pdf:http://de.arxiv.org/pdf/1406.2661
code:https://github.com/goodfeli/adversarial
摘要
我们提出了一个新的框架,用于通过对抗来估计生成模型过程中,我们同时训练两个模型:生成模型G
捕获数据分布,以及判别模型D样本来自训练数据而非G的概率。训练G的过程是最大程度地提高D犯错的可能性。 这个
框架对应于一个两人零和游戏。 在任意空间功能G和D,存在唯一的解决方案,其中G恢复训练数据
分布和D等于12无处不在。 在定义了G和D的情况下通过多层感知器,可以通过反向传播训练整个系统。
不需要任何马尔可夫链或展开的近似推理网络在训练或样本生成过程中。 实验证明通过定性和定量评估框架的潜力
生成的样本。
1.简介
深度学习的希望是发现表示概率的丰富的,层次化的模型[2]分布在人工智能应用中遇到的各种数据,例如自然图像,包含语音的音频波形以及自然语言语料库中的符号。到目前为止,深度学习中最引人注目的成功涉及判别模型,通常是那些将高维,丰富的感觉输入映射到类别标签[14,20]。这些惊人的成功主要基于反向传播和dropout算法,使用分段线性单位[17,8,9]的梯度特别良好。深度生成模型的的影响比较小,因为难以近似许多难以解决的概率计算在最大似然估计和相关策略中出现,并且由于难以利用生成上下文中分段线性单元的好处。我们提出了一种新的生成模型避免这些困难的估算程序。
在提出的对抗网框架中,生成模型与对手形成了对抗:判别模型,用于学习确定样本是来自模型分布还是来自模型分布数据分发。 生成模型可以被认为类似于伪造者团队,试图生产假货币并在未经检测的情况下使用它,而歧视模型是类似于警察,试图发现假币。 此游戏中的竞争推动双方都改进自己的方法,直到假冒品与真品无法区分为止文章。
该框架可以针对多种模型和优化产生特定的训练算法算法。 在本文中,我们探讨了生成模型生成样本时的特殊情况通过使随机噪声穿过多层感知器,判别模型也是多层感知器。 我们将此特殊情况称为对抗网。 在这种情况下,我们可以训练两种模型都仅使用非常成功的反向传播和辍学算法[16],仅使用正向传播从生成模型中抽取样本。 不必使用近似推断或马尔可夫链。
2.相关工作
直到最近,大多数有关深度生成模型的工作都集中在提供参数化模型的模型上。概率分布函数的规范。然后可以通过最大化模型来训练模型对数似然。在这个模型家族中,也许最成功的是博尔兹曼机器[25]。这种模型通常具有难解的似然函数,因此需要似然梯度的许多近似。这些困难推动了发展“生成机”的模型-模型未明确表示可能性,但能够生成所需分布的样本。生成随机网络[4]是可以通过精确的反向传播而不是大量近似进行训练的生成机Boltzmann机器需要。这项工作扩展了生成机器的概念通过消除生成随机网络中使用的马尔可夫链。
通过生成过程反向传播衍生物,我们发现:
![]()
1132/5000
在我们进行这项工作时,我们还没有意识到Kingma和Welling [18]和Rezende等。 [23]开发了更通用的随机反向传播规则,允许反向传播通过具有有限方差的高斯分布,并反向传播至协方差参数以及均值。这些反向传播规则可以让人们了解条件发生器的方差,在这项工作中我们将其视为超参数。金马和Welling [18]和Rezende等。 [23]使用随机反向传播训练变分自动编码器VAE)。像生成对抗网络一样,变分自动编码器将可区分的具有第二神经网络的发电机网络。与生成对抗网络不同,第二个VAE中的网络是执行近似推理的识别模型。 GAN要求通过可见单位进行区分,因此无法对离散数据建模,而VAE要求通过隐藏单元进行区分,因此不能具有离散的潜在变量。其他类似VAE方法已经存在[12,22],但与我们的方法关系不大。
先前的工作还采用了使用判别标准来训练生成力的方法模型[29,13]。这些方法使用的标准对于深度生成模型来说是很难的。这些深度模型很难估计这些方法,因为它们涉及概率比不能使用下限概率的变分近似来近似。噪声对比估计(NCE)[13]涉及通过学习噪声模型来训练生成模型使模型有用的权重可用于区分固定噪声分布中的数据。用一个先前训练过的模型,因为噪声分布允许训练一系列递增模型质量。这可以看作是一种非正式竞赛机制,其精神与正式竞赛相似用于对抗网络游戏。 NCE的主要局限性在于其“歧视者”由噪声分布和模型分布的概率密度之比定义,因此需要通过两种密度进行评估和反向传播的能力。
先前的一些工作使用了使两个神经网络竞争的一般概念。最相关的工作是最小化可预测性[26]。在最小化可预测性方面,将神经网络中的每个隐藏单元训练为与第二个网络的输出不同,第二个网络的输出会根据所有其他隐藏单元的值来预测该隐藏单元的值。这项工作在以下三个重要方面与可预测性最小化不同:1)在这项工作中,网络之间的竞争是唯一的训练标准,并且足以单独训练网络。可预测性最小化只是一个正则化器,它鼓励神经网络的隐藏单元在完成其他任务时在统计上独立。这不是主要的培训标准。2)比赛的性质不同。在最小化可预测性方面,比较了两个网络的输出,其中一个网络试图使输出相似,而另一个网络试图使输出不同。有问题的输出是单个标量。在GAN中,一个网络会生成一个丰富的高维向量,该向量将用作另一个网络的输入,并尝试选择一个输入另一个网络不知道如何处理。 3)学习过程的规范不同。可预测性最小化被描述为目标函数要最小化的优化问题,学习接近目标函数的最小值。 GAN是基于最小极大博弈而不是优化问题,并且具有一种价值函数,一个代理商试图最大化,而另一个代理商试图最小化。游戏在一个鞍点处终止,该鞍点对于一个玩家的策略而言是最小值,对于另一个玩家的策略而言是最大值。
生成对抗网络有时与“对抗示例”的相关概念相混淆[28]。对抗性示例是通过直接在分类网络的输入上使用基于梯度的优化找到的示例,以查找与尚未分类的数据相似的示例。这与当前的工作不同,因为对抗性示例不是训练生成模型的机制。相反,对抗性示例主要是一种分析工具,用于显示神经网络以有趣的方式表现,通常会自信地进行分类,即使人类观察者无法察觉到两个图像的置信度也很高。此类对抗性示例的存在确实表明,生成式对抗性网络训练可能是低效的,因为它们表明,有可能使现代的歧视性网络自信地识别某个类别,而无需模仿该类别的任何人类可感知的属性。
3.对抗网络
当模型都是多层感知器时,对抗建模框架最容易应用。 为了了解发生器在数据上的分布,我们定义了一个先验的输入噪声变量,然后将到数据空间的映射表示为,其中G是由多层感知器表示的微分函数 带有参数。 我们还定义了第二个多层感知器,它输出一个标量。 表示x来自数据而非的概率。 我们训练D来最大化为G训练样本和样本分配正确标签的可能性。我们同时训练G来最小化。 换句话说,D和G玩以下具有值函数的两人博弈游戏:
![]()
在下一部分中,我们将对对抗网进行理论分析,本质上表明,当G和D被赋予足够的容量(即在非参数范围内)时,训练准则允许人们恢复生成数据的分布。 有关该方法的较不正式,较教学性的说明,请参见图1。 在实践中,我们必须使用迭代的数值方法来实现游戏。 在训练的内部循环中将D优化以完成是计算上的问题,并且在有限的数据集上会导致过度拟合。 取而代之的是,我们在优化D的k个步骤和优化G的一个步骤之间交替进行。只要G的变化足够缓慢,就可以使D保持在其最佳解附近。 该过程在算法1中正式提出。
在实践中,公式1可能无法为G提供足够的梯度来学习。 在学习的早期,当G较差时,D可以以高置信度拒绝样本,因为它们明显不同于训练数据。 在这种情况下,达到饱和。 与其训练G以使
最小,我们可以训练G以使
最大化。 该目标函数导致G和D动力学的相同固定点,但在学习早期就提供了更强的梯度。
4.理论结果
生成器G隐式地将概率分布定义为当
时获得的样本G(z)的分布。 因此,如果给定足够的容量和训练时间,我们希望算法1收敛到一个好的
估计量。 本部分的结果在非参数设置中完成,例如 我们通过研究概率密度函数空间中的收敛性来表示具有无限容量的模型。
我们将在第4.1节中显示,此博弈游戏具有的全局最优值。 然后,我们将在4.2节中展示算法1优化公式1,从而获得所需的结果。

图1 通过同时更新判别分布(D,蓝色,虚线)来训练生成对抗网络,以便区分生成数据的分布(黑色,虚线)的样本与生成分布
的样本(绿色,实线)。下方的水平线是从
中采样的域,在这种情况下是均匀的。上面的水平线是
的域的一部分。向上的箭头表示映射
如何将非均匀分布
施加到转换后的样本上。 G在高密度区域收缩,在
低密度区域膨胀。(a) 考虑一个接近收敛的对抗对:
与
相似,D是部分准确的分类器。(b)在算法的内部循环中,训练D来区分数据中的样本,收敛到
。 (c)在更新G之后,D的坡度已引导
流向更可能归类为数据的区域。 (d)经过几个步骤的训练,如果G和D具有足够的能力,则它们将达到无法提高的点,因为
。鉴别器无法区分两个分布,即
。

4.1  全局优化
全局优化
我们首先考虑任何给定生成器G的最佳鉴别符D。
命题1:对于固定的G,最优判别器D为:
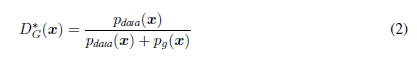
证明: 给定任何生成器G,鉴别器D的训练准则是使量的值最大化。
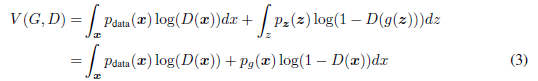
对于任何,函数
在[0,1]区间中的
达到最大值。 鉴别符不需要在
之外定义,包括证明。
请注意,D的训练目标可以解释为最大化对数似然率以估计条件概率,其中Y表示x是来自
(y = 1)还是来自
(y = 0) )。 公式1中的博弈游戏可以重新表示为:
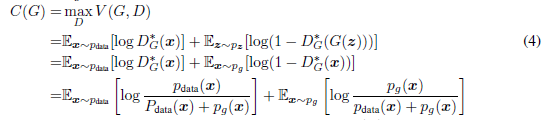
定理1.当且仅当时,才能达到虚拟训练准则
的全局最小值。 此时,
达到
的值。
证明. 对于,
(考虑式2)。 因此,通过检查等式4, 在
时,我们发现
。这是
的最佳可能值,仅当
时才达到, 观察到
![]()
通过从减去该表达式,我们得到:
![]()
其中,KL是Kullback-Leibler散度。 我们在前面的表达式中认识到模型的分布与数据生成过程之间的詹森-香农差异:
![]()
由于两个分布之间的詹森-香农散度总是非负的,并且当它们相等时为零,因此我们证明了是
的全局最小值,唯一的解是
,即生成模型完美地复制了数据分布。
4.2算法1的收敛
命题2。如果G和D具有足够的容量,并且在算法1的每个步骤中,都可以使鉴别器达到给定G的最优值,并更新pg以改进准则
![]()
then converges to
.
证明. 按照上述准则,将V(G; D)= U(pg; D)视为pg的函数。 注意,U(pg; D)在pg中是凸的。 凸函数的超导数包括在达到最大值时的函数导数。 换句话说,如果f(x)= sup 2A f(x)且f(x)在x中每个凸,则@f(x)2 @f if = arg sup 2A f(x)。 这等效于在给定相应G的情况下在最佳D下计算pg的梯度下降更新。supD U(pg; D)在pg中是凸的,具有在Thm 1中证明的唯一全局最优值,因此pg的更新足够小, pg收敛到px,得出证明。
实际上,对抗网络通过函数G(z; g)表示有限的pg分布族,并且我们优化g而不是pg本身,因此证明不适用。 但是,多层感知器在实践中的出色性能表明,尽管缺乏理论上的保证,它们还是可以使用的合理模型。
5. 实验
我们训练了对抗网络,包括MNIST [21],Toronto Face数据库(TFD)[27]和CIFAR-10 [19]。 生成器网络使用了整流器线性激活[17、8]和S型激活的混合,而鉴别器网络使用了maxout [9]激活。 辍学[16]被应用于训练鉴别器网络。 尽管我们的理论框架允许在发电机的中间层使用压降和其他噪声,但我们仅将噪声用作发电机网络最底层的输入。
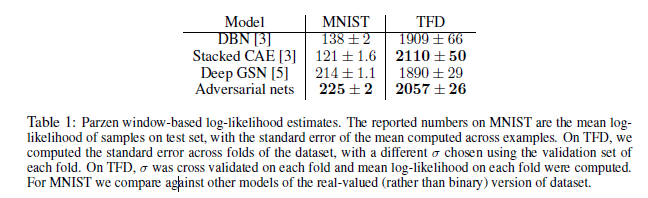
我们通过将高斯Parzen窗口拟合到G生成的样本并报告此分布下的对数似然来估计pg下测试集数据的概率。通过对验证集进行交叉验证来获得高斯参数。此过程在Breuleux等人中进行了介绍。 [7],用于各种生成模型,对于这些模型,确切的可能性难以把握[24、3、4]。结果报告在表1中。这种估计可能性的方法具有较高的方差,并且在高维空间中的效果不佳,但这是我们所知的最佳方法。可以采样但无法估计可能性的生成模型的进步直接激励着人们进一步研究如何评估这种模型。在图2和3中,我们显示了训练后从发电机网络中抽取的样本。尽管我们没有断言这些样本比通过现有方法生成的样本更好,但我们认为这些样本至少与文献中更好的生成模型具有竞争力,并强调了对抗框架的潜力。
6 优点与缺点
与以前的建模框架相比,此新框架具有优点和缺点。 缺点主要是没有pg(x)的明确表示,并且在训练过程中D必须与G很好地同步(特别是,在没有updateD的情况下G不能被过多训练,以避免出现“ Helvetica场景” 其中,G将太多的z值折叠成与x相同的值,以至于没有足够的多样性来建模pdata),就像必须在学习步骤之间保持Boltzmann机器的负链更新一样。 优点是不再需要马尔可夫链,仅使用backprop即可获得梯度,在学习过程中无需进行推理,并且可以将多种功能集成到模型中。 表2总结了生成对抗网络与其他生成建模方法的比较。
前述优点主要是计算上的。 对抗模型还可以从生成器网络中获得一些统计上的优势,该生成器网络不直接使用数据示例进行更新,而仅使用流经鉴别器的梯度进行更新。 这意味着输入的组成部分不会直接复制到生成器的参数中。 对抗网络的另一个优点是它们可以表示非常尖锐的分布,甚至可以是简并的分布,而基于马尔可夫链的方法则要求分布有些模糊,以使链能够在模式之间进行混合。
7 结论与未来工作
该框架允许多种扩展:


1. 可以通过将c作为输入添加到G和D来获得条件生成模型。
2. 通过训练辅助网络来预测给定x的z,可以执行学习到的近似推理。 这类似于由唤醒睡眠算法[15]训练的推理网络,但是具有的优点是,在生成器网络完成训练之后,可以为固定的生成器网络训练推理网络。
3. 通过训练一组共享参数的条件模型,可以近似地对所有条件条件进行建模,其中S是x的索引的子集。 本质上,人们可以使用对抗性网络来实现确定性MP-DBM的随机扩展[10]。
4.半监督学习:当有限的标记数据可用时,来自鉴别器或推理网络的功能可以提高分类器的性能。
5.效率提高:通过设计更好的协调G和D的方法或确定训练过程中样本z的更好分布,可以大大加快训练速度。