SGI�汾��STL�еĹ�ϣ���Լ�hash_map��hash_set��û�б�����C++���еģ�������C++���е�unorder_map��unorder_set����������ģ����еײ�ʹ�õ�hashtable������ƪ�����н���hashtable�������������µ�����һ�Ա�һ��SGI�汾�Ĺ�ϣ���͵���C++���еĹ�ϣ��������
һ����ϣ������
��ϣ��ͬ����һ����ֵ��Ӧһ��ʵֵ�����ǹ�ϣ���ҵ�������Ҫ��ʵֵ������Ҫ������һ��ʹ�ö���ʱ����������Ϊ��ϣ����ʵֵ�ͼ�ֵ����һ����Ӧ�����ģ����ֺ�������Ϊɢ�к�����ͨ��ʵֵ������ü�ֵ�����֪���˼�ֵ��Ҳ����Ҫ������һ���Ӹ��ڵ㿪ʼ���²��ң����ǿ���������һ��ֱ���ҵ���ֵ��Ӧ���ڴ档��ʵҲ����ʹ���������ڴ�Ĺ��͡����������ϣ������ں���������ÿռ�����ȡʱ�䡣
�ڹ�ϣ��������������ȽϺ��ģ�һ�������Ǽ�ֵ��ʵֵ��ζ�Ӧ��Ҳ����ɢ�к����Ǻ�����ʽ���ܹ���ɢ�б��еĿռ������ʸ��ߣ������ù�ϣ��ռ�ÿռ��С��
�ڶ������������ν����ײ�����������ͬ��ʵֵ��ɢ�к���ӳ�䵽ͬһ����ֵ����ν����
��ɢ�к���
SGI��ɢ�к����ܼ�����ʵֵ%TableSize��
���������õ�ɢ�к�������ȥ������һ��
����ײ������
��������Ҫ�ᵽ�����ֽ����ʽ������̽�⣬����̽��Ϳ�����
- ����̽��
���ǵ�������ײʱ�����Զ�������һ���������ײ�����������ƣ�ֱ��û����ײΪֹ��
��һ������������ע������ʹ�õ�ɢ�к�������ʵֵ%TableSize��
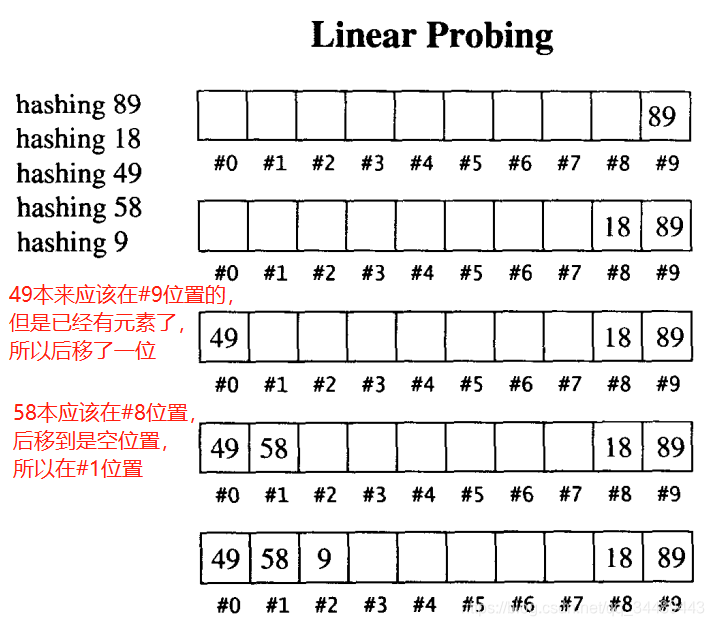
- ����̽��

- ����
������õģ�Ҳ��SGIʹ�õķ��������ǰ���ͬ��ֵ��Ԫ�طŵ�һ�𣬷���һ�������ϣ���ʽ���£�
���а�hashtable�ڵ�Ԫ�س�ΪͰ�ӡ�
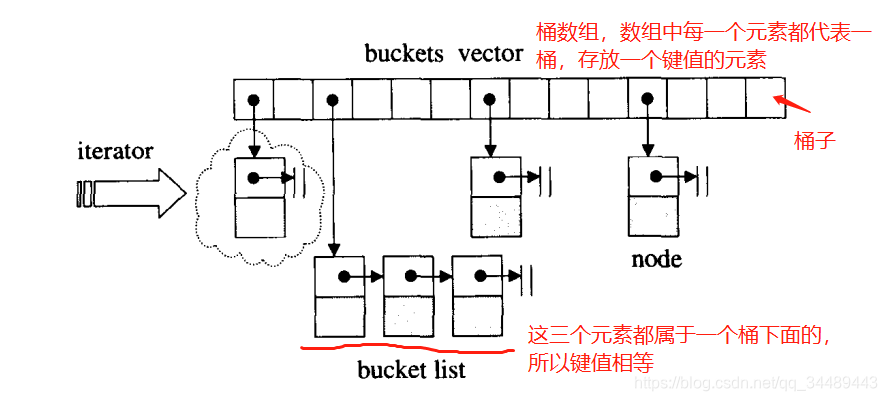
ע��������˵��ʵֵ�ͼ�ֵ���ֱ�ָ�û���ļ�ֵ�ͺ�ϣ��Ͱ���������ֵ�����ָ��������������˵��
����SGI�й�ϣ��Դ�����
�ٹ�ϣ����ÿһ��������ݵĽڵ�����ݽṹ
template <class _Val>
struct _Hashtable_node
{
_Hashtable_node* _M_next;_Val _M_val;
};
��û����ʹ��list����slist�����ǵ����ִ�����һ�������ڵ�
�ڹ�ϣ���ĵ�����
��ϣ���ĵ�����ʱforward_iterator�����������ֻ��++�������û�ШC�������
�������д洢��������Ա����
class _Hashtable_iterator
{
...typedef _Hashtable_node<_Val> _Node;_Node* _M_cur;//��ϣ����һ��Ԫ�ص�ָ��_Hashtable* _M_ht;//ָ���ϣ����Ͱ�����ָ��
...
}
��ϣ���������е�++���غ�����
template <class _Val, class _Key, class _HF, class _ExK, class _EqK, class _All>
_Hashtable_iterator<_Val,_Key,_HF,_ExK,_EqK,_All>&
_Hashtable_iterator<_Val,_Key,_HF,_ExK,_EqK,_All>::operator++()
{
const _Node* __old = _M_cur;_M_cur = _M_cur->_M_next;//�����һ�������ϻ�����һ��Ԫ�أ��Ǿͷ�����һ��if (!_M_cur) {
size_type __bucket = _M_ht->_M_bkt_num(__old->_M_val);//�ҵ��ڵ�Ԫ�ض�Ӧ��Ͱ��������Ͱ�����ҵ���һ������ͰԪ�أ���ͰԪ����ָ��Ľڵ����++�Ľ��while (!_M_cur && ++__bucket < _M_ht->_M_buckets.size())_M_cur = _M_ht->_M_buckets[__bucket];}return *this;//���ܻ᷵��NULL���������NULL�����Ǻ�����Ҳû�ҵ���һ��ֵ
}
�۹�ϣ�������ݽṹ
hasher _M_hash;//ɢ�к�������ϣӳ�亯����
key_equal _M_equals;//�жϼ�ֵ��ͬ���ĺ���
_ExtractKey _M_get_key;//�ӽڵ���ȡ����ֵ�ĺ����������ں������KeyofValue
vector<_Node*,_Alloc> _M_buckets;//Ͱ���飬ע�����õ�vectorʵ�ֵ�
size_type _M_num_elements;//��ϣ����Ԫ�ظ���
��Ͱ����Ĵ�С
��SGI�汾�У�Ͱ����Ĵ�Сֻ��28����������ȥ��ѡ��������ѡ����Ͱ�������Ŀ����Ȼ��ı�Ϊ�������28����������ʵûʲô�ô�����C++���У���û����������ˡ�
��Ͱ����IJ������
pair<iterator, bool> insert_unique(const value_type& __obj)
{
resize(_M_num_elements + 1);//�ж��Ƿ���Ҫ�ؽ�Ͱ���飬��Ҫ������return insert_unique_noresize(__obj);//����Ԫ��obj
}template <class _Val, class _Key, class _HF, class _Ex, class _Eq, class _All>
void hashtable<_Val,_Key,_HF,_Ex,_Eq,_All>::resize(size_type __num_elements_hint)
{
const size_type __old_n = _M_buckets.size();if (__num_elements_hint > __old_n) {
//����ϣ���е�Ԫ�ظ�������Ͱ����ĸ���ʱ���ͻ��ؽ�Ͱ����const size_type __n = _M_next_size(__num_elements_hint);//�ҳ���һ��������ȷ��Ͱ����ijߴ�if (__n > __old_n) {
//����һ���������ڵ�ǰ����ʱ���Ż��ؽ�Ͱ���飬����������ˣ��Ͳ���ı���vector<_Node*, _All> __tmp(__n, (_Node*)(0),_M_buckets.get_allocator());//�½�һ��Ͱ���飬����������ÿ��Ԫ�ض���0__STL_TRY {
for (size_type __bucket = 0; __bucket < __old_n; ++__bucket) {
_Node* __first = _M_buckets[__bucket];//ԭͰ����������ң��ӵ�һ���������£���ÿһ��Ԫ�������ҵ�//������Ͱ�����ж�Ӧ�ļ�ֵ��Ȼ���ƹ�ȥ������ÿ���²����Ԫ�ض��Dz���ͷԪ������while (__first) {
size_type __new_bucket = _M_bkt_num(__first->_M_val, __n);_M_buckets[__bucket] = __first->_M_next;__first->_M_next = __tmp[__new_bucket];__tmp[__new_bucket] = __first;__first = _M_buckets[__bucket];//�������ɹ����Բ鿴��260ҳ������Ϊ���Ƿ�����ָ��������ѣ�û��ʲô�������� }}_M_buckets.swap(__tmp);}}}
}
//����������Ҳ�ܼ��������ҵ���Ӧ�ļ�ֵ��Ȼ�����Ǹ�Ͱ�����Ƿ�����ͬʵֵ��Ԫ�أ��о����̷��أ�
//û�оͽ�Ԫ��obj�����������ڵ�
template <class _Val, class _Key, class _HF, class _Ex, class _Eq, class _All>
pair<typename hashtable<_Val,_Key,_HF,_Ex,_Eq,_All>::iterator, bool>
hashtable<_Val,_Key,_HF,_Ex,_Eq,_All>::insert_unique_noresize(const value_type& __obj)
{
const size_type __n = _M_bkt_num(__obj);_Node* __first = _M_buckets[__n];for (_Node* __cur = __first; __cur; __cur = __cur->_M_next) if (_M_equals(_M_get_key(__cur->_M_val), _M_get_key(__obj)))return pair<iterator, bool>(iterator(__cur, this), false);_Node* __tmp = _M_new_node(__obj);__tmp->_M_next = __first;_M_buckets[__n] = __tmp;++_M_num_elements;return pair<iterator, bool>(iterator(__tmp, this), true);
}
��insert_equalֻ�����һ�����뺯����ͬ��Դ�����£�
//�������ҵ���Ӧ�ļ�ֵ��Ȼ�����Ǹ�Ͱ�����Ƿ�����ͬʵֵ��Ԫ�أ��в��뵽��ͬ�ڵ��·���
//û�оͽ�Ԫ��obj�����������ڵ�
template <class _Val, class _Key, class _HF, class _Ex, class _Eq, class _All>
typename hashtable<_Val,_Key,_HF,_Ex,_Eq,_All>::iterator
hashtable<_Val,_Key,_HF,_Ex,_Eq,_All>::insert_equal_noresize(const value_type& __obj)
{
const size_type __n = _M_bkt_num(__obj);_Node* __first = _M_buckets[__n];for (_Node* __cur = __first; __cur; __cur = __cur->_M_next) if (_M_equals(_M_get_key(__cur->_M_val), _M_get_key(__obj))) {
_Node* __tmp = _M_new_node(__obj);__tmp->_M_next = __cur->_M_next;__cur->_M_next = __tmp;++_M_num_elements;return iterator(__tmp, this);}_Node* __tmp = _M_new_node(__obj);__tmp->_M_next = __first;_M_buckets[__n] = __tmp;++_M_num_elements;return iterator(__tmp, this);
}
����δ�ʵֵ�ҵ���ֵ
size_type _M_bkt_num(const value_type& __obj) const
{
return _M_bkt_num_key(_M_get_key(__obj));
}//��ʵֵ�ҵ���Ӧ�ļ�ֵ�������û����ʵֵ�ͼ�ֵ������set��ʵֵ�ͼ�ֵ��һ���ģ�map�м�ֵ��ʵֵ��first����size_type _M_bkt_num_key(const key_type& __key) const
{
return _M_bkt_num_key(__key, _M_buckets.size());
}
//������Ϊ���������������������ɢ�к��������û���ļ�ֵת���ɹ�ϣ����Ͱ�����������ֵ
//����_M_hash����hash functions��ֻ����SGI�е�hash function���٣�����ֻ���ļ��������ṩ�������ܶຯ��û���ṩ���������Ҫʹ�ã���Ҫ�Զ��塣
size_type _M_bkt_num_key(const key_type& __key, size_t __n) const
{
return _M_hash(__key) % __n;
}
����SGI��C++���й�ϣ����ʲô��һ��
��C++����Ͱ����ijߴ粻�����������������µ�Դ�룺
void _Check_size()
{
// grow table as needed
if (max_load_factor() < load_factor()){
// rehash to bigger tablesize_type _Newsize = bucket_count();if (_Newsize < 512)_Newsize *= 8; // ��512���dz���8else if (_Newsize < _Vec.max_size() / 2)_Newsize *= 2; // ����512���dz���2_Init(_Newsize);_Reinsert();}
}
��ɢ�к�����һ��
Դ�����£�
���������ڿ�����_Mask��ֵ����Ҳ��֪�����ԭ�����д�����
size_type _Hashval(const key_type& _Keyval) const
{
// return hash value, masked and wrapped to current table size
size_type _Num = ((_Traits&)*this)(_Keyval) & _Mask;
if (_Maxidx <= _Num)_Num -= (_Mask >> 1) + 1;
return (_Num);
}
��SGIģ���У�ֻ�м������Ϳ��Ե���ֵ������C++���У��������е�����Ե���ֵ��Ҳ����hash function�����������
�ġ�����hashtableʵ�ֵ�����
hash_set����ֵ��ʵֵ���ⶼ��Ӧ�ò�ļ�ֵʵֵ����һ���ģ�ʵ�ֻ��ƺ�setһ��������identity��������������û��˳��ģ���ֵ�����ظ���
hash_map:��ֵ��ʵֵ�Dz�һ���ģ�ʵ�ֻ��ƺ�mapһ��������select1st������������ÿ��Ԫ�ص����ݶ���pair��������û��˳��ģ���ֵ�����ظ���
hash_multiset����ֵ�����ظ���
hash_multimap����ֵ�����ظ�
��C++���ж�Ӧ��������
hash_set->unordered_set
hash_map->unordered_map
hash_multiset->unordered_multiset
hash_multimap->unordered_multimap