目录
1、定义
1.1、约定
1.2、贪心算法+切分定理
2、加权无向图的数据类型
2.1、Edge类
2.2、EdgeWeightedGraph
3、最小生成树--Prim算法
3.1、Prim算法--方式一
3.2、Prim算法---方法二
4、最小生成树算法---Kruskal算法
1、定义
加权图是一种为每条边关联一个权值或是成本的图模型。
一幅加权图的最小生成树(MST) 是树中所有边的权值之和最小 的生成树。
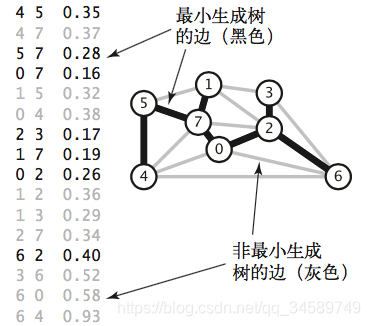
1.1、约定
在计算图的最小生成树的过程中,因为图的多种特殊情况,比如负的权值,不连通的情况,会让我们去做多余的处理,为了我们更好的理解最小生成树的算法, 我们做了下面的约定:
- 只考虑连通图。如果一幅图是非连通的, 我们只能使用这个算法来计算它的所有连通分量的最小生成树,合并在一起称其为最小生成 森林。
- 边的权重不一定表示距离
- 边的权重可能是 0 或者负数。
- 所有边的权重都各不相同。如果不同边的权重可 以相同,最小生成树就不一定唯一了。
1.2、贪心算法+切分定理
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
而我们图的最小生成树算法就是利用了贪心算法的原理,我们只要把图中连接每个点的最小权值的边找出来,然后并让他们连成一棵树,并且不能出现环或者多棵树我们就算完成了。
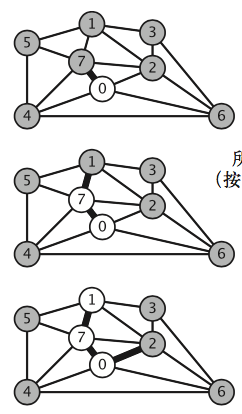
而切分定理就是在贪心算法的基础上,从起点s出发,把起点s和其他点分成两部分,然后找出起点s和另外一部分连接的最短路径(也叫横切边)。现在就是两个点,然后找出另外的部分连接这两个点的最短路径(横切边)连成三个点,这样不断持续下去,就能生成我们的最小生成树。
切分定理:图的一种切分是将图的所有顶点分为两个非空且不重叠的两个集合。横切边是一条连接 两个属于不同集合的顶点的边。
2、加权无向图的数据类型
这里我们求的加权无向图的最小生成树,我们首先要表示出加权无向图的数据类型, 然后我们才能做下一步的计算。
Edge类来存储边、边的权值、边的两个顶点。
EdgeWeightedGraph 类 中有一个 数据链表,数组用来存储每个顶点,链表用来存储每个顶点相连的边。
2.1、Edge类
public class Edge implements Comparable<Edge> {private final int v;private final int w;private final double weight;public Edge(int v, int w, int weight) {this.v = v;this.w = w;this.weight = weight;}public double weight() {return weight;}public int either() {return v;}public int other(int vertex){if (vertex==v) return w;else if (vertex==w) return v;else return 0; //这里应该抛出异常}@Overridepublic int compareTo(Edge that) {if (this.weight>that.weight) return 1;else if (this.weight<that.weight) return -1;else return 0;}
}2.2、EdgeWeightedGraph
public class EdgeWeightedGraph {private int V;private int E;private Bag<Edge>[] adj;public EdgeWeightedGraph(int v) {V = v;adj = new Bag[v];for (int i = 0; i < v; i++) {adj[i] = new Bag<>();}}private void addEdge(Edge e) {int v = e.either();int w = e.other(v);adj[v].add(e);adj[w].add(e);E++;}public int V() {return V;}public int E() {return E;}public Iterable<Edge> adj(int v) {return adj[v];}public Iterable<Edge> edges() {Bag<Edge> edges = new Bag<>();for (int v = 0; v < V; v++) {for (Edge w : adj(v)) {if (w.other(v) > v) { //因为每条边会被存储两次,这个判断是为了筛选出一次edges.add(w);}}}return edges;}
}3、最小生成树--Prim算法
Prim算法就是在贪心算法的基础上,从起点s出发,把起点s和其他点分成两部分,然后找出起点s和另外一部分连接的最短路径(也叫横切边)。现在就是两个点,然后找出另外的部分连接这两个点的最短路径(横切边)连成三个点,这样不断持续下去,就能生成我们的最小生成树。
每次连接都会给树添加一条边,知道图中的所有顶点都被连接到树中。
3.1、Prim算法--方式一
思路就是把所有边都添加到一个优先队列中,然后每次从队列中拿一条权值最小的边,判断该边的两个顶点是否都连入了树中,没有的话就把该边连入到树中。直到所有的顶点连接到树上。
该Prim 算法计算一幅含有 V 个顶点和 E 条边的连通加权无向图的最小生成树 所需的空间与 E 成正比,所需的时间与 ElogE 成正比(最坏情况)。
public class LazyPrimMST {private boolean[] marked; //判断是否已经走过该点private Queue<Edge> mst; //存储最小生成树的边private MinPQ<Edge> pq; //优先队列,每次从队列中取出最短的边public LazyPrimMST(EdgeWeightedGraph G) {marked = new boolean[G.V()];mst=new Queue<>();pq = new MinPQ<>();visit(G,0);while (!pq.isEmpty()){Edge e=pq.delMin(); //取出最短的边int v=e.either();int w=e.other(v);if (marked[v]&&marked[w]) continue;//如果边的两个顶点走过了就进行下一次循环mst.enqueue(e);if (!marked[v]) visit(G,v); //将没有放入优先队列的边添加进去if (!marked[w]) visit(G,w);}}private void visit(EdgeWeightedGraph G, int v) {marked[v] = true;for (Edge e : G.adj(v)) {if (!marked[e.other(v)]) {pq.insert(e);}}}private Iterable<Edge> mst() {return mst;}
}3.2、Prim算法---方法二
方法二的思路 是从起点s出发,将从s到w点的边 s--->w 标记为最短路径的边,并存入数组中,当我们在遍历其他点 v时,v点也能通往w,且边v--->w比 边s--->w短, 那么我们就将数组中通往w的边替换成v--w。
不断重复,这样数组中存放就是通往每个点的最短的边了,因为这些边能通往每个顶点,那么他们必然也能练成一棵树,通往起点0是没有边的。
该Prim 算法的即计算一幅含有 V 个顶点和 E 条边的连通加权无向图的最小生成树所需的空间和 V 成正比,所需的时间和 ElogV 成正比(最坏情况)。
public class PrimMST {private boolean[] marked; //判断是否走过该点private Edge[] edgeTo; //存放最小生成树的边private double[] distTo; //存放每天边的权重private IndexMinPQ<Double> pq; //索引优先队列,可以通过索引来更改存储的值public PrimMST(EdgeWeightedGraph G) {marked = new boolean[G.V()];edgeTo = new Edge[G.V()]; //顶点数量和最小生成树边的数量一致distTo = new double[G.V()]; pq = new IndexMinPQ<>(G.V());for (int i = 0; i < G.V(); i++) { //1、先讲每条边的权值设置为无穷大 distTo[i] = Double.POSITIVE_INFINITY;}distTo[0] = 0.0; //2、起点0 的权值为0 ,并将起点0加入到优先队列中pq.insert(0, 0.0);while (!pq.isEmpty()) { //3、每次从队列中取出最短的边,并返回边 v-->w 的顶点wvisit(G, pq.delMin());}}private void visit(EdgeWeightedGraph G, int v) {marked[v] = true; //4、标记走过了该点for (Edge e : G.adj(v)) { //5、遍历该点的所有邻边int w = e.other(v);if (marked[w])continue;if (e.weight() < distTo[w]) { //6、如果该边 v-->w 的权值,比前面加入通往w的边的权值小,则替换 edgeTo[w] = e;distTo[w] = e.weight();if (pq.contains(w)) //7、如果优先队列已经存了通往w的边,但不是最短的,则替换pq.change(w, distTo[w]);elsepq.insert(w, distTo[w]);}}}public Iterable<Edge> edges() {Queue<Edge> mst = new Queue<>();for (int v = 0; v < this.edgeTo.length; ++v) {Edge e = this.edgeTo[v];if (e != null) {mst.enqueue(e);}}return mst;}public double weight() {double weight = 0.0;for (Edge e : edges())weight += e.weight();return weight;}
}
4、最小生成树算法---Kruskal算法
Prim算法的思想是从一个顶点出发不断地长大成一棵树。而Kruskal算法的思想是从无数颗小树不断合并成一棵大树。
Kruskal算法的思想是将每条边都加入优先队列中,然后每次拿出最小的边,作为最小生成树的一条边,然后再从中拿出另一条最短的边,并且这条边不会和最小生成树数组中的边构成环,如果构成环就跳过该条边,从下一条最短边开始。这样就会从无数条短边开始,不断合成一棵树。
Kruskal 算法的计算一幅含有 V 个顶点和 E 条边的连通加权无向图的最小生成 树所需的空间和 E 成正比,所需的时间和 ElogE 成正比(最坏情况)。
public class KruskalMST {private static final double FLOATING_POINT_EPSILON = 1.0E-12D;private double weight;private final Queue<Edge> mst = new Queue<>();public KruskalMST(EdgeWeightedGraph G) {MinPQ<Edge> pq = new MinPQ<>();for (Edge e : G.edges()) {pq.insert(e);}UF uf = new UF(G.V());while (!pq.isEmpty() && this.mst.size() < G.V() - 1) {Edge e = (Edge) pq.delMin();int v = e.either();int w = e.other(v);if (uf.find(v) != uf.find(w)) {uf.union(v, w);this.mst.enqueue(e);this.weight += e.weight();}}}public Iterable<Edge> edges() {return this.mst;}public double weight() {return this.weight;}
}