ΦρΫι
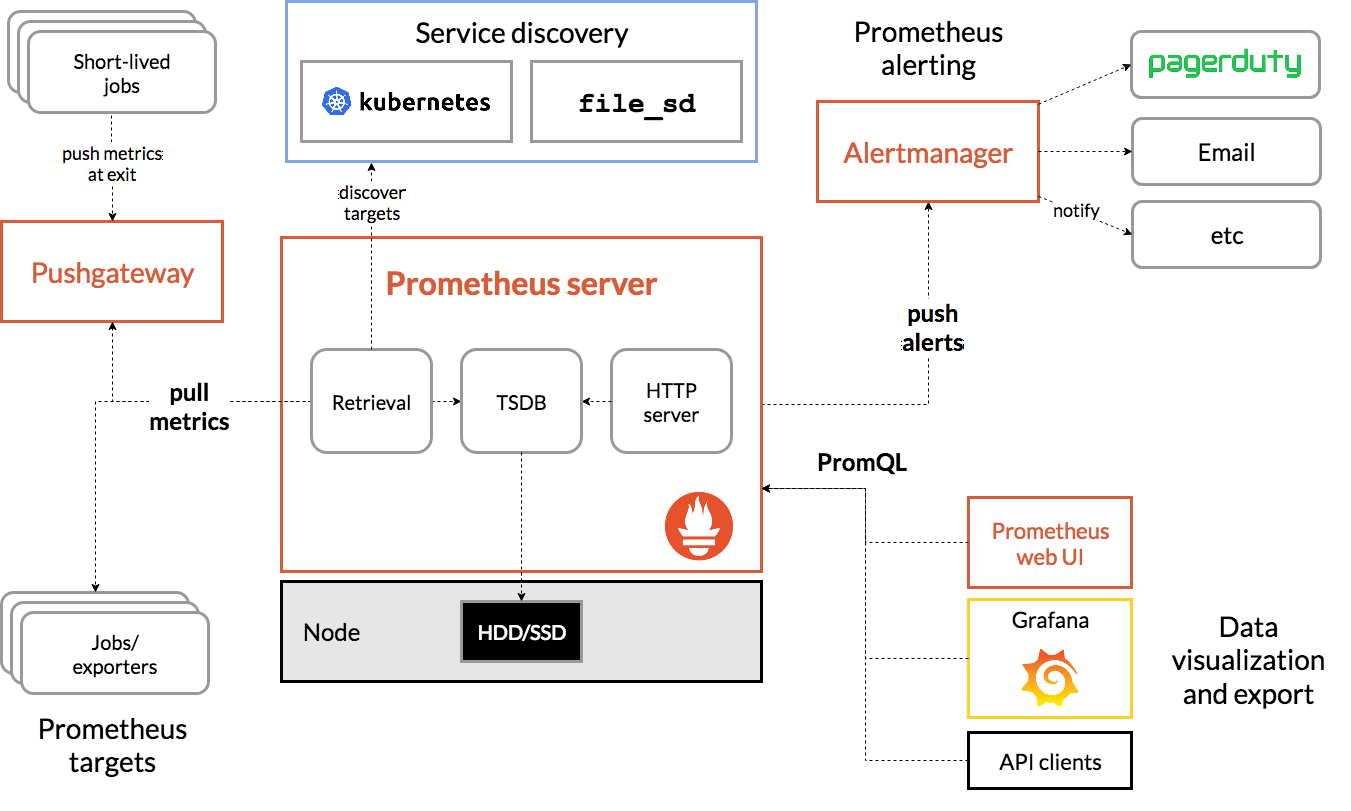
÷°«ΑΈ“Ο«―ßœΑ Prometheus ΒΡ ±ΚρΨΆΝΥΫβΒΫ Prometheus ΑϋΚ§“ΜΗω±®Ψ·ΡΘΩιΘ§ΨΆ «Έ“Ο«ΒΡ AlertManagerΘ§Alertmanager ÷ς“Σ”Ο”ΎΫ” ’ Prometheus ΖΔΥΆΒΡΗφΨ·–≈œΔΘ§Υϋ÷ß≥÷ΖαΗΜΒΡΗφΨ·Ά®÷Σ«ΰΒάΘ§Εχ«“Κή»ί“ΉΉωΒΫΗφΨ·–≈œΔΫχ––»Ξ÷ΊΘ§ΫΒ‘κΘ§Ζ÷ΉιΒ»Θ§ «“ΜΩν«ΑΈάΒΡΗφΨ·Ά®÷ΣœΒΆ≥ΓΘ
ΦήΙΙ
Ϋ”œ¬ά¥Έ“Ο«ΨΆά¥―ßœΑœ¬ AlertManager ΒΡΨΏΧε Ι”ΟΖΫΖ®ΓΘ
Ά®Ιΐ‘Ύ Prometheus ÷–Ε®“εΗφΨ·Ιφ‘ρΘ§Prometheus Μα÷ήΤΎ–‘ΒΡΕ‘ΗφΨ·Ιφ‘ρΫχ––ΦΤΥψΘ§»γΙϊ¬ζΉψΗφΨ·¥ΞΖΔΧθΦΰΨΆΜαœρ Alertmanager ΖΔΥΆΗφΨ·–≈œΔΓΘ
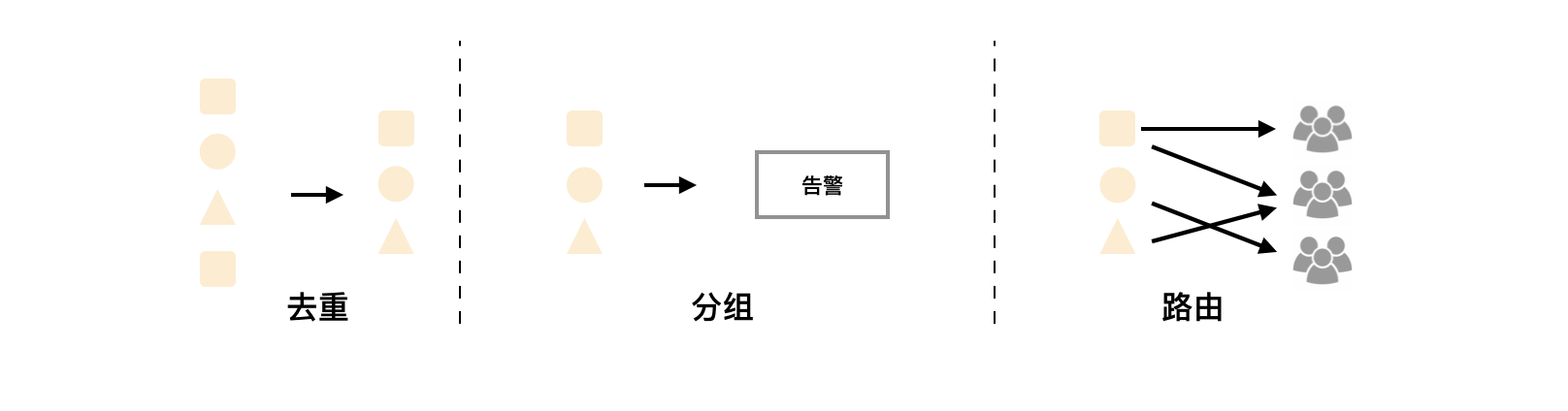
‘Ύ Prometheus ÷–“ΜΧθΗφΨ·Ιφ‘ρ÷ς“Σ”…“‘œ¬ΦΗ≤ΩΖ÷Ήι≥…ΘΚ
- ΗφΨ·Οϊ≥ΤΘΚ”ΟΜß–η“ΣΈΣΗφΨ·Ιφ‘ρΟϋΟϊΘ§Β±»ΜΕ‘”ΎΟϋΟϊΕχ―‘Θ§–η“ΣΡήΙΜ÷±Ϋ”±μ¥ο≥ωΗΟΗφΨ·ΒΡ÷ς“ΣΡΎ»ί
- ΗφΨ·Ιφ‘ρΘΚΗφΨ·Ιφ‘ρ ΒΦ …œ÷ς“Σ”…
PromQLΫχ––Ε®“εΘ§Τδ ΒΦ “β“ε «Β±±μ¥ο ΫΘ®PromQLΘ©≤ι―·ΫαΙϊ≥÷–χΕύ≥Λ ±ΦδΘ®DuringΘ©Κσ¥ΞΖΔΗφΨ·
‘Ύ Prometheus ÷–Θ§ΜΙΩ…“‘Ά®Ιΐ GroupΘ®ΗφΨ·ΉιΘ©Ε‘“ΜΉιœύΙΊΒΡΗφΨ·Ϋχ––Ά≥“ΜΕ®“εΓΘAlertmanager ΉςΈΣ“ΜΗωΕάΝΔΒΡΉιΦΰΘ§ΗΚ‘πΫ” ’≤Δ¥Πάμά¥Ή‘ Prometheus Server ΒΡΗφΨ·–≈œΔΓΘAlertmanager Ω…“‘Ε‘’β–©ΗφΨ·–≈œΔΫχ––Ϋχ“Μ≤ΫΒΡ¥ΠάμΘ§±»»γΒ±Ϋ” ’ΒΫ¥σΝΩ÷ΊΗ¥ΗφΨ· ±ΡήΙΜœϊ≥ΐ÷ΊΗ¥ΒΡΗφΨ·–≈œΔΘ§Ά§ ±Ε‘ΗφΨ·–≈œΔΫχ––Ζ÷Ήι≤Δ«“¬Ζ”…ΒΫ’ΐ»ΖΒΡΆ®÷ΣΖΫΘ§Prometheus ΡΎ÷ΟΝΥΕ‘” ΦΰΓΔSlack Εύ÷÷Ά®÷ΣΖΫ ΫΒΡ÷ß≥÷Θ§Ά§ ±ΜΙ÷ß≥÷”κ Webhook ΒΡΦ·≥…Θ§“‘÷ß≥÷ΗϋΕύΕ®÷ΤΜ·ΒΡ≥ΓΨΑΓΘάΐ»γΘ§ΡΩ«Α Alertmanager ΜΙ≤Μ÷ß≥÷ΕΛΕΛΘ§”ΟΜßΆξ»ΪΩ…“‘Ά®Ιΐ Webhook ”κΕΛΕΛΜζΤς»ΥΫχ––Φ·≥…Θ§¥”ΕχΆ®ΙΐΕΛΕΛΫ” ’ΗφΨ·–≈œΔΓΘΆ§ ± AlertManager ΜΙΧαΙ©ΝΥΨ≤Ρ§ΚΆΗφΨ·“÷÷ΤΜζ÷Τά¥Ε‘ΗφΨ·Ά®÷Σ––ΈΣΫχ––”≈Μ·ΓΘ
Α≤ΉΑ
¥”ΙΌΖΫΈΡΒΒConfiguration | Prometheus÷–Έ“Ο«Ω…“‘Ω¥ΒΫœ¬‘ΊAlertManagerΕΰΫχ÷ΤΈΡΦΰΚσΘ§Ω…“‘Ά®Ιΐœ¬ΟφΒΡΟϋΝν‘Υ––ΘΚ
$ ./alertmanager --config.file=simple.yml- name: alertmanagerimage: prom/alertmanager:v0.14.0imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/alertmanager.yml"
Τδ÷–-config.file≤Έ ΐ «”Οά¥÷ΗΕ®Ε‘”ΠΒΡ≈δ÷ΟΈΡΦΰΒΡΘ§”…”ΎΈ“Ο«’βάοΆ§―υ“Σ‘Υ––ΒΫ Kubernetes Φ·»Κ÷–ά¥Θ§Υυ“‘Έ“Ο« Ι”ΟdockerΨΒœώΒΡΖΫ Ϋά¥Α≤ΉΑΘ§ Ι”ΟΒΡΨΒœώ «ΘΚprom/alertmanager:v0.15.3ΓΘ
Ήœ»Θ§÷ΗΕ®≈δ÷ΟΈΡΦΰΘ§Ά§―υΒΡΘ§Έ“Ο«’βάο Ι”Ο“ΜΗω ConfigMap Ή ‘¥Ε‘œσΘΚ(alertmanager-conf.yaml)

apiVersion: v1
kind: ConfigMap
metadata:name: alert-confignamespace: kube-ops
data:config.yml: |-global:# ‘ΎΟΜ”–±®Ψ·ΒΡ«ιΩωœ¬…υΟςΈΣ“―ΫβΨωΒΡ ±Φδresolve_timeout: 5m# ≈δ÷Ο” ΦΰΖΔΥΆ–≈œΔsmtp_smarthost: 'smtp.163.com:25'smtp_from: 'ych_1024@163.com'smtp_auth_username: 'ych_1024@163.com'smtp_auth_password: '<” œδΟή¬κ>'smtp_hello: '163.com'smtp_require_tls: false# Υυ”–±®Ψ·–≈œΔΫχ»κΚσΒΡΗυ¬Ζ”…Θ§”Οά¥…η÷Ο±®Ψ·ΒΡΖ÷ΖΔ≤Ώ¬‘route:# ’βάοΒΡ±ξ«©Ν–±μ «Ϋ” ’ΒΫ±®Ψ·–≈œΔΚσΒΡ÷Ί–¬Ζ÷Ήι±ξ«©Θ§άΐ»γΘ§Ϋ” ’ΒΫΒΡ±®Ψ·–≈œΔάοΟφ”––μΕύΨΏ”– cluster=A ΚΆ alertname=LatncyHigh ’β―υΒΡ±ξ«©ΒΡ±®Ψ·–≈œΔΫΪΜα≈ζΝΩ±ΜΨέΚœΒΫ“ΜΗωΖ÷ΉιάοΟφgroup_by: ['alertname', 'cluster']# Β±“ΜΗω–¬ΒΡ±®Ψ·Ζ÷Ήι±Μ¥¥Ϋ®ΚσΘ§–η“ΣΒ»¥ΐ÷Ν…Όgroup_wait ±Φδά¥≥θ ΦΜ·Ά®÷ΣΘ§’β÷÷ΖΫ ΫΩ…“‘»Ζ±ΘΡζΡή”–ΉψΙΜΒΡ ±ΦδΈΣΆ§“ΜΖ÷Ήιά¥Μώ»ΓΕύΗωΨ·±®Θ§»ΜΚσ“ΜΤπ¥ΞΖΔ’βΗω±®Ψ·–≈œΔΓΘgroup_wait: 30s# Β±ΒΎ“ΜΗω±®Ψ·ΖΔΥΆΚσΘ§Β»¥ΐ'group_interval' ±Φδά¥ΖΔΥΆ–¬ΒΡ“ΜΉι±®Ψ·–≈œΔΓΘgroup_interval: 5m# »γΙϊ“ΜΗω±®Ψ·–≈œΔ“―Ψ≠ΖΔΥΆ≥…ΙΠΝΥΘ§Β»¥ΐ'repeat_interval' ±Φδά¥÷Ί–¬ΖΔΥΆΥϊΟ«repeat_interval: 5m# Ρ§»œΒΡreceiverΘΚ»γΙϊ“ΜΗω±®Ψ·ΟΜ”–±Μ“ΜΗωrouteΤΞ≈δΘ§‘ρΖΔΥΆΗχΡ§»œΒΡΫ” ’Τςreceiver: default# …œΟφΥυ”–ΒΡ τ–‘ΕΦ”…Υυ”–Ή”¬Ζ”…ΦΧ≥–Θ§≤Δ«“Ω…“‘‘ΎΟΩΗωΉ”¬Ζ”……œΫχ––Η≤Η«ΓΘroutes:- receiver: emailgroup_wait: 10smatch:team: nodereceivers:- name: 'default'email_configs:- to: '517554016@qq.com'send_resolved: true- name: 'email'email_configs:- to: '517554016@qq.com'send_resolved: trueΖ÷Ήι
Ζ÷ΉιΜζ÷ΤΩ…“‘ΫΪœξœΗΒΡΗφΨ·–≈œΔΚœ≤Δ≥…“ΜΗωΆ®÷ΣΘ§‘ΎΡ≥–©«ιΩωœ¬Θ§±»»γ”…”ΎœΒΆ≥ε¥ΜζΒΦ÷¬¥σΝΩΒΡΗφΨ·±ΜΆ§ ±¥ΞΖΔΘ§‘Ύ’β÷÷«ιΩωœ¬Ζ÷ΉιΜζ÷ΤΩ…“‘ΫΪ’β–©±Μ¥ΞΖΔΒΡΗφΨ·Κœ≤ΔΈΣ“ΜΗωΗφΨ·Ά®÷ΣΘ§±ήΟβ“Μ¥Έ–‘Ϋ” ή¥σΝΩΒΡΗφΨ·Ά®÷ΣΘ§ΕχΈόΖ®Ε‘Έ ΧβΫχ––ΩλΥΌΕ®ΈΜΓΘ
’β « AlertManager ΒΡ≈δ÷ΟΈΡΦΰΘ§Έ“Ο«œ»÷±Ϋ”¥¥Ϋ®’βΗω ConfigMap Ή ‘¥Ε‘œσΘΚ
$ kubectl create -f alertmanager-conf.yaml
configmap "alert-config" created»ΜΚσ≈δ÷Ο AlertManager ΒΡ»ίΤςΘ§Έ“Ο«Ω…“‘÷±Ϋ”‘Ύ÷°«ΑΒΡ Prometheus ΒΡ Pod ÷–ΧμΦ”’βΗω»ίΤςΘ§Ε‘”ΠΒΡ YAML Ή ‘¥…υΟς»γœ¬ΘΚ
- name: alertmanagerimage: prom/alertmanager:v0.15.3imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/config.yml"ports:- containerPort: 9093name: httpvolumeMounts:- mountPath: "/etc/alertmanager"name: alertcfgresources:requests:cpu: 100mmemory: 256Milimits:cpu: 100mmemory: 256Mi
volumes:
- name: alertcfgconfigMap:name: alert-config’βάοΈ“Ο«ΫΪ…œΟφ¥¥Ϋ®ΒΡ alert-config ’βΗω ConfigMap Ή ‘¥Ε‘œσ“‘ Volume ΒΡ–Έ ΫΙ“‘ΊΒΫ /etc/alertmanager ΡΩ¬Φœ¬»ΞΘ§»ΜΚσ‘ΎΤτΕ·≤Έ ΐ÷–÷ΗΕ®ΝΥ≈δ÷ΟΈΡΦΰ--config.file=/etc/alertmanager/config.ymlΘ§»ΜΚσΈ“Ο«Ω…“‘ά¥Ηϋ–¬’βΗω Prometheus ΒΡ PodΘΚ
$ kubectl apply -f prome-deploy.yaml
deployment.extensions "prometheus" configuredΒ±»ΜΈ“Ο«“≤Ω…“‘ΫΪ AlertManager ΒΡ≈δ÷ΟΈΡΦΰΡΎ»ί÷±Ϋ”Ζ≈»κΒΫ÷°«ΑΒΡ Prometheus ΒΡ ConfigMap ΒΡΉ ‘¥Ε‘œσ÷–Θ§“≤Ω…“‘”Ο“ΜΗωΒΞΕάΒΡ Pod ά¥‘Υ–– AlertManager ’βΗω»ίΤςΘ§Άξ’ϊΒΡΉ ‘¥«εΒΞΈΡΦΰΩ…“‘≤ΈΩΦ’βάοΘΚhttps://github.com/cnych/kubeapp/tree/master/prometheus
AlertManager ΒΡ»ίΤςΤτΕ·Τπά¥ΚσΘ§Έ“Ο«ΜΙ–η“Σ‘Ύ Prometheus ÷–≈δ÷Οœ¬ AlertManager ΒΡΒΊ÷ΖΘ§»Ο Prometheus ΡήΙΜΖΟΈ ΒΫ AlertManagerΘ§‘Ύ Prometheus ΒΡ ConfigMap Ή ‘¥«εΒΞ÷–ΧμΦ”»γœ¬≈δ÷ΟΘΚ
alerting:alertmanagers:- static_configs:- targets: ["localhost:9093"]Ηϋ–¬’βΗωΉ ‘¥Ε‘œσΚσΘ§…‘Β»“Μ–ΓΜαΕυΘ§÷¥–– reload ≤ΌΉςΘΚ
$ kubectl delete -f prome-cm.yaml
configmap "prometheus-config" deleted
$ kubectl create -f prome-cm.yaml
configmap "prometheus-config" created
# Ητ“ΜΜαΕυΚσ
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.102.74.90 <none> 9090:30358/TCP 3d
$ curl -X POST "http://10.102.74.90:9090/-/reload"Ηϋ–¬Άξ≥…ΚσΘ§Έ“Ο«≤ιΩ¥ Pod ΖΔœ÷”–¥μΈσΘ§≤ιΩ¥œ¬ alertmanager »ίΤςΒΡ»’÷ΨΘ§ΖΔœ÷”–»γœ¬¥μΈσ–≈œΔΘΚ
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
prometheus-56d64bf6f7-rpz9j 1/2 CrashLoopBackOff 491 1d
$ kubectl logs -f prometheus-56d64bf6f7-rpz9j alertmanager -n kube-ops
level=info ts=2018-11-28T10:33:51.830071513Z caller=main.go:174 msg="Starting Alertmanager" version="(version=0.15.3, branch=HEAD, revision=d4a7697cc90f8bce62efe7c44b63b542578ec0a1)"
level=info ts=2018-11-28T10:33:51.830362309Z caller=main.go:175 build_context="(go=go1.11.2, user=root@4ecc17c53d26, date=20181109-15:40:48)"
level=error ts=2018-11-28T10:33:51.830464639Z caller=main.go:179 msg="Unable to create data directory" err="mkdir data/: read-only file system"’βΗω «“ρΈΣ–¬Αφ±Ψdockerfile÷–ΒΡΡ§»œWORKDIRΖΔ…ζΝΥ±δΜ·Θ§±δ≥…ΝΥ/etc/alertmanagerΡΩ¬ΦΘ§Ρ§»œ«ιΩωœ¬¥φ¥Δ¬ΖΨΕ--storage.path «œύΕ‘ΡΩ¬Φdata/Θ§“ρ¥ΥΘ§alertmanager Μα‘ΎΈ“Ο«…œΟφΙ“‘ΊΒΡ ConfigMap ÷–»Ξ¥¥Ϋ®’βΗωΡΩ¬ΦΘ§Υυ“‘Μα±®¥μΘ§Έ“Ο«Ω…“‘Ά®ΙΐΗ≤Η«--storage.path≤Έ ΐά¥ΫβΨω’βΗωΈ ΧβΘ§‘Ύ»ίΤςΤτΕ·≤Έ ΐ÷–ΧμΦ”ΗΟ≤Έ ΐΘΚ
- name: alertmanagerimage: prom/alertmanager:v0.15.3imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/config.yml"- "--storage.path=/alertmanager/data"÷Ί–¬Ηϋ–¬ PodΘ§Ω…“‘ΖΔœ÷ Prometheus “―Ψ≠ « Running Ή¥Χ§ΝΥΘΚ
$ kubectl apply -f prome-deploy.yaml
deployment.extensions "prometheus" configured
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
prometheus-646f457455-gr8x5 2/2 Running 0 3m
$ kubectl logs -f prometheus-646f457455-gr8x5 alertmanager -n kube-ops
level=info ts=2018-11-28T11:03:16.054633463Z caller=main.go:174 msg="Starting Alertmanager" version="(version=0.15.3, branch=HEAD, revision=d4a7697cc90f8bce62efe7c44b63b542578ec0a1)"
level=info ts=2018-11-28T11:03:16.054931931Z caller=main.go:175 build_context="(go=go1.11.2, user=root@4ecc17c53d26, date=20181109-15:40:48)"
level=info ts=2018-11-28T11:03:16.351058702Z caller=cluster.go:155 component=cluster msg="setting advertise address explicitly" addr=10.244.2.217 port=9094
level=info ts=2018-11-28T11:03:16.456683857Z caller=main.go:322 msg="Loading configuration file" file=/etc/alertmanager/config.yml
level=info ts=2018-11-28T11:03:16.548558156Z caller=cluster.go:570 component=cluster msg="Waiting for gossip to settle..." interval=2s
level=info ts=2018-11-28T11:03:16.556768564Z caller=main.go:398 msg=Listening address=:9093
level=info ts=2018-11-28T11:03:18.549158865Z caller=cluster.go:595 component=cluster msg="gossip not settled" polls=0 before=0 now=1 elapsed=2.000272112s
level=info ts=2018-11-28T11:03:26.558221484Z caller=cluster.go:587 component=cluster msg="gossip settled; proceeding" elapsed=10.009335611s±®Ψ·Ιφ‘ρ
œ÷‘ΎΈ“Ο«÷Μ «Α― AlertManager »ίΤς‘Υ––Τπά¥ΝΥΘ§“≤ΚΆ Prometheus Ϋχ––ΝΥΙΊΝΣΘ§ΒΪ «œ÷‘ΎΈ“Ο«≤Δ≤Μ÷ΣΒά“ΣΉω ≤Ο¥±®Ψ·Θ§“ρΈΣΟΜ”–»ΈΚΈΒΊΖΫΗφΥΏΈ“Ο«“Σ±®Ψ·Θ§Υυ“‘Έ“Ο«ΜΙ–η“Σ≈δ÷Ο“Μ–©±®Ψ·Ιφ‘ρά¥ΗφΥΏΈ“Ο«Ε‘ΡΡ–© ΐΨίΫχ––±®Ψ·ΓΘ
Ψ·±®Ιφ‘ρ‘ –μΡψΜυ”Ύ Prometheus ±μ¥ο Ϋ”ο―‘ΒΡ±μ¥ο Ϋά¥Ε®“ε±®Ψ·±®ΧθΦΰΘ§≤Δ‘Ύ¥ΞΖΔΨ·±® ±ΖΔΥΆΆ®÷ΣΗχΆβ≤ΩΒΡΫ” ’’ΏΓΘ
Ά§―υ‘Ύ Prometheus ΒΡ≈δ÷ΟΈΡΦΰ÷–ΧμΦ”»γœ¬±®Ψ·Ιφ‘ρ≈δ÷ΟΘΚ
prometheus.yml: |rule_files:- /etc/prometheus/rules.ymlalerting:alertmanagers:- static_configs:- targets: ["localhost:9093"][root@master prometheus]# cat prometheus-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitorlabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:serviceAccountName: monitorcontainers:- name: prometheusimage: prom/prometheus:v2.2.1imagePullPolicy: IfNotPresentcommand:- prometheus- --config.file=/etc/prometheus/prometheus.yml- --storage.tsdb.path=/prometheus- --storage.tsdb.retention=720h- --web.enable-lifecycleports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheusname: prometheus-config- name: localtimemountPath: /etc/localtimevolumes:- name: prometheus-configconfigMap:name: prometheus-config- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/ShanghaiΤδ÷–rule_filesΨΆ «”Οά¥÷ΗΕ®±®Ψ·Ιφ‘ρΒΡΘ§’βάοΈ“Ο«Ά§―υΫΪrules.ymlΈΡΦΰ”Ο ConfigMap ΒΡ–Έ ΫΙ“‘ΊΒΫ/etc/prometheusΡΩ¬Φœ¬ΟφΦ¥Ω…:
apiVersion: v1
kind: ConfigMap
metadata:name: prometheus-confignamespace: kube-ops
data:prometheus.yml: |............rules.yml: |groups:- name: test-rulerules:- alert: NodeMemoryUsageexpr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 20for: 2mlabels:team: nodeannotations:summary: "{
{$labels.instance}}: High Memory usage detected"description: "{
{$labels.instance}}: Memory usage is above 20% (current value is: {
{ $value }}"[root@master prometheus]# kubectl exec -it prometheus-server-5775f99578-vngfh -n monitor -c prometheus sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/prometheus $ ls /etc/prometheus/
prometheus.yml rules.yml …œΟφΈ“Ο«Ε®“εΝΥ“ΜΗωΟϊΈΣNodeMemoryUsageΒΡ±®Ψ·Ιφ‘ρΘ§Τδ÷–ΘΚ
for”οΨδΜα Ι Prometheus ΖΰΈώΒ»¥ΐ÷ΗΕ®ΒΡ ±Φδ, »ΜΚσ÷¥––≤ι―·±μ¥ο ΫΓΘlabels”οΨδ‘ –μ÷ΗΕ®ΕνΆβΒΡ±ξ«©Ν–±μΘ§Α―ΥϋΟ«ΗΫΦ”‘ΎΗφΨ·…œΓΘannotations”οΨδ÷ΗΕ®ΝΥΝμ“ΜΉι±ξ«©Θ§ΥϋΟ«≤Μ±ΜΒ±ΉωΗφΨ· ΒάΐΒΡ…μΖί±ξ ΕΘ§ΥϋΟ«Ψ≠≥Θ”Ο”Ύ¥φ¥Δ“Μ–©ΕνΆβΒΡ–≈œΔΘ§”Ο”Ύ±®Ψ·–≈œΔΒΡ’Ι Ψ÷°άύΒΡΓΘ
ΈΣΝΥΖΫ±ψ―ί ΨΘ§Έ“Ο«ΫΪΒΡ±μ¥ο Ϋ≈–Εœ±®Ψ·ΝΌΫγ÷Β…η÷ΟΈΣ20Θ§÷Ί–¬Ηϋ–¬ ConfigMap Ή ‘¥Ε‘œσΘ§”…”ΎΈ“Ο«‘Ύ Prometheus ΒΡ Pod ÷–“―Ψ≠Ά®Ιΐ Volume ΒΡ–Έ ΫΫΪ prometheus-config ’βΗω“ΜΗω ConfigMap Ε‘œσΙ“‘ΊΒΫΝΥ/etc/prometheusΡΩ¬Φœ¬ΟφΘ§Υυ“‘Ηϋ–¬ΚσΘ§ΗΟΡΩ¬Φœ¬Οφ“≤Μα≥ωœ÷rules.ymlΈΡΦΰΘ§Υυ“‘«ΑΟφ≈δ÷ΟΒΡrule_files¬ΖΨΕ“≤ «’ΐ≥ΘΒΡΘ§Ηϋ–¬Άξ≥…ΚσΘ§÷Ί–¬÷¥––reload≤ΌΉςΘ§’βΗω ±ΚρΈ“Ο«»Ξ Prometheus ΒΡ Dashboard ÷–«–ΜΜΒΫalerts¬ΖΨΕœ¬ΟφΨΆΩ…“‘Ω¥ΒΫ”–±®Ψ·≈δ÷ΟΙφ‘ρΒΡ ΐΨίΝΥΘΚ
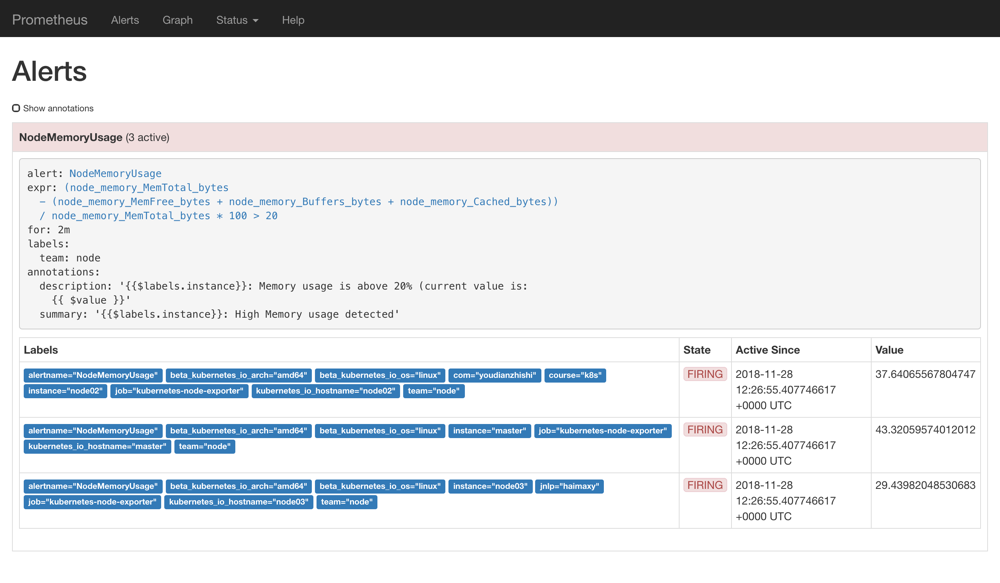
prometheus alerts
Έ“Ο«Ω…“‘Ω¥ΒΫ“≥Οφ÷–≥ωœ÷ΝΥΈ“Ο«Η’Η’Ε®“εΒΡ±®Ψ·Ιφ‘ρ–≈œΔΘ§Εχ«“±®Ψ·–≈œΔ÷–ΜΙ”–Ή¥Χ§œ‘ ΨΓΘ“ΜΗω±®Ψ·–≈œΔ‘Ύ…ζΟϋ÷ήΤΎΡΎ”–œ¬Οφ3÷÷Ή¥Χ§ΘΚ
- inactive: ±μ ΨΒ±«Α±®Ψ·–≈œΔΦ»≤Μ «firingΉ¥Χ§“≤≤Μ «pendingΉ¥Χ§
- pending: ±μ Ψ‘Ύ…η÷ΟΒΡψ–÷Β ±ΦδΖΕΈßΡΎ±ΜΦΛΜνΝΥ
- firing: ±μ Ψ≥§Ιΐ…η÷ΟΒΡψ–÷Β ±Φδ±ΜΦΛΜνΝΥ
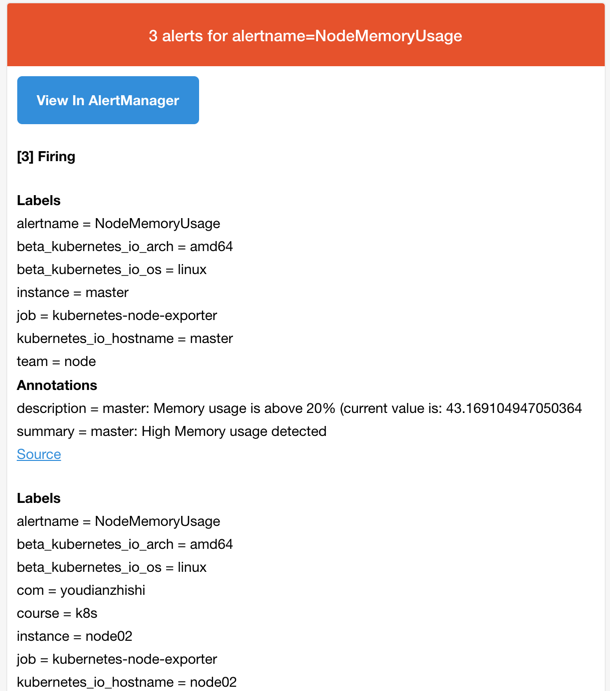
Έ“Ο«’βάοΒΡΉ¥Χ§œ÷‘Ύ «firingΨΆ±μ Ψ’βΗω±®Ψ·“―Ψ≠±ΜΦΛΜνΝΥΘ§Έ“Ο«’βάοΒΡ±®Ψ·–≈œΔ”–“ΜΗωteam=node’β―υΒΡ±ξ«©Θ§ΕχΉν…œΟφΈ“Ο«≈δ÷Ο alertmanager ΒΡ ±ΚρΨΆ”–»γœ¬ΒΡ¬Ζ”…≈δ÷Ο–≈œΔΝΥΘΚ
routes:
- receiver: emailgroup_wait: 10smatch:team: node Υυ“‘Έ“Ο«’βάοΒΡ±®Ψ·–≈œΔΜα±Μemail’βΗωΫ” ’Τςά¥Ϋχ––±®Ψ·Θ§Έ“Ο«…œΟφ≈δ÷ΟΒΡ «” œδΘ§Υυ“‘’ΐ≥Θά¥ΥΒ’βΗω ±ΚρΈ“Ο«Μα ’ΒΫ“ΜΖβ»γœ¬ΒΡ±®Ψ·” ΦΰΘΚ
prometheus email receiver