ВЉжїЮЊСЫЙЙНЈЭГвЛЕФflinkбЇЯАБЪМЧ
https://ci.apache.org/projects/flink/flink-docs-release-1.13
https://ci.apache.org/projects/flink/flink-docs-release-1.12
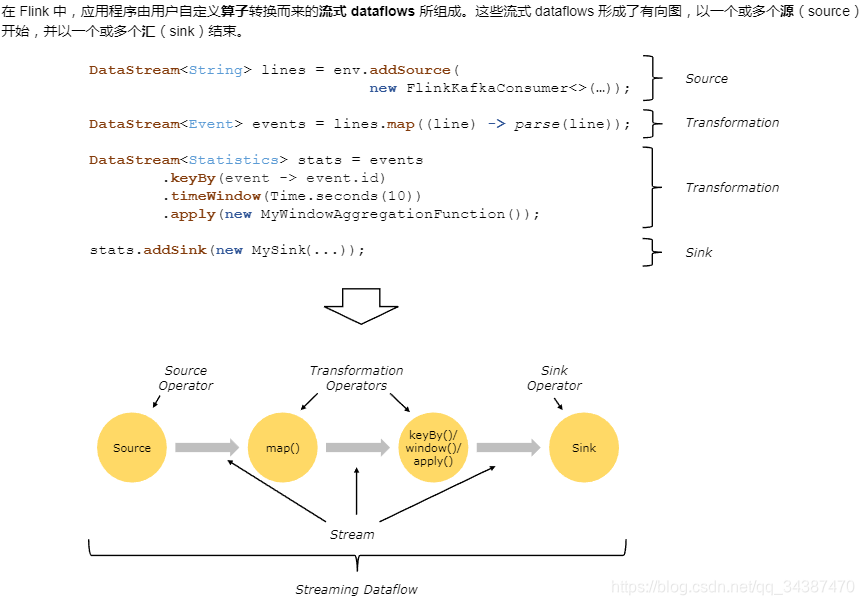
Flink ЫузгжЎМфПЩвдЭЈЙ§вЛЖдвЛЃЈжБДЋЃЉФЃЪНЛђжиаТЗжЗЂФЃЪНДЋЪфЪ§ОнЃК
вЛЖдвЛФЃЪНЃЈР§ШчЩЯЭМжаЕФ Source КЭ map() ЫузгжЎМфЃЉПЩвдБЃСєдЊЫиЕФЗжЧјКЭЫГађаХЯЂЁЃетвтЮЖзХ map() ЫузгЕФ subtask[1] ЪфШыЕФЪ§ОнвдМАЦфЫГађгы Source ЫузгЕФ subtask[1] ЪфГіЕФЪ§ОнКЭЫГађЭъШЋЯрЭЌЃЌ
МДЭЌвЛЗжЧјЕФЪ§ОнжЛЛсНјШыЕНЯТгЮЫузгЕФЭЌвЛЗжЧјЁЃ
жиаТЗжЗЂФЃЪНЃЈР§ШчЩЯЭМжаЕФ map() КЭ keyBy/window жЎМфЃЌвдМА keyBy/window КЭ Sink жЎМфЃЉдђЛсИќИФЪ§ОнЫљдкЕФСїЗжЧјЁЃЕБФудкГЬађжабЁдёЪЙгУВЛЭЌЕФ transformationЃЌ
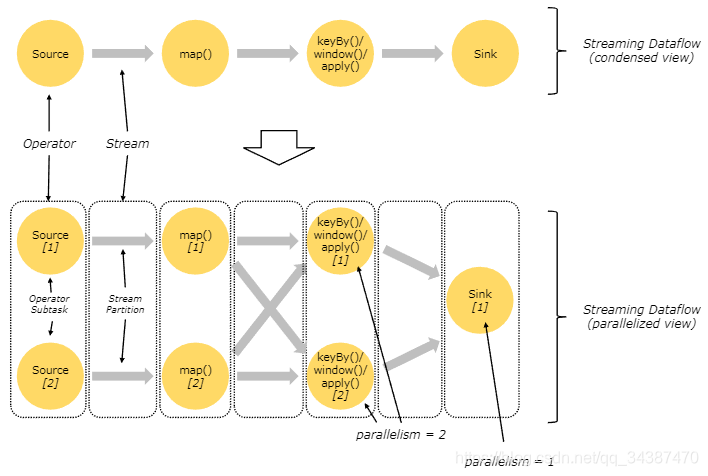
УПИіЫузгзгШЮЮёвВЛсИљОнВЛЭЌЕФ transformation НЋЪ§ОнЗЂЫЭЕНВЛЭЌЕФФПБъзгШЮЮёЁЃР§ШчвдЯТетМИжж transformation КЭЦфЖдгІЗжЗЂЪ§ОнЕФФЃЪНЃК
keyBy()ЃЈЭЈЙ§ЩЂСаМќжиаТЗжЧјЃЉЁЂbroadcast()ЃЈЙуВЅЃЉЛђ rebalance()ЃЈЫцЛњжиаТЗжЗЂЃЉЁЃдкжиаТЗжЗЂЪ§ОнЕФЙ§ГЬжаЃЌ
дЊЫижЛгадкУПЖдЪфГіКЭЪфШызгШЮЮёжЎМфВХФмБЃСєЦфжЎМфЕФЫГађаХЯЂЃЈР§ШчЃЌkeyBy/window ЕФ subtask[2] НгЪеЕНЕФ map() ЕФ subtask[1] жаЕФдЊЫиЖМЪЧгаађЕФЃЉ
ЁЃвђДЫЃЌЩЯЭМЫљЪОЕФ keyBy/window КЭ Sink ЫузгжЎМфЪ§ОнЕФжиаТЗжЗЂЪБЃЌВЛЭЌМќЃЈkeyЃЉЕФОлКЯНсЙћЕНДя Sink ЕФЫГађЪЧВЛШЗЖЈЕФЁЃ
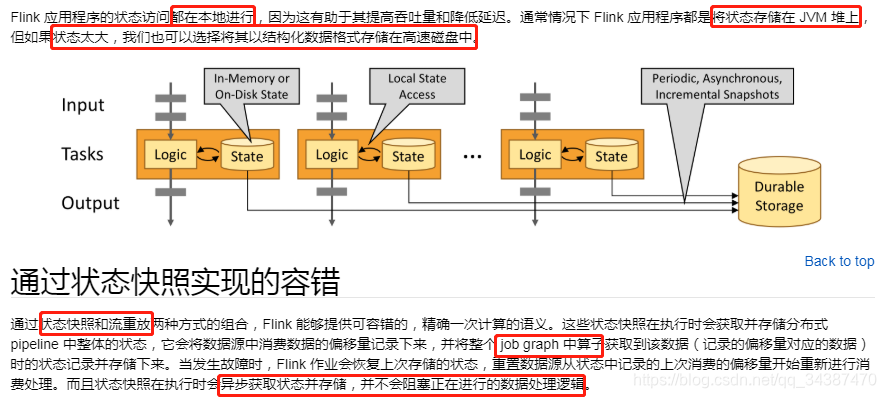

ЕБЪЙгУЛљгкЖбЕФ state backend БЃДцзДЬЌЪБЃЌЗУЮЪКЭИќаТЩцМАдкЖбЩЯЖСаДЖдЯѓЁЃЕЋЪЧЖдгкБЃДцдк RocksDBStateBackend жаЕФЖдЯѓЃЌЗУЮЪКЭИќаТЩцМАађСаЛЏКЭЗДађСаЛЏЃЌЫљвдЛсгаИќДѓЕФПЊЯњЁЃ
ЕЋ RocksDB ЕФзДЬЌСПНіЪмБОЕиДХХЬДѓаЁЕФЯожЦЁЃЛЙвЊзЂвтЃЌжЛга RocksDBStateBackend ФмЙЛНјаадіСППьееЃЌетЖдгкОпгаДѓСПБфЛЏЛКТ§зДЬЌЕФгІгУГЬађРДЫЕЪЧДѓгаёдвцЕФЁЃ
ЫљгаетаЉ state backends ЖМФмЙЛвьВНжДааПьееЃЌетвтЮЖзХЫќУЧПЩвддкВЛЗСАе§дкНјааЕФСїДІРэЕФЧщПіЯТжДааПьееЁЃ
![]()
BILIBILIМмЙЙ

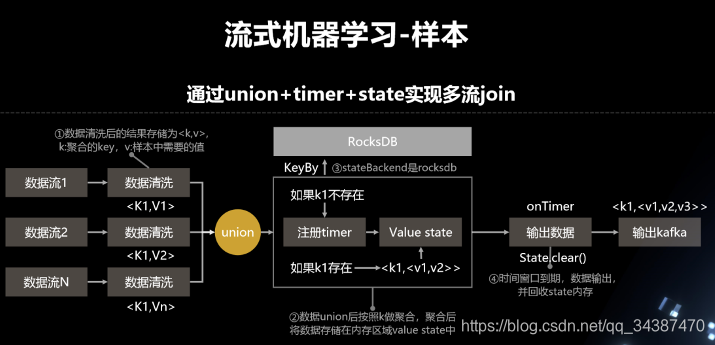
СїЪНЛњЦїбЇЯАЫљЮНЕФбљБОЩњГЩЃЌЦфЪЕОЭЪЧЖрИіЪ§ОнСїАДееЯрЭЌЕФ key зівЛИіЦДНгЁЃБШШчЫЕЃЌЮвУЧгаШ§ИіЪ§ОнСїЃЌЪ§ОнЧхЯДКѓЕФНсЙћДцДЂЮЊ <k , v>, k ЪЧОлКЯЕФ keyЃЌv ЪЧбљБОжаашвЊЕФжЕЁЃ
Ъ§Он union Кѓзі KeyBy ОлКЯЃЌОлКЯКѓНЋЪ§ОнДцДЂдкФкДцЧјгђ value state жаЁЃШчЯТЭМЫљЪОЃК
ШчЙћ k1 ВЛДцдкЃЌдђзЂВс timerЃЌдйДцЕН state жаЁЃ
ШчЙћ k1 ДцдкЃЌОЭДг state жаАбЫќИјФУГіРДЃЌИќаТжЎКѓдйДцНјШЅЁЃЕНзюКѓЫќЕФ timer ЕНЦкжЎКѓЃЌОЭЛсНЋетЬѕЪ§ОнЪфГіЃЌВЂЧвДг state жаЧхГ§ЕєЁЃ
BAIXINYINHANG