����Ŀ¼
- Cascade R-CNN
-
- ����
- ���;��
- ��ʧ����
- ע��������
-
- CV�е�ע�������
- �Ӿ�ע���������ڷ��������е�Ӧ��
-
- SENet 2017 `ͨ��ע����` Look what
- CBAM 2018 `�ռ�ע����` Look where
- SKNet 2019 `������ע����`
- Self-attention�����������е�Ӧ��: Non-local Module
-
- Self-attention
- Non-local 2017
-
- ����
- non-local block
- NLNet����
- Non-local + Attention
-
- ����
- DANet 2018
-
- Position Attention Module��PAM��
- Channel Attention Module��CAM��
- �ܽ�
- GCNet 2019
-
- Simplified NL Block
- GCNetģ��
- ����
Cascade R-CNN
- Cascade R-CNN: Delving into High Quality Object Detection
- ���R-CNNϵ�е��������ģ�� ����ĸĽ�������
- ��Ҫ�����ƥ���������� multi-level �ķ�ʽ��
����
- ��� = ���� + ��λ
- ������˵����ǩ���DZ�ǩ��ֱ�Ӽ�����ʧ����
- ��λ�ͱȽ��鷳��Ŀǰ��Ҫ������������ع�������
- ��λ �Ƚ��鷳���ڣ�
anchor��Ԥ��Predict����ʵֵGt������֮����ڵı任��ϵ�� - ��ΪAnchor�кܶ�(HW x Anchor_num)����ֻ��������"��Ч��Anchor"
- ͨ�������ǿ�Gt��Anchor֮���IoU���趨��ֵ����0.5������0.5����Ϊ�ǡ�����������
- ʵ�����ϸ���˵ʹ��0.5����ֵƫ�ͣ���ɵĽ������ Figure 1(a)�������кܶ࣬��close�� false positives ��ͨ��˵�����кܶ��ظ���û�õĿ��Գ�Ϊ������������������������� Figure 1(b)����

- ��һζ�������ֵ��Ҳ��ʹ��Ч������Ϊ��
- ���IOU�ᵼ���������������٣�Ȼ��ģ�ͱȽϴᵼ�¹���ϡ�
- detector�϶�����ijһ��IOU��ֵ��ѵ���ģ�����inferenceʱ������anchor box֮����Щanchor box��ground truth box���и��ָ�����IOU��������ЩIOU��˵detector�Ǵ��Ż��ġ�����ɢ���ⲻ���Ż���
���;��

iterative BBox regression����ͼ(b)�����⣺�� ����head������һ���ģ�Ҳ����˵�������ijһ��IOU��ֵ������0.5�������Ż��ģ����ǵ�inferenceʱ��������IOU����0.5�Ժ����Ǵ��Ż�suboptimal �� �� ƫ���ۻ�����ͬ��head���ں���Ľṹ��˵�Ǵ��Ż���suboptimal ��Integral Loss����ͼ?��ȱ�㣺��ͬIOU��ֵ�ķֲ��Dz�����ģ������������ʧ�Dz������

��ʧ����
L(xt,g)=Lcls(ht(xt),yt)+��[yt��1]Lloc(ft(xt,bt),g)L\left(x^{t}, g\right)=L_{c l s}\left(h_{t}\left(x^{t}\right), y^{t}\right)+\lambda\left[y^{t} \geq 1\right] L_{l o c}\left(f_{t}\left(x^{t}, \mathbf{b}^{t}\right), \mathbf{g}\right) L(xt,g)=Lcls?(ht?(xt),yt)+��[yt��1]Lloc?(ft?(xt,bt),g)
- ����
bt=ft?1(xt?1,bt?1)\mathbf{b}^{t}=f_{t-1}\left(x^{t-1}, \mathbf{b}^{t-1}\right) bt=ft?1?(xt?1,bt?1)
ע��������
CV�е�ע�������
- Sequence Attention (NLP)
- ���ա�Attention is all you need��˵�ģ���Ϊһ�����ࣺ
- dot-product attention
- additive attention
- ����
- CBAM��Convolutional Block Attention Module

- multi-head attention����sequence attentionΪ������ͷattention��ʵ���Ͼ��Dz��кü���attention�����ϲ�
- ���self-attention����ִ�У����Ľ��concatenation��һ�����������8��ͷ��concat֮�ߴ���Ϊԭ����8�������������������С��ԭ���ijߴ�

- ���self-attention����ִ�У����Ľ��concatenation��һ�����������8��ͷ��concat֮�ߴ���Ϊԭ����8�������������������С��ԭ���ijߴ�
- transformer��transformer��һ����ȫ����attention�Ľṹ����ȫû��CNN��RNN��Ӱ�ӣ���Ҳ����˵����attention���Ʋ���������RNN����CNN�����Զ������ó��������γɽṹ��pytorch��1.2�汾�Ѿ�������transformer�㡣 �����ṹ��PS��Bertֻ�б���ṹ

�Ӿ�ע���������ڷ��������е�Ӧ��
- �ռ�������ͼƬ�еĵĿռ�����Ϣ����Ӧ�Ŀռ�任���Ӷ��ܽ��ؼ�����Ϣ��ȡ�������Կռ������������ɣ����д�֣�������Spatial Attention Module��
- ͨ�����������ڸ�ÿ��ͨ���ϵ��źŶ�����һ��Ȩ�أ���������ͨ����ؼ���Ϣ����ضȵĻ������Ȩ��Խ�����ʾ��ض�Խ�ߡ���ͨ����������mask�����д�֣�������senet, Channel Attention Module��
- ��������� �ռ����ע�����Ǻ�����ͨ�����е���Ϣ����ÿ��ͨ���е�ͼƬ����ͬ�ȴ��������������Ὣ�ռ���任����������ԭʼͼƬ������ȡ�Σ�Ӧ�����������������Ŀɽ����Բ�ǿ���� ͨ�����ע�����Ƕ�һ��ͨ���ڵ���Ϣֱ��ȫ��ƽ���ػ���������ÿһ��ͨ���ڵľֲ���Ϣ������������ʵҲ�DZȽϱ�������Ϊ�����Խ������˼·���Ϳ�����Ƴ�������ע��������ģ�͡�ͬʱ��ͨ��ע�����Ϳռ�ע�����������۴�֣���������BAM, CBAM��
SENet 2017 ͨ��ע���� Look what
- Squeeze-and-Excitation Networks
- SENet��Ҫ��ͨ����ʽ�ؽ�ģͨ��֮����������ϵ������Ӧ������Уͨ����������Ӧ�����仰˵������ѧϰ��ͨ��֮�������ԣ�ɸѡ�������ͨ����ע����������������������һ�������������Ч���ȽϺá�

- ��U����һ��Global Average Pooling��ͼ�е�Fsq(.)�����߳�ΪSqueeze�������������1x1xC�����پ�������ȫ���ӣ�ͼ�е�Fex(.)�����߳�ΪExcitation�������������sigmoid�������е�self-gating mechanism�����Ƶ�[0��1]�ķ�Χ�������ֵ��Ϊscale�˵�U��C��ͨ���ϣ� ��Ϊ��һ�����������ݡ�
- ���ֽṹ��ԭ������ͨ������scale�Ĵ�С������Ҫ��������ǿ������Ҫ�������������Ӷ�����ȡ������ָ���Ը�ǿ��
- ͨ��˵���ǣ�ͨ���Ծ����ĵ���feature map���д������õ�һ����ͨ����һ����һά������Ϊÿ��ͨ�������۷�����Ȼ�ķ����ֱ�ʩ�ӵ���Ӧ��ͨ���ϣ��õ�����������ԭ�еĻ�����ֻ������һ��ģ�顣
- ��Inception����

class SELayer(nn.Module):def __init__(self, channel, reduction=16):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)
CBAM 2018 �ռ�ע���� Look where
- Ϊ��ǿ���ռ��ͨ��������ά���ϵ���������������������Ӧ��ͨ���Ϳռ�ע��ģ�飬���ֱ���ͨ���Ϳռ�ά����ѧϰ��עʲô���������ע�����⣬ͨ���˽�Ҫǿ�������Ƶ���ϢҲ�����������ڵ���Ϣ������

- ��ResnetΪ������Bottleneck���£�
class Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(planes * 4)self.relu = nn.ReLU(inplace=True)self.ca = ChannelAttention(planes * 4)self.sa = SpatialAttention()self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)out = self.ca(out) * outout = self.sa(out) * outif self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return out
- ����ģ��

class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)self.relu1 = nn.ReLU()self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))out = avg_out + max_outreturn self.sigmoid(out)
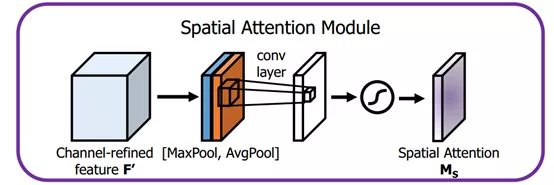
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()assert kernel_size in (3, 7), 'kernel size must be 3 or 7'padding = 3 if kernel_size == 7 else 1self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)x = torch.cat([avg_out, max_out], dim=1)x = self.conv1(x)return self.sigmoid(x)
SKNet 2019 ������ע����
- Selective Kernel Networks
- �����˵���Ҫ�ԣ�����ͬ��ͼ���ܹ��õ����в�ͬ��Ҫ�Եľ�����
- ������˵����ģ���ڳ��ֱ����������кܴ����������������е�ʵ��Ҳ֤ʵ���ڷ����������кܺõı��֡�
- SKNet�Բ�ͬͼ��ʹ�õľ�����Ȩ�ز�ͬ����һ����Բ�ͬ�߶ȵ�ͼ��̬���ɾ����ˡ�������Ҫ��Split��Fuse��Select��������ɣ�


- Split�����Ƕ�ԭ����ͼ������ͬ��С�ľ����˲��ֽ��о����Ĺ��̣���������ж����֧����������������efficient grouped/depthwise convolutions��BN��
- Fuse�����Ǽ���ÿ��������Ȩ�صIJ��֣�
- �������ֵ�����ͼ��Ԫ�����
U=U~+U^\mathbf{U}=\tilde{\mathbf{U}}+\widehat{\mathbf{U}} U=U~+U - Uͨ��ȫ��ƽ���ػ� (GAP) ����ͨ��ͳ����Ϣ���õ���Scά��ΪC * 1
sc=Fgp(Uc)=1H��W��i=1H��j=1WUc(i,j)s_{c}=\mathcal{F}_{g p}\left(\mathbf{U}_{c}\right)=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} \mathbf{U}_{c}(i, j) sc?=Fgp?(Uc?)=H��W1?i=1��H?j=1��W?Uc?(i,j) - ����ȫ�������ɽ��������z��ά��Ϊd *1����8��RELU�������B��ʾ������ (BN)����ά�� Ϊ�����˵ĸ���, Wά��ΪdxC, d����ȫ���Ӻ������ά��, L�����е�ֵΪ32��rΪѹ�����ӡ�
z=Ffc(s)=��(B(Ws))d=max?(C/r,L)\begin{array}{l} \mathbf{z}=\mathcal{F}_{f c}(\mathbf{s})=\delta(\mathcal{B}(\mathbf{W} \mathbf{s})) \\ d=\max (C / r, L) \end{array} z=Ffc?(s)=��(B(Ws))d=max(C/r,L)?
- �������ֵ�����ͼ��Ԫ�����
- Select�����Ǹ��ݲ�ͬȨ�ؾ����˼����õ����µ�����ͼ�Ĺ���
- ����softmax����ÿ�������˵�Ȩ��, ���㷽ʽ����ͼ��ʾ�����������������, �� ac + bc = 1�� z ��ά��Ϊ (d *1) A��ά��Ϊ (C *d) ��B��ά��Ϊ (C ?d),\left.^{*} \mathrm{d}\right),?d), ��a =A��=\mathrm{A} \times=A�� z��ά��Ϊ1 ?C0* \mathrm{C}_{0}?C0?
- Ac��BcΪA��B�ĵ�c������ (1*d)��acΪa�ĵ�C��Ԫ��, �����ֱ�õ���ÿ�������˵�Ȩ�ء�
ac=eAczeAcz+eBcz,bc=eBczeAcz+eBcza_{c}=\frac{e^{\mathbf{A}_{c} \mathbf{z}}}{e^{\mathbf{A}_{c} \mathbf{z}}+e^{\mathbf{B}_{c} \mathbf{z}}}, b_{c}=\frac{e^{\mathbf{B}_{c} \mathbf{z}}}{e^{\mathbf{A}_{c} \mathbf{z}}+e^{\mathbf{B}_{c} \mathbf{z}}} ac?=eAc?z+eBc?zeAc?z?,bc?=eAc?z+eBc?zeBc?z? - ��Ȩ��Ӧ�õ�����ͼ�ϡ�����V = [V1,V2,��, VC], Vc ά��Ϊ (H x W) ,���
Vc=ac?U~c+bc?U^c,ac+bc=1\mathbf{V}_{c}=a_{c} \cdot \tilde{\mathbf{U}}_{c}+b_{c} \cdot \hat{\mathbf{U}}_{c}, \quad a_{c}+b_{c}=1 Vc?=ac??U~c?+bc??U^c?,ac?+bc?=1

- ����
class SKConv(nn.Module):def __init__(self, features, WH, M, G, r, stride=1, L=32):super(SKConv, self).__init__()d = max(int(features / r), L)self.M = Mself.features = featuresself.convs = nn.ModuleList([])for i in range(M):# ʹ�ò�ͬkernel size�ľ���self.convs.append(nn.Sequential(nn.Conv2d(features,features,kernel_size=3 + i * 2,stride=stride,padding=1 + i,groups=G), nn.BatchNorm2d(features),nn.ReLU(inplace=False)))self.fc = nn.Linear(features, d)self.fcs = nn.ModuleList([])for i in range(M):self.fcs.append(nn.Linear(d, features))self.softmax = nn.Softmax(dim=1)def forward(self, x):for i, conv in enumerate(self.convs):fea = conv(x).unsqueeze_(dim=1)if i == 0:feas = feaelse:feas = torch.cat([feas, fea], dim=1)fea_U = torch.sum(feas, dim=1)fea_s = fea_U.mean(-1).mean(-1)fea_z = self.fc(fea_s)for i, fc in enumerate(self.fcs):print(i, fea_z.shape)vector = fc(fea_z).unsqueeze_(dim=1)print(i, vector.shape)if i == 0:attention_vectors = vectorelse:attention_vectors = torch.cat([attention_vectors, vector],dim=1)attention_vectors = self.softmax(attention_vectors)attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)fea_v = (feas * attention_vectors).sum(dim=1)return fea_v
- ˼ά��ͼ���������֣�

Self-attention�����������е�Ӧ��: Non-local Module
- soft-attention (��) / hard-attention (��RLѧϰ)
- �ڼ�����Ӿ��У��ܶ��������ع���(���磬���ࡢ��⡢�ָ����ģ�͡���Ƶ������)����ʹ��Soft Attention����Щ����Ҳ�����˺ܶͬ��Soft Attentionʹ�÷�������Щ������ͬ�IJ��ֶ��������������ѧϰȨ�طֲ�������ѧ������Ȩ��ʩ��������֮�Ͻ�һ����ȡ���֪ʶ�� ����ʩ��Ȩ�صķ�ʽ���в�𣬿����ܽ����£�
- ��Ȩ����������ԭͼ�ϣ�
- ��Ȩ�����������ռ�߶��ϣ�����ͬ�ռ������Ȩ��
- ��Ȩ����������Channel�߶��ϣ�����ͬͨ��������Ȩ��
- ��Ȩ������������ͬʱ����ʷ�����ϣ����ѭ���ṹ����Ȩ�أ�����������룬������Ƶ��صĹ���
Self-attention

- Self-attention�ṹ���϶��·�Ϊ������֧���ֱ���query��key��value��
- ��query_conv�����У�����Ϊ
B��C��W��H�����ΪB��C/8��W��H�� - ��key_conv�����У�����Ϊ
B��C��W��H�����ΪB��C/8��W��H�� - ��value_conv�����У�����Ϊ
B��C��W��H�����ΪB��C��W��H��
- ��query_conv�����У�����Ϊ
- ����ʱͨ����Ϊ������
- ��query��ÿ��key�������ƶȼ���õ�Ȩ�أ����õ����ƶȺ�����
�����ƴ�ӣ���֪�������ȣ� - ʹ��һ��softmax��������ЩȨ�ؽ��й�һ����
- ��Ȩ�غ���Ӧ�ļ�ֵvalue���м�Ȩ��͵õ�����attention��
- ��query��ÿ��key�������ƶȼ���õ�Ȩ�أ����õ����ƶȺ�����
class Self_Attn(nn.Module):""" Self attention Layer"""def __init__(self,in_dim,activation):super(Self_Attn,self).__init__()self.chanel_in = in_dimself.activation = activationself.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)self.gamma = nn.Parameter(torch.zeros(1))self.softmax = nn.Softmax(dim=-1)def forward(self,x):"""inputs :x : input feature maps( B X C X W X H)returns :out : self attention value + input featureattention: B X N X N (N is Width*Height)"""m_batchsize,C,width ,height = x.size()proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)energy = torch.bmm(proj_query,proj_key) # transpose checkattention = self.softmax(energy) # BX (N) X (N)proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X Nout = torch.bmm(proj_value,attention.permute(0,2,1) )out = out.view(m_batchsize,C,width,height)out = self.gamma*out + xreturn out,attention
Non-local 2017
- Non-local Neural Networks
- �ڲ�����������֮��������ϵ�Ļ����������һ�ַǾֲ���Ϣͳ�Ƶ�ע�������ơ���Self Attention
����
- �������г��˾���������ͳ��ȫ����Ϣʱ���ֵ������������£�
- ����Χ����������Ҫ�ۻ��ܶ�������������ѧϰЧ��̫�ͣ�
- ����������Ҫ�ۼƺ�������ҪС�ĵ����ģ����ݶȣ�
- ����Ҫ�ڱȽ�Զλ��֮�����ش�����Ϣʱ����������ʱ��ֲ����������ѡ�
- ��������ͼƬ�˲�������Ǿֲ���ֵ�˲�����˼���������һ������������ֱ��Ƕ�뵽��ǰ����ķǾֲ��������ӣ����Բ���ʱ��(һάʱ���ź�)���ռ�(ͼƬ)��ʱ��(��Ƶ����)������Χ������������Ƶĺô��ǣ�
- ��Ƚ��ڲ��϶ѵ�������RNN���ӣ��Ǿֲ�����ֱ�Ӽ�������λ��(������ʱ��λ�á��ռ�λ�ú�ʱ��λ��)֮��Ĺ�ϵ���ɿ��ٲ���Χ���������ǻ������ŷʽ���룬���ּ��㷽����ʵ����������ؾ���ֻ�����Ƿ���������ؾ���
- �Ǿֲ���������Ч�ʺܸ���Ҫ�ﵽͬ��Ч����ֻ��Ҫ���ٵĶѵ��㣻
- �Ǿֲ��������Ա�֤����߶Ⱥ�����߶Ȳ�����������ƿ��Ժ�����Ƕ�뵽Ŀǰ������ܹ��С�
non-local block
- ͨ�ù�ʽ��
yi=1C(x)��?jf(xi,xj)g(xj)y_{i}=\frac{1}{C(x)} \sum_{\forall j} f\left(x_{i}, x_{j}\right) g\left(x_{j}\right)yi?=C(x)1??j��?f(xi?,xj?)g(xj?) - xxx�������źţ�CV��ʹ�õ�һ����feature map
- iii �����������λ�ã���ռ䡢ʱ�����ʱ�յ�������������ӦӦ�ö�jjj����ö��Ȼ�����õ���
- fff ����ʽ����iii��jjj�����ƶ�
�����Զ������� - ggg ��������feature map��jjjλ�õı�ʾ
ӳ�亯�� - ���յ�yyy��ͨ����Ӧ����C(x)C(x)C(x)���б��������Ժ�õ���
- Ϊ�˼����⣬��������ggg����Ϊһ��1��11 \times 11��1�ľ���
- �������Զ������������У�
- Gaussian: f(xi,xj)=exiT?xj,C(x)=��?jf(xi,xj)f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)=e^{\mathrm{x}_{i}^{T} \cdot \mathrm{x}_{j}}, \mathcal{C}(x)=\sum_{\forall j} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)f(xi?,xj?)=exiT??xj?,C(x)=��?j?f(xi?,xj?)
- Embedded Gaussian: f(xi,xj)=e��(xi)T??(xj),C(x)=��?jf(xi,xj)f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)=e^{\theta\left(\mathrm{x}_{i}\right)^{T} \cdot \phi\left(\mathrm{x}_{j}\right)}, \mathcal{C}(x)=\sum_{\forall j} f\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)f(xi?,xj?)=e��(xi?)T??(xj?),C(x)=��?j?f(xi?,xj?)
- Dot Product: f(xi,xj)=��(xi)T??(xj),C(x)=�O{i�Oiis a valid index of x}�Of\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)=\theta\left(\mathrm{x}_{i}\right)^{T} \cdot \phi\left(\mathrm{x}_{j}\right), \mathcal{C}(x)=|\{i \mid i \text { is a valid index of } \mathrm{x}\}|f(xi?,xj?)=��(xi?)T??(xj?),C(x)=�O{ i�Oi is a valid index of x}�O
- Concatenation:
f(xi,xj)=ReLU?(wfT?[��(xi),?(xj)]),C(x)=�O{i�Oiis a valid index of x}�Of\left(\mathrm{x}_{i}, \mathrm{x}_{j}\right)=\operatorname{ReLU} \left(\mathrm{w}_{f}^{T} \cdot\left[\theta\left(\mathrm{x}_{i}\right), \phi\left(\mathrm{x}_{j}\right)\right]\right), \mathcal{C}(x)=|\{i \mid i \text { is a valid index of } \mathrm{x}\}|f(xi?,xj?)=ReLU(wfT??[��(xi?),?(xj?)]),C(x)=�O{ i�Oi is a valid index of x}�O
���൱��embedded��������ƴ����Ϊ��ReLU�����ȫ���Ӳ�����롣����visual reasoning���õıȽ϶ࡣ

- ������ƫ���ڸ߽����������non local layer, Ҳ�����ھ���ʵ�ֵĹ���������pooling������һ�����ټ�����
import torch
from torch import nn
from torch.nn import functional as Fclass _NonLocalBlockND(nn.Module):"""���ù���NONLocalBlock2D(in_channels=32),super(NONLocalBlock2D, self).__init__(in_channels,inter_channels=inter_channels,dimension=2, sub_sample=sub_sample,bn_layer=bn_layer)"""def __init__(self,in_channels,inter_channels=None,dimension=3,sub_sample=True,bn_layer=True):super(_NonLocalBlockND, self).__init__()assert dimension in [1, 2, 3]self.dimension = dimensionself.sub_sample = sub_sampleself.in_channels = in_channelsself.inter_channels = inter_channelsif self.inter_channels is None:self.inter_channels = in_channels // 2# ����ѹ���õ�channel����if self.inter_channels == 0:self.inter_channels = 1if dimension == 3:conv_nd = nn.Conv3dmax_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))bn = nn.BatchNorm3delif dimension == 2:conv_nd = nn.Conv2dmax_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))bn = nn.BatchNorm2delse:conv_nd = nn.Conv1dmax_pool_layer = nn.MaxPool1d(kernel_size=(2))bn = nn.BatchNorm1dself.g = conv_nd(in_channels=self.in_channels,out_channels=self.inter_channels,kernel_size=1,stride=1,padding=0)if bn_layer:self.W = nn.Sequential(conv_nd(in_channels=self.inter_channels,out_channels=self.in_channels,kernel_size=1,stride=1,padding=0), bn(self.in_channels))nn.init.constant_(self.W[1].weight, 0)nn.init.constant_(self.W[1].bias, 0)else:self.W = conv_nd(in_channels=self.inter_channels,out_channels=self.in_channels,kernel_size=1,stride=1,padding=0)nn.init.constant_(self.W.weight, 0)nn.init.constant_(self.W.bias, 0)self.theta = conv_nd(in_channels=self.in_channels,out_channels=self.inter_channels,kernel_size=1,stride=1,padding=0)self.phi = conv_nd(in_channels=self.in_channels,out_channels=self.inter_channels,kernel_size=1,stride=1,padding=0)if sub_sample:self.g = nn.Sequential(self.g, max_pool_layer)self.phi = nn.Sequential(self.phi, max_pool_layer)def forward(self, x):''':param x: (b, c, h, w):return:'''batch_size = x.size(0)g_x = self.g(x).view(batch_size, self.inter_channels, -1)#[bs, c, w*h]g_x = g_x.permute(0, 2, 1)theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)theta_x = theta_x.permute(0, 2, 1)phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)f = torch.matmul(theta_x, phi_x)print(f.shape)f_div_C = F.softmax(f, dim=-1)y = torch.matmul(f_div_C, g_x)y = y.permute(0, 2, 1).contiguous()y = y.view(batch_size, self.inter_channels, *x.size()[2:])W_y = self.W(y)z = W_y + xreturn z
- �������л���һ�������IJ���Ҳ�����õ�ȫ����Ϣ���Ǿ���Linear�㣬ȫ���Ӳ㽫feature map��ÿһ�������Ϣ���������ںϣ�Linear���Կ���һ�������Non local������
NLNet����
- Non-local Neural Networksģ����Ȼ�������µIJ��㣺
- ֻ�漰����λ��ע����ģ�飬��û���漰���õ�ͨ��ע��������
- ���Կ����������ͼ�ϴ���ô����(batch,hxw,512)������Ƿdz����ڴ�ͼ������ģ�Ҳ����˵����������ͼ�ܴ����Ч�ʵ�����������Ȼ�������취����������ų߶ȣ�������������ʧ��Ϣ��������Ѵ����취��
- �Ľ�˼·

Non-local + Attention
����
- Non-local Network��NLNet��ʹ����ע������������ģԶ������������ÿ����ѯ�㣨query position����NLNet ���ȼ����ѯ�������е�֮��ijɶԹ�ϵ�Եõ�ע����ͼ��Ȼ��ͨ����Ȩ�͵ķ�ʽ�ۺ����е���������Ӷ��õ���˲�ѯ����ص�ȫ�������������ٷֱ�ȫ�������ӵ�ÿ����ѯ��������У����Զ�������Ľ�ģ���̡����ǣ�NLNet�����ż�����������⡣
- SENetģ���������SE block��ʹ��ȫ�������ĶԲ�ͬͨ������Ȩֵ�ر궨����ͨ���������е��������Dz������ַ�������û�г������ȫ����������Ϣ��CBAM��ע�������̷�Ϊ���������IJ��֣�ͨ��ע����ģ�飨look what���Ϳռ�ע����ģ�飨look where�����������Խ�Լ�����ͼ����������ұ�֤���������Ϊ���弴�õ�ģ�鼯�ɵ����е�����ܹ���ȥ������CBAM��Ҫ�ֹ����pooling������֪���ȸ��Ӳ�����
DANet 2018
- Dual Attention Network for Scene Segmentation
- DANet��һ�־����Ӧ��self-Attention�����磬��������һ����ע�����������ֱ�ռ�ά�Ⱥ�ͨ��ά���е�����������ϵ��
- �����ָ���ҪԤ���ͼ���е����ص�����ijһĿ������࣬��ͼ���ĸ��Ӷ��������գ��ӽǣ��߶ȣ��ڵ��ȣ����ڳ�������������ص���б���ɺܴ����ѡ�
- ���������ָ�����¿ɷ�Ϊ�����������ͣ��� ͨ��ʹ�ö�߶������ںϵķ�ʽ��ǿ�ر�ı���������ռ�������ṹ (PSP��ASPP) ���߸߲�dz�������ں� (RefineNet)��������Щ��ʽû�п��ǵ���ͬ����֮��Ĺ���������������ڳ���������ȷʵʮ����Ҫ���� ���� RNN ���繹����������Χ�����������������ֹ������������� RNN �� long-term memorization��
- ˫��ע�����磨DANet��������Ӧ�ؼ��ɾֲ�������ȫ���������ڴ�ͳ������FCN֮�ϸ����������͵�ע����ģ�飬�ֱ�ģ��ռ��ͨ��ά���е������������

Position Attention Module��PAM��
- ͨ������λ�ô��������ļ�Ȩ����ѡ���Եؾۺ�ÿ��λ�õ����������۾�����Σ����Ƶ����������˴���ء�

Channel Attention Module��CAM��
- ͨ����������ͨ��ӳ��֮������������ѡ���Ե�ǿ�������������ͨ��ӳ�䡣

�ܽ�
- �ܵ���˵��DANet������Ҫ˼���� CBAM �� non-local ���ںϱ��Ρ���deep feature map����spatial-wise self-attention��ͬʱҲ����channel-wise self-attetnion���������������� element-wise sum �ںϡ�
- �� CBAM �ֱ���пռ��ͨ�� self-attention��˼���ϣ�ֱ��ʹ���� non-local ������ؾ��� Matmul ����ʽ�������㣬������ CBAM �ֹ���� pooling������֪���ȸ��Ӳ�����
GCNet 2019
- Global Context Network
- ���߶Բ�����������ϵ�ķ����ֳɣ�
- ��ע������������ģquery�ԵĹ�ϵ
NLNet - ��query-independent (��������Ϊ��query����) ��ȫ�������Ľ�ģ
SENet
- ��ע������������ģquery�ԵĹ�ϵ
- ���߾�������������ȱ����
- NLNet���Dz�����ע������������ģ���ضԹ�ϵ��Ȼ��NLNet����ÿһ��λ��ѧϰ����λ��������attention map������˴����ļ����˷�
- SENet��ȫ�������ĶԲ�ͬͨ������Ȩֵ�ر궨��������ͨ��������Ȼ��������Ȩֵ�ر궨�������ںϣ����ܳ������ȫ��������
- ���߶�NLNet������һ����������ֿ��ӻ�����Լ�ʵ������֤����non-local network��ȫ���������ڲ�ͬλ�ü�������ͬ�ģ������ѧϰ������λ��������ȫ��������
- ����ϣ���ܹ����ٲ���Ҫ�ļ����������ͼ��㣬�����SENet��ƣ������GCNet�ں������ߵ��ŵ㣬���ܹ�����NLNet��ȫ�������Ľ�ģ���������ܹ���SENetһ��������
Simplified NL Block

- ��NL Block�Ĺ�ʽ�������£�
zi=xi+��j=1Npexp?(Wkxj)��m=1Npexp?(Wkxm)(Wv?xj)\mathbf{z}_{i}=\mathbf{x}_{i}+\sum_{j=1}^{N_{p}} \frac{\exp \left(W_{k} \mathbf{x}_{j}\right)}{\sum_{m=1}^{N_{p}} \exp \left(W_{k} \mathbf{x}_{m}\right)}\left(W_{v} \cdot \mathbf{x}_{j}\right)zi?=xi?+j=1��Np??��m=1Np??exp(Wk?xm?)exp(Wk?xj?)?(Wv??xj?)- WkW_{k}Wk? �� WvW_{v}Wv? ��ʾΪ����ת������
- ��һ��������

- ��ʽ
zi=xi+Wv��j=1Npexp?(Wkxj)��m=1Npexp?(Wkxm)xj\mathbf{z}_{i}=\mathbf{x}_{i}+W_{v} \sum_{j=1}^{N_{p}} \frac{\exp \left(W_{k} \mathbf{x}_{j}\right)}{\sum_{m=1}^{N_{p}} \exp \left(W_{k} \mathbf{x}_{m}\right)} \mathbf{x}_{j}zi?=xi?+Wv?j=1��Np??��m=1Np??exp(Wk?xm?)exp(Wk?xj?)?xj? - ������֮��, 1x1���� WvW_{v}Wv? ��FLOPs�� O(HWC2)\mathcal{O}\left(\mathrm{HWC}^{2}\right)O(HWC2) ���� O(C2)\mathcal{O}\left(\mathrm{C}^{2}\right)O(C2)
- ��non-local block�ĵڶ����Dz���λ�������ģ�����λ�ù�����һ���ˣ�����ֱ�ӽ�ȫ�������Ľ�ģΪ����λ�������ļ�Ȩƽ��ֵ��Ȼ��ۼ�ȫ��������������ÿ��λ�õ������ϡ�
GCNetģ��
- ���������һ���µ�ȫ�������Ľ�ģ��ܣ�global context block(��дGCNet)���ܹ���Non-local blockһ��������Ч�ij��������������ܹ���SE blockһ��ʡ������

- global attention pooling���������Ľ�ģ��
- bottleneck transform������ͨ����������
- broadcast element-wise addition���������ںϡ�
- ��Ϊ����bottleneck transform�������Ż��Ѷȣ�������ReLUǰ������һ��layer normalization��(�����Ż��Ѷ�����Ϊ��������˷�����)
����
- GC block��ResNet�е�ʹ��λ����ÿ����Stage֮������Ӳ��֣��±���GC block�Ĺٷ�ʵ��(����mmdetection������)��
import torch
from torch import nnclass ContextBlock(nn.Module):def __init__(self,inplanes,ratio,pooling_type='att',fusion_types=('channel_add', )):super(ContextBlock, self).__init__()valid_fusion_types = ['channel_add', 'channel_mul']assert pooling_type in ['avg', 'att']assert isinstance(fusion_types, (list, tuple))assert all([f in valid_fusion_types for f in fusion_types])assert len(fusion_types) > 0, 'at least one fusion should be used'self.inplanes = inplanesself.ratio = ratioself.planes = int(inplanes * ratio)self.pooling_type = pooling_typeself.fusion_types = fusion_typesif pooling_type == 'att':self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)self.softmax = nn.Softmax(dim=2)else:self.avg_pool = nn.AdaptiveAvgPool2d(1)if 'channel_add' in fusion_types:self.channel_add_conv = nn.Sequential(nn.Conv2d(self.inplanes, self.planes, kernel_size=1),nn.LayerNorm([self.planes, 1, 1]),nn.ReLU(inplace=True), # yapf: disablenn.Conv2d(self.planes, self.inplanes, kernel_size=1))else:self.channel_add_conv = Noneif 'channel_mul' in fusion_types:self.channel_mul_conv = nn.Sequential(nn.Conv2d(self.inplanes, self.planes, kernel_size=1),nn.LayerNorm([self.planes, 1, 1]),nn.ReLU(inplace=True), # yapf: disablenn.Conv2d(self.planes, self.inplanes, kernel_size=1))else:self.channel_mul_conv = Nonedef spatial_pool(self, x):batch, channel, height, width = x.size()if self.pooling_type == 'att':input_x = x# [N, C, H * W]input_x = input_x.view(batch, channel, height * width)# [N, 1, C, H * W]input_x = input_x.unsqueeze(1)# [N, 1, H, W]context_mask = self.conv_mask(x)# [N, 1, H * W]context_mask = context_mask.view(batch, 1, height * width)# [N, 1, H * W]context_mask = self.softmax(context_mask)# [N, 1, H * W, 1]context_mask = context_mask.unsqueeze(-1)# [N, 1, C, 1]context = torch.matmul(input_x, context_mask)# [N, C, 1, 1]context = context.view(batch, channel, 1, 1)else:# [N, C, 1, 1]context = self.avg_pool(x)return contextdef forward(self, x):# [N, C, 1, 1]context = self.spatial_pool(x)out = xif self.channel_mul_conv is not None:# [N, C, 1, 1]channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))out = out * channel_mul_termif self.channel_add_conv is not None:# [N, C, 1, 1]channel_add_term = self.channel_add_conv(context)out = out + channel_add_termreturn outif __name__ == "__main__":in_tensor = torch.ones((12, 64, 128, 128))cb = ContextBlock(inplanes=64, ratio=1./16.,pooling_type='att')out_tensor = cb(in_tensor)print(in_tensor.shape)print(out_tensor.shape)