
??????????????ʲô�ǻƽ��ź�ָ�ꣿ����μ�� Kubernetes Ӧ�ó����еĻƽ��źţ�Golden Signals ���������������Ӧ�ó����е����⡣��Щ�ź���һ���ָ�꣬���û��������ߵĽǶ��ṩ����Ĺ㷺��ͼ����������Լ�����ֱ��Ӱ��Ӧ�ó�����Ϊ��DZ�����⡣
�������
��֮ǰPrometheus������ֽ��ܼ�صĻ���Ŀ�꣬�����Ǽ�ʱ�������������Ҫ�ܹ����ٶ�������ж�λ�����ڴ�ͳ��ؽ���������ԣ��û���������Ȼ��һ���ںУ��û��������˽�ϵͳ������������״̬�����Prometheus�����û�������еĶ����������о�һЩ���õļ��ά�ȡ�
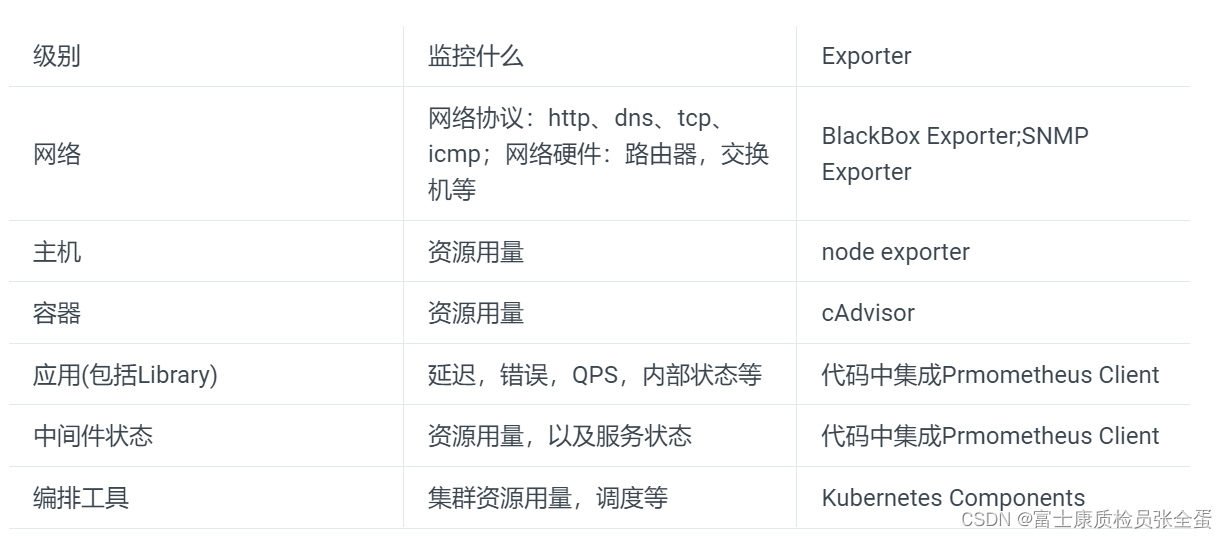
���ģʽ
�����������ܵIJ�ͬ��ؼ������⡣ʵ���ϸ��ݲ�ͬ��ϵͳ���ͺ�Ŀ�꣬���ﻹ��һЩͨ�õ���·��ģʽ����ʹ�á�
4���ƽ�ָ��
Four Golden Signals��Google��Դ����ֲ�ʽ��صľ����ܽᣬ4���ƽ�ָ������ڷ�����������ն��û����顢�����жϡ�ҵ��Ӱ��Ȳ�������⡣��Ҫ��ע�������������͵�ָ�꣺�ӳ٣�ͨѶ���������Լ����Ͷȣ�
-
�ӳ٣�������������ʱ�䡣
��¼�û��������������ʱ�䣬�ص���Ҫ���ֳɹ�������ӳ�ʱ���ʧ��������ӳ�ʱ�䡣 ���������ݿ���������ؼ����˷����쳣����HTTP 500������£��û�Ҳ���ܻ�ܿ�õ�����ʧ�ܵ���Ӧ���ݣ�����������ּ�����Щ������ӳ٣����ܵ��¼�������ʵ�ʽ��������IJ��졣�������⣬��������ͨ���ᳫ������ʧ�ܡ���������Ա��Ҫ�ر�ע����Щ�ӳٽϴ�Ĵ�����Ϊ��Щ�����Ĵ��������Ӱ��ϵͳ�����ܣ��������Щ������ӳ�Ҳ�Ƿdz���Ҫ�ġ�
-
ͨѶ������ص�ǰϵͳ�����������ں����������������
�������ڲ�ͬ���͵�ϵͳ���Կ��ܴ�����ͬ�ĺ��塣���磬��HTTP REST API��, ����ͨ����ÿ��HTTP��������
-
������ص�ǰϵͳ���з����Ĵ���������������ǰϵͳ�����������ʡ�
����ʧ�ܶ�����Щ����ʽ��(����, HTTP 500����)������Щ����ʽ(���磬HTTP��Ӧ200����ʵ��ҵ��������Ȼ��ʧ�ܵ�)��
����һЩ��ʽ�Ĵ�����HTTP 500����ͨ���ڸ��ؾ�����(��Nginx)�Ͻ��в�������һЩϵͳ�ڲ����쳣���������Ҫֱ�Ӵӷ��������ӹ���ͳ�Ʋ����л�ȡ��
-
���Ͷȣ�������ǰ����ı��Ͷȡ�
��Ҫǿ������Ӱ�����״̬�������Ƶ���Դ�� ���磬���ϵͳ��Ҫ���ڴ�Ӱ�죬�Ǿ���Ҫ��עϵͳ���ڴ�״̬�����ϵͳ��Ҫ���������I/O���Ǿ���Ҫ�۲����I/O��״̬����Ϊͨ������£�����Щ��Դ�ﵽ���ͺ�������ܻ������½���ͬʱ���������ñ��Ͷȶ�ϵͳ����Ԥ�⣬���磬�������Ƿ������4��Сʱ������ˡ���
RED����
RED������Weave Cloud�ڻ���Google�ġ�4���ƽ�ָ�ꡱ��ԭ���½��Prometheus�Լ�Kubernetes����ʵ����ϸ�����ܽ�ķ����ۣ��ر��ʺ�����ԭ��Ӧ���Լ�����ܹ�Ӧ�õļ�غͶ�������Ҫ��ע�������ֹؼ�ָ�꣺
-
(����)���ʣ�����ÿ����յ���������
-
(����)����ÿ��ʧ�ܵ���������
-
(����)��ʱ��ÿ������ĺ�ʱ��
�ڡ�4��ƽ��źš���ԭ���£�RED����������Ч�İ����û�������ԭ���Լ�����Ӧ���µ��û��������⡣
USE����
USE����ȫ��"Utilization Saturation and Errors Method"����Ҫ���ڷ���ϵͳ�������⣬����ָ���û�����ʶ����Դƿ���Լ�����ķ���������USE��������������ʾ�ĺ��壬USE������Ҫ��ע����Դ�ģ�ʹ����(Utilization)�����Ͷ�(Saturation)�Լ�����(Errors)��
-
ʹ���ʣ���עϵͳ��Դ��ʹ������� �������Դ��Ҫ�����������ڣ�CPU���ڴ棬���磬���̵ȵȡ�100%��ʹ����ͨ����ϵͳ����ƿ���ı�־��
-
���Ͷȣ�����CPU��ƽ�������Ŷӳ��ȣ�������Ҫ�������Դ�ı��Ͷ�(ע�⣬��ͬ��4��ƽ��ź�)���κ���Դ��ij�̶ֳ��ϵı��Ͷ����ܵ���ϵͳ���ܵ��½���
-
��������������磺�����������ݰ���������м�����̫�������ͻ��14�Ρ���
ͨ������Դ����ָ������۲죬ͨ���������̿���֪���û�ʶ����Դƿ����
�ƽ��źţ�Kubernetes Ӧ�ó����ر�
��ϲ�����ѳɹ��� Kubernetes �в�������Ӧ�ó�����ʱ���ᷢ�־ɵļ�ع����������ô�������������DZ�����⡣�����ع���ͨ�����ھ�̬�����ļ���ּ�ڼ�ػ���������������������������������У�����仯�ܿ졣�����������������ŵ��ٶȴ��������٣����û���ض��ķ����ֹ��ܣ��Ͳ����ܸ��ϡ��������µ�Sysdig ����ʹ�ñ��棬22% ���������ʱ�䲻�� 10 �룬54% ���������ʱ�䲻�� 5 ���ӡ�
������ִ����ϵͳΪ���ͬ��Ŀ���ṩ��������ָ�ꡣ��������û��ָ���У�������������Ӧ�ó���������ص����ݡ�����̫���صľ�����ʹ�����������Խ���״̬�͡������ľ���������һ�£�һ��������ʹ�ò�һֱ���������ؾ����Ľڵ㡣ֻҪ�ڵ��еķ���������Ͳ������κ����顣����������û�о���һ����⣬��Ϊ��Ҫ�ľ�������û���ؽ�Ҫ�ĺ����С�
���Ǻܶ��˶����ٵ����⣬���˵��ǣ��Ѿ����˽���ˡ������ĸ��ƽ��źţ�����Google SRE �ֲ����״�ʹ�õ�����ƽ��ź����ĸ�ָ�꣬���ǿ��������ܺõ��˽���÷����IJ�������������Ӧ�ó������ʵ����״�������������������������û���������Ӧ�ó����е���������
Golden signals metric: Latency explained
�ӳ�������ϵͳΪ��Է���������ṩ���������ʱ�䡣���Ǽ�������½��������Ҫ��־��
ʹ���ӳ�ʱ����ʹ��ƽ��ֵ�Dz����ģ���Ϊ���ǿ��ܻ���������磬������һ��������ʾƽ�� 100 �������Ӧʱ�䡣��ƾ��Щ��Ϣ���ǾͿ�����Ϊ���dz��ã����û��ķ�����������Ϊ�ǻ����ġ�
����ʹ�ò�ͬ��ͳ�Ʋ��������ƫ����ҵ����ì�ܵĴ𰸣��⽫ʹ�����˽��ӳ�ֵ�ķ�ɢ��������������������������һ�ַdz��죬��һ�ֽ�������Ϊ�������ݿ�����ܼ������һ�����͵��û�������һ��������� 10 ����������ƽ��ֵ���ܻ�ܵͣ���Ӧ�ó���������ƿ������Ҳ����Ҫ����������ƽ��ֵ��
����������Ϊ��һ���ܺõĹ�����ֱ��ͼָ�ꡣ��Щ��ʾ��ͬ�ӳ���ֵ�µ������������������������ٷ�λ���ۺϡ��ٷ�λ���ǵ��ڸ����ٷֱȵĶ���ֵ��ֵ�����磬p99 ��ʾ�� 99% ��������ӳ�ֵ���ڰٷ�λ����
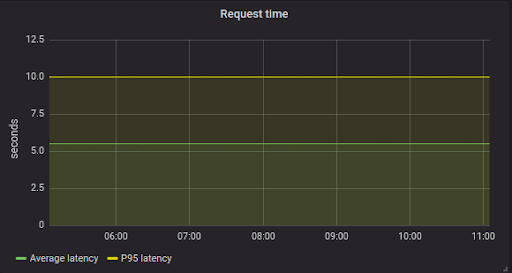
����������Ļ��ͼ�п����ģ�ƽ���ӳ��ǿ��Խ��ܵģ�����������Dz鿴�ٷ�λ�������ǻᷢ��ֵ���ںܴ���죬�Ӷ����õ��˽���ʵ���ӳٸ�֪��ʲô����ͬ�İٷ�λ�����ﲻͬ����Ϣ��p50 ͨ����ʾһ�������½����� p95���� p99����������ض������ϵͳ����е��������⡣
������Ϊ 1% ������ĸ��ӳٲ���ʲô�����⣬������������Ҫ������������ȫ���غ���ʾ�� Web Ӧ�ó��������ֳ����ij����У�1% �������еĸ��ӳٻ�Ӱ�������û��ĸߵö�����ʣ���Ϊ��Щ�������֮һ�ή������Ӧ�ó�������ܡ�
��һ�����ڷ����ӳ�ֵ�����ù�����APDEX �������������� SLA ����������ṩ���ڰٷ�λ����ϵͳ״�����ó̶ȵ�һ����
Golden signals metric: Errors explained
���ķ��صĴ������Ǹ����������һ���ܺõ�ָ�ꡣ����Ҫ�����ʽ����Ҫ�����ʽ������һ��dz���Ҫ��
��ʽ����������κ����͵� HTTP �����������Щ������ʶ����Ϊ�����������״ӻظ���ͷ�л�ã���������������ϵͳ�ж��dz�һ�¡���Щ�����һЩʾ����������Ȩ���� (503)��δ�ҵ����� (404) ����������� (500)����ijЩ����£������������ܷdz����壨418 �C ���Dz������
��һ���棬��ʽ������ܸ��Ѽ�⡣���� HTTP ��Ӧ���� 200 ���������д�����Ϣ��������ô������ͬ������Υ��ҲӦ����Ϊ����
- ������ HTTP �ظ��Ĵ�����Ϊ����ʱ�䳬����ʱʱ�䡣
- ���Գɹ��������е����ݴ���
When using dashboards to analyze errors, mean values or percentiles do not make any sense. In order to properly see the impact of errors, the best way is to use rates. The percentage of requests that end in errors per second can give detailed information about when the system started to fail and with what impact.
ʹ���DZ����������ʱ��ƽ��ֵ��ٷ�λ��û���κ����塣Ϊ����ȷ�ؿ��������Ӱ�죬��õķ�����ʹ�ñ��ʡ�ÿ���Դ������������ٷֱȿ����ṩ�й�ϵͳ��ʱ��ʼʧ���Լ�Ӱ�����ϸ��Ϣ��