本篇为MyBatis查询缓存及配置笔记,内容为对一些相关文章的整合,很多文章都只介绍关于MyBatis缓存的一部分内容相对零散,以此篇文章进行相关整合,以节省广大开发者翻阅相关文档的时间和精力
Mybatis查询缓存简介
一级缓存是SqlSession级别的缓存。在操作数据库时需要构造 sqlSession对象,在对象中有一个数据结
构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共
用二级缓存,二级缓存是跨SqlSession的。
工作原理
一级缓存
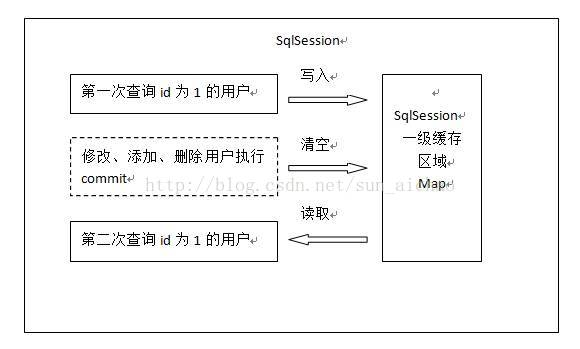
一级缓存工作原理图
第一次发起查询用户id为1的用户信息,先去找缓存中是否有1的用户,如果有的话拿去用,如果没有去数据库中查去。得到用户信息放入一级缓存中去。如果SqlSession去执行commit操作(执行插入、删除、更新)的话,清空SqlSession中的一级缓存,这样做就是为了让缓存中的数据保持最新,避免用户读到错误的数据。
二级缓存
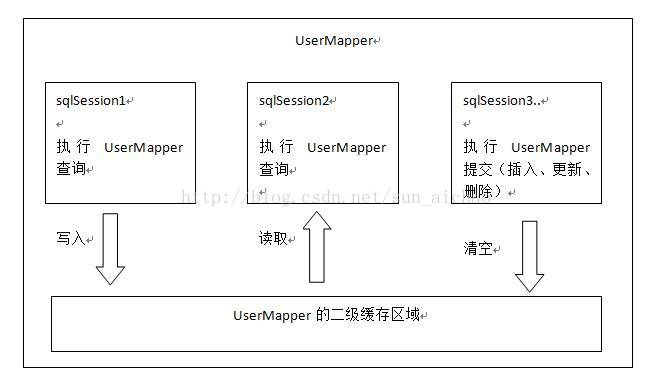
二级缓存工作原理图
首先得开启二级缓存,sqlSession1去查询用户id为1的用户信息,查询到用户信息会将查询数据存储到二级缓存中。
如果SqlSession3去执行相同 mapper下sql,执行commit提交,清空该 mapper下的二级缓存区域的数据。sqlSession2去查询用户
id为1的用户信息,去缓存中找是否存在数据,如果存在直接从缓存中取出数据。
一级缓存和二级缓存的区别
二级缓存的范围更大,多个sqlSession可以共享一个UserMapper的二级缓存区域。UserMapper有一个二级缓存区域(按namespace分) ,其它mapper也有自己的二级缓存区域(按namespace分)。
每一个namespace的mapper都有一个二缓存区域,两个mapper的namespace如果相同,这两个mapper执行sql查询到数据将存在相同 的二级缓存区域中。
mybaits的二级缓存是mapper范围级别的缓存,所以我们需要开启二级缓存,并在Mapper文件中开启具体的缓存配置
MyBatis中开启二级缓存及flushCache与useCache的使用
第一步:Configuration.xml设置二级缓存的总开关,
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="cacheEnabled" value="true" />
<setting name="lazyLoadingEnabled" value="false" />
<setting name="multipleResultSetsEnabled" value="true" />
<setting name="useColumnLabel" value="true" />
<setting name="defaultExecutorType" value="REUSE" />
<setting name="defaultStatementTimeout" value="25000" />
</settings>
<mappers>
</mappers>
</configuration>
第二步:在具体的mapper.xml中开启二级缓存。
在MyBatis的XML文件中可以
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.ctd.cmp.loganalyse.bean.pojo.mapper.CtdBizMetricsMapper">
<cache eviction="FIFO" flushInterval="600000" size="4096" readOnly="true"/>
<select id="save" parameterType="XX" flushCache="true" useCache="false"> </select>
</mapper>
各个属性意义如下:
- eviction:缓存回收策略
- LRU:最少使用原则,移除最长时间不使用的对象
- FIFO:先进先出原则,按照对象进入缓存顺序进行回收
- SOFT:软引用,移除基于垃圾回收器状态和软引用规则的对象
- WEAK:弱引用,更积极的移除移除基于垃圾回收器状态和弱引用规则的对象
- flushInterval:刷新时间间隔,单位为毫秒,这里配置的100毫秒。如果不配置,那么只有在进行数据库修改操作才会被动刷新缓存区
- size:引用额数目,代表缓存最多可以存储的对象个数
- readOnly:是否只读,如果为true,则所有相同的sql语句返回的是同一个对象(有助于提高性能,但并发操作同一条数据时,可能不安全),如果设置为false,则相同的sql,后面访问的是cache的clone副本。
可以在Mapper的具体方法下设置对二级缓存的访问意愿:
<select id="save" parameterType="XX" flushCache="true" useCache="false"> </select>
如果没有去配置flushCache、useCache,那么默认是启用缓存的
- flushCache默认为false,表示任何时候语句被调用,都不会去清空本地缓存和二级缓存。
- useCache默认为true,表示会将本条语句的结果进行二级缓存。
- 在insert、update、delete语句时: flushCache默认为true,表示任何时候语句被调用,都会导致本地缓存和二级缓存被清空。 useCache属性在该情况下没有。update 的时候如果 flushCache="false",则当你更新后,查询的数据数据还是老的数据。