Manipulating Node Similarity Measures in Networks论文阅读笔记、
1.基本概念
- P问题:可以在多项式时间内解决;
- NP问题:无法确定能否在多项式时间内解决,但是可以在多项式时间内验证。
- NP hard问题:所有的NP问题都能reduce到NP hard问题。证明A是NP难问题:对问题A给限制条件得到特例B;证明B是NPC问题(或利用Reducetion,用该问题求解另一个已知是NP难的问题)。
- NPC问题:是NP问题,所有的NP问题都可以约化到它。证明NPC问题:证3SAT问题可以归约到此问题。
- 参数算法:参数算法的初衷是,通过在问题中引入一个参数k,将算法的时间复杂度的指数部分限制在参数k上而不是整个输入大小n,只要参数k的大小控制在一定范围之内,算法的时间复杂度依然是整个问题输入的多项式。通过这种方法可以把一大批NP完全问题的可解范围扩大很多。
- 近似算法:在可行时间内找到一个近似解
常见NPC问题:超级马里奥、3 Dimensional Matching、Subset Sum、Partition、Recangle Packing、Jigsaw Puzzles。
常见近似算法案例:顶点覆盖、集合覆盖
论文涉及到的:
- 顶点覆盖问题,有FPT解,参数为k(要找的顶点数)
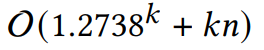
2.论文阅读
Abstract:
通过删边可以改变节点相似度,会影响到链接预测
流行的操纵节点相似度的计算都是np难问题
本文中提出了细粒度复杂度结果,从参数复杂度入手;一些是FPT,另外有一些是W1 hard,W2 hard问题
Introduction:
分析 social network有很多应用:节点相似度(链接预测)
问题:对手通过操纵网络达到打乱节点相似度有多难?应用:找恶意用户,找关键边
把操纵局部相似性问题抽象为三个图论问题,删边与邻居有关(局部相似度),任务变成删掉共同邻居
三个问题:Eliminating Similarity、Reducing Total Similarity、Reducing Maximum Similarity
- Eliminating Similarity:
- 输入:图、目标节点对、候选移边集合C、预算k
- 目标:能否在C中找到k条边,将其移除后保证目标节点对具有不相邻的邻居
- 问题:在抑制真实相似性的同时,可以保持少量相似性以实现不间断且更快的通信(不应该将相似度减少完)
- Reducing Total Similarity:
- 输入:输入:图、目标节点对、候选移边集合C、预算k、阈值t
- 目标:能否在C中找到k条边,将其移除后保证目标节点对中公共邻居总和最多为t
- 问题:可能有少量目标节点对的邻居很多(只考虑了整体,忽略了局部)
- Reducing Maximum Similarity
- 输入:图、目标节点对、候选移边集合C、预算k、阈值t
- 目标:在C中找到最多k条边,将其移除后保证所有目标节点对中共同用户最多为t
贡献:参数复杂度+近似算法;考虑的参数:最大可移除的边数k,|S|对希望消除相似性的边对,顶点的最大度,图的平均度;

问题1中存在一个集合W,要消除相似性的节点对都在里面。问题1可在多项式时间内解决。难度:问题三>问题二>问题一
preliminaries:
- 相似性度量:Jaccard相似度和Adamic/Adar index。二者都是局部相似度,因此降低相似度只需要减少共同邻居。
- 问题定义:计算出最小的边集合,保证移除后目标节点对无共同邻居。
定义2.1:Eliminating Similarity(G,S,C,k)

定义2.2:Reducing Total Similarity(定义2.1的推广,相当于加了一个阈值k)(G,S,C,k,t)

定义2.3:Reducing Maximum Similarity(定义2.2中,虽然整体少了,但是可能局部大)(G,S,C,k,t)
t表示S中顶点对的最大公共邻居数

论点2.4:后面会用到,我暂时也不懂什么意思(多项式时间内多对一简化??)

Algorithmic Results
结果:Eliminating Similarity 是FPT问题,参数k
1.将问题转换为了顶点覆盖问题,此问题有FPT解
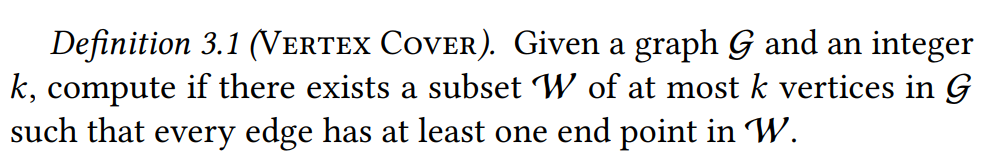

定理3.2:Eliminating Similarity复杂度和顶点覆盖一样
![]()
推论3.3:优化k 存在多项式内的解
定理3.4:定义了W集合(好像是说S中需要降低相似度的节点对都在W中,S是点对集合,W是点集合),主要是为了说明Eliminating Similarity可以在多项式时间内解决,可是刚刚不是已经证明了吗?

之后的工作关注参数|S|(前面是在关注k),用Lenstra的引理设计自己的FPT问题
引理3.5:这个引理是说有一种算法可以计算出最优解和可行解,是解决线性程序的,是FPT算法
the number of variable后面用到了variable的复杂度

接下来考虑Reducing Total Similarity问题
定理3.6:参数为|S|,FPT算法
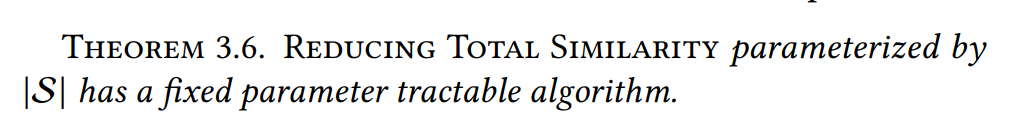
定理3.7:这是根据前面2.4推出来的(我的理解:Reducing Total Similarity更难都是FPT,所以Eliminating Similarity也是)

定理3.8:解释是说定理3.6可以同样被应用于Reducing Maximum Similarity问题,证明过程类似,只是换了两个不等式
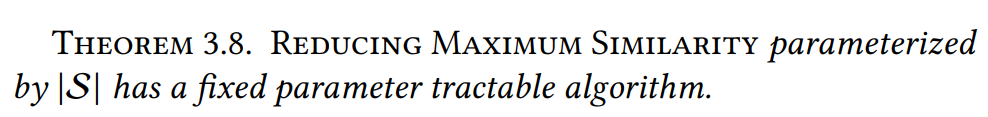
接下来考虑Reducing Maximum Similarity问题,会说明它是FPT算法,参数是最大度
定理3.9:Reducing Total Similarity的时间复杂度,和最大度有关;证明用到了动态规划

定理3.10:也是根据2.4推出来的,Eliminating Similarity同

HARDNESS RESULTS
参数为k时,Reducing Total Similarity是W1 hard问题;因此将该问题归约到局部顶点覆盖问题
定义4.1:k个顶点覆盖s条边,k为参数时该问题是W1 hard问题

定理4.2:Reducing Total Similarity W1 hard,证明过程用到了近似算法
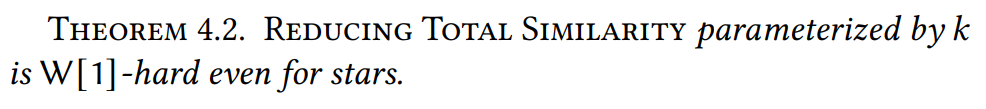
推论4.3:
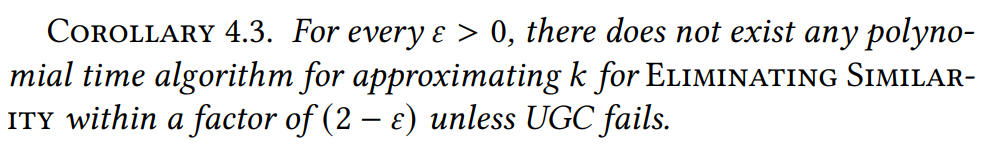
参数为k时,Reducing Maximum Similarity是W1 hard问题
定义4.4:集合覆盖问题

论点4.5:b是budget
![]()
定理4.6:
![]()
定理4.7:Reducing Maximum Similarity是NPC问题,参数为最大度时
![]()
考虑平均度作为参数
定理4.8:Eliminating Similarity是para-NP-hard问题,参数为平均度时
![]()
推论4.9:也是根据2.4推出来的

整个证明部分的总结如图:

Experiment Results
评估了FPT算法的性能,本文的算法称为FPTA
- DataSet:BA、ER 1000节点 2000边;真实数据集;

- baseline:Greedy(效果好,很耗时)、High Jaccard Similarity、Random
评估指标:删边数+运行时间


