����Ŀ¼
- url
- 1.����ѧϰ�����㷨
- 2.�����Իع�Ϊ�����л���ѧϰ����
-
- 2.1 numpyʵ��
-
- �ܽ
- 2.2 sklearnʵ��
- 3.ͼ�����
-
- 3.1 ֧������������
- 4.�����㷨�����б�
- 5.������֤+��������(��������)
- 6.�ܽ�
url
https://download.csdn.net/download/qq_34405401/12208225
1.����ѧϰ�����㷨
- �ල
- ���Իع�
- ���ع� (����)
- SVM��֧��������support Vector Machine��
- DT����������
- �����㷨
- ���ɭ��
- XGBoost
- k-NN
- Bayes����
- �ල
- PCA
- ����������Ƽ���
- k-Means
2.�����Իع�Ϊ�����л���ѧϰ����
2.1 numpyʵ��
- ���Իع�ij���
- ���ݳ������ȹ�ϵ��
- ���Իع����(����������Ĺ�ϵ)��
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt# ��ȡ����
age = np.loadtxt('ex2x.dat')
tall = np.loadtxt('ex2y.dat')
# �����ݻ�һ��ɢ��ͼ
figure = plt.figure(1, figsize=(5, 4))
ax = figure.add_axes([0.1, 0.1, 0.8, 0.8], title='����������')
#��������x�ᣬx�������䣬left=1.0������Сһ�꣬right=10.0�������ʮ��
ax.set_xlim(left=1.0, right=10)
#����y�ᣬy�������ߣ����0.5�����1.5
ax.set_ylim(bottom=0.5, top=1.5)
ax.scatter(x=age, y=tall, color='blue')
plt.show()
# ��������
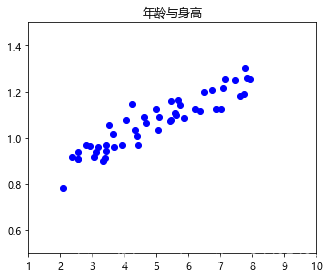
- ���ۣ�
- ���������߳����ȹ�ϵ��
- ѧϰĿ�꣺
- �ҳ�һ��ֱ�ߣ�ʹ�õ㾡������ֱ����Χ��
- ��ģ
- yi=w1?xi+w2?1y_i = w_1 \ast x_i + w_2 \ast 1yi?=w1??xi?+w2??1
- ���ŵ�w1��w2
- ��ģʽ�����Իع����ѧģ��:(����w����һ��1����w2����x���һ��)
- $ y = W \cdot x$
- ����ģ������ʵ�������ݴ������
- ?=y?y��\epsilon = y - y ^ \prime?=y?y��
- ����������������ģ�ͼ�������ݴ��������������ƽ������С��(������)
- ?=��i=1,?,N(yi?yi��)2\epsilon = \sum \limits _{i=1,\cdots, N} (y_i - y_i ^\prime)^2?=i=1,?,N��?(yi??yi��?)2
- ���ۻ���
- �����������Ӹ�˹�ֲ������ĵ�����ȷֵ��Խ�ӽ����ĵ�(��ȷֵ)����Խ��
- L=��ip(?�Oxi)L = \prod \limits _i p(\epsilon | x_i)L=i��?p(?�Oxi?)
- ��ʧ����(����)�����ż���
- ��Сֵ�㣨��ѧ������⣩
- ���������������ʧ�������㷨����Щ�㷨��װ��ģ�飬�У��Ż���
- ��С����ʧ������һЩ�����㷨��
- ��С���˷���
- �ݶ��½�����
- �����½�����
- ţ�ٵ�������
- ��ţ�ٷ�
- ��
��������-��������ģ�����(��������Ĵ���,ʹ����С���˷���W):
import numpy.linalg as ln
#��Ҫ��ѵ������age��tall�ѻ�ȡ����ӡ�鿴���ǵ�����
print(age.shape,tall.shape)
(50,) (50,)
#���������(50,)��ζ��һά���飬��������50��Ԫ�أ�����(50,1)�Ǿ��Ƕ�ά���飬��50��1��
#������Ҫ������ת�ɾ�����ζ�Ŷ�ά����
X = np.zeros(shape=(age.shape[0], 2), dtype=np.float)#�˴�X����������Ϊ��Ӧ����� 6.��ģ�ͣ������һ�ж���1
Y = tall.reshape(tall.shape[0], 1)#��ת�ɾ���(��ά����)��50��1����ʽ#X=np.zeros()�е�Ԫ�ض���0�������Ҫ��¡����
X[:, 0] = age
X[:, 1] = 1 #���һ�ж���1
W���㹫ʽ��W=(XTX)?1XTYW = (X^T X)^{-1}X^TYW=(XTX)?1XTY
W = np.matmul(np.matmul(ln.inv(np.matmul(X.T, X)), X.T), Y)
print(W)
[[0.06388117][0.75016254]]
Ԥ���Y(tall)�ļ��㹫ʽ�� $Y = X W $
#����Ҫ��ѧϰ�õ�������ģ�ͻ��������ٰ�ԭ������ʵ����ɢ��ͼҲ���������������Ƿ���ϰ��ģ�͵���Χ#������ģ�Ϳ�������ʵ���ݵ�x(age)��Ԥ��y(tall)������Ҳ����������50��x����������ģ������y��������ģ��#��0��10��֮������50����
X_AX = np.linspace(0, 10, 50, dtype=np.float)#��ʽ����
X_X = np.zeros(shape=(X_AX.shape[0], 2), dtype=np.float) # ��������50������-����
X_X[:, 0] = X_AX
X_X[:, 1] = 1
#���Ԥ��ֵY_X
Y_X = np.matmul(X_X, W)#��������ģ��
fig = plt.figure(1, figsize=(5, 4))
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8], title="ѵ��ģ��")
ax.set_xlim(0,10)
ax.set_ylim(0, 1.7)
ax.plot(X_AX, Y_X, color='blue')
#������ʵֵ��ɢ��ͼ
ax.scatter(x=age, y=tall, color='red')
plt.show()
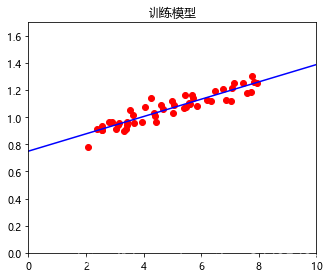
- 11.����Ƚ�
- �ع�ģ�ͱȽ���ʵֵ������ֵ֮�����Ϲ�ϵ�����ϵ��
- r(Y��,Y)=cov(Y��,Y)Var(Y��)Var(Y)r(Y ^ \prime, Y) = \dfrac{cov(Y^\prime,Y)}{\sqrt{Var(Y ^ \prime)Var(Y)}}r(Y��,Y)=Var(Y��)Var(Y)?cov(Y��,Y)?
Y_ = np.matmul(X, W)#Y_����ʵ����X��Ԥ��ֵ
r = np.corrcoef(Y.T, Y_.T)#�Ƚ�Ԥ���Y����ʵ��Y_
print(r)
[[1. 0.92631702][0.92631702 1. ]]
�ܽ
��ȷ��ģ�ͣ�Ȼ�����������ģ��ȷ����ʧ��������ѡ���Ż�����С����ʧ���������ģ�ͱ�̡�
2.2 sklearnʵ��
from sklearn.linear_model import LinearRegression# 1. ����
regressor = LinearRegression()# 2. fit��ѵ��
regressor.fit(X, Y) # sklearn�ṩ���ݸ�ʽ���Զ�����������Ҫ�������γ����ݸ�ʽ�Ĺ淶��# 3. Ԥ��
Y_PRE = regressor.predict(X)#coef��ϵ������ʱ��ӦW;intercept�ǽؾ�
print(regressor.coef_, regressor.intercept_)
[[0.06388117 0. ]] [0.75016254]
#����Ԥ���������
score = regressor.score(X, Y)
print(score)
0.858063223720823
3.ͼ�����
�����㷨�У�SVM��Logistic��PCA��
3.1 ֧������������
import numpy as np
#�����Ӿ�����ʹ��opencv
import cv2
# ��ȡͼ��
img_test = cv2.imread("./att_faces/s1/1.pgm")
print(img_test.shape)
(112, 92, 3)
#ÿ��ͼƬ����״Ϊ112��(��)��92��(��)��3Ϊ��ȼ���������ɫͨ��
#������չʾ����ͼƬ
%matplotlib inline
import matplotlib.pyplot as plt
#cmap=plt.cm.gray�ǰ��Ҷ�չʾ
plt.imshow(img_test, cmap=plt.cm.gray)
plt.show()

# ��������ȡͼ����һ�����İ���ͼ
# ���峣��#ÿ������ʮ���Լ���ͼ��
ONE_PERSON_FACE_NUM = 10
#һ����40����
PERSON_NUM = 40
#ͼ��������Ȼ��40*10
SAMPLE_NUM = ONE_PERSON_FACE_NUM * PERSON_NUM
#ÿ��ͼ���112����92
IMG_W = 92
IMG_H = 112#������ͼ�����ĵľ���
#��Ϊ��400��ͼ���������SAMPLE_NUM������ÿ��ͼ����Ϣ�����Ч����һ�д���һ��ͼ
data_faces = np.zeros(shape=(SAMPLE_NUM, IMG_W * IMG_H), dtype=np.int32)
#һ�д���һ��ͼƬ��������ֻ��Ҫһ��
label_faces = np.zeros(shape=(SAMPLE_NUM, 1), dtype=np.int32)#��ͼƬ��Ϣ���Ƶ�������
idx = 0 # ���ݼ���λ�ã������ĸ��ļ���
for i in range(1, PERSON_NUM + 1): # 40���˵�Ŀ¼,�˴���ʹ�DZ��1��PERSON_NUM����Ϊrange������PERSON_NUM�����Ե�+1for j in range(1, ONE_PERSON_FACE_NUM + 1):path_ = "./att_faces/s{i}/{j}.pgm".format(i=i,j=j)img_ = cv2.imread(path_)#��Ϊ��ȡ������ͨ��ͼ��Ϊ�˴����ټ�������ת��Ϊ�Ҷ�ͼ����Ϊ��ͼ��ʶ����ɫû��̫���ֵ�����Կ�ת�Ҷȣ�gray_ = cv2.cvtColor(img_, cv2.COLOR_BGR2GRAY)data_faces[idx, :] = gray_.reshape(IMG_W * IMG_H)label_faces[idx, :] = iidx += 1print(data_faces.shape,label_faces.shape)
(400, 10304) (400, 1)
#��ʱͼ��ת������ϣ��鿴�����Ƿ���Ϣ��ȷ
#�鿴����������һ��ͼ��
plt.imshow(data_faces[-1:].reshape((IMG_H, IMG_W)), cmap='gray')
plt.show()
#�鿴�ļ��д�ŵ����һ��
img_test = cv2.imread("./att_faces/s40/10.pgm")
plt.imshow(img_test, cmap=plt.cm.gray)
plt.show()


#ȷ��������Ϣ��ȷ����������ͼ�����Ԥ��������PCA��ά�����л��Զ���һ��
#��ά��ԭ����ԭ������ά��̫�ߣ�����̫��;�Ҿ�ʵ�齵��20άЧ�����from sklearn.decomposition import PCA
#����20ά
n_dims = 20
# ѵ����whitenΪ����svd_solverΪ����ֵ�ֽ�
pca = PCA(n_components=n_dims, whiten=True, svd_solver='randomized')
# ��data_faces��ѵ���õ���ά�������
pca.fit(data_faces)
#����ά��õ��ĵ�һ������������ʾ�������������
eg_faces = pca.components_.reshape((n_dims, IMG_H, IMG_W))
plt.imshow(eg_faces[0], cmap='gray')
plt.show()
print(eg_faces[0])

[[-0.00212508 -0.00211277 -0.0021425 ... -0.00192885 -0.00195297-0.00202584][-0.00215919 -0.00206477 -0.00235067 ... -0.00176855 -0.00173679-0.00189663][-0.0019191 -0.00201744 -0.00217899 ... -0.0018383 -0.00174359-0.00175921]...[-0.01346525 -0.01375571 -0.01361521 ... -0.00615034 -0.00604953-0.00588547][-0.01411743 -0.01450171 -0.01444153 ... -0.00682447 -0.00679768-0.00701538][-0.01481082 -0.01578775 -0.01547279 ... -0.00704006 -0.00639096-0.00734479]]
#�鿴��ά�����е���������
rows = 5
cols = 4
plt.figure(figsize=(1.8 * cols, 2.4 * rows))
for i in range(n_dims):ax = plt.subplot(rows, cols, i+1)plt.imshow(eg_faces[i], cmap="gray")plt.xticks(())plt.yticks(())
plt.show()

#ͨ�������Խ�ά��ѵ�����Ѿ��ó���20���������������������ݽ�ά��20ά
#�˴���data_facesѵ������data_faces��ά������������;��ʵӦ����һ��������ѵ����Ȼ����������ݽ�ά
pca_data = pca.transform(data_faces)
print(pca_data.shape)
(400, 20)
#�������ع���з��࣬SVC��֧����������������
from sklearn.svm import SVC
classifier = SVC(kernel='rbf', C=1000, gamma=0.1)
#ѵ��
classifier.fit(pca_data, label_faces[:,0])
#Ԥ�⣬��ѵ�������ݽ���Ԥ�⣬��̫��
pre_labels = classifier.predict(pca_data)
#��ӡԤ�����
print(pre_labels)
[ 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 33 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 55 5 6 6 6 6 6 6 6 6 6 6 7 7 7 7 7 7 7 7 7 7 8 88 8 8 8 8 8 8 8 9 9 9 9 9 9 9 9 9 9 10 10 10 10 10 1010 10 10 10 11 11 11 11 11 11 11 11 11 11 12 12 12 12 12 12 12 12 12 1213 13 13 13 13 13 13 13 13 13 14 14 14 14 14 14 14 14 14 14 15 15 15 1515 15 15 15 15 15 16 16 16 16 16 16 16 16 16 16 17 17 17 17 17 17 17 1717 17 18 18 18 18 18 18 18 18 18 18 19 19 19 19 19 19 19 19 19 19 20 2020 20 20 20 20 20 20 20 21 21 21 21 21 21 21 21 21 21 22 22 22 22 22 2222 22 22 22 23 23 23 23 23 23 23 23 23 23 24 24 24 24 24 24 24 24 24 2425 25 25 25 25 25 25 25 25 25 26 26 26 26 26 26 26 26 26 26 27 27 27 2727 27 27 27 27 27 28 28 28 28 28 28 28 28 28 28 29 29 29 29 29 29 29 2929 29 30 30 30 30 30 30 30 30 30 30 31 31 31 31 31 31 31 31 31 31 32 3232 32 32 32 32 32 32 32 33 33 33 33 33 33 33 33 33 33 34 34 34 34 34 3434 34 34 34 35 35 35 35 35 35 35 35 35 35 36 36 36 36 36 36 36 36 36 3637 37 37 37 37 37 37 37 37 37 38 38 38 38 38 38 38 38 38 38 39 39 39 3939 39 39 39 39 39 40 40 40 40 40 40 40 40 40 40]
#�鿴Ԥ���ȷ��,�˴���100%��ȷ
corr_num = (pre_labels == label_faces[:,0]).sum()
corr_num/=400.0
print(corr_num)
1.0
4.�����㷨�����б�
- ʶ��ȷ�ʣ�
- ��ʶ�ʣ���FAR����ָ�ڱ�ָ�����ݿ��ϲ���ָ��ʶ���㷨ʱ����ָͬ�Ƶ�ƥ��������ڸ�����ֵ���Ӷ�����Ϊ����ָͬ�Ƶı�������˵���ǡ��Ѳ�Ӧ��ƥ���ָ�Ƶ���ƥ���ָ�ơ��ı�����
- ��ʶ�ʣ���FRR����ָ�ڱ�ָ�����ݿ��ϲ���ָ��ʶ���㷨ʱ����ָͬ�Ƶ�ƥ��������ڸ�����ֵ���Ӷ�����Ϊ�Dz�ָͬ�Ƶı�������˵���� ����Ӧ���ƥ��ɹ���ָ�Ƶ��ɲ���ƥ���ָ�ơ��ı�����
- ����ģʽ��
- ��������
- ���౨��
- ��ȷ�ȵ÷�
��������ͼ����������Ϊ����
# ��������from sklearn.metrics import confusion_matrixmatrix = confusion_matrix(pre_labels, label_faces[:,0])
print(matrix)
[[10 0 0 ... 0 0 0][ 0 10 0 ... 0 0 0][ 0 0 10 ... 0 0 0]...[ 0 0 0 ... 10 0 0][ 0 0 0 ... 0 10 0][ 0 0 0 ... 0 0 10]]
# ���౨��from sklearn.metrics import classification_reportreport = classification_report(pre_labels, label_faces[:,0])
print(report)
precision recall f1-score support1 1.00 1.00 1.00 102 1.00 1.00 1.00 103 1.00 1.00 1.00 104 1.00 1.00 1.00 105 1.00 1.00 1.00 106 1.00 1.00 1.00 107 1.00 1.00 1.00 108 1.00 1.00 1.00 109 1.00 1.00 1.00 1010 1.00 1.00 1.00 1011 1.00 1.00 1.00 1012 1.00 1.00 1.00 1013 1.00 1.00 1.00 1014 1.00 1.00 1.00 1015 1.00 1.00 1.00 1016 1.00 1.00 1.00 1017 1.00 1.00 1.00 1018 1.00 1.00 1.00 1019 1.00 1.00 1.00 1020 1.00 1.00 1.00 1021 1.00 1.00 1.00 1022 1.00 1.00 1.00 1023 1.00 1.00 1.00 1024 1.00 1.00 1.00 1025 1.00 1.00 1.00 1026 1.00 1.00 1.00 1027 1.00 1.00 1.00 1028 1.00 1.00 1.00 1029 1.00 1.00 1.00 1030 1.00 1.00 1.00 1031 1.00 1.00 1.00 1032 1.00 1.00 1.00 1033 1.00 1.00 1.00 1034 1.00 1.00 1.00 1035 1.00 1.00 1.00 1036 1.00 1.00 1.00 1037 1.00 1.00 1.00 1038 1.00 1.00 1.00 1039 1.00 1.00 1.00 1040 1.00 1.00 1.00 10accuracy 1.00 400macro avg 1.00 1.00 1.00 400
weighted avg 1.00 1.00 1.00 400
# ��ȷ�ȵ÷�from sklearn.metrics import accuracy_scoreacc = accuracy_score(pre_labels, label_faces[:,0])
print(acc)
1.0
5.������֤+��������(��������)
- �������ݼ�����Ϊ��ѵ���������Լ�
- ���ַ�����
- ֱ�ӷ�
- n-��
- ���ַ�����
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.svm import SVC
#�������ݼ�
data,target=datasets.load_iris(return_X_y=True)
print(data.shape)#������֤��ѵ����+���Լ�
#test_size=0.2,���Լ���ԭ���ݹ�ģ��0.2
data_train,data_test,target_train,target_test=train_test_split(data,target,test_size=0.2)
print(data_train.shape)#���û���ѧϰ�㷨���ѵ��������ѵ��+��������ѵ����
#classifier=SVC(kernel='rbf',C=1000,gamma=0.1) #����㷨�����ǹ̶���
#�����ֵ�
dic_p={
'C':[1,10,100,10000],'gamma':[0.01,0.1,1],
}
#��������������ǴӲ����ֵ����Զ��ҵ���Ѳ���,����������
classifier=GridSearchCV(SVC(kernel='rbf'),dic_p)
classifier.fit(data_train,target_train)#���
pre=classifier.predict(data_test)
#���Լ�һ����ʮ������ӡ��ȷԤ��ĸ���
print((pre==target_test).sum())
(150, 4)
(120, 4)
30
6.�ܽ�
- ģʽʶ�� ������ѧϰ�������Ӿ����������磬���ѧϰ��ϵ
- sklearn������ѧϰ�����࣬�ع飬���࣬ģ�ͣ���ά�� ����Ԥ���������ݷ��� -> �����ھ�
- tensorflow/pytorch: ���ѧϰ
- �����Ӿ���ͼ��opencv�� + ��Ȼ���ԣ�NLTK��