����Ŀ¼
- 1.����
- 2.ʹ��
-
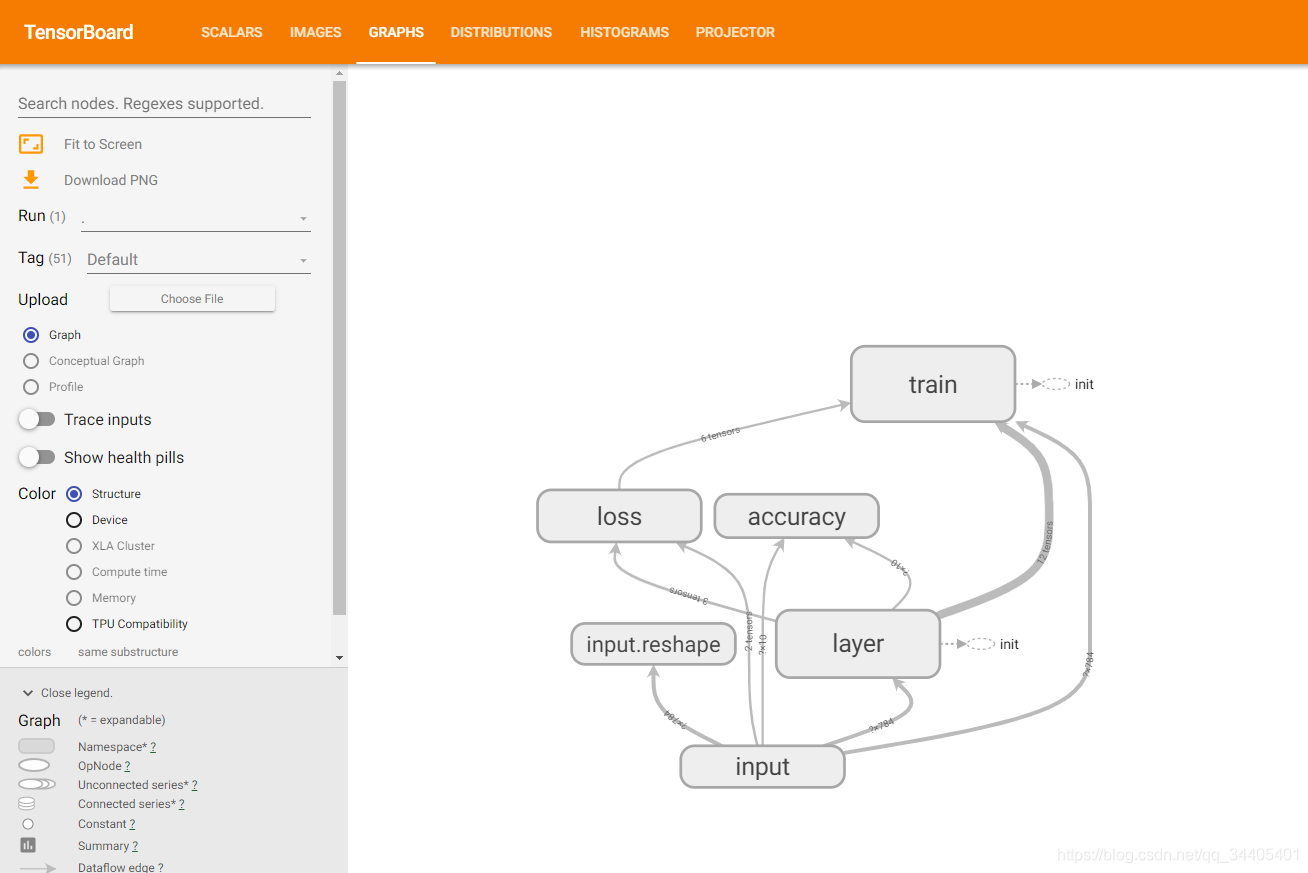
- 2.1 ��ʾ�����ͼ������with tf.name_scope('name')���ʹͼ�����������������Ϊ����
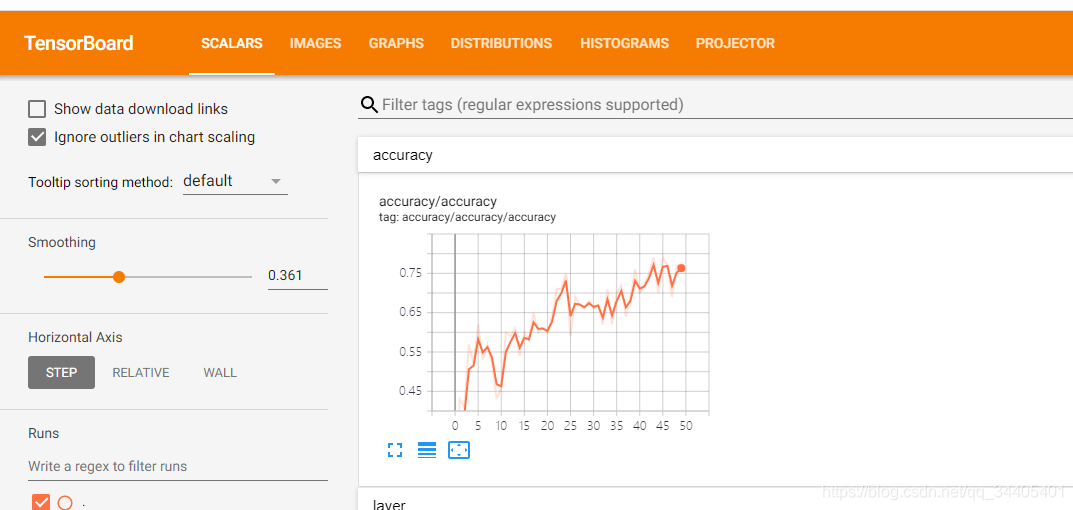
- 2.2 �鿴����ʱͼ�����ݣ�Ȩ�ء�ƫ�á���ʧֵ��ȷ�ʵ�ֵ�ڵ��������е���ʾ
- 2.3 ������̿��ӻ�
1.����
TensorBoard��Tensorflow�Դ���һ��ǿ��Ŀ��ӻ����ߣ�Ҳ��һ��webӦ�ó����������ڶ����ѧϰ���У�Tensorflow��ĿǰΨһ�Դ����ӻ����ߵĿ⡣����������չʾ����ͼ��������ָ��仯�������ķֲ�����ȡ��ر�����ѵ�������ʱ�����ǿ������ò�ͬ�IJ��������磺Ȩ��W��ƫ��B������������ȫ���Ӳ����ȣ���ʹ��TensorBoader���Ժ�ֱ�۵İ����ǽ��в�����ѡ��
2.ʹ��
2.1 ��ʾ�����ͼ������with tf.name_scope(��name��)���ʹͼ�����������������Ϊ����
1.��������ʹ�� with.tf.name_scope(��name��) �ѳ��������еĸ�С��ŵ����Ե������ռ���
2.�������ռ��µĸ�����Ҳ��������
3.�ڻỰ�¼��� writer=tf.summary.FileWriter(��TensorGraph/��,sess.graph) ��������һ��������·��������ͼ���ڵ�ǰĿ¼�µ�TensorGraph�ļ���û
�д��ļ����Զ�������
4.���г��ͻ�����ͼ��
5.��ͼ��cmd���У�����tensorboard --logdir=F:\jupyter_notebook\tensorflow_test\TensorGraph --host=127.0.0.1�����к���һ����ַ����google����ַ
6.��ֹ��ͼ��ctrl+c
7.����Ϊ���˳��������ͼ�����仯ʱ����Ҫ�ȰѴ���ԭͼ���ļ�ɾ����Ȼ���������г���jupyter notebook��>Kernel---->Restart & Runall��Ȼ������cmd��ͼ�����Ǿ��Ǹ��º��

import tensorflow as tf
#������д������ع��߰�
from tensorflow.examples.tutorials.mnist import input_data#�������ݼ�,��������Զ��������ݼ�����������Ҳ�����Լ�����
mnist=input_data.read_data_sets("MNIST_data",one_hot=True)#����ÿ�η�������·��ͼƬ������Ҳ����ѵ������
batch_size=50
#���㹲�ж�������,mnist.train.num_examples����ѵ�����ݵ�����
n_batch=mnist.train.num_examples//batch_sizewith tf.name_scope('input'):#��������placeholder#[None,784]����������������784�У���ΪͼƬ������28*28=784�����ݼ���ʾΪ60000*784����˴˴�����ҲΪ784��x=tf.placeholder(tf.float32,[None,784],name='xInput')#[None,10]:���ݼ���ÿ�����ֿɷ�Ϊ0��9ʮ����y=tf.placeholder(tf.float32,[None,10],name='yInput')with tf.name_scope('compute'):#������������:�����784����Ԫ�������10����Ԫw=tf.Variable(tf.zeros([784,10]),name="wight") #Ȩֵ��������������b=tf.Variable(tf.zeros([10]),name="bias") #ƫ��ֵprediction=tf.nn.softmax(tf.matmul(x,w)+b,name="softmaxNum") # ͨ��tf.matmul(x,w)+b������ź��ܺͣ���ͨ��softmaxתΪ����ֵ# #���δ��ۺ�����Ϊ��ʧ����(ԭ�汾)
# loss=tf.reduce_mean(tf.square(y-prediction))with tf.name_scope('train'):
#ʹ�ö�����Ȼ������Ϊ���ۺ���loss=tf.nn.softmax_cross_entropy_with_logits_v2(labels=y,logits=prediction)#ʹ��Adam�Ż�����С��losstrain_step=tf.train.AdamOptimizer(0.001).minimize(loss)#����ȷ�ʣ�����ѵ���õ�ģ�͵�Ԥ��ֵ��ȷ��
#tf.argmax(y,1)�Ƿ���y�������и��������Ǹ���equal�DZȽ����������Ƿ���ȣ�����bool����
#��Ϊtf.argmax(y,1)�Ľ�����б������correct_predictionҲ���б�
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
#��������ȷ��,tf.cast()�ǽ�bool���͵�ֵת��Ϊ�����ͣ�����reduce_mean()��ƽ��ֵ�ó�����
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#��ʼ������
init=tf.global_variables_initializer()with tf.Session() as sess:sess.run(init)#���ɱ����������ͼ�ļ�writer=tf.summary.FileWriter('TensorGraph/',sess.graph) for num in range(1): #��Ϊ���������Ϊ����ʾͼ�����Բ���ʱ��ѵ����for i in range(n_batch): # n_batch��ѵ�����ݵ���������#��õ�ǰ���ε�ͼƬ��ͼƬ���ݱ�����batchX��ͼƬ��ǩ������batchYbatchX,batchY=mnist.train.next_batch(batch_size)sess.run(train_step,feed_dict={
x:batchX,y:batchY})#ÿѵ����һ�Σ���һ��ȷ��,���������Dz��Լ���ͼƬ�ͱ�ǩprint("��{0}��ȷ��:".format({
num}),sess.run(accuracy,feed_dict={
x:mnist.test.images,y:mnist.test.labels}))
Extracting MNIST_data\train-images-idx3-ubyte.gz
Extracting MNIST_data\train-labels-idx1-ubyte.gz
Extracting MNIST_data\t10k-images-idx3-ubyte.gz
Extracting MNIST_data\t10k-labels-idx1-ubyte.gz
��{0}��ȷ��: 0.9051
2.2 �鿴����ʱͼ�����ݣ�Ȩ�ء�ƫ�á���ʧֵ��ȷ�ʵ�ֵ�ڵ��������е���ʾ
1.ʹ��tf.summary.scalar(��accuracy��, accuracy)������ֵ����һ�����������֣��ڶ�����������ֵ
2.tf.summary.histogram(��weights��, w)ֱ��ͼչʾ
3.���ͨ�� merge=tf.summary.merge_all() �����м��ֵ�ϲ�����
4 ��merge����ѵ��ģ��һ�����У�ע��˴�Ҫ�������������գ�Ҫ����ʽ�����
5.ÿ����һ�ν�����ͨ�� writer.add_summary(summary,num)������һ�μ��ֵ�ı仯�͵ڼ��μ��뵽���ɵ��ļ���
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_datamnist=input_data.read_data_sets("MNIST_data",one_hot=True)batch_size=50
n_batch=mnist.train.num_examples//batch_sizewith tf.name_scope('input'):x=tf.placeholder(tf.float32,[None,784],name='xInput')y=tf.placeholder(tf.float32,[None,10],name='yInput')with tf.name_scope('compute'):w=tf.Variable(tf.zeros([784,10]),name="wight") #Ȩֵ��������������#չʾȨֵ w �ľ�ֵ�仯tf.summary.scalar('weightScalar',tf.reduce_mean(w))#��ֱ��ͼչʾ w �仯���tf.summary.histogram('weightHistogram',w)b=tf.Variable(tf.zeros([10]),name="bias") #ƫ��ֵ#չʾƫ��ֵ b �ľ�ֵ�仯tf.summary.scalar('biasScalar',tf.reduce_mean(b))prediction=tf.nn.softmax(tf.matmul(x,w)+b,name="softmaxNum") # ͨ��tf.matmul(x,w)+b������ź��ܺͣ���ͨ��softmaxתΪ����ֵwith tf.name_scope('loss'):loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y,logits=prediction))#չʾ��ʧֵ�仯tf.summary.scalar('lossScalar',loss)
with tf.name_scope('train'):#ʹ��Adam�Ż���ѵ��ģ�ͣ�Ҳ������С����ʧ����train_step=tf.train.AdamOptimizer(0.001).minimize(loss)with tf.name_scope('accuracyCompute'):with tf.name_scope('correct_prediction'):correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))with tf.name_scope('accuracy'):accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#չʾȷ�ȵı仯tf.summary.scalar('accuracyScalar',accuracy)init=tf.global_variables_initializer()#�ϲ����еļ���ָ��ı仯
merged= tf.summary.merge_all()with tf.Session() as sess:sess.run(init)#���ɱ����������ͼ�ļ�writer=tf.summary.FileWriter('TensorGraph/',sess.graph) for num in range(21): for i in range(n_batch):batchX,batchY=mnist.train.next_batch(batch_size)#run��һ��������merge��Ϊ��һ��ѵ��һ��ͳ�ƣ�summary�ǽ��������Ǹ�merge����ģ�trainRes�ǽ���train_step�ģ���������ҪtrainRes#summary,trainRes=sess.run([merged,train_step],feed_dict={x:batchX,y:batchY})summary=sess.run(merged,feed_dict={
x:batchX,y:batchY})sess.run(train_step,feed_dict={
x:batchX,y:batchY})#��summary��sum���뵽���ɵ��ļ��У�sum�ǵڼ���writer.add_summary(summary,num)print("��{}��ȷ��:".format({
num}),sess.run(accuracy,feed_dict={
x:mnist.test.images,y:mnist.test.labels}))
WARNING:tensorflow:From <ipython-input-10-6d2870582292>:4: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.
Instructions for updating:
Please write your own downloading logic.
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting MNIST_data\train-images-idx3-ubyte.gz
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting MNIST_data\train-labels-idx1-ubyte.gz
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:110: dense_to_one_hot (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.one_hot on tensors.
Extracting MNIST_data\t10k-images-idx3-ubyte.gz
Extracting MNIST_data\t10k-labels-idx1-ubyte.gz
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
��{0}��ȷ��: 0.9081
��{1}��ȷ��: 0.9172
��{2}��ȷ��: 0.9231
��{3}��ȷ��: 0.9248
��{4}��ȷ��: 0.9235
��{5}��ȷ��: 0.9273
��{6}��ȷ��: 0.9278
��{7}��ȷ��: 0.9287
��{8}��ȷ��: 0.9286
��{9}��ȷ��: 0.9306
��{10}��ȷ��: 0.931
��{11}��ȷ��: 0.9318
��{12}��ȷ��: 0.9307
��{13}��ȷ��: 0.9319
��{14}��ȷ��: 0.9318
��{15}��ȷ��: 0.9321
��{16}��ȷ��: 0.933
��{17}��ȷ��: 0.9325
��{18}��ȷ��: 0.9324
��{19}��ȷ��: 0.9325
��{20}��ȷ��: 0.9325
ԭ������ʱһֱ���������������ִ�����
��һ�ִ���:tags and values not the same shape: [] != [50] (tag ��loss/lossScalar��)[[{ {node loss/lossScalar}}]]
�������:loss=tf.nn.softmax_cross_entropy_with_logits_v2(labels=y,logits=prediction)
����:loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y,logits=prediction))
�ڶ��ִ���:��ʾplaceholderû�д����ݣ������������Ƿ�ƨ
����:����jupyter notebook;������Kernel�£�����ÿ�����ж�Ҫ��������������
2.3 ������̿��ӻ�
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.tensorboard.plugins import projector#�������ݼ�
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
#�����
max_steps = 50
#ͼƬ����
image_num = 3000
#�ļ�·��
DIR = "F:/jupyter_notebook/tensorflow_test"#���V���
sess = tf.Session()
#������Ƭ
embedding = tf.Variable(tf.stack(mnist.test.images[:image_num]),trainable=False,name='embedding' )#������Ҫ
def variable_summaries(var):with tf.name_scope('summaries'):mean = tf.reduce_mean(var)tf.summary.scalar( 'mean',mean) #ƽ����with tf.name_scope('stddev'):stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))tf.summary.scalar('stddev',stddev) #����tf.summary.scalar('max',tf.reduce_max(var))#���tf.summary.scalar('min', tf.reduce_min(var)) #��С��tf.summary.histogram('histogram',var) #ֱ��ͼ#�����ռ�
with tf.name_scope('input'):#�����none��ʾ��һ��ά�ȿ���������ij���x = tf.placeholder(tf.float32,[None, 784],name='x-input')#��ȷ�ı�ǩy = tf.placeholder(tf.float32,[None, 10],name='y-input')#��ʾͼƬ
with tf.name_scope('input.reshape'):image_shaped_input = tf.reshape(x,[-1,28,28,1])tf.summary.image('input',image_shaped_input,10)with tf.name_scope('layer'):#����һһ����������with tf.name_scope('weights'):W = tf.Variable(tf.zeros([784,10]),name='W')variable_summaries (W)with tf.name_scope('biases'):b = tf.Variable(tf.zeros([10]),name='b' )variable_summaries (b)with tf.name_scope('wx_plus_b') :wx_plus_b = tf.matmul(x,W) + bwith tf.name_scope('softmax'):prediction = tf.nn.softmax(wx_plus_b)with tf.name_scope('loss'):#�����ش��ۺ���loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y,logits=prediction))tf.summary.scalar('1oss',loss)
with tf.name_scope('train'):#ʹ���ݶ��½���train_step=tf.train.AdamOptimizer(0.001).minimize(loss)#��ʼ������
sess.run(tf.global_variables_initializer())with tf.name_scope('accuracy'):with tf.name_scope('correct_prediction') :#��������һ���������б���correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax����-ά����������ֵ���ڵ�λ��with tf.name_scope('accuracy'):#��ȷ��accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) #��correct_prediction��Ϊfloat32����tf.summary.scalar('accuracy',accuracy)#����metadata�ļ�
if tf.gfile.Exists(DIR + '/projector/projector/metadata.tsv'):tf.gfile.DeleteRecursively(DIR +'/projector/projector/metadata.tsv')
with open(DIR+'/projector/projector/metadata.tsv','w') as f:labels=sess.run(tf.argmax(mnist.test.labels[:],1))for i in range(image_num):f.write(str(labels[i])+'\n')#�ϲ����е�summary
merged = tf.summary.merge_all()projector_writer =tf.summary.FileWriter(DIR +'/projector/projector',sess.graph)
saver = tf.train.Saver()
config = projector.ProjectorConfig()
embed = config.embeddings.add()
embed.tensor_name = embedding.name
embed.metadata_path = DIR +'/projector/projector/metadata.tsv'
embed.sprite.image_path = DIR +'projector/data/mnist_10k_sprite.png'
embed.sprite.single_image_dim.extend([28, 28])
projector.visualize_embeddings(projector_writer,config)for i in range (max_steps):#ÿ������100������batch_xs,batch_ys = mnist.train.next_batch(100)run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)run_metadata = tf.RunMetadata()summary,_=sess.run([merged,train_step],feed_dict={
x:batch_xs,y:batch_ys},options=run_options,run_metadata=run_metadata)projector_writer.add_run_metadata(run_metadata,'step%03d' % i)projector_writer.add_summary(summary,i)if i%5 == 0:acc = sess.run(accuracy,feed_dict={
x:mnist.test.images,y:mnist.test.labels})print ("Iter " + str(i) +" , Testing Accuracy= " + str (acc))saver.save(sess,DIR +'/projector/projector/a_model.ckpt',global_step=max_steps)
projector_writer.close()
sess.close()
WARNING:tensorflow:From <ipython-input-1-69a118b0aa4e>:6: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.
Instructions for updating:
Please write your own downloading logic.
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting MNIST_data/train-images-idx3-ubyte.gz
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting MNIST_data/train-labels-idx1-ubyte.gz
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:110: dense_to_one_hot (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.one_hot on tensors.
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
WARNING:tensorflow:From F:\anaconda\lib\site-packages\tensorflow_core\contrib\learn\python\learn\datasets\mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
Iter 0 , Testing Accuracy= 0.4341
Iter 5 , Testing Accuracy= 0.5381
Iter 10 , Testing Accuracy= 0.5527
Iter 15 , Testing Accuracy= 0.6098
Iter 20 , Testing Accuracy= 0.6489
Iter 25 , Testing Accuracy= 0.6812
Iter 30 , Testing Accuracy= 0.6982
Iter 35 , Testing Accuracy= 0.7
Iter 40 , Testing Accuracy= 0.7144
Iter 45 , Testing Accuracy= 0.7246