1.数据准备
import sys
import osimport numpy as npimport textwrap
wrapper = textwrap.TextWrapper(width=70)import trax
from trax import layers as tl
from trax.fastmath import numpy as jnp# to print the entire np array
np.set_printoptions(threshold=sys.maxsize)# Importing CNN/DailyMail articles dataset
train_stream_fn = trax.data.TFDS('cnn_dailymail',data_dir='data/',keys=('article', 'highlights'),train=True)# This should be much faster as the data is downloaded already.
eval_stream_fn = trax.data.TFDS('cnn_dailymail',data_dir='data/',keys=('article', 'highlights'),train=False)
#helper func
def tokenize(input_str, EOS=1):"""Input str to features dict, ready for inference"""# Use the trax.data.tokenize method. It takes streams and returns streams,# we get around it by making a 1-element stream with `iter`.inputs = next(trax.data.tokenize(iter([input_str]),vocab_dir='vocab_dir/',vocab_file='summarize32k.subword.subwords'))# Mark the end of the sentence with EOSreturn list(inputs) + [EOS]def detokenize(integers):"""List of ints to str"""s = trax.data.detokenize(integers,vocab_dir='vocab_dir/',vocab_file='summarize32k.subword.subwords')return wrapper.fill(s)SEP = 0 # Padding or separator token
EOS = 1 # End of sentence token# Concatenate tokenized inputs and targets using 0 as separator.
def preprocess(stream):for (article, summary) in stream:joint = np.array(list(article) + [EOS, SEP] + list(summary) + [EOS])mask = [0] * (len(list(article)) + 2) + [1] * (len(list(summary)) + 1) # Accounting for EOS and SEPyield joint, joint, np.array(mask)# You can combine a few data preprocessing steps into a pipeline like this.
input_pipeline = trax.data.Serial(# Tokenizestrax.data.Tokenize(vocab_dir='vocab_dir/',vocab_file='summarize32k.subword.subwords'),# Uses function defined abovepreprocess,# Filters out examples longer than 2048trax.data.FilterByLength(2048)
)# Apply preprocessing to data streams.
train_stream = input_pipeline(train_stream_fn())
eval_stream = input_pipeline(eval_stream_fn())train_input, train_target, train_mask = next(train_stream)assert sum((train_input - train_target)**2) == 0 # They are the same in Language Model (LM).
boundaries = [128, 256, 512, 1024]
batch_sizes = [16, 8, 4, 2, 1]# Create the streams.
train_batch_stream = trax.data.BucketByLength(boundaries, batch_sizes)(train_stream)eval_batch_stream = trax.data.BucketByLength(boundaries, batch_sizes)(eval_stream)
2.构建模型
计算自注意力
def DotProductAttention(query, key, value, mask):"""Dot product self-attention.Args:query (jax.interpreters.xla.DeviceArray): array of query representations with shape (L_q by d)key (jax.interpreters.xla.DeviceArray): array of key representations with shape (L_k by d)value (jax.interpreters.xla.DeviceArray): array of value representations with shape (L_k by d) where L_v = L_kmask (jax.interpreters.xla.DeviceArray): attention-mask, gates attention with shape (L_q by L_k)Returns:jax.interpreters.xla.DeviceArray: Self-attention array for q, k, v arrays. (L_q by L_k)"""assert query.shape[-1] == key.shape[-1] == value.shape[-1], "Embedding dimensions of q, k, v aren't all the same"### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) #### Save depth/dimension of the query embedding for scaling down the dot productdepth = query.shape[-1]# Calculate scaled query key dot product according to formula abovedots = jnp.matmul(query, jnp.swapaxes(key, -1, -2)) / jnp.sqrt(depth)# Apply the maskif mask is not None: # The 'None' in this line does not need to be replaceddots = jnp.where(mask, dots, jnp.full_like(dots, -1e9))# Softmax formula implementation# Use trax.fastmath.logsumexp of dots to avoid underflow by division by large numbers# Hint: Last axis should be used and keepdims should be True# Note: softmax = e^(dots - logsumexp(dots)) = E^dots / sumexp(dots)logsumexp = trax.fastmath.logsumexp(dots,axis=-1,keepdims=True)# Take exponential of dots minus logsumexp to get softmax# Use jnp.exp()dots = jnp.exp(dots-logsumexp)# Multiply dots by value to get self-attention# Use jnp.matmul()attention = jnp.matmul(dots,value)## END CODE HERE ###return attentiondef dot_product_self_attention(q, k, v):""" Masked dot product self attention.Args:q (jax.interpreters.xla.DeviceArray): queries.k (jax.interpreters.xla.DeviceArray): keys.v (jax.interpreters.xla.DeviceArray): values.Returns:jax.interpreters.xla.DeviceArray: masked dot product self attention tensor."""### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) #### Hint: mask size should be equal to L_q. Remember that q has shape (batch_size, L_q, d)mask_size = q.shape[1]# Creates a matrix with ones below the diagonal and 0s above. It should have shape (1, mask_size, mask_size)# Notice that 1's and 0's get casted to True/False by setting dtype to jnp.bool_# Use jnp.tril() - Lower triangle of an array and jnp.ones()mask = jnp.tril(jnp.ones((1, mask_size, mask_size), dtype=jnp.bool_), k=0)### END CODE HERE ###return DotProductAttention(q, k, v, mask)Multi_heads:

def DotProductAttention(query, key, value, mask):"""Dot product self-attention.Args:query (jax.interpreters.xla.DeviceArray): array of query representations with shape (L_q by d)key (jax.interpreters.xla.DeviceArray): array of key representations with shape (L_k by d)value (jax.interpreters.xla.DeviceArray): array of value representations with shape (L_k by d) where L_v = L_kmask (jax.interpreters.xla.DeviceArray): attention-mask, gates attention with shape (L_q by L_k)Returns:jax.interpreters.xla.DeviceArray: Self-attention array for q, k, v arrays. (L_q by L_k)"""assert query.shape[-1] == key.shape[-1] == value.shape[-1], "Embedding dimensions of q, k, v aren't all the same"### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) #### Save depth/dimension of the query embedding for scaling down the dot productdepth = query.shape[-1]# Calculate scaled query key dot product according to formula abovedots = jnp.matmul(query, jnp.swapaxes(key, -1, -2)) / jnp.sqrt(depth)# Apply the maskif mask is not None: # The 'None' in this line does not need to be replaceddots = jnp.where(mask, dots, jnp.full_like(dots, -1e9))# Softmax formula implementation# Use trax.fastmath.logsumexp of dots to avoid underflow by division by large numbers# Hint: Last axis should be used and keepdims should be True# Note: softmax = e^(dots - logsumexp(dots)) = E^dots / sumexp(dots)logsumexp = trax.fastmath.logsumexp(dots,axis=-1,keepdims=True)# Take exponential of dots minus logsumexp to get softmax# Use jnp.exp()dots = jnp.exp(dots-logsumexp)# Multiply dots by value to get self-attention# Use jnp.matmul()attention = jnp.matmul(dots,value)## END CODE HERE ###return attentiondef compute_attention_output_closure(n_heads, d_head):""" Function that simulates environment inside CausalAttention function.Args:d_head (int): dimensionality of heads.n_heads (int): number of attention heads.Returns:function: compute_attention_output function"""def compute_attention_output(x):""" Compute the attention output.Args:x (jax.interpreters.xla.DeviceArray): tensor with shape (batch_size X n_heads, seqlen, d_head).Returns:jax.interpreters.xla.DeviceArray: reshaped tensor with shape (batch_size, seqlen, n_heads X d_head)."""### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) #### Length of the sequence# Should be size of x's first dimension without counting the batch dimseqlen = x.shape[1]# Reshape x using jnp.reshape() to shape (batch_size, n_heads, seqlen, d_head)x = jnp.reshape(x,(-1,n_heads,seqlen,d_head))# Transpose x using jnp.transpose() to shape (batch_size, seqlen, n_heads, d_head)x = jnp.transpose(x,(0,2,1,3))### END CODE HERE #### Reshape to allow to concatenate the headsreturn jnp.reshape(x, (-1, seqlen, n_heads * d_head))return compute_attention_output
def CausalAttention(d_feature, n_heads, compute_attention_heads_closure=compute_attention_heads_closure,dot_product_self_attention=dot_product_self_attention,compute_attention_output_closure=compute_attention_output_closure,mode='train'):"""Transformer-style multi-headed causal attention.Args:d_feature (int): dimensionality of feature embedding.n_heads (int): number of attention heads.compute_attention_heads_closure (function): Closure around compute_attention heads.dot_product_self_attention (function): dot_product_self_attention function. compute_attention_output_closure (function): Closure around compute_attention_output. mode (str): 'train' or 'eval'.Returns:trax.layers.combinators.Serial: Multi-headed self-attention model."""assert d_feature % n_heads == 0d_head = d_feature // n_heads### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) #### HINT: The second argument to tl.Fn() is an uncalled function (without the parentheses)# Since you are dealing with closures you might need to call the outer # function with the correct parameters to get the actual uncalled function.ComputeAttentionHeads = tl.Fn('AttnHeads', compute_attention_heads_closure, n_out=1)return tl.Serial(tl.Branch( # creates three towers for one input, takes activations and creates queries keys and values根据stack分别对应QKV[tl.Dense(d_feature), ComputeAttentionHeads], # queries[tl.Dense(d_feature), ComputeAttentionHeads], # keys[tl.Dense(d_feature), ComputeAttentionHeads], # values),tl.Fn('DotProductAttn', dot_product_self_attention, n_out=1), # takes QKV# HINT: The second argument to tl.Fn() is an uncalled function# Since you are dealing with closures you might need to call the outer # function with the correct parameters to get the actual uncalled function.tl.Fn('AttnOutput', compute_attention_output_closure, n_out=1), # to allow for paralleltl.Dense(d_feature) # Final dense layer)Serial[Branch_out3[[Dense_512, AttnHeads][Dense_512, AttnHeads][Dense_512, AttnHeads]]DotProductAttn_in3AttnOutputDense_512
]
def DecoderBlock(d_model, d_ff, n_heads,dropout, mode, ff_activation):"""Returns a list of layers that implements a Transformer decoder block.The input is an activation tensor.Args:d_model (int): depth of embedding.d_ff (int): depth of feed-forward layer.n_heads (int): number of attention heads.dropout (float): dropout rate (how much to drop out).mode (str): 'train' or 'eval'.ff_activation (function): the non-linearity in feed-forward layer.Returns:list: list of trax.layers.combinators.Serial that maps an activation tensor to an activation tensor."""### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) #### Create masked multi-head attention block using CausalAttention functioncausal_attention = tl.CausalAttention( d_model,n_heads=n_heads,mode=mode)# Create feed-forward block (list) with two dense layers with dropout and input normalizedfeed_forward = [ # Normalize layer inputstl.LayerNorm(),# Add first feed forward (dense) layer (don't forget to set the correct value for n_units)tl.Dense(n_units=d_ff),# Add activation function passed in as a parameter (you need to call it!)ff_activation(), # Generally ReLU# Add dropout with rate and mode specified (i.e., don't use dropout during evaluation)tl.Dropout(rate=dropout,mode=mode),# Add second feed forward layer (don't forget to set the correct value for n_units)tl.Dense(n_units=d_model),# Add dropout with rate and mode specified (i.e., don't use dropout during evaluation)tl.Dropout(rate=dropout,mode=mode)]# Add list of two Residual blocks: the attention with normalization and dropout and feed-forward blocksreturn [tl.Residual(# Normalize layer inputtl.LayerNorm(),# Add causal attention block previously defined (without parentheses)causal_attention,# Add dropout with rate and mode specifiedtl.Dropout(rate=dropout,mode=mode)),tl.Residual(# Add feed forward block (without parentheses)feed_forward),][Serial[Branch_out2[NoneSerial[LayerNormSerial[Branch_out3[[Dense_512, AttnHeads][Dense_512, AttnHeads][Dense_512, AttnHeads]]DotProductAttn_in3AttnOutputDense_512]Dropout]]Add_in2
], Serial[Branch_out2[NoneSerial[LayerNormDense_2048ReluDropoutDense_512Dropout]]Add_in2
]]
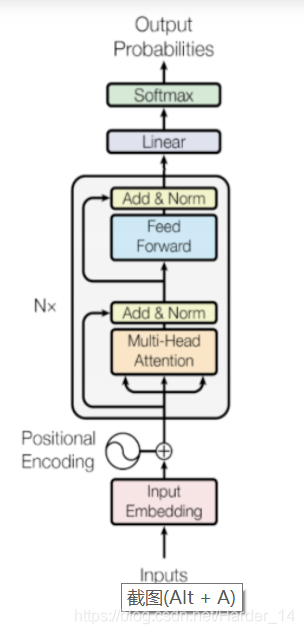
def TransformerLM(vocab_size=33300,d_model=512,d_ff=2048,n_layers=6,n_heads=8,dropout=0.1,max_len=4096,mode='train',ff_activation=tl.Relu):"""Returns a Transformer language model.The input to the model is a tensor of tokens. (This model uses only thedecoder part of the overall Transformer.)Args:vocab_size (int): vocab size.d_model (int): depth of embedding.d_ff (int): depth of feed-forward layer.n_layers (int): number of decoder layers.n_heads (int): number of attention heads.dropout (float): dropout rate (how much to drop out).max_len (int): maximum symbol length for positional encoding.mode (str): 'train', 'eval' or 'predict', predict mode is for fast inference.ff_activation (function): the non-linearity in feed-forward layer.Returns:trax.layers.combinators.Serial: A Transformer language model as a layer that maps from a tensor of tokensto activations over a vocab set."""### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) #### Embedding inputs and positional encoderpositional_encoder = [ # Add embedding layer of dimension (vocab_size, d_model)tl.Embedding(vocab_size,d_model),# Use dropout with rate and mode specifiedtl.Dropout(rate=dropout,mode=mode),# Add positional encoding layer with maximum input length and mode specifiedtl.PositionalEncoding(max_len=max_len,mode=mode)]# Create stack (list) of decoder blocks with n_layers with necessary parametersdecoder_blocks = [DecoderBlock(d_model, d_ff, n_heads, dropout, mode, ff_activation) for _ in range(n_layers)]# Create the complete model as written in the figurereturn tl.Serial(# Use teacher forcing (feed output of previous step to current step)tl.ShiftRight(mode=mode), # Specify the mode!# Add positional encoderpositional_encoder,# Add decoder blocksdecoder_blocks,# Normalize layertl.LayerNorm(),# Add dense layer of vocab_size (since need to select a word to translate to)# (a.k.a., logits layer. Note: activation already set by ff_activation)tl.Dense(vocab_size),# Get probabilities with Logsoftmaxtl.LogSoftmax())
Serial[ShiftRight(1)Embedding_33300_512DropoutPositionalEncodingSerial[Branch_out2[NoneSerial[LayerNormSerial[Branch_out3[[Dense_512, AttnHeads][Dense_512, AttnHeads][Dense_512, AttnHeads]]DotProductAttn_in3AttnOutputDense_512]Dropout]]Add_in2]Serial[Branch_out2[NoneSerial[LayerNormDense_2048ReluDropoutDense_512Dropout]]Add_in2]LayerNormDense_33300LogSoftmax
]3.模型训练
def training_loop(TransformerLM, train_gen, eval_gen, output_dir = "~/model"):'''Input:TransformerLM (trax.layers.combinators.Serial): The model you are building.train_gen (generator): Training stream of data.eval_gen (generator): Evaluation stream of data.output_dir (str): folder to save your file.Returns:trax.supervised.training.Loop: Training loop.'''output_dir = os.path.expanduser(output_dir) # trainer is an objectlr_schedule = trax.lr.warmup_and_rsqrt_decay(n_warmup_steps=1000, max_value=0.01)### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) ###train_task = training.TrainTask( labeled_data=train_gen, # The training generatorloss_layer=tl.CrossEntropyLoss(), # Loss function optimizer=trax.optimizers.Adam(0.01), # Optimizer (Don't forget to set LR to 0.01)lr_schedule=lr_schedule,n_steps_per_checkpoint=10)eval_task = training.EvalTask( labeled_data=eval_gen, # The evaluation generatormetrics=[tl.CrossEntropyLoss(), tl.Accuracy()] # CrossEntropyLoss and Accuracy)### END CODE HERE ###loop = training.Loop(TransformerLM(d_model=4,d_ff=16,n_layers=1,n_heads=2,mode='train'),train_task,eval_tasks=[eval_task],output_dir=output_dir)return loop4.模型评估
def next_symbol(cur_output_tokens, model):"""Returns the next symbol for a given sentence.Args:cur_output_tokens (list): tokenized sentence with EOS and PAD tokens at the end.model (trax.layers.combinators.Serial): The transformer model.Returns:int: tokenized symbol."""### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) #### current output tokens lengthtoken_length = len(cur_output_tokens)# calculate the minimum power of 2 big enough to store token_length# HINT: use np.ceil() and np.log2()# add 1 to token_length so np.log2() doesn't receive 0 when token_length is 0padded_length = 2**int(np.ceil(np.log2(token_length + 1)))# Fill cur_output_tokens with 0's until it reaches padded_lengthpadded = cur_output_tokens + [0] * (padded_length - token_length)padded_with_batch = np.array(padded)[None, :] # Don't replace this 'None'! This is a way of setting the batch dim# model expects a tuple containing two padded tensors (with batch)output, _ = model((padded_with_batch, padded_with_batch)) # HINT: output has shape (1, padded_length, vocab_size)# To get log_probs you need to index output with 0 in the first dim# token_length in the second dim and all of the entries for the last dim.log_probs = output[0, token_length, :]### END CODE HERE ###return int(np.argmax(log_probs))def greedy_decode(input_sentence, model):"""Greedy decode function.Args:input_sentence (string): a sentence or article.model (trax.layers.combinators.Serial): Transformer model.Returns:string: summary of the input."""### START CODE HERE (REPLACE INSTANCES OF 'None' with your code) #### Use tokenize()cur_output_tokens = tokenize(input_sentence) + [0]generated_output = [] cur_output = 0 EOS = 1 while cur_output != EOS:# Get next symbolcur_output = next_symbol(cur_output_tokens, model)# Append next symbol to original sentencecur_output_tokens.append(cur_output)# Append next symbol to generated sentencegenerated_output.append(cur_output)print(detokenize(generated_output))### END CODE HERE ###return detokenize(generated_output)