Behavior Selection Algorithms
An Overview
Michael Dawe, Steve Gargolinski, Luke Dicken,
Troy Humphreys, and Dave Mark
翻译:TraceYang,钱康来
4.1 介绍
当家用机玩家对他们购买的游戏要求更高的时候,为游戏编写AI系统变得越来越难了。同时,一些移动平台的小游戏也突然开始活跃了,这使得让AI程序员知道如何在短时间内获得最佳的行为变得重要起来。
即使是强力的机器上运行的复杂游戏,NPC的种类很多,简单的例如跑过去或猎杀的简单动物,复杂的可以让玩家用几个小时来交互的成熟的同伴角色。虽然这些示例的AI也是遵循着感觉-思考-行动的循环,但这个循环中“思考”部分仍然是不明确的。有各种算法来从中选择,每种算法都适合不同的用途。例如对于实现最近的家用机游戏里人类角色的最佳选择,并不适合来创建基于网络的棋盘游戏中的对手。
本文将介绍一些游戏行业中最为流行和已被验证过的决策算法,当可能是最佳使用选择时,提供这些选择的概述并简单介绍这些算法,以及使用场景。虽然本文并不是综合性资源,但希望对对AI程序员选择各种算法来使用来说是一个不错的介绍。
4.2 有限状态机(Finite-State Machines)
有限状态机(FSM)是现今游戏AI编程最常见行为建模算法。FSM的概念很简单,实现起来也很方便,因为可以用很小的开销产生出强力且灵活的AI架构。他们直观而且方便可视化,有助于非程序背景的成员之间的沟通,每个AI程序员都必须熟悉用FSM工作,并且可以意识到它们的优势与缺点。
FSM可以把NPC的所有AI分解成称作状态(State)的小的离散的部分。每个状态表示一个特定的行为或内部配置,而同时只有一个状态被认为是“有效”的。状态之间用转换(transitions)来连接。当满足特定条件时,有的链接会负责切换到新的有效状态。
FSM的一个吸引人的特性是很方便画出和可视化,每个圆角矩形代表一个状态,用箭头链接两个盒子来代表状态间的转换。转换箭头上的标签是触发转换的必要条件。实心圆代表初始状态,当FSM初次运行时会进入这个状态,假设我们为保卫城堡的守卫设计了FSM,如图4.1所示。
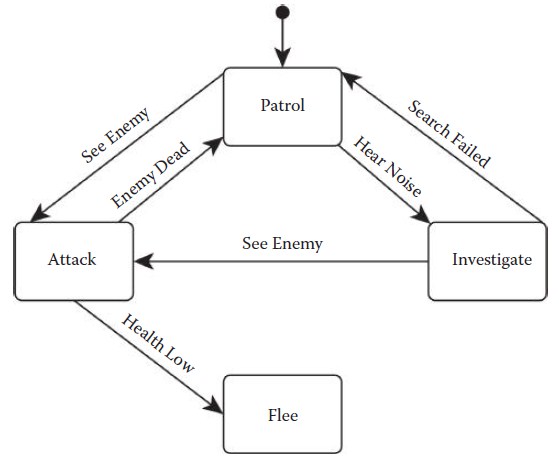
图4.1 FSM的图代表了一个守卫NPC的行为
我们的守卫NPC会在巡逻(Patrol)状态开始,并关注城堡中属于他负责的部分。如果他听到了什么声音,就会脱离巡逻状态,移动并调查(Inverstiage)一下噪音再返回巡逻状态。如果发现了敌人,就会进入攻击(Attack)状态以对抗威胁,在攻击时,如果他的生命值过低,他会逃跑保命(Flee),如果他打败了敌人,会返回巡逻状态。
虽然有很多可行的FSM的实现,这里看下算法实现的示例还是有帮助的,首先是FSMState类,我们每个具体状态都通过它来扩展:
class FSMState{virtual void onEnter();virtual void onUpdate();virtual void onExit();list<FSMTransition> transitions;};
每个FSMState都有3个不同的时机可以有机会执行逻辑,进入状态时,离开状态时,以及状态有效且没有发生转换的每次Tick的时候。每个状态还要负责保存FSMTransition对象的列表,表示的是这个状态的潜在转换。
class FSMTransition{virtual bool isValid();virtual FSMState* getNextState();virtual void onTransition();}
在我们的图表中,每个转换都由FSMTransition扩展而来。当满足转换条件时,isValid()函数的返回值会为true,然后用getNextState()得到要转换到的有效状态。当转移开始onTransition() 函数就有机会执行所有必要的行为逻辑,类似FSMState里的onEnter()函数。
最后,是FiniteStateMachine类:
class FiniteStateMachine{void update();list<FSMState> states;FSMState* initialState;FSMState* activeState;}
FiniteStateMachine类中包含了我们所有状态机的列表,以及初始状态和当前有效状态。还包含了核心的更新函数,负责调用每次Tick按下面的方式来运行我们的行为算法:
- 调用activeState.transtitions列表里每个状态转移的isValid() 函数,直到有isValid()返回true,或者没有状态转移发生。
- 如果找到有效的状态转移,那么:
- 调用activeState.onExit()
- 设置activeState为validTransition.getNextState()
- 调用activeState.onEnter()
- 如果没有找到有效的转换,则调用activeState.onUpdate()
有了这个结构,大致上就是设置转换和onEnter(), onUpdate(), onExit(), 和onTransition() 函数里填写来产生所需的AI行为。具体的实现完全依赖设计。例如我们的攻击状态触发一些对话, “他在哪,抓住他!”是在onEnter()里说的,使用onUpdate() 来定期的选择战略位置,移动到掩体,向敌人开火等等。而攻击和巡逻之间的转换的onTransition()函数里可以触发一些额外的对话,例如“威胁消除!”。
在开始编码你的FSM前,绘制一些像图4.1那样的表对定义行为逻辑和如何互相连结它们很有帮助。一旦理解了不同的状态和转换就可以开始编写代码了。FSM是灵活且强力的,但只有在理解了核心逻辑之后,才能开发出可用的效果。
4.3 分层有限状态机(Hierarchical Finite-State Machines)
FSM是非常有用的工具,但也有它的弱点。为NPC的FSM添加第2,3,4个状态通常在结构上还是很常见的,因为这些都需要与现有的状态之间关联转换(transition)的。但如果到了接近项目结束,FSM已经参杂了20,30,40个已有状态,那么要适应新的状态到已有的结构里是非常困难而且容易出错的。
也有一些常见的情况是FSM不适合处理的,例如处境行为(situational behavior)的重复使用。作为示例,图4.2展示了一个守夜人角色NPC负责保卫建筑的保险箱。
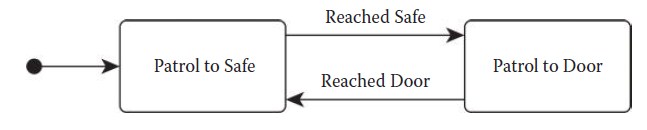
图4.2 FSM图表代表了警卫的行为
NPC会一直简单的在前门与保险箱之间巡逻。假如这时加入一个新的称作对话(Conversation )的状态,让守夜人可以接电话并暂停下来进行短暂通话,然后再回去巡逻。如果守夜人接电话时是向大门方向巡逻,我们希望电话结束后他能重新向门的方向巡逻。同样的,如果电话响起时他在向保险箱方向巡逻,电话结束后他也应该转移回到巡逻保险箱的状态。
因为我们需要知道接完电话后要回到哪个状态,那就要强制创建一个新的对话(Conversation )状态,每次都要复用这个行为,就如图4.3所示的那样。
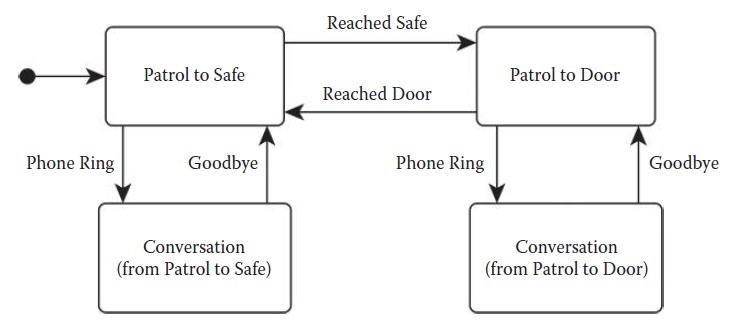
图4.3 我们的守夜人需要多个对话状态的实例
在上面这个简单的例子里我们需要两个对话行为才能完成,更复杂的FSM我们可能需要的就更多。每次都手动的添加这些我们希望重用的状态并不是个好注意也不够优雅。会导致状态和图表复杂度的爆炸,让已有的FSM更难以理解而新的状态也很难加入还容易出错。
值得庆幸的是,有种技术可以缓解这种结构性上的问题:那就是分层有限状态机(HFSM),在HFSM里,每个独立的状态都可以是一个完整的状态机。这种技术可以有效的把一个状态机在层次里分离成多个状态机。
回到前面守夜人的例子,如果我们把两个巡逻状态放入称作看守建筑的状态机里,那么就如图4.4所示,我们只需要处理一个会话状态。
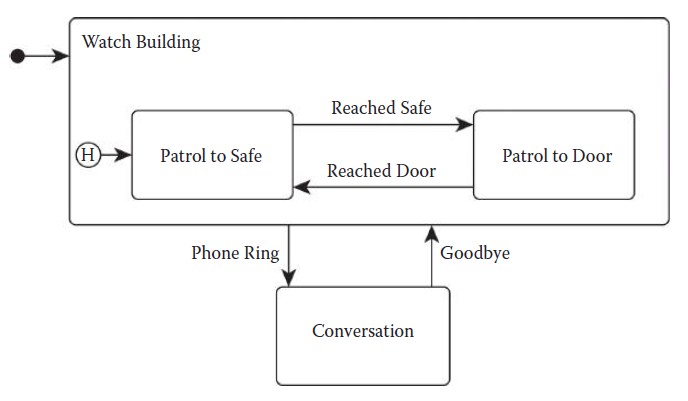
图4.4 HFSM解决了‘’对话“重复的问题。
这样可以工作的原因是HFSM增加了FSM里没有的额外的滞后(hysteresis )。在标准的FSM里,我们通常假定状态机是从初始状态开始,但在HFSM的嵌套状态机里并不是这样。注意图中被圈上的"H",指向的是‘’历史状态”。第一次进入嵌套看守建筑的状态机,历史状态会指定初始状态,但从那以后,它指向的是这个状态机当前有效的状态。
在我们的例子里,HFSM从看守大楼开始(由前面的实心圆和箭头指示),选择巡逻到保险箱(Patrol to Safe)为起始状态。如果NPC到达了保险箱并转换到巡逻大门(Patrol to Door),这时历史状态切换到巡逻大门。如果这时NPC这个时候响了,那么HFSM会退出巡逻大门和看守建筑,转换到对话状态。在对话结束后,HFSM会转换回看守建筑中的巡逻大门状态(通过历史状态)。
如你所看到的,这个设置不需要复制任何状态就实现了我们的设计目标。一般来说,HFSM提供了比状态布局更多的结构控制,允许更大,更复杂的行为分解到更小的更简单的碎片里。
HFSM的算法更新类似FSM,因为嵌套的状态机会增加递归复杂度。伪码实现相当复杂,超出本文讨论的范围了。需要可靠的细节实现的话,可以看下Ian Millington and John Funge的著作《Artificial Intelligence for Games》的5.3.9章节。
FSM和HFSM都是为解决AI程序员通常要面对的宽泛问题的极为有效的算法。就如讨论过的,使用FSM有很多优点,但也有一些缺点。FSM潜在的不利因素在于你所期望的结构或许不能优雅的来适应结构。而HFSM在一些情况下可以帮助缓解这些压力,如果FSM在状态与状态之间关联方面“转换过多”时,而HFSM的也不能提供帮助,其他的算法可能是更好的选择。
4.4 行为树(Behavior Trees)
行为树描述的是从根节点开始由行为组成的数据结构,这些行为是NPC可以独立执行的行动。每个行为都可以有子行为,这给了算法像树结构一样的特征。
每个行为都定义了先决条件(precondition),来指定代理在申请条件下执行行为,以及当执行行为时代理要实际做的行动。算法从树的根节点开始,并检查行为的先决条件,依次决策每个行为。在树的每一层,只能有一个行为被选择,所以如果一个行为被执行了,他的兄弟行为就不需要检查了,而它的子行为仍然要被检查。相反,如果行为的先决条件并没有返回true,那算法就会跳过检查它的子行为,并转移到下个兄弟行为。一旦到达树的终点,算法会让优先级最高的行为运行,并依次执行每个行动。
算法按下面的顺序来执行行为树:
- 把根节点(root node)作为当前节点(current node)
- 还有当前节点存在
- 运行当前节点的先决条件(precondition)
- 如果先决条件返回true
- 把节点加入到执行列表
- 设置节点的子节点作为当前节点
- 如果返回不为true
- 设置节点的兄弟节点作为当前节点
- 运行所有在执行列表里的行为
行为树的真正的优势在于它的简洁,因为它简单的性质,基本算法可以快速的实现。因为树是无状态的,算法不需要记忆它前一个行为来决定当前帧要执行的行为。此外写入的行为可以(也应该)完全不知道彼此,所以,从角色的行为树里添加或删除行为不会影响树其余部分的运行。这就减轻了FSM的每个状态都需要知道和其他状态的转换准则这个常见问题。
可扩展性也是行为树的一个优点。让它可以很容易的从基本算法的描述开始,再开始添加额外的功能。通常我们在on_start/on_finish这两个函数里会添加行为树行为。也可以实现不同的行为选择器(selectors)。例如,父行为可以指定不选择一个子行为来运行,而是让所有的子行为都运行一次,或者是随机选择一个它的子行为来运行。事实上,如果需要的,子行为可以基于功能系统(utility system)类型的选择器来运行。先决条件也可以响应事件来触发,给予行为树反应代理的刺激。另外一种流行的扩展是指定个别行为的非排他性,意味着如果他们的前决条件运行了,行为树还是要继续检查这层里其他兄弟行为。
尽管行为树简单和强力,但并不是总是选择算法的最佳选择。因为每次都是必须是从选择行为的根开始运行,它的运行时间通常要比FSM要长,而且随意的实现会造成大量条件语句,这样可能会非常慢,这取决于你的运行平台。另一方面,评估树里的每一个可能的行为可能会影响到其他需要处理能力的事项这点也是限制因素。两种算法都可以是算法的有效实现,因此程序员不得不去决定哪个是最好的。
因为行为自身是无状态的,所以当创建的行为是要记忆的话就必须要小心。例如,想象一个市民从战斗中逃离,一旦原理战斗区域,“逃跑”行为就会停止执行,而最高优先的行为可能会把市民带回到战斗区域,让市民在这两种状态里循环。虽然可以采取措施来防止这种问题,但传统的策划倾向更简单的去处理这种情况。
4.5 功能系统(Utility Systems)
大部分的AI逻辑以及相关的计算逻辑都是基于简单的布尔问题。例如代理体会问“能看到敌人么?”或者“还有弹药嘛?”这些都是纯粹的“是”或“否”的问题。布尔方程的决策往往是两极分化的。这点在前面的架构里也看到了,这种问题的结果通常会直接反应到一个行动上。例如:
if (CanSeeEnemy()){AttackEnemy();}if (OutOfAmmo()){Reload();}
即使当多个条件合并时,布尔方程往往会导致一个非常离散的结果集合。
if (OutOfAmmo() && CanSeeEnemy()){Hide();}
很多要决策的形式并不是太有条理,有很多问题是“是”或“否”来回答是不恰当的。例如我们要考虑敌人有多远,还有多少发子弹剩下,有多饿,受伤状况如何,或者是一些数量的连续值。相应的,这些连续值可以映射为如何去采取行动,而不是简单的一个基于功能的系统,会用测量,称重,合并,比率,等级以及排序等很多的考虑来决定潜在行为的可取性。使用上面的例子作介绍,我们可以评估有多强烈的需求去攻击,装弹和隐藏等等。
虽然功能技术可以用来实现其他架构中的转换逻辑,但基于功能构建一个完整的决策引擎也是非常可行的。而实时上,有时建立一个基于功能的AI是远优于其他方法的。可以让游戏包含很多可能的行动,以及不再是一个‘’正确”回答,而可以是基于大量竞争输入的一个更好的行动。在一些情况下,我们将超越简单的使用功能来测量或评价事物,而是它让驱动实际运行的决策机制。用另外一种方式来说明,不再说“这是你要做的一个行动”,功能系统会建议“这里有一些你可能去做的可选项”。
有个被充分证明的使用功能的例子是【模拟人生】,在这个游戏里,代理(也就是实际的模拟人),把他们环境中的信息在内部状态中结合起来,来达到一个每个潜在行为的更好的结果。举个例子,当我很饿的时候,即使只有很少的食物我也会去获得,反而当我不是很饿的时候就没有吸引力。此外,接近“大量“的食物仍然是一个高优先的选项,即便只是“有点饿"。注意“非常多”,“一些”,”很少”,“一点”实际都是在最大和最小范围间的值(典型的使用方法是0到1之间的浮点值)。
当要选择一个新动作时(通常是因为当前动作结束或一些打断系统),有一些候选方法可供选择。例如,可以对潜在行为的分数排序,简单的选择“最合适”的行为-也就是分数最高的那个。另外一个就是用分数作为种子权重来随机选择。通过转化随机数为权重可行性,最合适的行为有较高的机会被选择。当一个行为的适用性上升,它的分数会上升,被选择的机会也提高了。
另外一个基于功能架构比其他架构更适合的示例是角色扮演游戏(RPG)。通常在这类游戏里,代理体的选项通常是各种各样的,可能根据环境只是微秒的更好或更坏。例如,选择根据给予的敌人类型,代理体的状态,玩家状态来选择用什么武器,法术,道具或行为,可以是复杂的平衡行为。
另外,功能架构在一些游戏系统中是作为更经济的决策层来使用的。在RTS游戏的创造单位还是建筑的问题上,例如,这是有效组织消费,时间,和不同轴向上的优先级(例如“攻击”,“防御”)。基于功能的架构往往能更适应不断变化的游戏环境。因此比起更多脚本的模型,它可以更好的从混乱环境中恢复,脚本模型容易出现绝望的困惑(受影响太大),或者根本不受到环境影响。
这种适应性的主要原因是最佳分数是高度动态的。当游戏情况改变了-不管是环境变了还是代理的状况变了-大多数的行动分数都会改变。当分数变化后,他们就可以选择‘’合理“”的行为,这个结果受行为分数的起伏和流动,特别是与权重随机选择合并后,通常会产生动态的突发行为。
另一方面,和使用布尔转换决策逻辑的架构不同,功能系统通常会有不可预测性。因为基于特定的环境和上下文中行动有多少“意义”来进行选择,行动看起来也更加合理。这种不可预测下有它的优点和缺点。它可以改善可信度,因为在特定环境下可以发生各种行动,这可以让代理体看起来更加自然,而不仅仅是可预测的机械的基于if/then的模型。虽然在一些情况下是让人满意的,如果你要设计要求在特定时刻调的具体行为,就必须要用更多脚本行为来覆盖功能计算。
使用基于功能架构的另一个告诫就是,获得微妙差别和可反应性往往是有代价的。虽然核心架构通常是相对简单的设置,也可以简单的添加新的行为,它们还是有一些挑战的。很少有行为会在基于功能系统中孤立,相反的,它是被添加到一堆其他的有想法的潜在行为里,相关的数学模型鼓励合适的行为“冒泡到顶部”。这个诀窍(功能系统)是兼顾所有模型来鼓励最合理的行为。比起科学更加艺术一些。与艺术一样,产生的结果也往往比单独使用简单科学的更加迷人。
更多基于功能系统,可以看下这些书里的文章。An Introduction to Utility Theory和Behavioral Mathematics for Game AI 。
4.6 目标导向的行动计划(Goal-Oriented Action Planners)
目标导向的行动计划(GOAP)技术是最早是Monolith’s Jeff Orkin与2005年在游戏F.E.A.R中创造的,并在多个游戏中使用,最近的游戏是正当防卫2( Just Cause 2 )和杀出重围3:人类革命(Deus Ex: Human Revolution)。GOAP来自于1970年首次开发的斯坦福研究院AI解决问题方法(STRIPS)。一般来说,STRIPS(以及GOAP)允许AI系统通过提供的游戏世界如何去运作的描述,创建它自己的方法来解决问题,这些描述可以是可能行动的列表,每种行动可以被使用的需求(称作前提条件),以及行动的影响。这个系统接下来用象征性表现世界的初始状态,并需要设置一些需要达到的结果。在GOAP中,物体对象通常是根据预先设定的NPC希望完成的一组目标,通过一些例如优先级或状态转换的方法来被选择的。计划系统会确定一些列的行动,让代理来改变世界,从原来状态向包含着需要的满足目标的现实的状态转化。最经典的一种方式其实就是达到目标状态的关键路径,而目标是包含了所有客观实时最容易达到的状态。
GOAP通过“反向链查找(backwards chaining search)”这来工作,这是个奇特的短语,因为着要从你要实现的目标着手,确定有什么行动会变被要求产生,再找出要发生这些行动的先决条件。你继续以这种方式工作直到到达你的初始状态。这是一种在科学界已经失宠了的相当传统的方法,被依靠启发式搜索,修正以及其他的窍门的“正向链查找”替代了。向后查找是个牢固的苦力,然后尽管他不够优雅,比起现代技术它更容易理解和实现。
反向链查找的工作方式如下:
- 增加目标到未完成事情列表
- 对每个未完成事件
- 移除这个未完成事件
- 查找影响这个事件的行动
- 如果满足这个行动的先决条件
- 增加行动到计划
- 反向工作增加已支持的行动链到计划
- 如果不满足
- 增加先决条件到未完成事件列表
GOAP一个有意思的地方是允许计划系统忽视“上下文前提条件”,但在运行时必须满足让行动可以执行。这样就可以绕过某些世界的某些不容易用符号表示的特定方面-例如要保证开火前目标在视线内,这需要去访问一些非公开的信息,从而保证这个好处理。这使得计划GOAP产生是比较灵活的,调用的行动比起最基础的执行水准更有战术水平。也就是计划告诉你要做什么,但不是如何去做。例如,如何在开火前去创建视线细节说明可以被省略,也可以更被动的来处理。
让我们假设有一个典型的NPC战士角色,他的目标是杀死另外一个角色。我们用Target.Dead来表示我们的目标。为了让目标去死,我们的角色需要射击他(基础系统)。射击的先决条件是装备武器,假设我们的角色没有武器,就需要行动来给予这个角色武器,或者是在枪套里绘制一个。当然这有一个先决条件,武器必须是在角色的道具栏里。如果都满足的话,我们就可以创建一个简单的计划来绘制武器并射击。如果角色没有武器怎么办?我们将不得不找到方法来获取武器。如果寻找不能回溯和找到替代品来进行射击行动,或许附近有安装好的武器可以用来Target.Dead。在这两种情况下,明显提供一套世界里可以去做的全面的行动选择,我们就可以把它留给角色来决定去做什么,让动态和有趣的行为自然的出现,而不是在开发中想象和创建他们。
最后,要考虑游戏中武器的最大范围。作为上下文的前提条件,我们要求目标必须在射程内。策划不会去花时间来让它成为true,也不能,因为涉及了目标如何去移动的推理,但是也不会在条件满足前开火,反而是会去找其他替代战术或使用,例如射程更远的不同武器。
很多人喜欢用基于自动计划的方法来控制NPC。这样可以让设计人员专注于创建可以自我组成行为的简单的组件,从而简化了开发过程。也可以是“新奇”的解决方案,永远不会被团队预料,而作出的优秀故事往往是被玩家传颂的。GOAP本身仍是最容易实现自动计划的。从简单的科学观点来看,因为它的发展,艺术取得了长足的进步。也就是说,如果使用正确并提供了好的适应强的特殊定制的起点,它仍然是非常强大的技术。
值得注意的是,这种方法采用了以人物为中心的智能,移除了很多开发团队的创作和管理控制。成为我行我素的人,选择的计划更多的是完成角色本身的目标,而不会为了更加宏伟的目标譬如生成更加逼真的游戏体验,这个可能就会破坏实现安排好的整体计划(譬如一个士兵自己的计划不会将自己带到指定地点?)。
虽然使用已知的工程技术和有代表性的技巧可以避免这些类型的问题,但它的架构并不像行为树那么简单,后者允许需要的行为可以直接注入到角色的决策逻辑里。同时,GOAP方法比起基于层次任务网络更容易设计,因为GOAP中你只需要描述物体对象在世界中的流程。
GOAP和类似技术并没有银弹解决方案,但在合适情况下它们可以证实在创造现实计划的工作从不同种类的原始的世界状态开始行为和玩家可以完全交互的有身历其境感的角色上是非常强力的。
4.7 层次任务网络(Hierarchical Task Networks)
虽然GOAP是最有名的游戏计划,但其他类型的计划也应该得到普及。比如在 Guerrilla Games的杀戮地带2(KillZone)和High Moon Studios的变形金刚:塞伯坦之战中使用的层次任务网络系统。就像其他的计划一样,HTN的目标目标是找到NPC要执行的计划,而不是如何去做这个找到的计划。
HTN从初始的世界状态开始工作,主要任务是去我们需求要解决的问题。这个高层次任务会分解为越来越多的小任务,直到我们可以执行任务计划来解决问题为止。每个高层次任务都有多种方法完成,当前的世界状态来决定高层次任务将分解成那些小的任务组。这就允许可以在多个抽象层来决策。
而相对的反向计划的GOAP,是从想要的世界状态开始,反向移动到当前的状态的世界。HTN是前向计划,以为着它从当前世界状态开始,朝所需的方案来运作。计划从原始的状态出发,能够处理不同的基本事务。世界状态代表了问题空间的状态。游戏术语中里例子,可能是NPC在世界中的视口。游戏状态被分解成了多个属性,如健康度,耐力,敌人的健康,范围等等。这些知识的表述给予了计划去做事的理由。
接下来,我们有两个不同的任务:原始任务(primitive tasks)和复合任务(compound tasks)。原始任务是可以解决问题的可操作事项,游戏术语里可以是武器开火(FireWeapon),Reload(装弹)和移动到掩体(MoveToCover)。这些任务可以被世界状态影响,比如开火任务会使用弹药和装弹任务会重新装填武器。复合任务是更高层的任务,可以用不同方法完成,作为方法(Method)来描述。而方法是可以完成复合任务的一组任务,以及确定方法何时使用的前提条件。复合任务允许HTN根据世界的原因来决定采取何种行动。
要使用复合任务,我们可以建立HTN域,域是代表了所有解决我们的问题方法的大的任务层次,比如行为是如何作为NPC的类型,下面的伪代码显示了如何去构建计划。
- 将根复合任务加入到分解列表里
- 对每个在分解列表里的任务
- 移除任务
- 如果任务是复合的
- 找到世界中满足复合任务的方法
- 如果找到方法,将方法任务加入到分解列表
- 如果没有找到,恢复计划到最后分解任务之间的状态
- 如果任务是原始的
- 使用任务影响到当前的世界状态
- 增加任务到最后的计划列表里
如前所述,HTN计划是从非常高层次的任务开始,不断的分解成小的更小的任务。这种分解是通过比较复合方法中每个方法在当前世界状态中的条件来掌控的。当我们最终遇到原始任务时,就把它加入到最后的计划里。因为每个原始任务都是可操作的步骤,我们可以用它们来影响世界状态,本质上就是不断往前推动。一旦分解列表空了,我们就有了整套的游戏计划,或者没有计划而退出离开。
接下来演示HTN是如何工作的,假设游戏的士兵NPC需要写AI。根复合任务可以命名为BeSoldierTask。接下来,士兵是是否有敌人用来攻击会有不同的行为。因此,就需要两个方法来描述在这个情况下的做法。这种情况下的方法的任务可以叫做AttackEnemyTask,任务的方法定义了士兵可以攻击的不同方式。例如,如果士兵的步枪有弹药,就可以从掩体位置射击,如果没有弹药,他会冲向敌人使用匕首攻击,就需要给AttackEnemyTask写两种方法来完成这个任务。
我们越是深入士兵的行为,就有更多的形式和细化。域的组织结构自然的决定了一个人是如何描述他对另一个人的行为的。
因为HTN使用分层次结构描述行为,角色的塑造和论证都是用一种自然的方式,运行设计者更简单的读取HTN域,有助于程序和设计之间的协作。和其他的计划系统一样,AI实际的工作可以很好的保存在模块化的原始任务里,可以跨不同的AI角色来大量的重用。
因为HTN是通过图来搜索的,图的大小会影响搜索时间,但有两种方法来控制搜索大小。第一种是方法的条件可以用来过滤层次中的所有分支。这个在行为构建时可以天然的产生。还有一种方法是部分计划可以把复杂计划推迟到计划执行的时候。例如复合任务AttackEnemy的考虑。一种可能是子任务NavigateToEnemy接着MeleeEnemy,NavigateToEnemy 需要寻路计算,不仅昂贵,而且会被世界状态影响,这个可能会改变计划和执行。通过利用部分计划,把计划分成两种方法,而不是一个带两个子任务的方法:如果敌人在范围外就NavigateToEnemy,在范围内就MeleeEnemy 。这就运行我们当敌人超出范围时只构建NavigateToEnemy的一部分计划,缩短了搜索的时间。
另外需要注意的是,用户需要构建网络提供给HTN来工作。和GOAP风格的计划系统相比,这是一柄双刃剑。虽然这可以让设计师完成他们想要的非常有表现力的行为,但它消除NPC的去构建那些设计师可能没有想到事物的能力。根据你所创建的游戏,它可能会被认为是一个优势或弱点。
4.8 Conclusion
有了这些各种各样的行为选择算法,AI程序员就需要知道每一种方法的知识,以在给定情况下最好的来应用。哪那种方法对于给定的NPC是最好的,可以依赖游戏,NPC的知识状态,目标平台等等。虽然每个可用选项,都不是全面的对策,多了解一些选项从哪里开始也是非常宝贵的。花时间去仔细考虑游戏的需求,AI系统可以制作出最好的玩家体验并在开发时间和易用性上保持平衡。