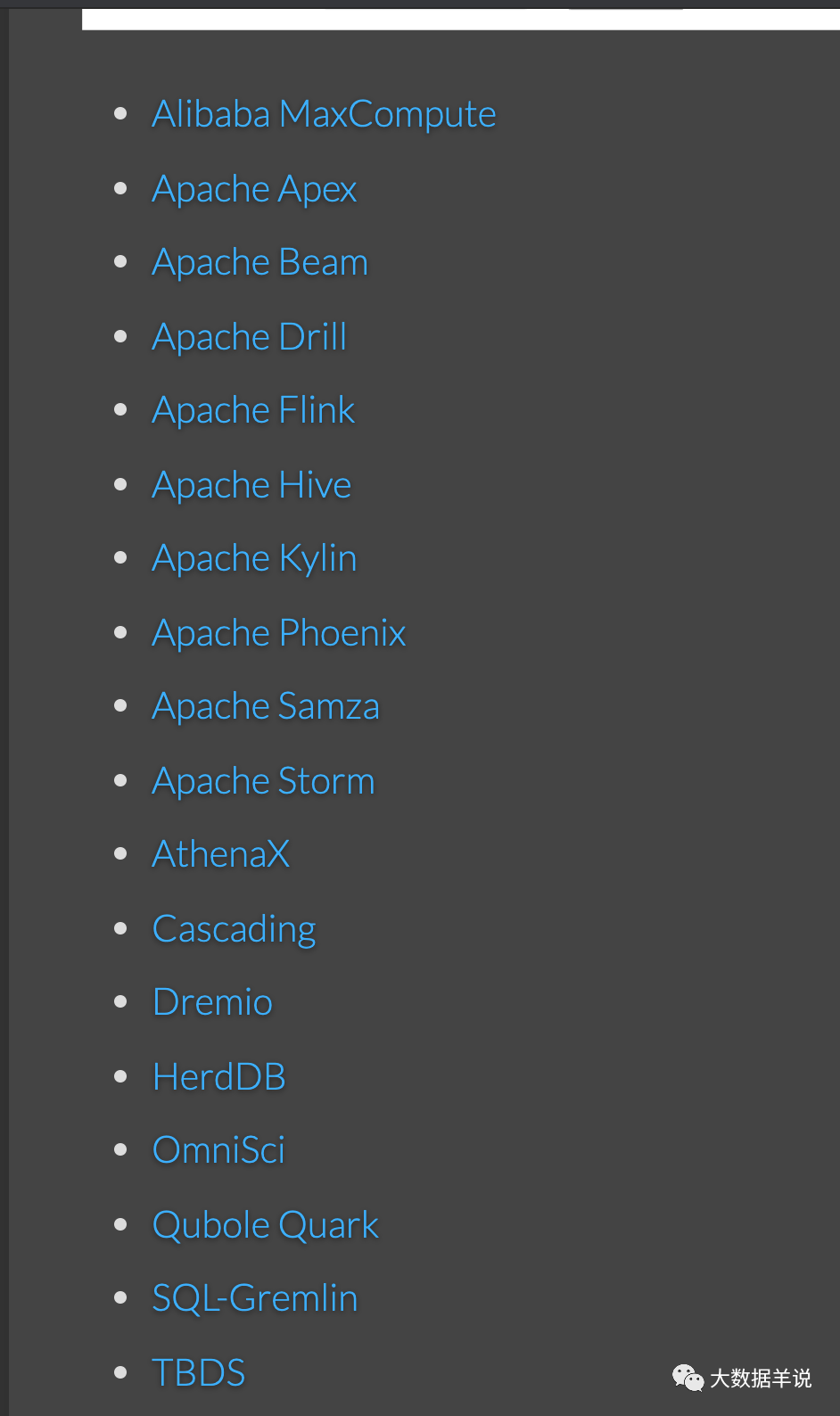
4
����˵�Ļ�������������Ϊ calcite �����⼸�����ܣ���Ȼ����������ţ�ƵĹ��ܣ�����Ȥ�����Բ��������
-
�Զ��� sql ������������˵�����·�����һ�����棬Ȼ������Ҫ�����������������һ���� sql �Ľӿڣ���ô���ǾͿ���ʹ��ֱ�� calcite�������Լ�ȥдһ��ר�ŵ� sql �Ľ��������Լ�ִ���Լ��Ż����棬calcite �˶��С�
-
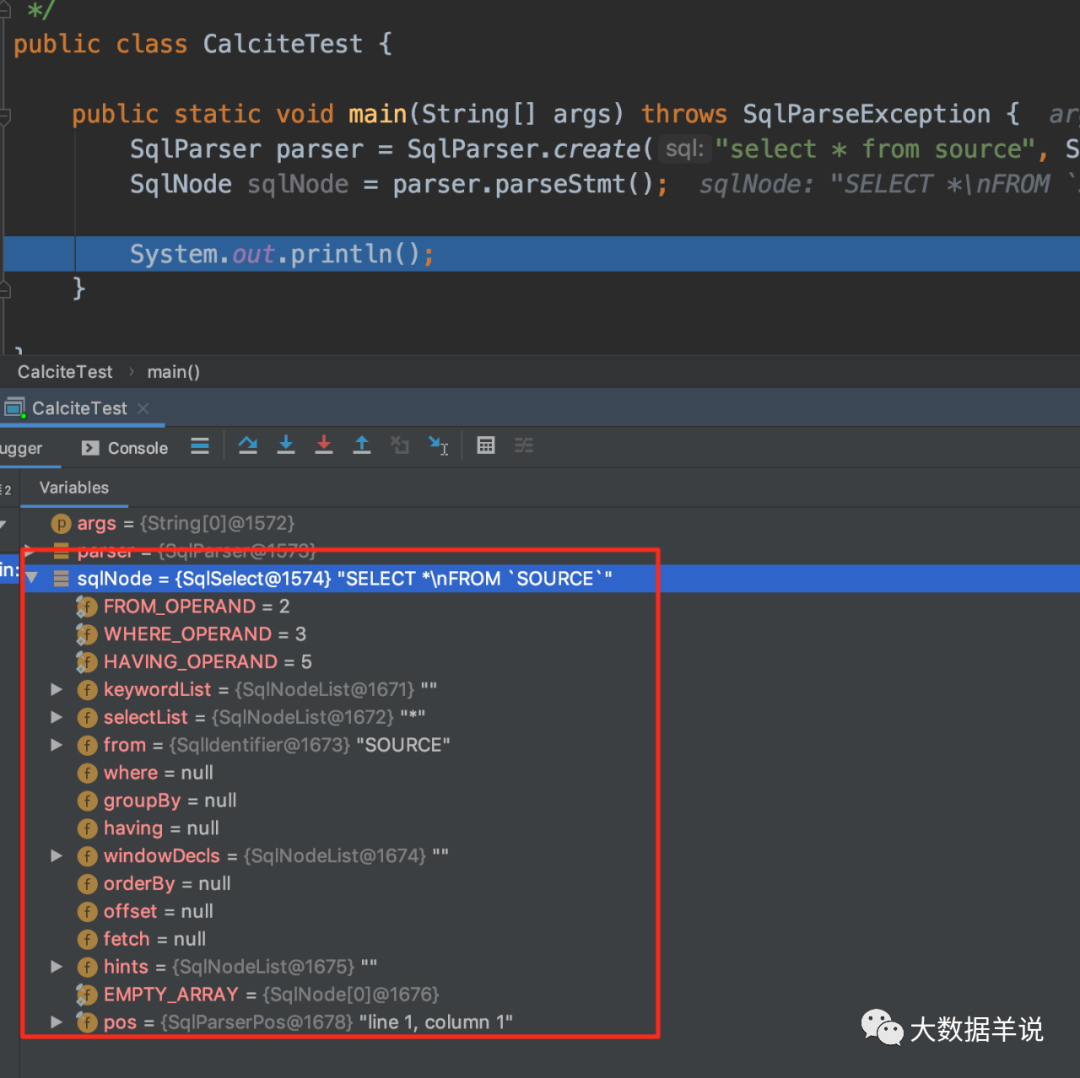
sql parser��extends SqlAbstractParserImpl������ sql �ĸ��ֹ�ϵ��������Ϊ����� AST����Щ AST ���ܶ�Ӧ������� java model���� java ���������棬�������Ҫ��������Щ����
SqlSelect��SqlNode�����Ϳ��Ը�����Щ�����������������ˡ��ٸ����ӣ�����ͼ��һ����select c,d from source where a = '6'sql������ calcite �Ľ���֮�Ϳ��Եõ� AST model��SqlNode�������Կ�����SqlSelect��SqlIdentifier��SqlIdentifier��SqlCharStringLiteral�� -
sql validator��extends SqlValidatorImpl���������������ʽ������Ϣ���� SqlNode ��ȷ��У�顣
-
sql optimizer����֦��ν�����Ƶ��Ż�
�������Щ���������������ͼ��ʾ��
29
ʵ��ʹ�� calcite ����һ�� sql��������������
2
3.2.flink sql Ϊʲôѡ�� calcite��
-
�����ظ������ӡ����ľ���Ӧ�÷����м�ֵ�������ϡ�
-
calcite ����� stream ���Ľ������������ɼ� https://calcite.apache.org/docs/stream.html��
4.����ƪ-calcite ������������
4.1.������ calcite
����֮�أ����˽�ԭ��֮ǰ������������������Ҳ��������������⡣
�����Ѿ���һ�� csv �İ����ˡ�����Ȥ�Ŀ���ֱ�� https://calcite.apache.org/docs/tutorial.html ��
����һ�� csv demo������ϸ�˽� calcite ֮ǰ����Ҫ�˽��� sql��calcite ��֧������ϵ������
4.2.��ϵ����
sql �ǻ��ڹ�ϵ�����IJ�ѯ���ԣ��ǹ�ϵ�����ڹ����ϵ�һ�ֺܺõ�ʵ�ַ������ڹ����У���ϵ�����ѱ������ sql ���������⡣��ϵ������ sql �Ĺ�ϵ���¡�
-
���Խ�һ�� sql ����Ϊһ����ϵ��������ʽ����ϡ��� sql �еIJ���������ת���ɹ�ϵ�����ı���ʽ��
-
sql ��ִ���Ż������е��Ż���ǰ�ᶼ���Ż�ǰ���Ż�������ִ�н����ͬ�����ȼ۽������ǻ��ڹ�ϵ��������ġ�
4.2.1.���ù�ϵ����
�ܽ��£�����Щ���õĹ�ϵ������
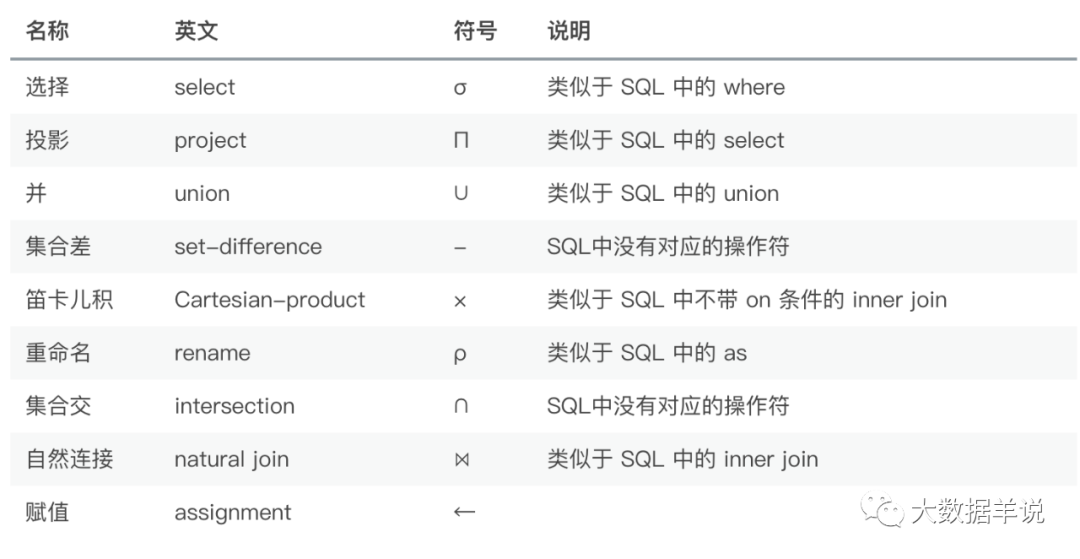
50
4.2.2.sql �Ż�֧��֮��ϵ�����ȼ۱任
��ϵ�����ȼ۱任�� calcite optimizer �Ļ������ۡ�
������һЩ�ȼ۱任�����ӡ�
1.���ӣ�?�����ѿ������������Ľ�����
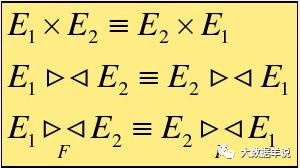
51
2.���ӣ�?�����ѿ������������Ľ����
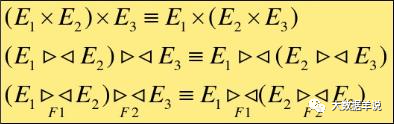
3.ͶӰ�������Ĵ��Ӷ���

4.ѡ�������Ĵ��Ӷ���
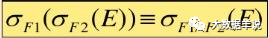
5.ѡ��������ͶӰ�������Ľ���
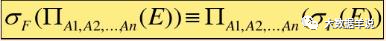
6.ѡ��������ѿ������������Ľ���

7.ѡ�������벢�������Ľ���
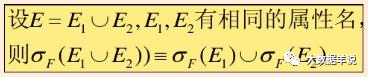
8.ѡ��������-���Ľ���

9.ͶӰ��������ѿ������������Ľ���

10.ͶӰ�������벢�������Ľ���

Ȼ��һ�����ڹ�ϵ�����Ż���ʵ�� sql ������
��������ϵ A��a1,a2,a3,������B��b1,b2,b3, �� ����C��a1,b1,c1,c2, �� ��
��һ����ѯ�������£�
SELECT A.a1 FROM A��B��C WHERE A.a1 = C.a1 AND B.b1 = C.b1 AND f(c1)
1.���Ƚ� sql תΪ��ϵ�����������
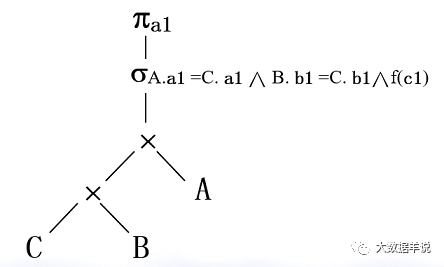
36
2.�Ż���ѡ�������Ĵ��Ӷ��ɡ�
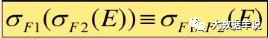
47
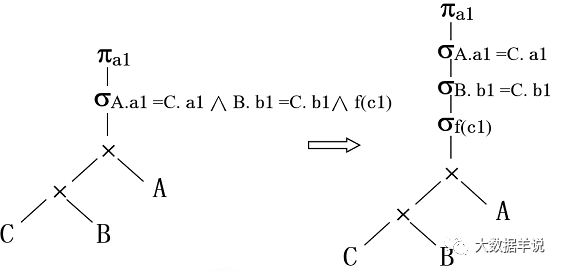
37
3.�Ż���ѡ��������ѿ������������Ľ�����

48
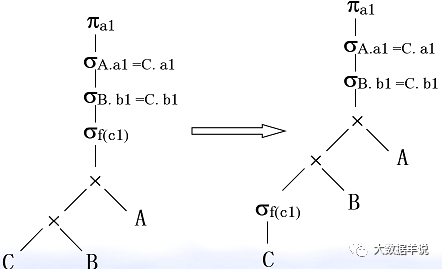
38
4.�Ż���ͶӰ��������ѿ������������Ľ�����

49
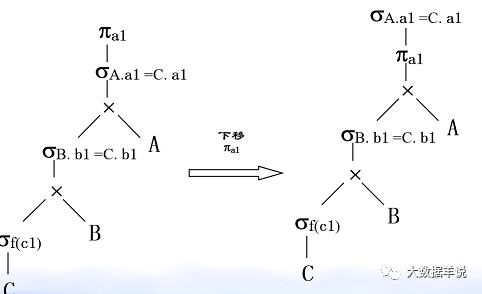
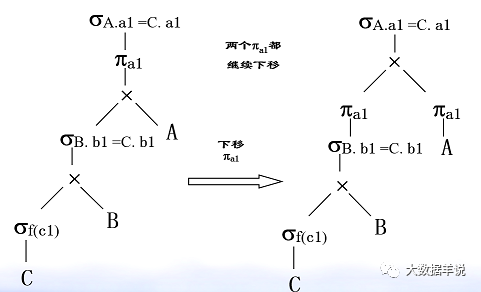
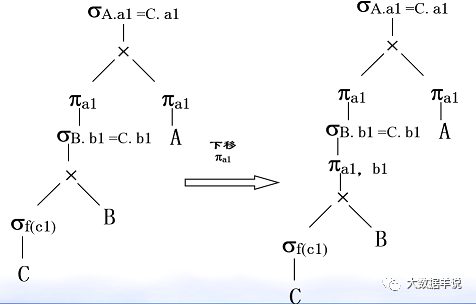
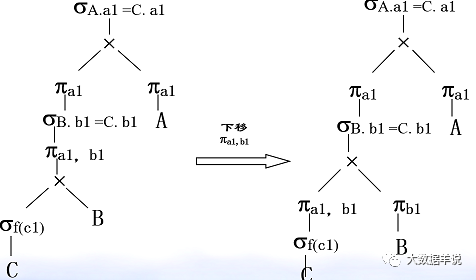
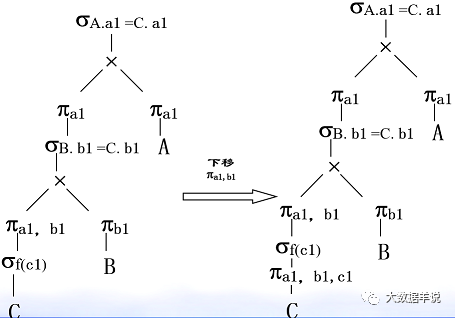
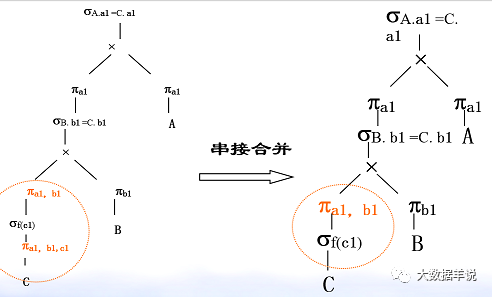
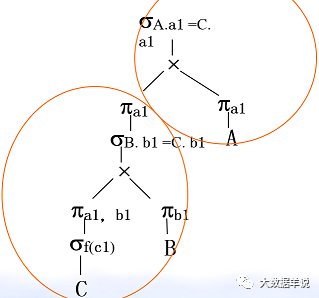
���ڹ�ϵ�������Ǿ����˴��µ��˽⡣
����֮�⣬���ڸ������˽� flink sql��calcite ���ԣ����ǻ���Ҫ�˽�һ���� calcite ������ϵ������Щ��Ҫ model��
4.3.calcite ��֪�Ļ��� model
calcite �������������������Ҫ�� model ���������� flink sql ��������ʱ��Ҫ֪���ġ�
-
SqlNode��sql ת�����ɣ���������Ϊֱ�۱��� sql ��νṹ�ĵ� model
-
RelNode��SqlNode ת�����ɣ���������Ϊ�� SqlNode ת��Ϊ��ϵ�����������ϵ������νṹ�� model
�ٸ�������˵���£��������� flink sql����������֮��� SqlNode��RelNode ����ͼ��
SELECTsum(part_pv) as pv,window_start
FROM (SELECTcount(1) as part_pv,cast(tumble_start(rowtime, INTERVAL '60' SECOND) as bigint) * 1000 as window_startFROMsource_db.source_tableGROUP BYtumble(rowtime, INTERVAL '60' SECOND), mod(id, 1024)
)
GROUP BYwindow_start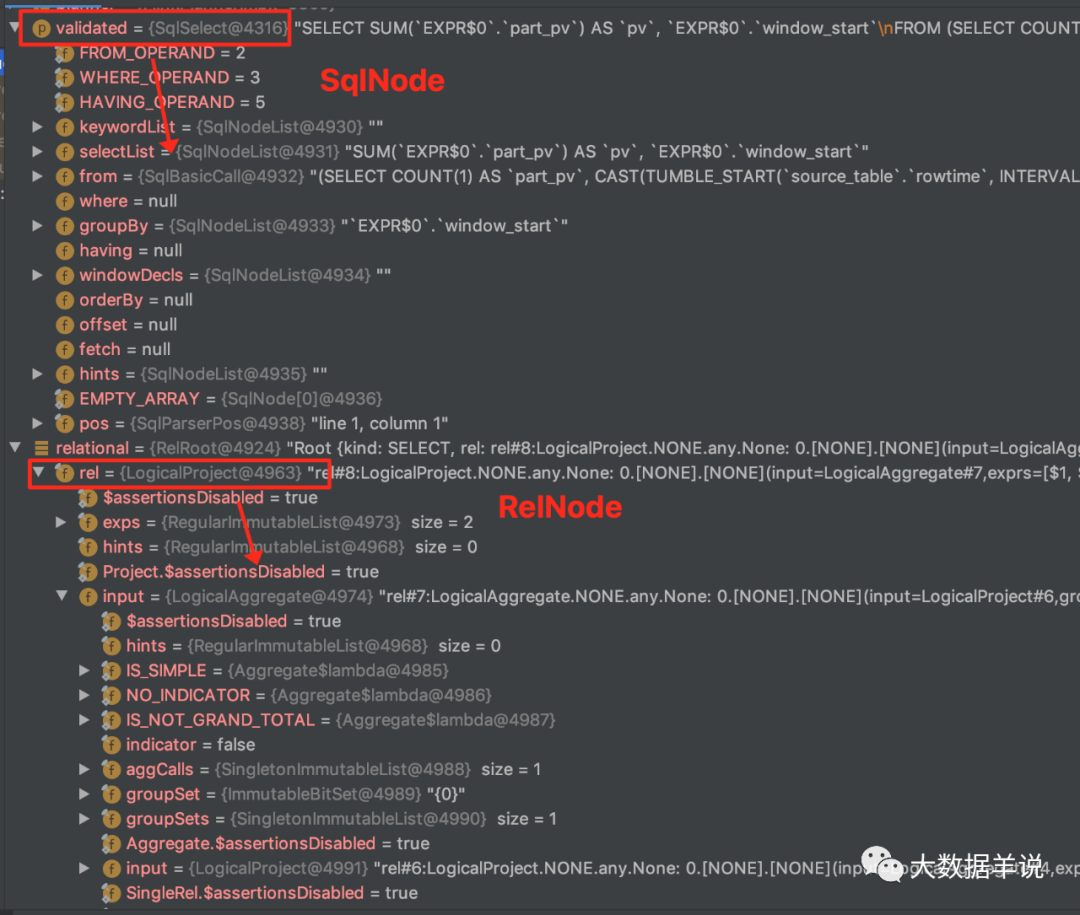
62
���Կ��� SqlNode ������������ sql �IJ�νṹ������ selectList��from��where��group by �ȡ�
RelNode �������ǹ�ϵ�����IJ�νṹ��ÿһ�㶼��һ�� input ���нӡ���������Ż���������״�ṹһ����

63
4.4.calcite �Ĵ������̣��� flink sql Ϊ����
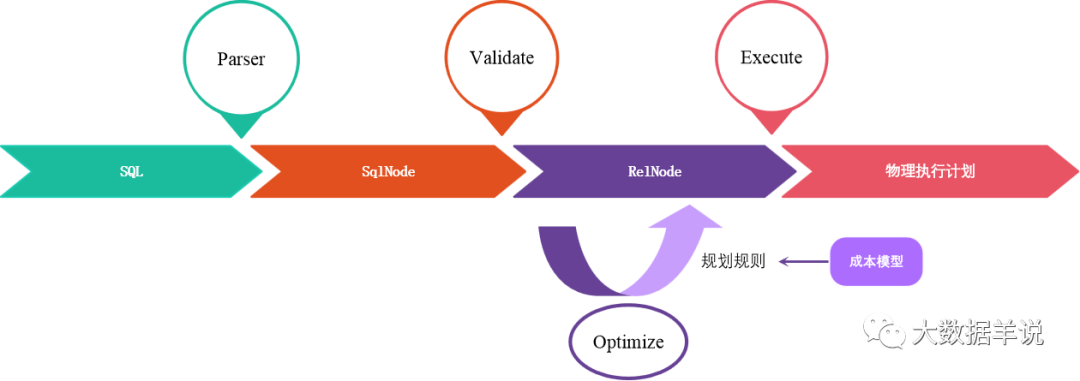
29
����ͼ��ʾ���˴����ǽ���Ͻڽ��ܵ� calcite �� model���Լ� flink sql ��ʵ������һ���䴦�����̣�
-
sql ������sql �C> SqlNode��
-
SqlNode ��֤��SqlNode �C> SqlNode��
-
���������SqlNode �C> RelNode��
-
�Ż��Σ�RelNode �C> RelNode��
4.4.1.flink sql demo
SELECTsum(part_pv) as pv,window_start
FROM (SELECTcount(1) as part_pv,cast(tumble_start(rowtime, INTERVAL '60' SECOND) as bigint) * 1000 as window_startFROMsource_db.source_tableGROUP BYtumble(rowtime, INTERVAL '60' SECOND), mod(id, 1024)
)
GROUP BYwindow_start����ǰ����������ת�������� ��ִ�� TableEnvironment#sqlQuery ���С�
���һ���Ż�����ִ�� sink ����ʱ���У���������������� tEnv.toRetractStream(result, Row.class)��
Դ�빫�ںź�̨�ظ�flink sql ֪������Ȼ������| flink sql Լ�� calcite��ȡ��
4.4.2.sql ������sql �C> SqlNode��
sql ������ʹ�� Sql Parser �� sql ����Ϊ SqlNode����һ����ִ�� TableEnvironment#sqlQuery ���С�
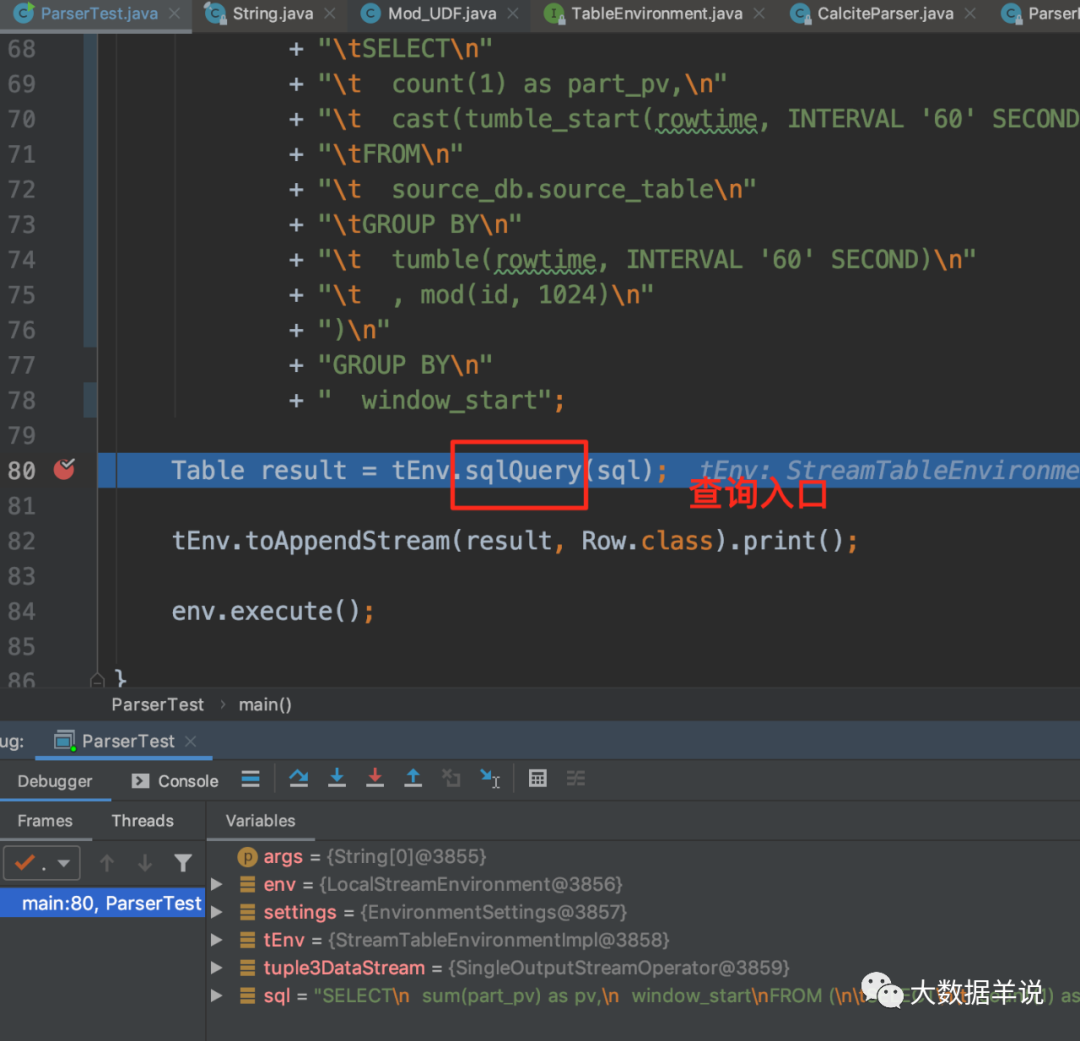
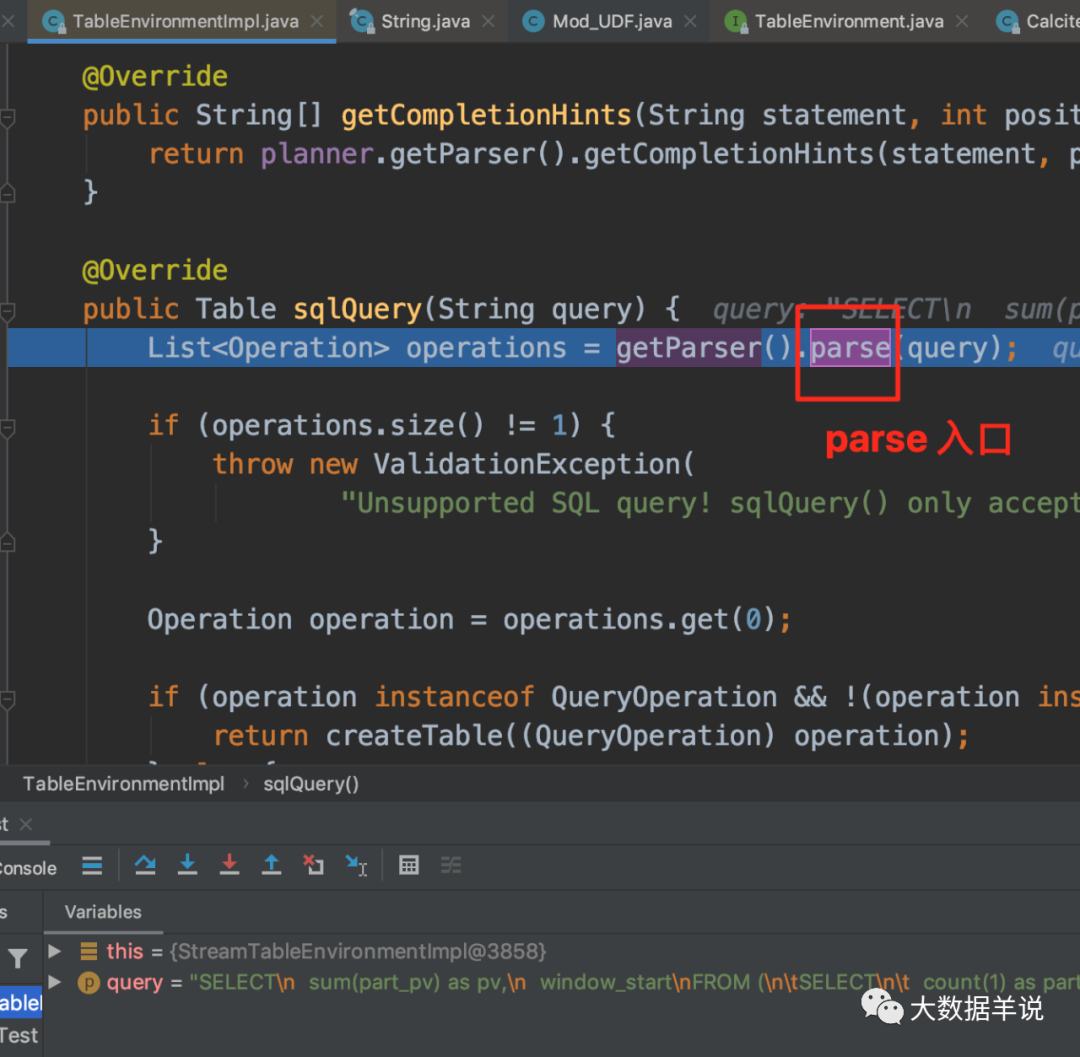
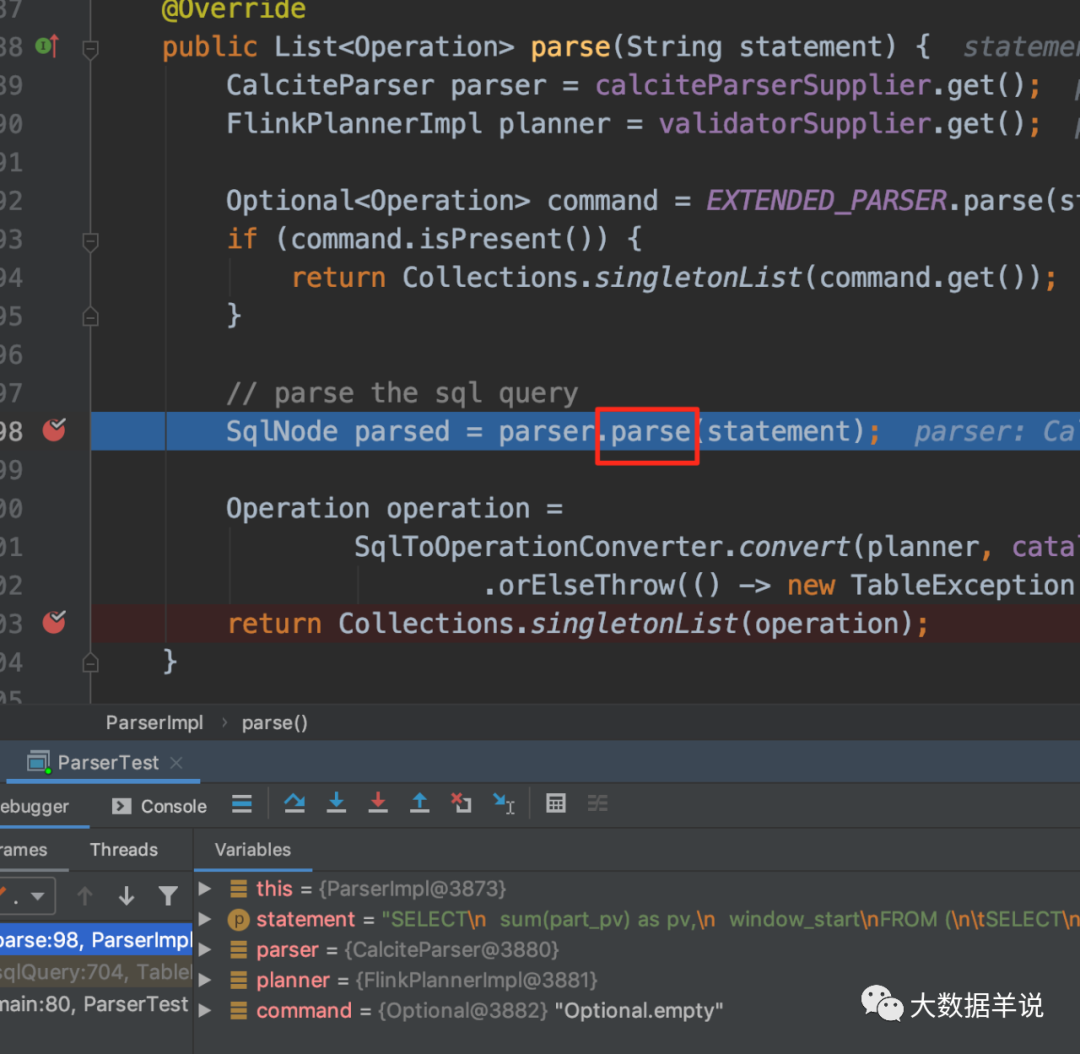
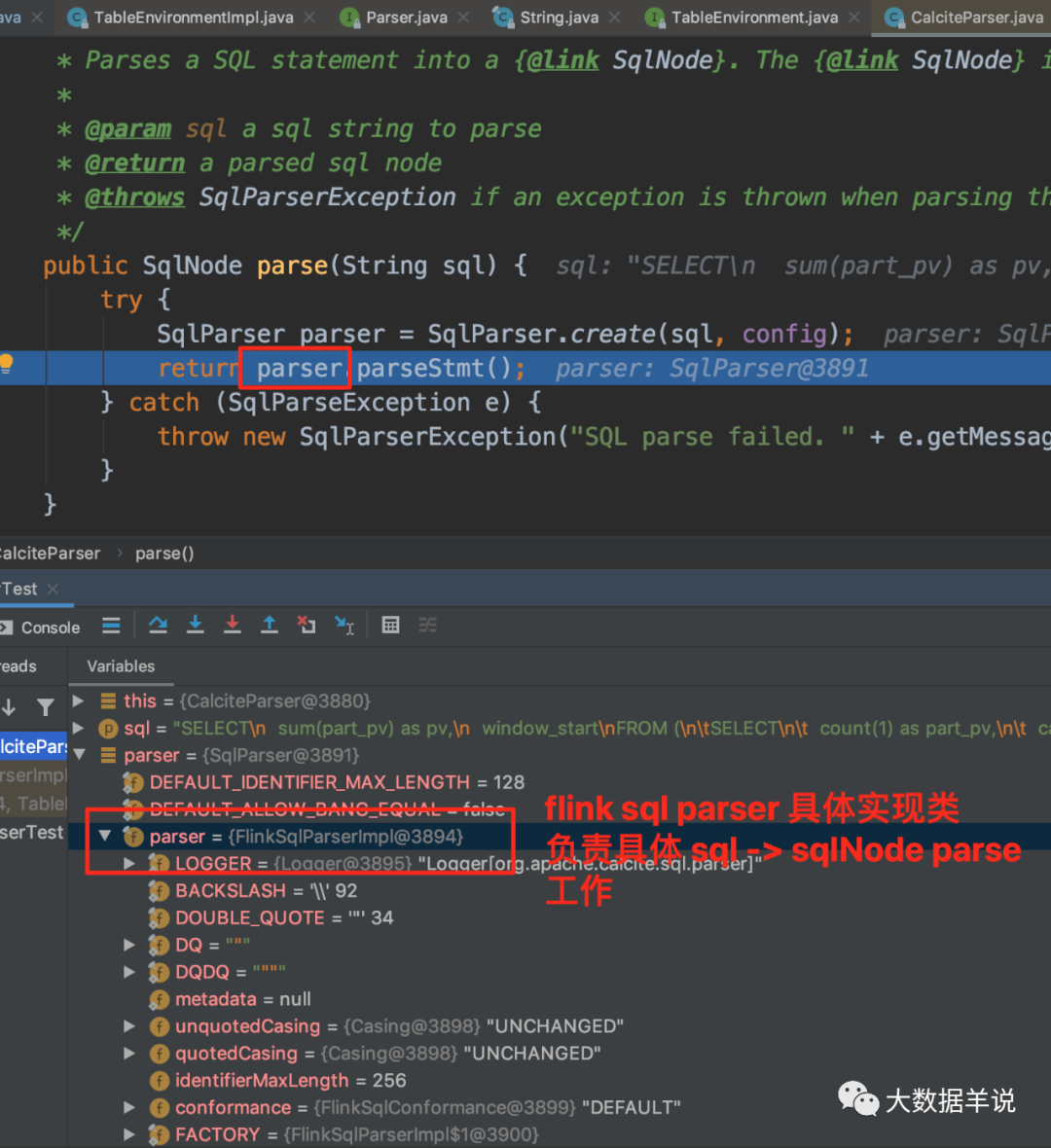
���Դ���ͼ���� flink sql ����ʵ������ FlinkSqlParserImpl��
68
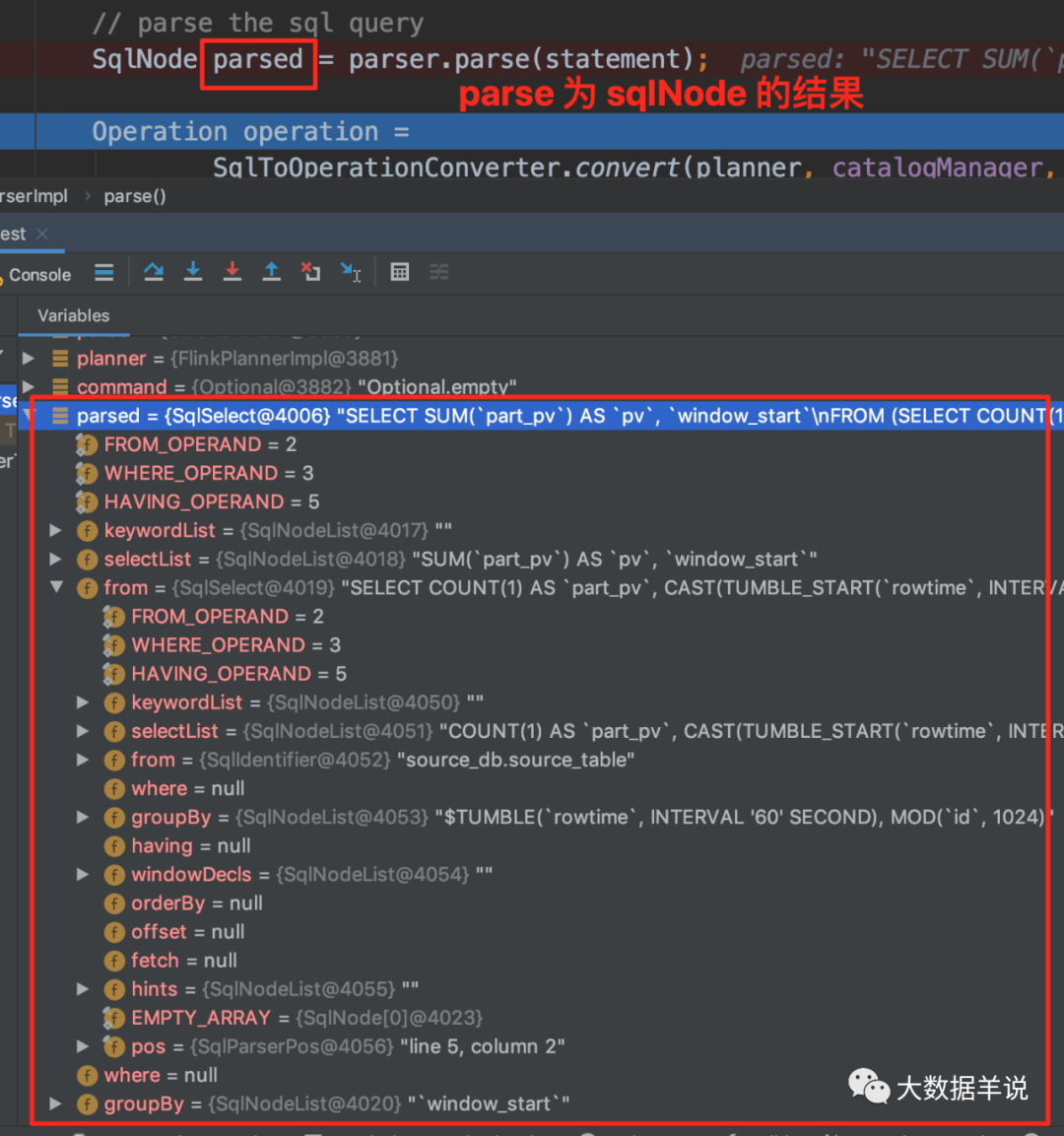
���� parse �õ� SqlNode ����ͼ��
4.4.3.SqlNode ��֤��SqlNode �C> SqlNode��
����ĵ�һ�������� SqlNode ������һ��δ����֤�ģ���һ����������Σ�����ǰ��Ҫ֪��Ԫ������Ϣ�������������������ֶ��������������������͵ļ�顣���������ʵ�����£�
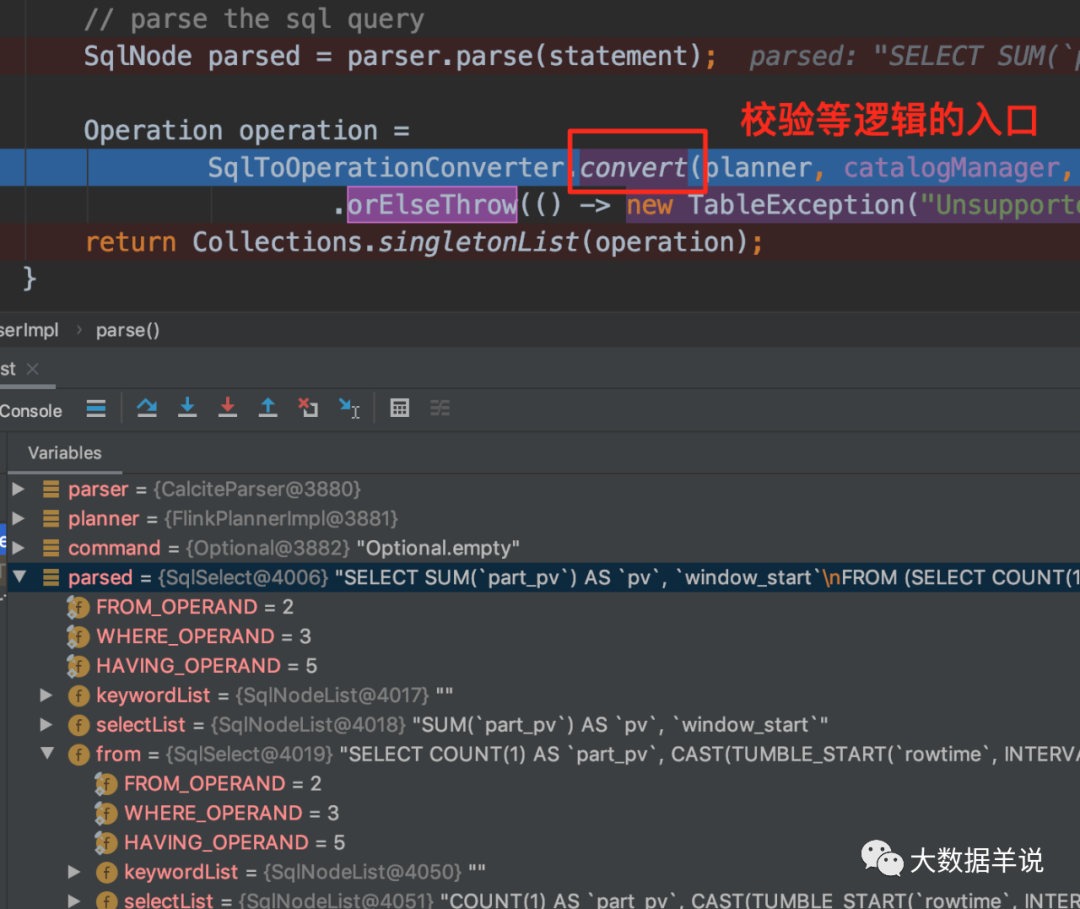
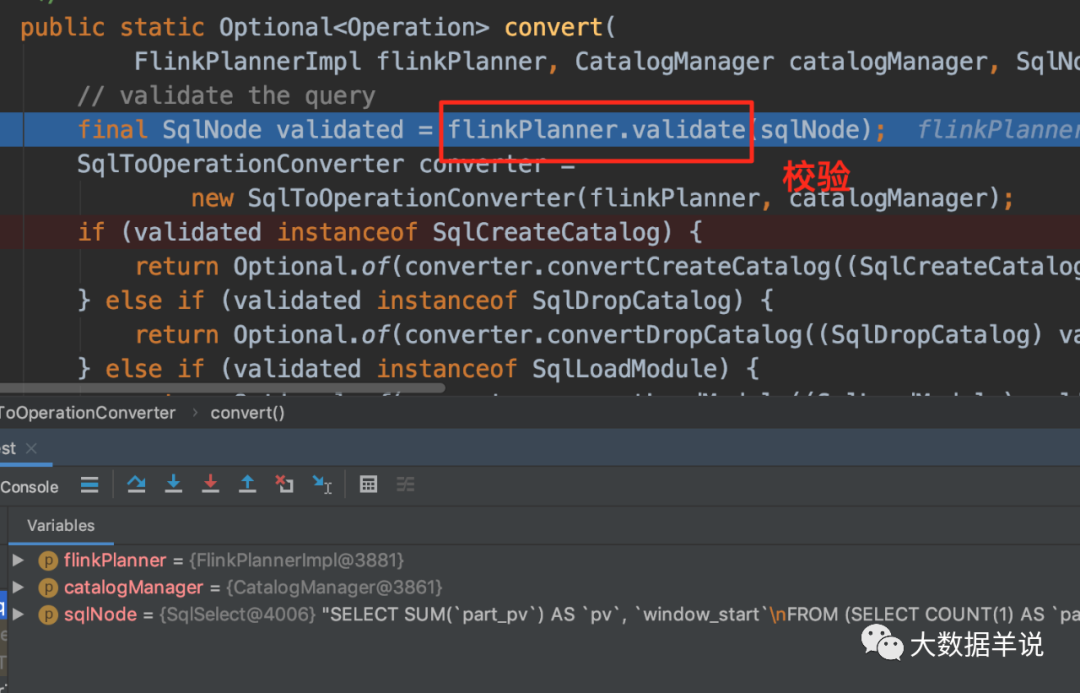
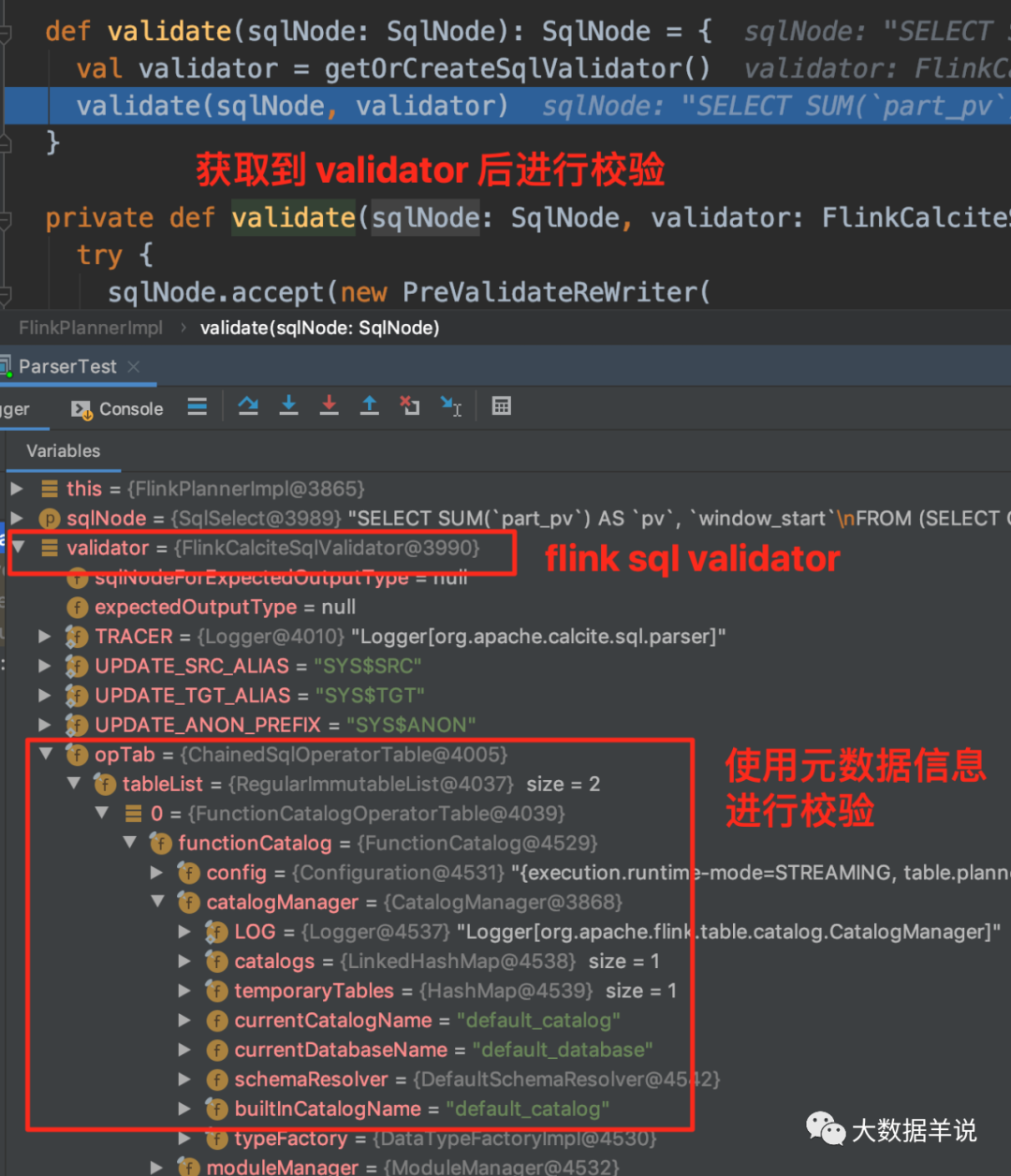
���Դ���ͼ���� flink sql У�����ľ���ʵ������ FlinkCalciteSqlValidator�����а�����Ԫ������Ϣ���Ӷ����Խ���Ԫ������Ϣ��顣
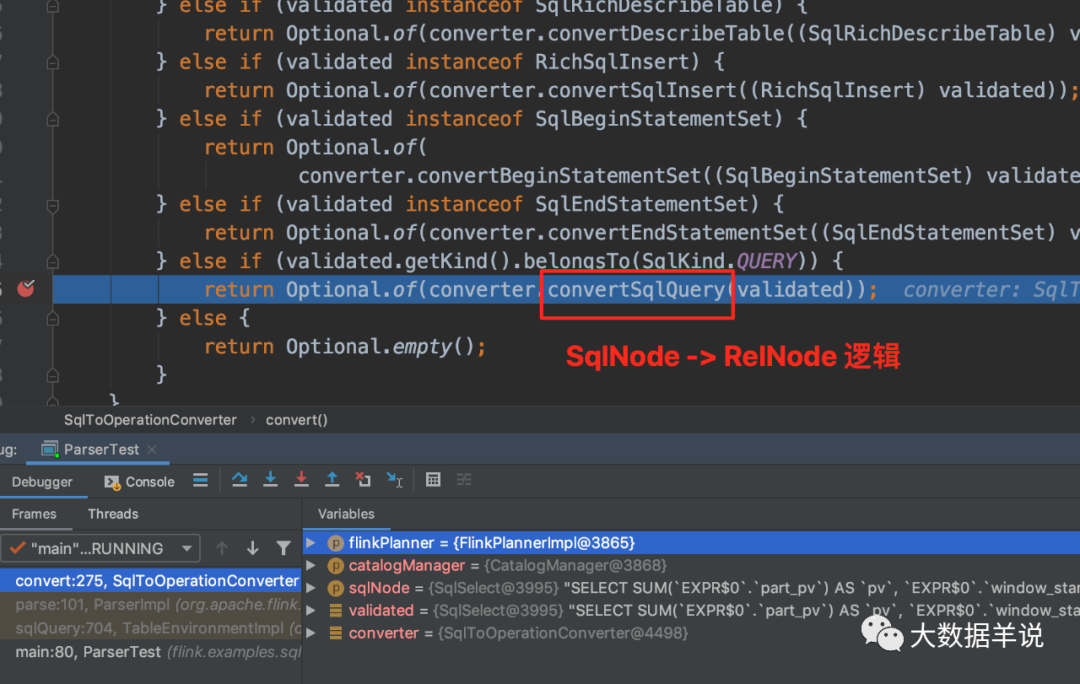
4.4.4.���������SqlNode �C> RelNode��
��һ�����ǽ� SqlNode ת���� RelNode��Ҳ����������Ӧ�Ĺ�ϵ�����������������һ�㶼�������ƻ���Logical Plan����
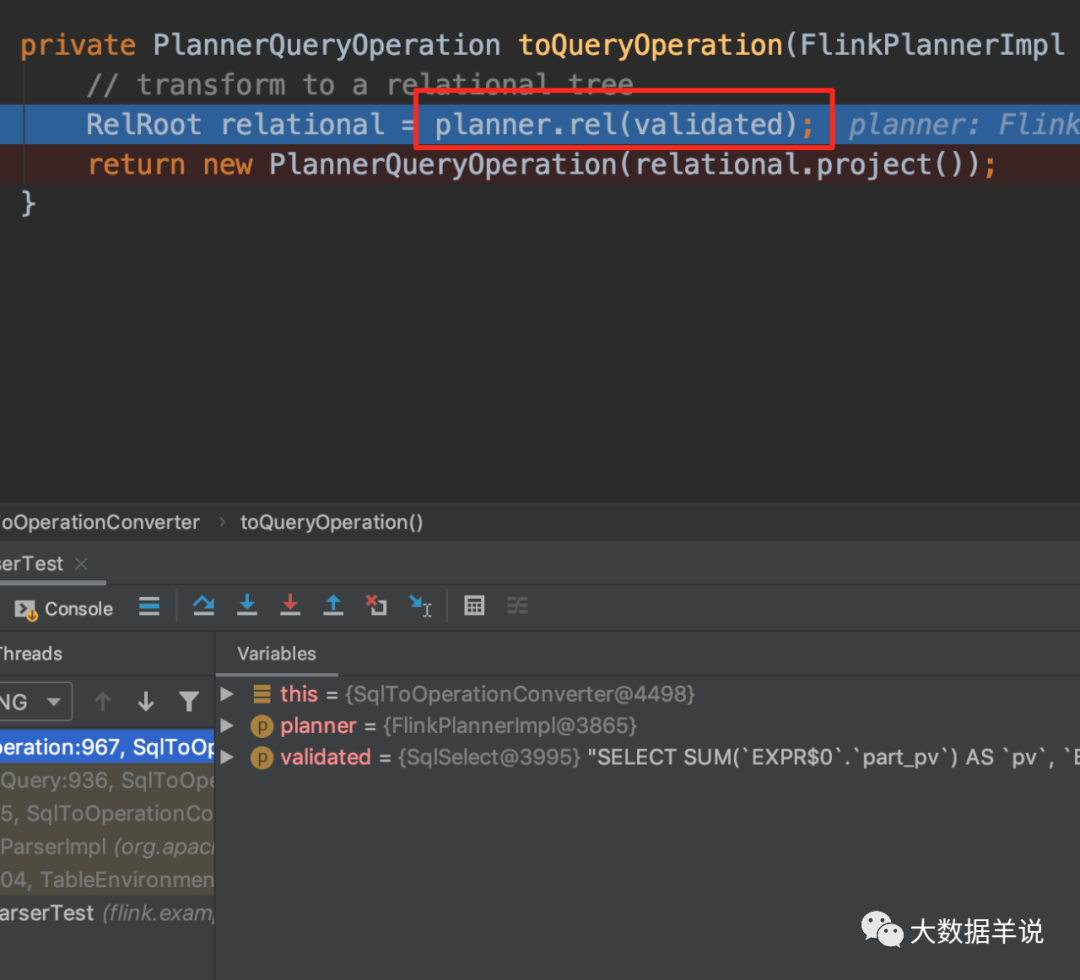
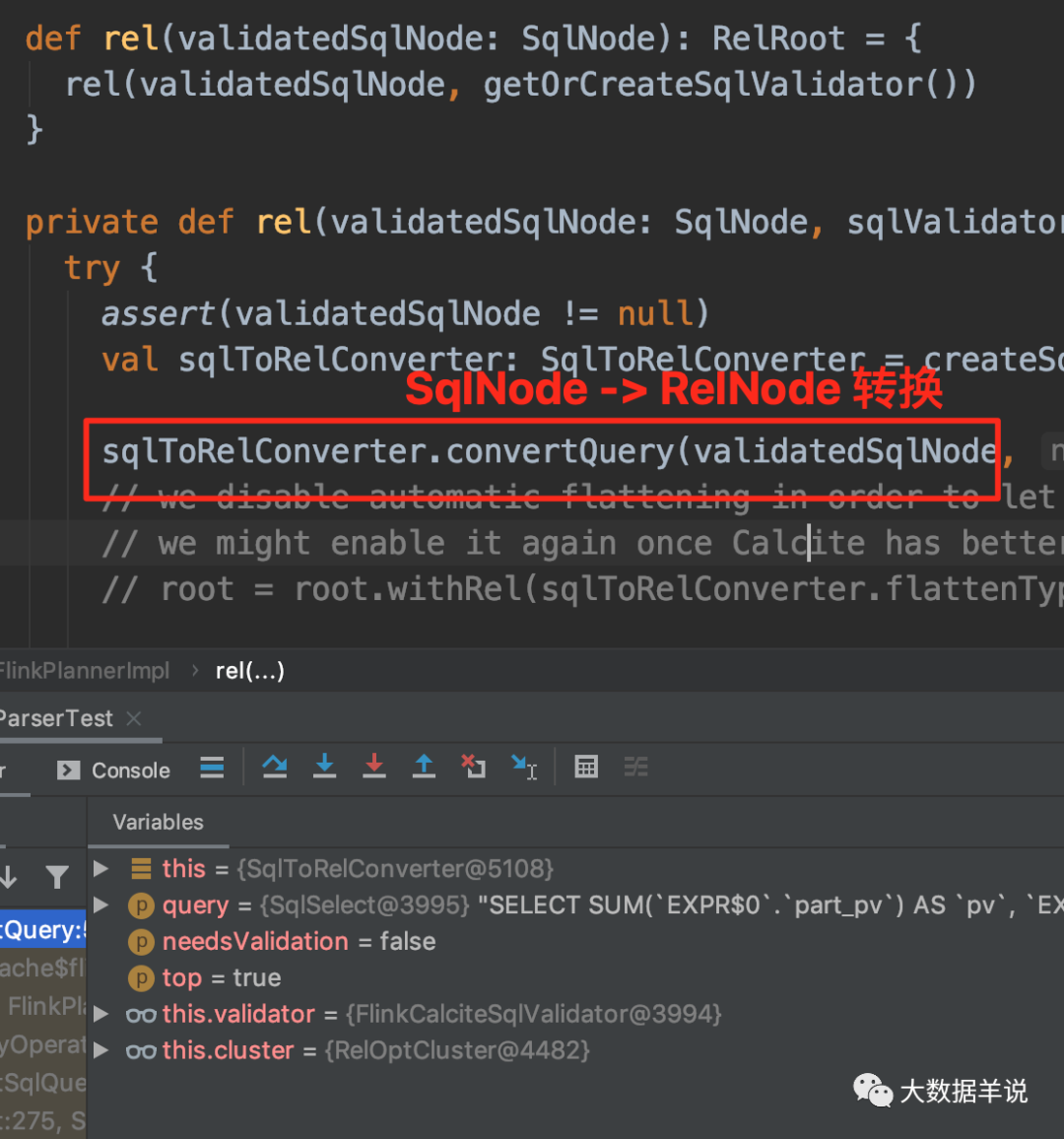
4.4.5.�Ż��Σ�RelNode �C> RelNode��
��һ�������Ż��Ρ���ϸ���ݿ����Լ� debug ����鿴���˴�������
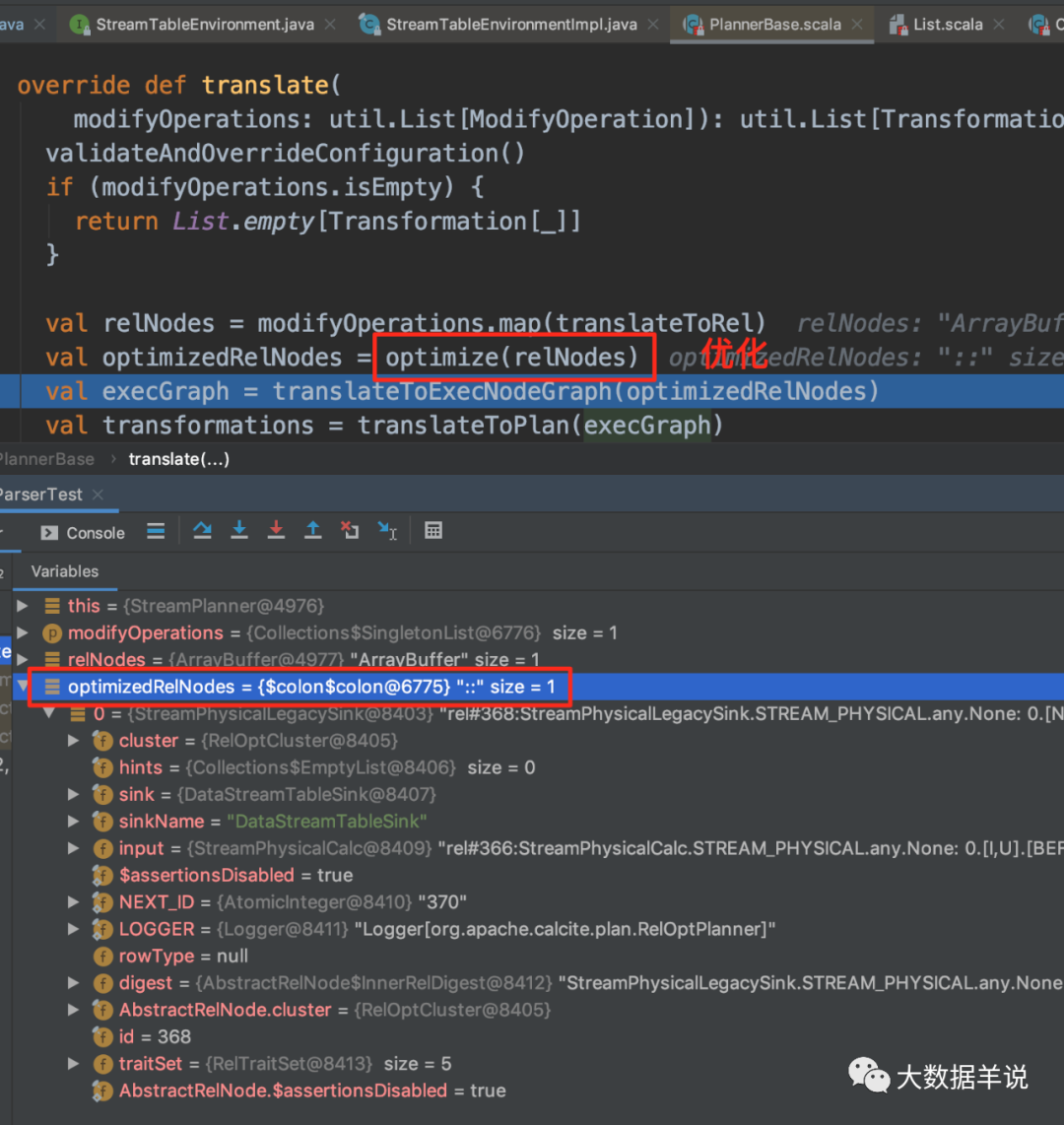
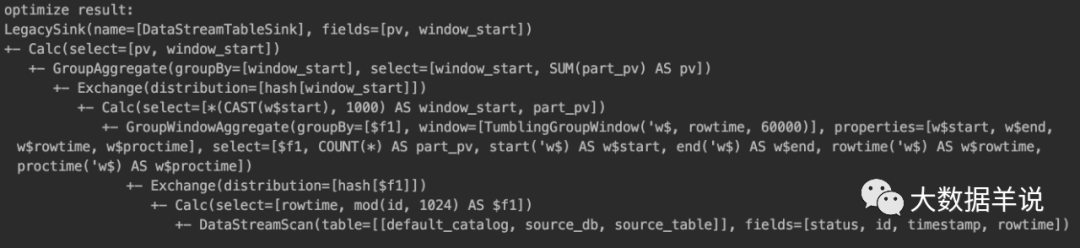
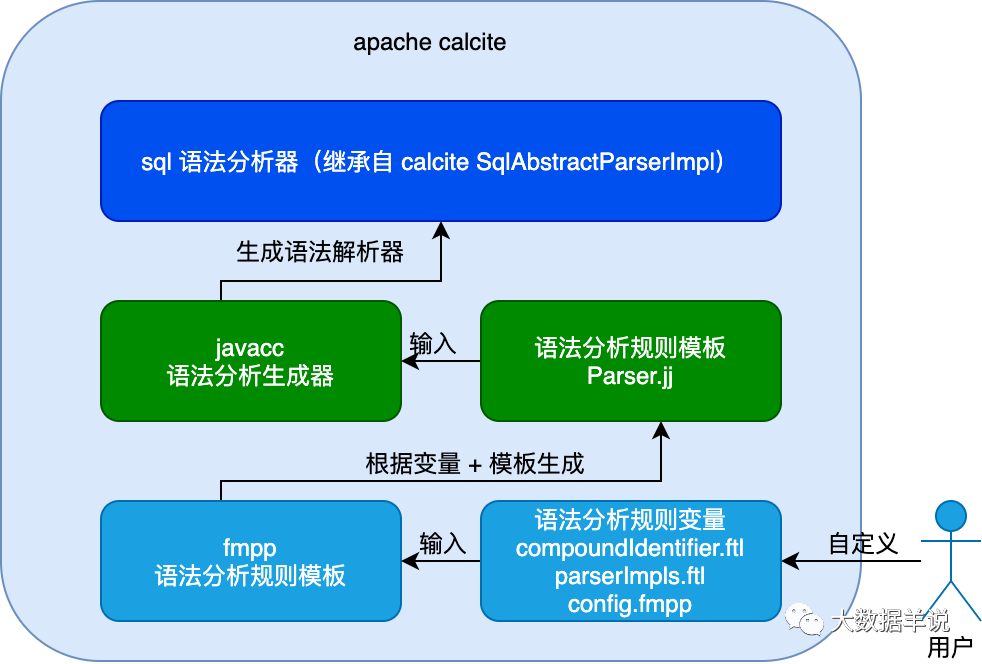
4.5.calcite ��ô������ôͨ�ã�
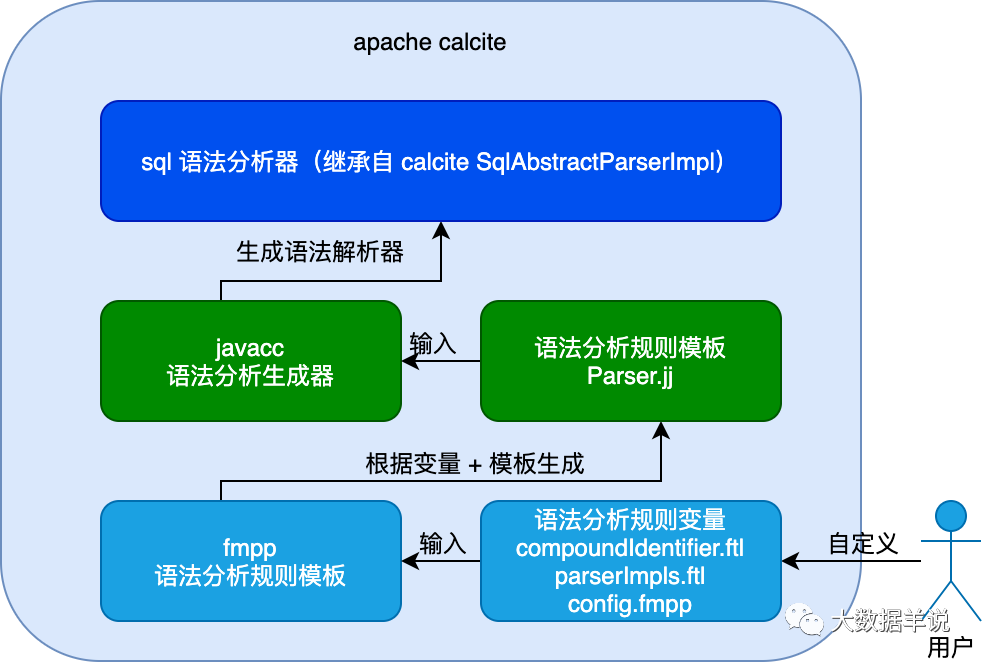
�˴��� calcite parser ����˵������ģ��Ϊʲô��ͨ�ã�������ģ�鶼�����Ƶķ�ʽ��
��˵��������Ϊ calcite parser ģ���ṩ�˽ӿڣ������ parse ���������ǿ��Ը����û��Զ���������õġ���ҿ��Կ���ͼ������������һ��ͼ����������
5
����ͼ������ sql ����������������һ������ģ����� �û��Զ�������������������������� sql ��������ʵҲ�Ǹ����û��Զ���� �������� ȥ���ɵ� ���������� ������ �Ķ�̬�������� javacc �����������calcite �ṩ����ͳһ�� sql AST ģ�͡��Ż�ģ�ͽӿڵȣ�������Ľ���ʵ�ֽ������û��Լ�ȥ������
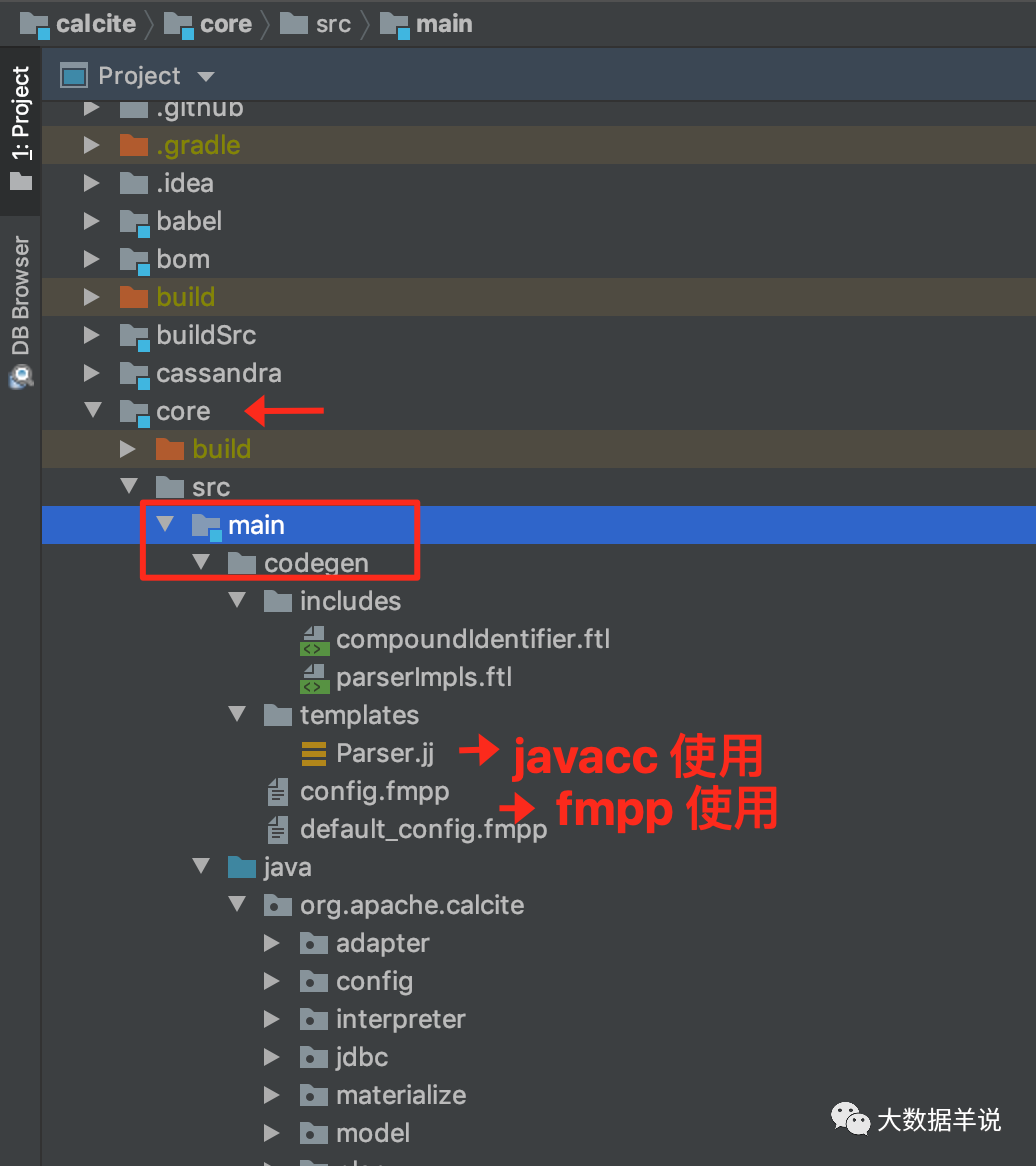
javacc ����� calcite �ж���� Parser.jj �ļ������ɾ���� sql parser ���루����ͼ������� sql parser ���������ǽ� sql ת���� AST ��SqlNode�������� calcite �����ĸ���ϸ���ݼ� https://matt33.com/2019/03/07/apache-calcite-process-flow/ ��
��ͼ�漰�����ļ���ҿ������� calcite Դ�� https://github.com/apache/calcite.git ֮���л��� core module ֮��鿴��
31
4.5.1.javacc ��ɶ��
javacc ��һ���� java ���������ܻ�ӭ�������������������������������߿��Զ�ȡ������������������������������ת���ɿ���ʶ����ƥ������ java �������� 100% �Ĵ� java ���룬�����ڶ���ƽ̨�����С�
���� javacc ��������һ��ͨ�õ���������������û�����ʹ�� javacc ���ⶨ��һ�� DSL ����������
�ٸ����ӣ������������� sql Ҳ�������ͨ�ã������ʹ�� javacc �Լ�����һ������ user-define-ql��Ȼ��ʹ�� javacc ��Ϊ��� user-define-ql �Ľ��������Dz��Ǻ������������Լ�ȥ��������ˡ�
4.5.2.���� javacc
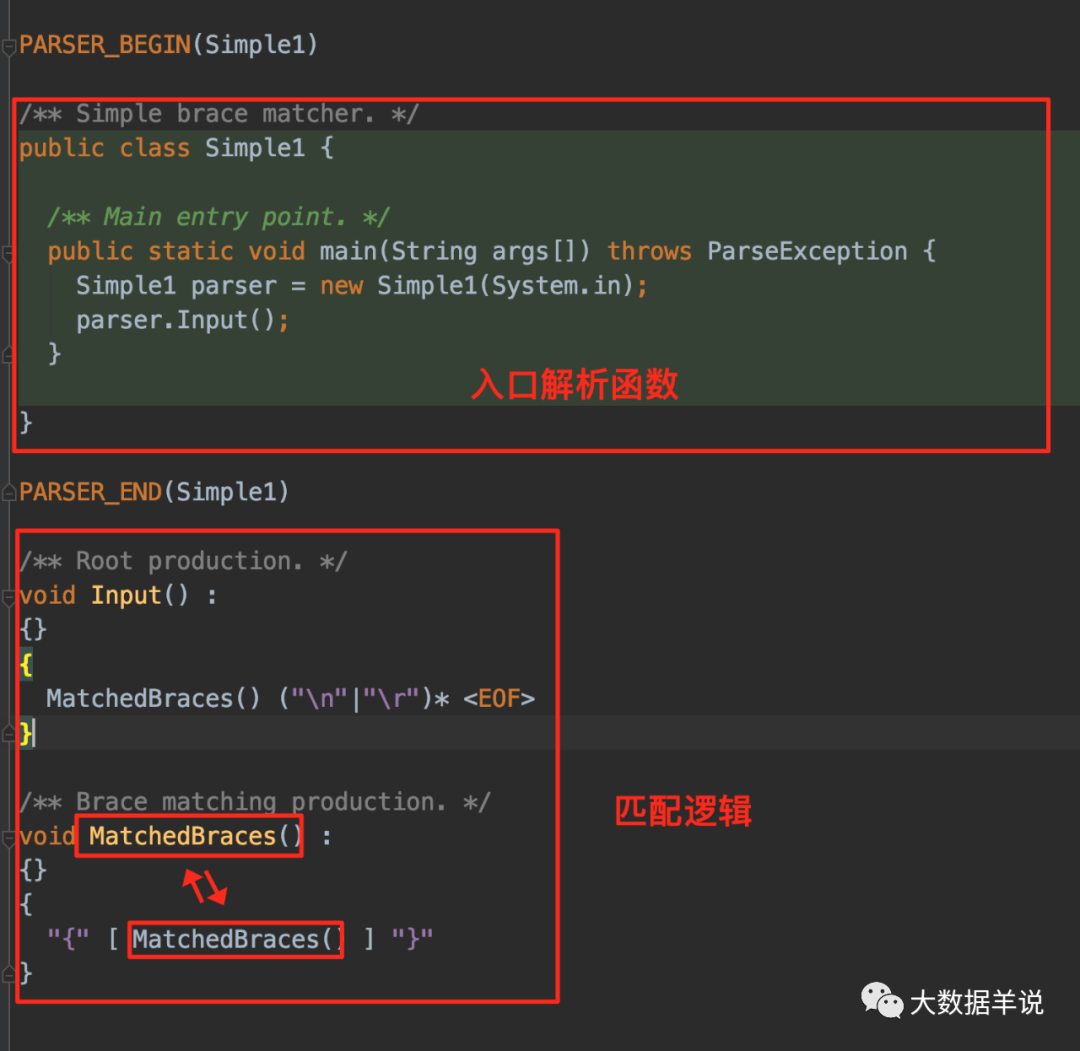
���ﲻ���ܾ���� javacc ���ֱ���Թ����� Simple1.jj Ϊ��������ϸ����ܿ��Բο�������https://javacc.github.io/javacc/�� ����һ�²��͡�
-
https://www.cnblogs.com/Gavin_Liu/archive/2009/03/07/1405029.html
-
https://www.yangguo.info/2014/12/13/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86-Javacc%E4%BD%BF%E7%94%A8/
-
https://www.engr.mun.ca/~theo/JavaCC-Tutorial/javacc-tutorial.pdf
Simple1.jj ������ʶ��һϵ�е� {��ͬ�����Ļ�����}��֮����� 0 ���������ս����
7
�����ǺϷ����ַ������ӣ�
{}��{
{
{
{
{}}}}}��etc.
�����Dz��Ϸ����ַ������ӣ�
{
{
{
{
��{}{}��{}}��{
{}{}}��etc.
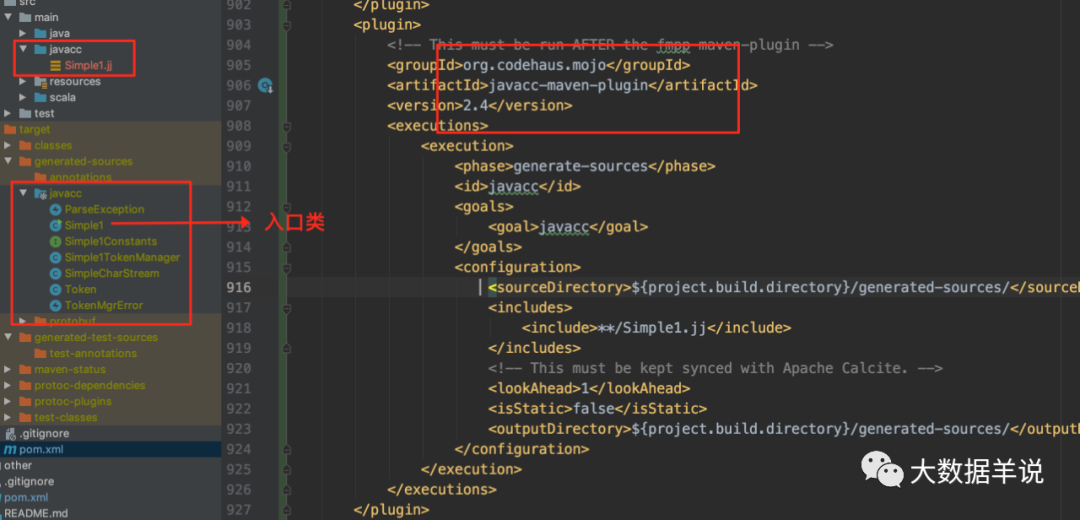
������������ʵ�ʽ� Simple1.jj �������ɾ���Ĺ�����롣
�� pom ��� javacc build �����
<plugin><!-- This must be run AFTER the fmpp-maven-plugin --><groupId>org.codehaus.mojo</groupId><artifactId>javacc-maven-plugin</artifactId><version>2.4</version><executions><execution><phase>generate-sources</phase><id>javacc</id><goals><goal>javacc</goal></goals><configuration><sourceDirectory>${project.build.directory}/generated-sources/</sourceDirectory><includes><include>**/Simple1.jj</include></includes><!-- This must be kept synced with Apache Calcite. --><lookAhead>1</lookAhead><isStatic>false</isStatic><outputDirectory>${project.build.directory}/generated-sources/</outputDirectory></configuration></execution></executions>
</plugin>�� compile ֮�ͻ��� generated-sources �����ɴ��룺
8
Ȼ��Ѵ��� copy �� Sources ·���£�
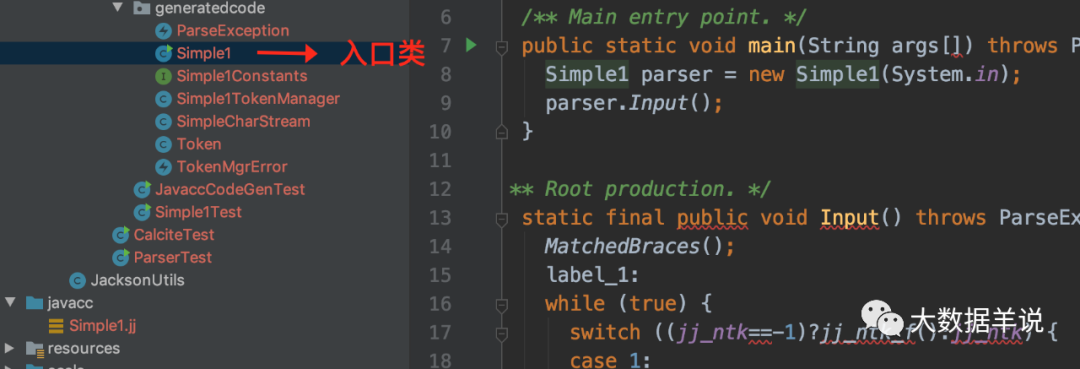
33
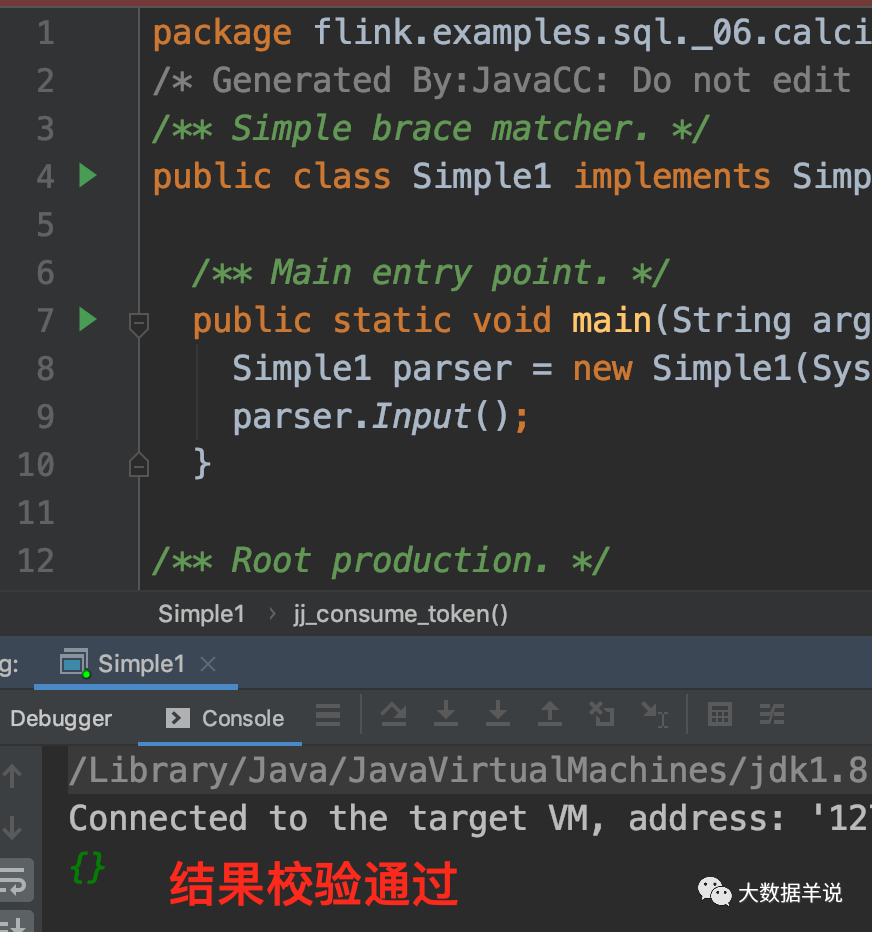
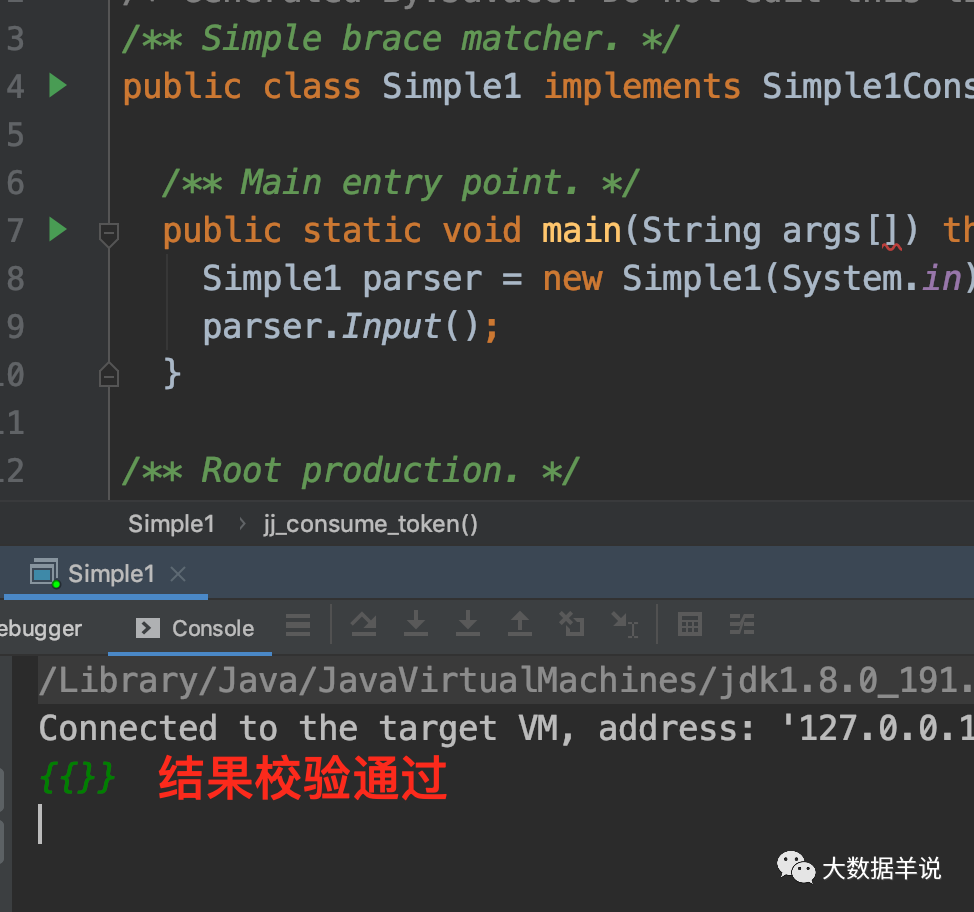
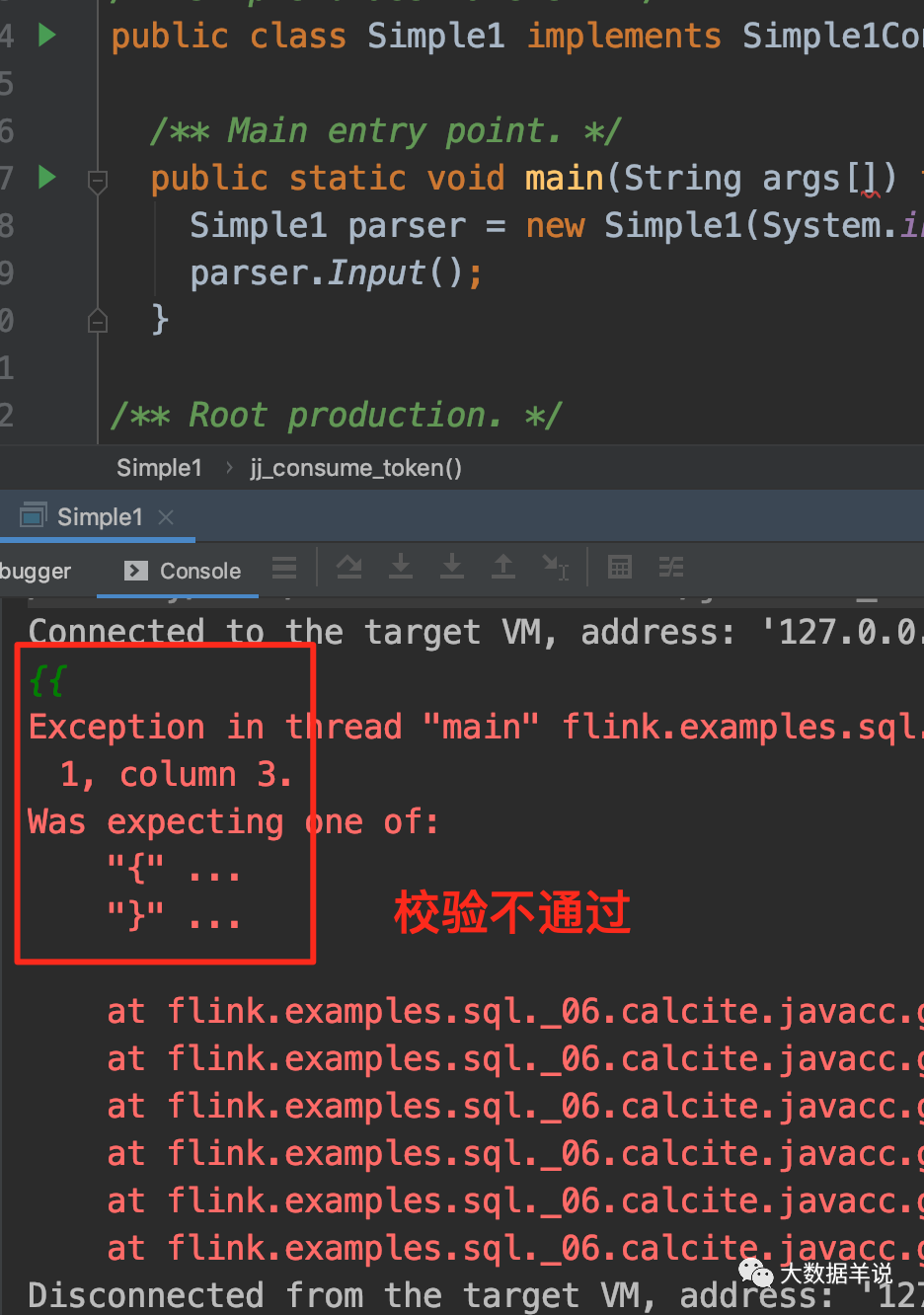
ִ���´��룬���Կ��� {}��{
{}} ������У��ͨ����һ�����ֲ����Ϲ���� {
{
���룬�ͻ��׳��쳣��
���� javacc �����Ͼ��˽������ˡ�
����Ȥ�Ŀ��Գ����Զ���һ����������
4.5.3.fmpp ��ɶ��
5
fmpp ����һ������ freemarker ��ģ�����������û�����ͳһ�����Լ��ı�����Ȼ���� ftl ģ�� + ���� ���ɶ�Ӧ�������ļ����� calcite ��ʹ�� fmpp ��Ϊ���� + ģ���ͳһ��������Ȼ����� fmpp �����ɶ�Ӧ�� Parser.jj �ļ���
5.ԭ������ƪ-calcite �� flink sql �д�չ����
��������һ��ͼ��������������Ҫ���֮���������ϵ��
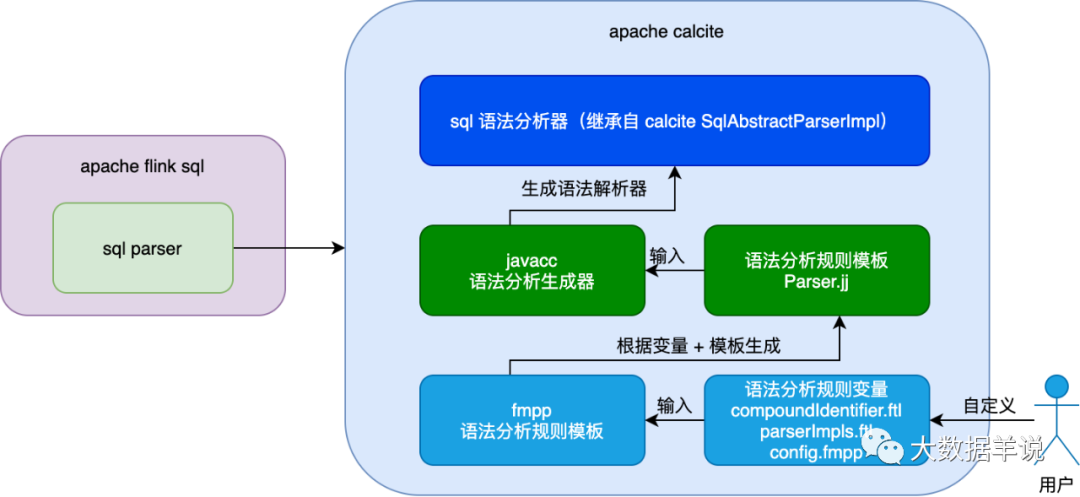
3
��û�´�������������Щ���̣�fmpp��Parser.jj ģ�����ɣ� -> javacc��Parser ���ɣ� -> calcite��
�ڽ��� Parser ��������֮ǰ���ȿ��� flink �������ɵ� Parser��FlinkSqlParserImpl ���˴�ʹ�� Blink Planner����
5.1.FlinkSqlParserImpl
�������������������������� flink 1.13.1 �汾����
public class ParserTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(10);EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);DataStream<Tuple3<String, Long, Long>> tuple3DataStream =env.fromCollection(Arrays.asList(Tuple3.of("2", 1L, 1627254000000L),Tuple3.of("2", 1L, 1627218000000L + 5000L),Tuple3.of("2", 101L, 1627218000000L + 6000L),Tuple3.of("2", 201L, 1627218000000L + 7000L),Tuple3.of("2", 301L, 1627218000000L + 7000L),Tuple3.of("2", 301L, 1627218000000L + 7000L),Tuple3.of("2", 301L, 1627218000000L + 7000L),Tuple3.of("2", 301L, 1627218000000L + 7000L),Tuple3.of("2", 301L, 1627218000000L + 7000L),Tuple3.of("2", 301L, 1627218000000L + 86400000 + 7000L))).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple3<String, Long, Long>>(Time.seconds(0L)) {@Overridepublic long extractTimestamp(Tuple3<String, Long, Long> element) {return element.f2;}});tEnv.registerFunction("mod", new Mod_UDF());tEnv.registerFunction("status_mapper", new StatusMapper_UDF());tEnv.createTemporaryView("source_db.source_table", tuple3DataStream,"status, id, timestamp, rowtime.rowtime");String sql = "SELECT\n"+ " count(1),\n"+ " cast(tumble_start(rowtime, INTERVAL '1' DAY) as string)\n"+ "FROM\n"+ " source_db.source_table\n"+ "GROUP BY\n"+ " tumble(rowtime, INTERVAL '1' DAY)";Table result = tEnv.sqlQuery(sql);tEnv.toAppendStream(result, Row.class).print();env.execute();}}debug ������֮ǰ���� sql -> SqlNode ������ʾ������ͼֱ�Ӷ�λ�� SqlParser��
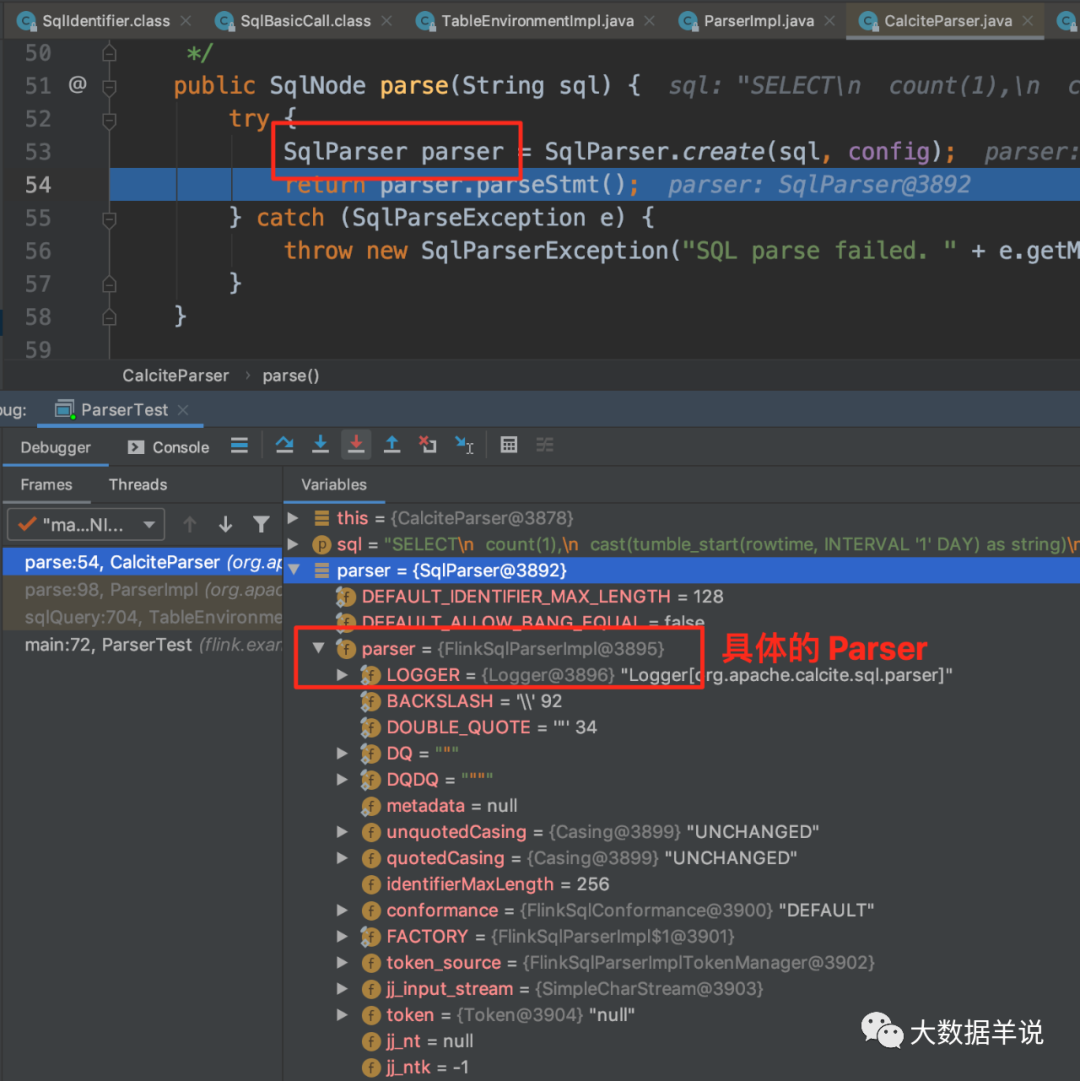
21
����ͼ���Կ�������� Parser ���� FlinkSqlParserImpl��
��λ������Ĵ�������ͼ��ʾ��flink-table-palnner-blink-2.11-1.13.1.jar����
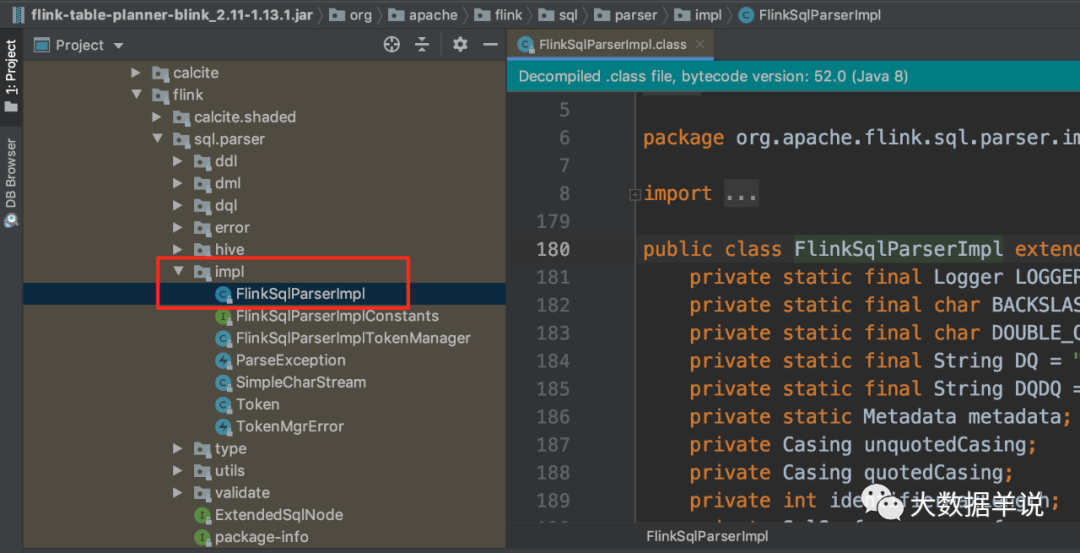
34
���� parse �Ľ�� SqlNode ����ͼ��
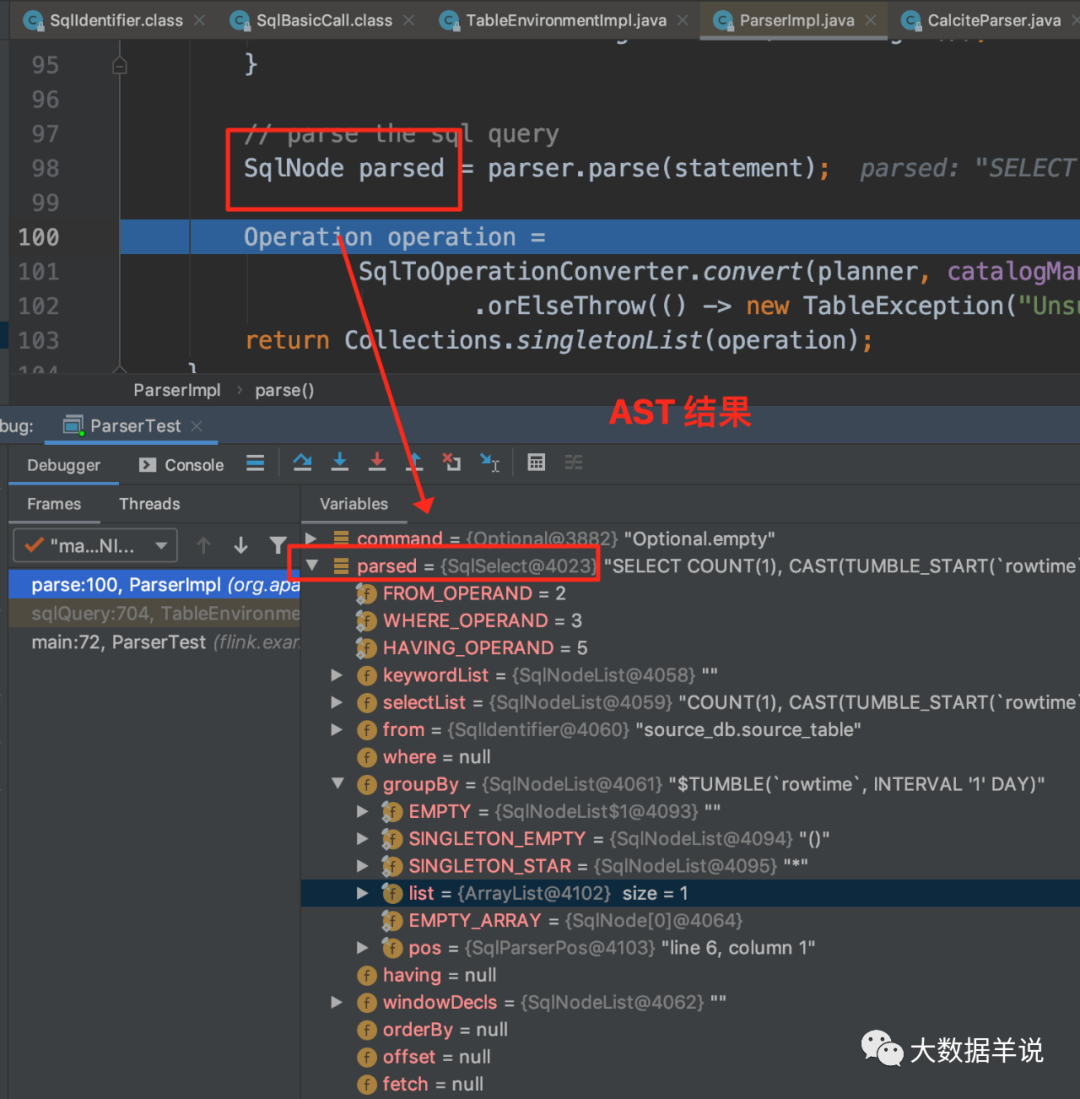
22
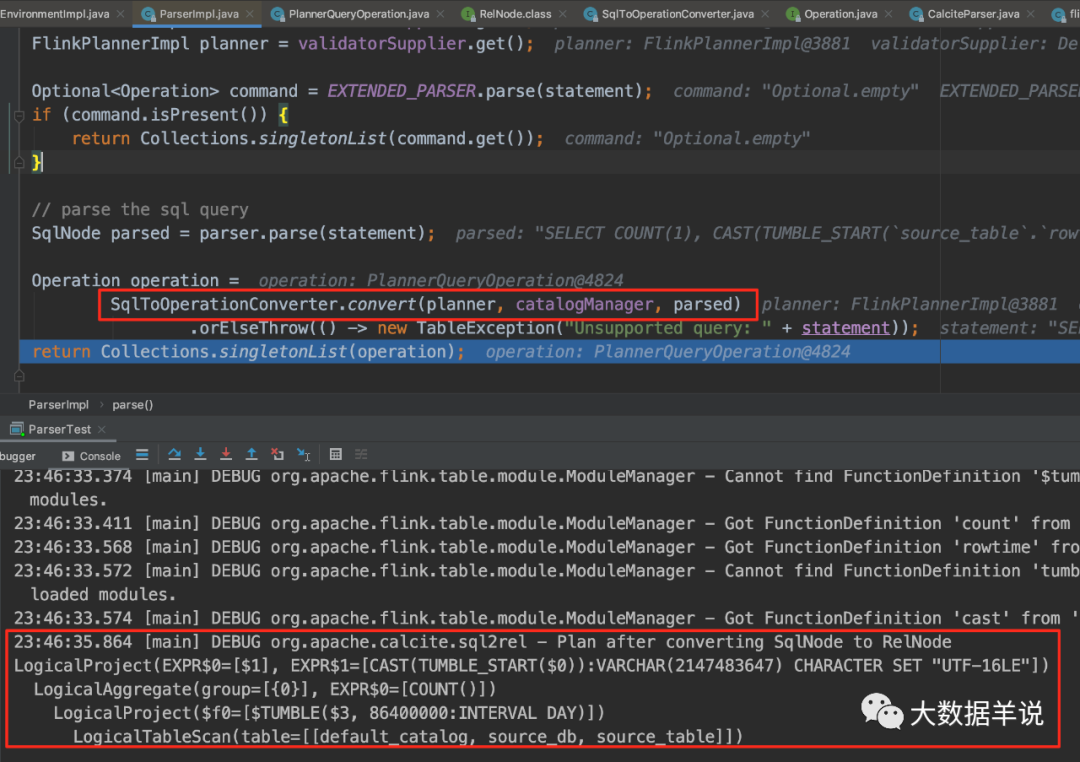
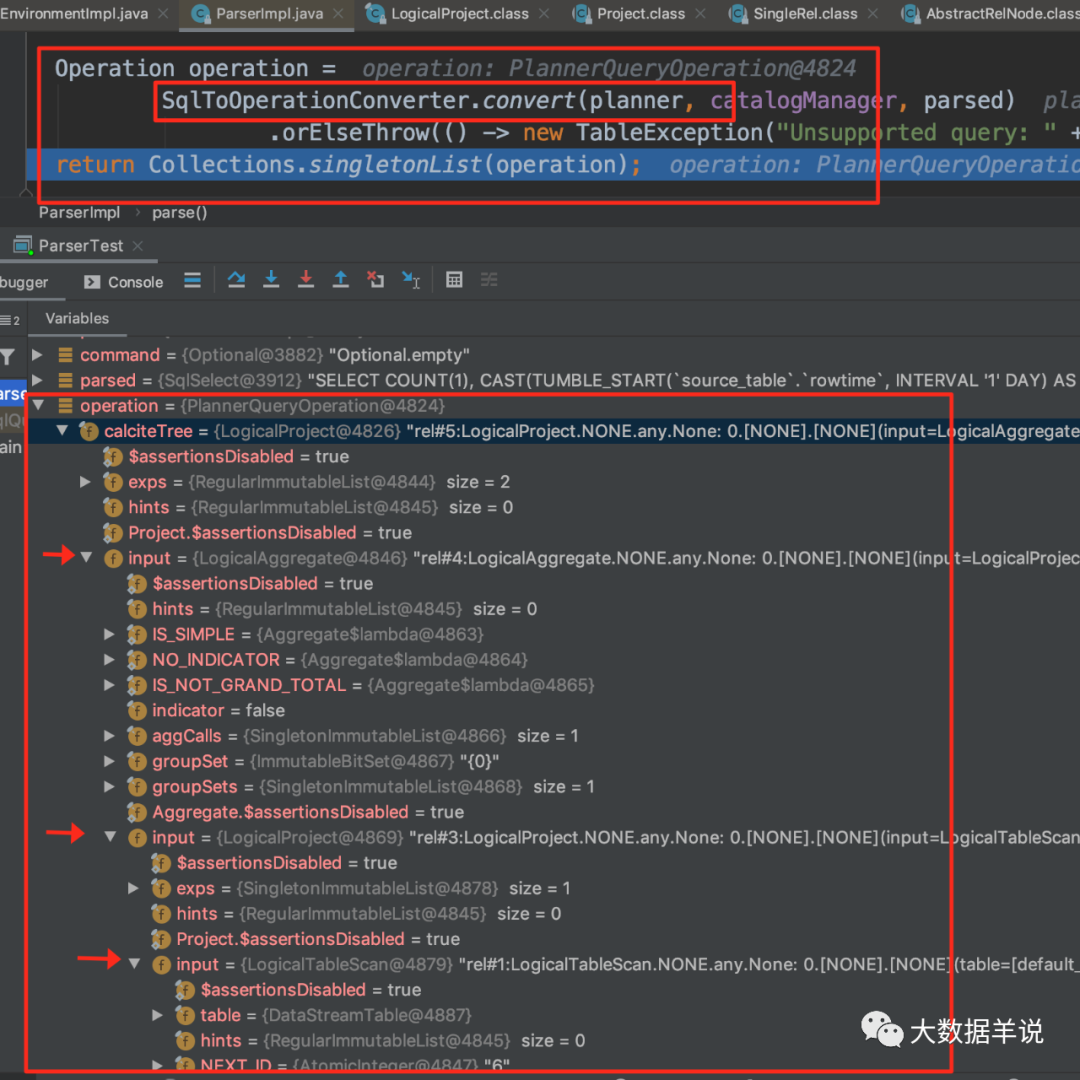
�������� FlinkSqlParserImpl ����ôʹ�� calcite ���ɵġ�
���嵽 flink �е�ʵ�֣�λ��Դ���е� flink-table.flink-sql-parser ģ�飨Դ����� flink 1.13.1����
flink ������ maven ���ʵ�ֵ�������������̡�
5.2.FlinkSqlParserImpl ������
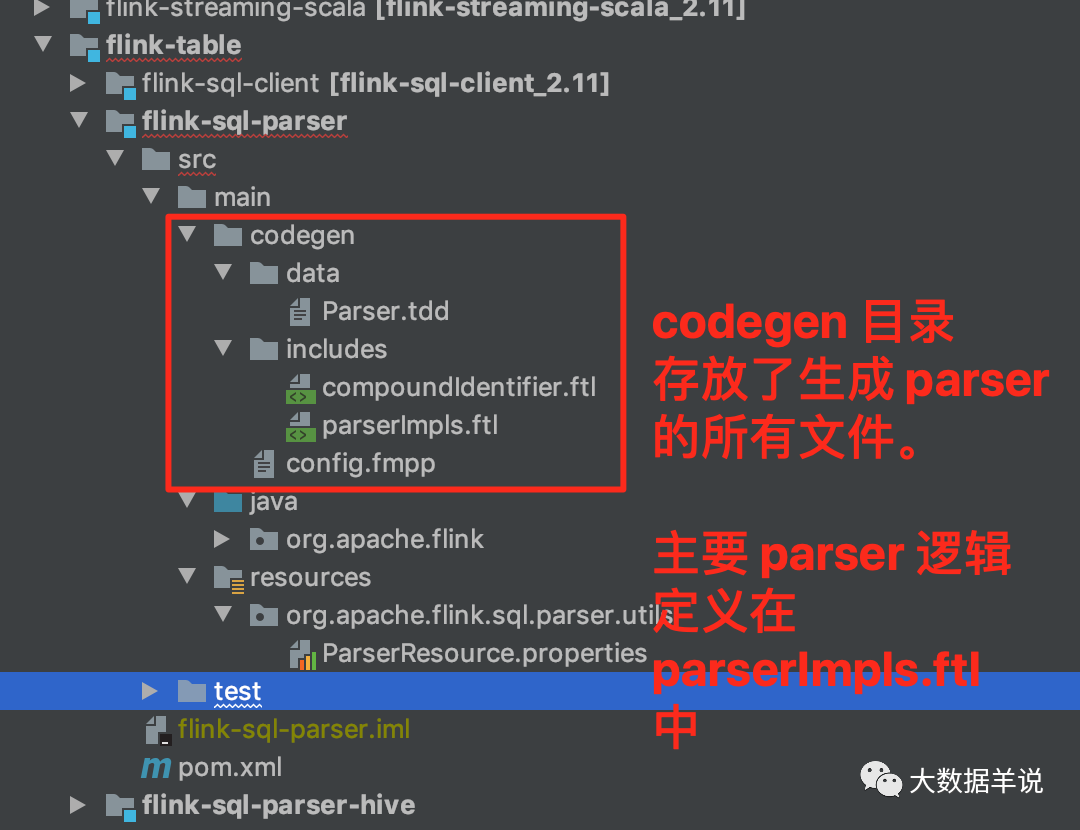
14
�������������� Parser �������̡�
5.2.1.flink ���� calcite
ʹ�� maven-dependency-plugin �� calcite ��ѹ�� flink ��Ŀ build Ŀ¼�¡�
<plugin><!-- Extract parser grammar template from calcite-core.jar and putit under ${project.build.directory} where all freemarker templates are. --><groupId>org.apache.maven.plugins</groupId><artifactId>maven-dependency-plugin</artifactId><executions><execution><id>unpack-parser-template</id><phase>initialize</phase><goals><goal>unpack</goal></goals><configuration><artifactItems><artifactItem><groupId>org.apache.calcite</groupId><artifactId>calcite-core</artifactId><type>jar</type><overWrite>true</overWrite><outputDirectory>${project.build.directory}/</outputDirectory><includes>**/Parser.jj</includes></artifactItem></artifactItems></configuration></execution></executions>
</plugin>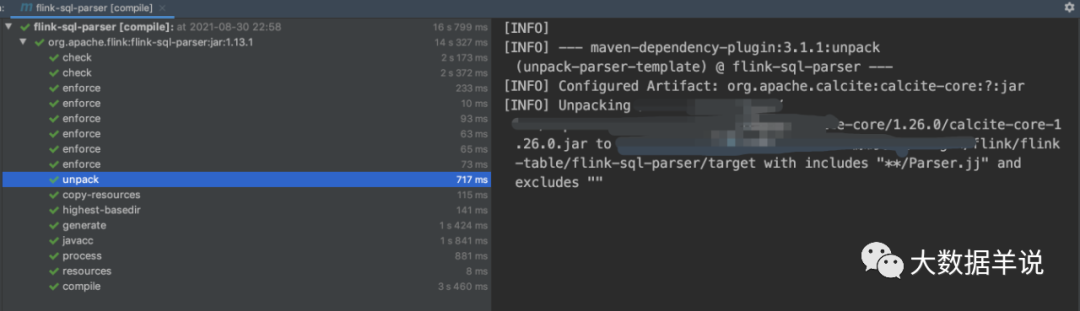
15
5.2.2.fmpp ���� Parser.jj
ʹ�� maven-resources-plugin �� Parser.jj �������ɡ�
<plugin><artifactId>maven-resources-plugin</artifactId><executions><execution><id>copy-fmpp-resources</id><phase>initialize</phase><goals><goal>copy-resources</goal></goals><configuration><outputDirectory>${project.build.directory}/codegen</outputDirectory><resources><resource><directory>src/main/codegen</directory><filtering>false</filtering></resource></resources></configuration></execution></executions>
</plugin>
<plugin><groupId>com.googlecode.fmpp-maven-plugin</groupId><artifactId>fmpp-maven-plugin</artifactId><version>1.0</version><dependencies><dependency><groupId>org.freemarker</groupId><artifactId>freemarker</artifactId><version>2.3.28</version></dependency></dependencies><executions><execution><id>generate-fmpp-sources</id><phase>generate-sources</phase><goals><goal>generate</goal></goals><configuration><cfgFile>${project.build.directory}/codegen/config.fmpp</cfgFile><outputDirectory>target/generated-sources</outputDirectory><templateDirectory>${project.build.directory}/codegen/templates</templateDirectory></configuration></execution></executions>
</plugin>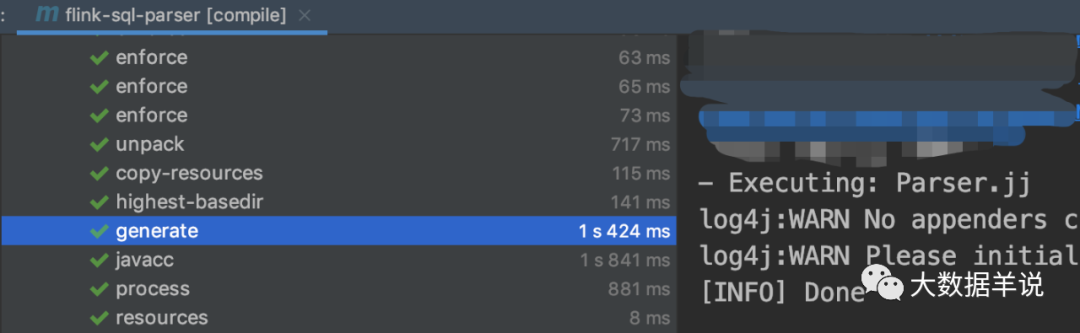
16
5.2.3.javacc ���� parser
ʹ�� javacc ������ Parser.jj �ļ����� Parser��
<plugin><!-- This must be run AFTER the fmpp-maven-plugin --><groupId>org.codehaus.mojo</groupId><artifactId>javacc-maven-plugin</artifactId><version>2.4</version><executions><execution><phase>generate-sources</phase><id>javacc</id><goals><goal>javacc</goal></goals><configuration><sourceDirectory>${project.build.directory}/generated-sources/</sourceDirectory><includes><include>**/Parser.jj</include></includes><!-- This must be kept synced with Apache Calcite. --><lookAhead>1</lookAhead><isStatic>false</isStatic><outputDirectory>${project.build.directory}/generated-sources/</outputDirectory></configuration></execution></executions>
</plugin>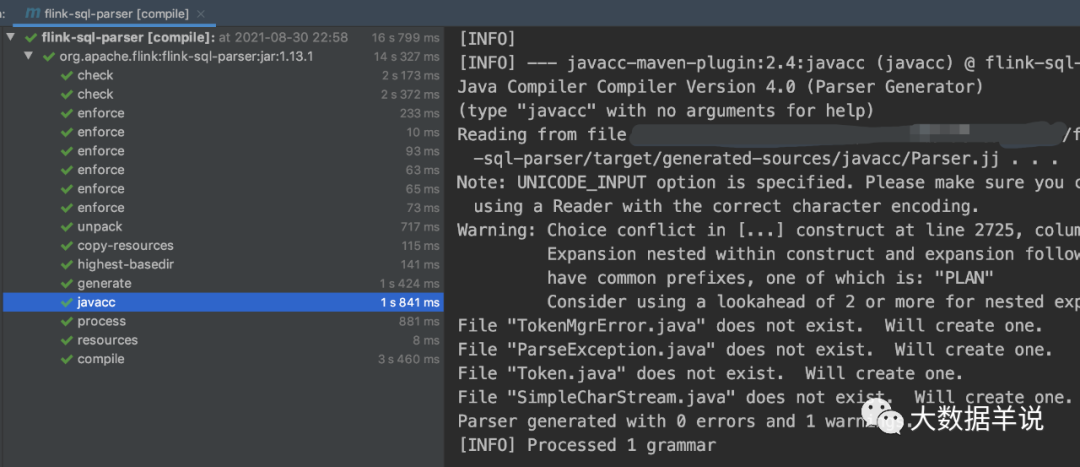
17
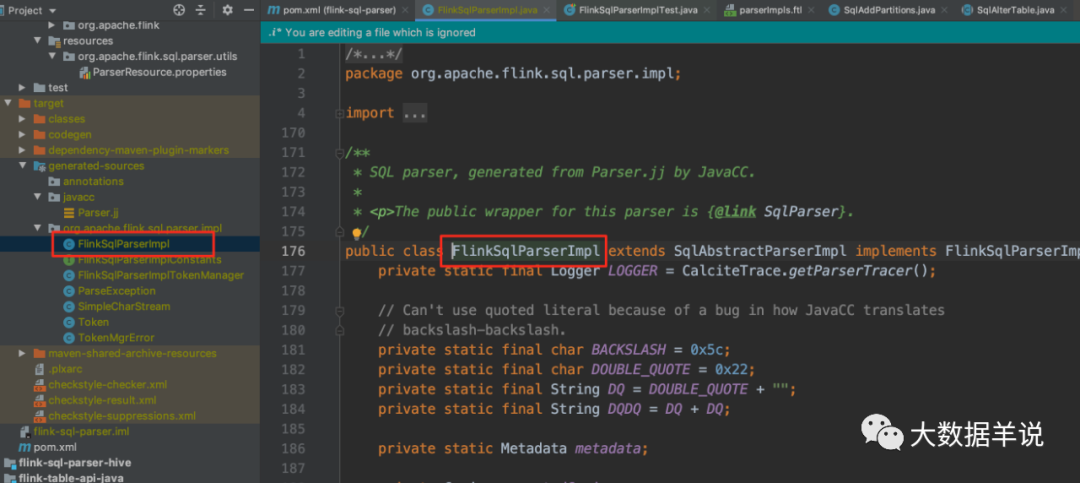
5.2.4.���� Parser
�������ɵ� Parser ���� FlinkSqlParserImpl��
18
5.2.5.blink planner ���� flink-sql-parser
blink planner��flink-table-planner-blink�� �ڴ��ʱ�� flink-sql-parser��flink-sql-parser-hive �����ȥ��
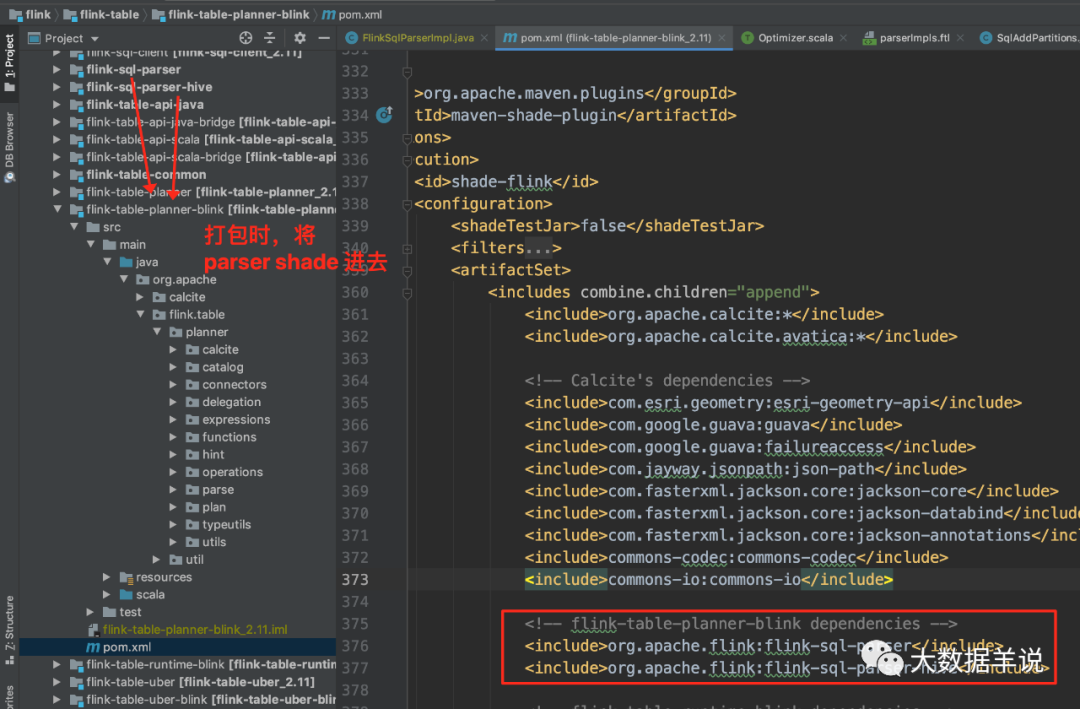
35
6.�ܽ���չ��ƪ
������Ҫ������ flink sql �� calcite ֮���������ϵ���Լ� flink sql parser �����ɹ��̡�������ö������� flink sql �����а�������æ���С���ģ���ע + ���� + �ٿ��������ɡ�
7.�����
https://www.slideshare.net/JordanHalterman/introduction-to-apache-calcite
https://arxiv.org/pdf/1802.10233.pdf
https://changbo.tech/blog/7dec2e4.html
http://www.liaojiayi.com/calcite/
https://www.zhihu.com/column/c_1110245426124554240
https://blog.csdn.net/QuinnNorris/article/details/70739094
https://www.pianshen.com/article/72171186489/
https://matt33.com/2019/03/07/apache-calcite-process-flow/
https://www.jianshu.com/p/edf503a2a1e7
https://blog.csdn.net/u013007900/article/details/78978271
https://blog.csdn.net/u013007900/article/details/78993101
http://www.ptbird.cn/optimization-of-relational-algebraic-expression.html
https://book.51cto.com/art/201306/400084.htm
https://book.51cto.com/art/201306/400085.htm
https://miaowenting.site/2019/11/10/Flink-SQL-with-Calcite/

��������˵
��������������������ĸ���~
32ƪԭ������
���ں�
�����Ƽ�
[
flink sql ֪������Ȼ���壩| �Զ��� protobuf format
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488994&idx=1&sn=20236350b1c8cfc4ec5055687b35603d&chksm=c154991af623100c46c0ed224a8264be08235ab30c9f191df7400e69a8ee873a3b74859fb0b7&scene=21#wechat_redirect)
[
flink sql ֪������Ȼ���ģ�| sql api ����ϵͳ
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488788&idx=1&sn=0127fd4037788762a0401313b43b0ea5&chksm=c15499ecf62310fa747c530f722e631570a1b0469af2a693e9f48d3a660aa2c15e610653fe8c&scene=21#wechat_redirect)
[
flink sql ֪������Ȼ������| �Զ��� redis ���ݻ������Դ�룩
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488720&idx=1&sn=5695e3691b55a7e40814d0e455dbe92a&chksm=c1549828f623113e9959a382f98dc9033997dd4bdcb127f9fb2fbea046545b527233d4c3510e&scene=21#wechat_redirect)
[
flink sql ֪������Ȼ������| �Զ��� redis ����ά������Դ�룩
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488635&idx=1&sn=41817a078ef456fb036e94072b2383ff&chksm=c1549883f623119559c47047c6d2a9540531e0e6f0b58b155ef9da17e37e32a9c486fe50f8e3&scene=21#wechat_redirect)
[
flink sql ֪������Ȼ��һ��| source\sink ԭ��
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488486&idx=1&sn=b9bdb56e44631145c8cc6354a093e7c0&chksm=c1549f1ef623160834e3c5661c155ec421699fc18c57f2c63ba14d33bab1d37c5930fdce016b&scene=21#wechat_redirect)
���� Flink ʵʱ�����ݷ�����ؼ������ģ���Ƶ����̨�ظ� ��flink�� ���� ��flink sql�� ��ȡ��
�����+�ڿ�����л���Ŀ϶� ?