������3�з����Խ�ά����
LLE�������ڵ�Ĺ�ϵ��Ȼ���ڵ�ά�ռ䱣�����ֹ�ϵ
Laplacian Eigenmaps����ͼ�ṹ�Ĺ�ϵ��Ȼ���ڵ�ά�ռ䱣�����ֹ�ϵ
t-SNE���ڷֲ��Ĺ�ϵ��Ȼ���ڵ�ά�ռ䱣�����ֹ�ϵ���������ò�ͬ���ƶȺ���ʵ��������ͬ��
��Ƶ pdf
Manifold Learning�����Խ�ά
��֮ǰ��Unsupervised Learning - Linear Methods˵��PCA��û���������Ա任�ģ��������棺

ͨ����ά������ʹ��ŷ�Ͼ��������롣��������ڸ�ά�ռ���ɫ��ͺ�ɫ��������������ұߵ�2ά��Ļ������ɫ��ͻ�ɫ����������������ݿ��ӻ�ʱ������������Ҫ�����ұߵĵ�ά�ȱ��ڹ۲�˴˾���ͽ��о��ࡣ
Locally Linear Embedding (LLE)
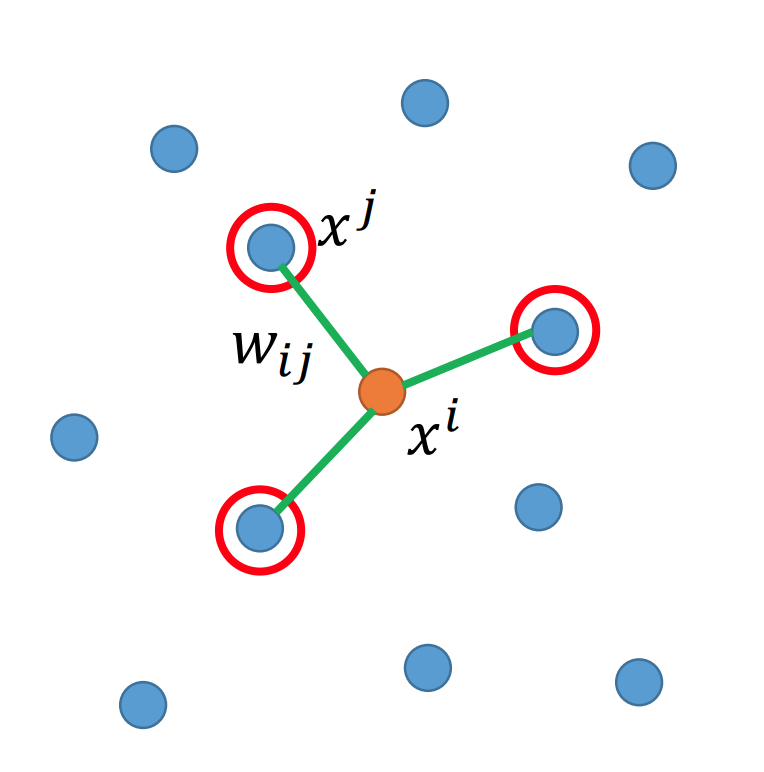
xjx^{j}xj��xix^{i}xi���ڵĵ㣬����֮��Ĺ�ϵ��wijw_{i j}wij?��ʾ��������ϣ����ʽ������С��
��i��xi?��jwijxj��2\sum_{i}\left\|x^{i}-\sum_{j} w_{i j} x^{j}\right\|_{2} i��?����������?xi?j��?wij?xj����������?2?
���Եõ���wijw_{i j}wij?�ͱ�ʾһ��Ȩ�أ�xjx^{j}xj����Χ�ĵ�����Ȩ��wijw_{i j}wij?����ʾxix^{i}xi
����wijw_{i j}wij?����

�ڵ�ά�ȵĿռ���һ��zjz^{j}zj�����Ȩ��wijw_{i j}wij?����ʾziz^{i}zi��
��i��zi?��jwijzj��2\sum_{i}\left\|z^{i}-\sum_{j} w_{i j} z^{j}\right\|_{2} i��?����������?zi?j��?wij?zj����������?2?
���Ծ�ʵ�ִӸ�άת��ά�����Ǻܶ�~~���˽�һ�¡�
��k��ѡ��Ƚ����У�
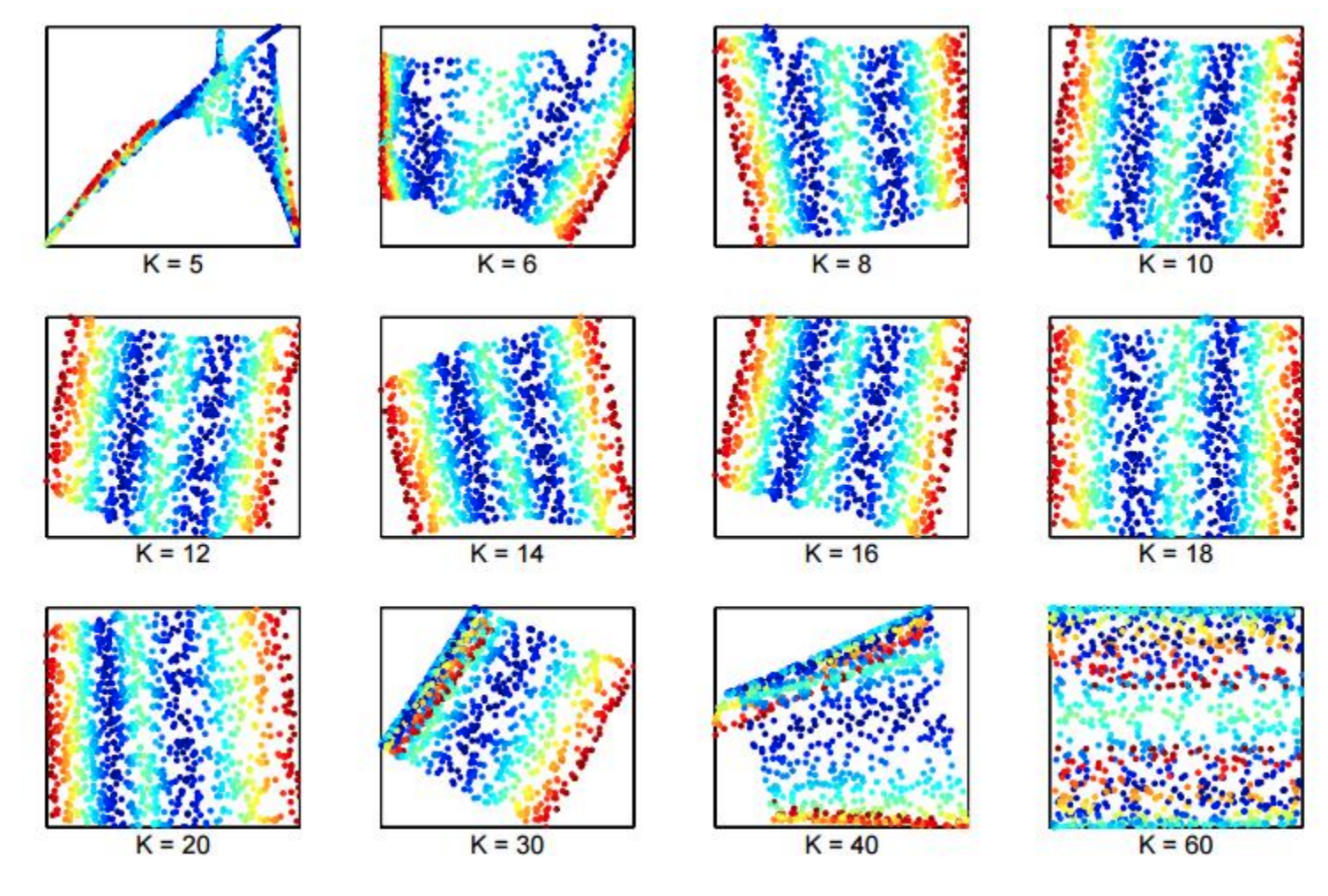
̫��̫Զ�����ǺܺõĹ�ϵ��
Laplacian Eigenmaps
��Semi-supervised�ᵽSmoothness Assumption��
���2��֮��ͨ�����ܶ�·����hightdensity path��ͨ������Ϊy1��y2�ǽӽ���
��Ȼ�������ڻ���ͼ�Ľṹ�ϼ�����ƾ��롣
���ƶ�s(xi,xj)s\left(x^{i}, x^{j}\right)s(xi,xj)���㣺
s(xi,xj)=exp?(?�á�xi?xj��2)s\left(x^{i}, x^{j}\right)=\exp \left(-\gamma\left\|x^{i}-x^{j}\right\|^{2}\right)s(xi,xj)=exp(?������?xi?xj����?2)
Ȼ��wi,j=s(xi,xj)w_{i, j} =s\left(x^{i}, x^{j}\right)wi,j?=s(xi,xj)����LLE˼�����ƣ��������֮���ϵwi,jw_{i, j}wi,j?���ڵ�ά�ռ���һ����zjz^{j}zj������ϣ��S������С��������ҵ���Ӧ��ziz^{i}zi���Ӷ�ʵ�ֽ�ά��
���Ǻ��ڰ�ලѧϰ��ͬ���ǣ�zj,ziz^{j}, z^{i}zj,zi��û�б�ǩ���ڰ�ලѧϰ�п���ͨ�����������һ���֣����������zi=zj=0z^{i}=z^{j}=\mathbf{0}zi=zj=0��ôS��һ����0���ǻ��������ġ�������Ҫ��z����Լ����
����ϣ����ά�ռ���Mά�ģ�����Щ����ɵľ�������ҲӦ��ҪΪM��
Span?{z1,z2,��zN}=RM\operatorname{Span}\left\{z^{1}, z^{2}, \ldots z^{N}\right\}=R^{M} Span{
z1,z2,��zN}=RM
T-distributed Stochastic Neighbor Embedding (t-SNE)
����ʹ��LLE�ķ����ܹ�ʹ��ͬ��ۼ�������ȱû��ʹ��ͬ��ֿ����������棺

t-SNEĿ�ľ���Ϊ�˽�������
t-SNE������
���xix_ixi?��xjx_jxj?�Ĺ�һ������(����һ����Ŀ�����ڲ�ͬά�ռ���бȽ�)��
P(xj�Oxi)=S(xi,xj)��k��iS(xi,xk)P\left(x^{j} \mid x^{i}\right)=\frac{S\left(x^{i}, x^{j}\right)}{\sum_{k \neq i} S\left(x^{i}, x^{k}\right)} P(xj�Oxi)=��k??=i?S(xi,xk)S(xi,xj)?
ͬ���ģ��ڵ�ά�ռ�Ҳ����ziz_izi?��zjz_jzj?�Ĺ�һ�����룺
Q(zj�Ozi)=S��(zi,zj)��k��iS��(zi,zk)Q\left(z^{j} \mid z^{i}\right)=\frac{S^{\prime}\left(z^{i}, z^{j}\right)}{\sum_{k \neq i} S^{\prime}\left(z^{i}, z^{k}\right)} Q(zj�Ozi)=��k??=i?S��(zi,zk)S��(zi,zj)?
����ϣ��һ�������Χ�ֲ��ڽ�ά�治�䣬���Կ�������Χ��Ĺ�һ�����������ֲ�������ϣ���ܵķֲ����ԽСԽ�á��������ֲ������õľ���KLɢ��(�����)�����Զ���ʽ����GD����z��
L=��iKL(P(?�Oxi)��Q(?�Ozi))=��i��jP(xj�Oxi)log?P(xj�Oxi)Q(zj�Ozi)\begin{array}{r} L=\sum_{i} K L\left(P\left(* \mid x^{i}\right) \| Q\left(* \mid z^{i}\right)\right) \\ \quad=\sum_{i} \sum_{j} P\left(x^{j} \mid x^{i}\right) \log \frac{P\left(x^{j} \mid x^{i}\right)}{Q\left(z^{j} \mid z^{i}\right)} \end{array} L=��i?KL(P(?�Oxi)��Q(?�Ozi))=��i?��j?P(xj�Oxi)logQ(zj�Ozi)P(xj�Oxi)??
ok���ص��������⣬t-SNEΪʲô���Ѳ�ͬ��������
�ؼ�����SSS��S��S^{\prime}S����һ����
S��Smoothness Assumptionһ����ŷʽ���뾭��RBF
S(xi,xj)=exp?(?��xi?xj��2)\begin{array}{l} S\left(x^{i}, x^{j}\right) \\ =\exp \left(-\left\|x^{i}-x^{j}\right\|_{2}\right) \end{array} S(xi,xj)=exp(?����?xi?xj����?2?)?
S��S^{\prime}S�������ı䣺
S��(zi,zj)=1/1+��zi?zj��2S^{\prime}\left(z^{i}, z^{j}\right)=1 / 1+\left\|z^{i}-z^{j}\right\|_{2} S��(zi,zj)=1/1+����?zi?zj����?2?
����S��S^{\prime}S����β�������ھ���Զ�������(�����)���ڱ���ͬ�ֲ�Ҳ�������ƶ�Ҫһ���Ļ�S��S^{\prime}S���ĺ���ֵ�����ĸ�Զ�����ھ�����������(����С)�����̫�ࣺ
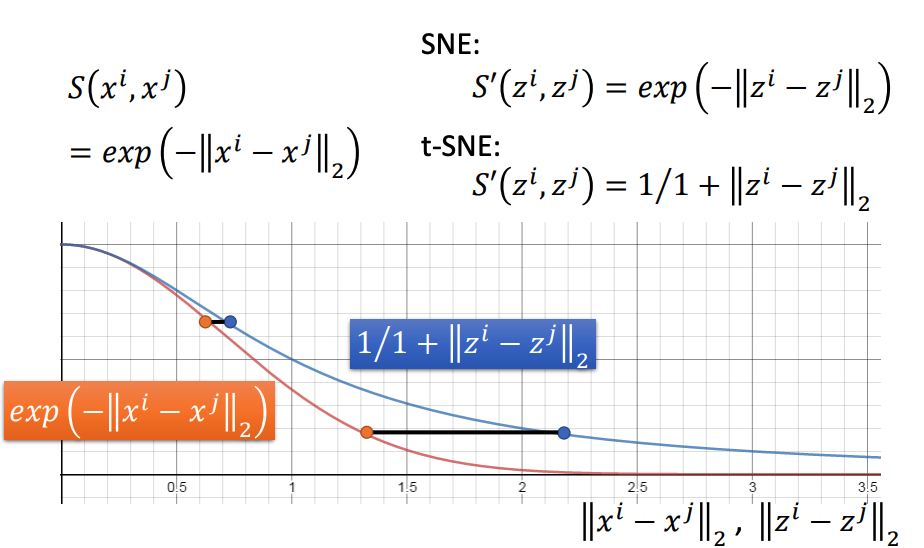
S��S^{\prime}S���������ı����SNE������
���ϲο��������ʦ��Ƶ��ppt������Ϊѧϰ�ʼǽ���ʹ��