最近要做行级别的手写文件检测工作,将CASIA-HWDB2.x(offline)数据进行合并,生成了page level的数据集,还带有相应的bbox。如果大家想交流ocr相关的工作可以加群(文章末尾):
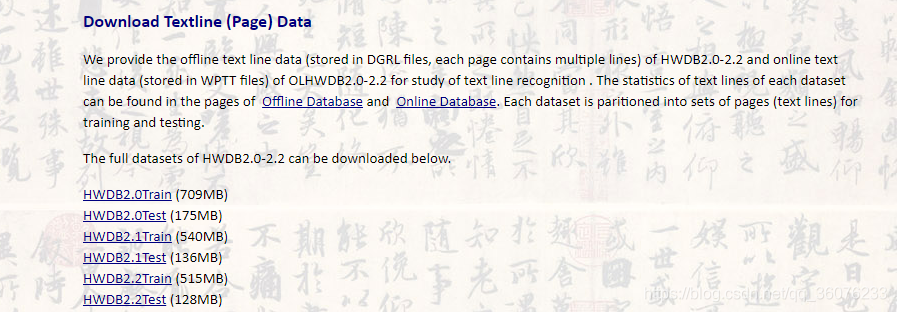
CASIA-HWDB2.x(offline)数据集下载地址:http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html
我所下载的是这一部分:
CASIA-HWDB2.x(offline)数据集解析可以参考:https://www.freesion.com/article/6894959465/
解析完后HWDB2.xTrain_images下的图片:

图片预览:
001-P16_0.jpg:

解析完后HWDB2.xTrain_label下的label:
label预览:
001-P16_0.txt:
2002年以来,国内企业家包括许多著名企业家在内涉嫌违法犯罪被捕入
现在进入主题,将解析好的图片拼接成整页的形式:
001-P16,page结果预览:

label预览:
671,1000,2660,1000,2660,1120,671,1120,2002年以来,国内企业家包括许多著名企业家在内涉嫌违法犯罪被捕入
500,1120,2591,1120,2591,1246,500,1246,狱的人数不断增多,此方面的报道也屡屡见诸极端。不是哪个被抓了,就
500,1246,2565,1246,2565,1347,500,1347,是哪个被判了,或者是这个案子开庭了,那个案子判决了。总之,几乎月月都有这样
500,1347,770,1347,770,1442,500,1442,的新闻。
667,1442,2660,1442,2660,1551,667,1551,企业家落马、判刑、入狱、甚至犯死罪被执行死刑了,媒体关注的焦点
500,1551,2633,1551,2633,1671,500,1671,往往不是法律问题,而更多的是企业家经营和管理上的问题。在媒体上发表
500,1671,2655,1671,2655,1769,500,1769,各种意见的,不乏经济学家、管理学家,却很少有法律专家来参与讨论。这是一种
500,1769,2624,1769,2624,1892,500,1892,不正常的现象。企业家不管在经营、管理上存在什么问题,最终的结局如果是
500,1892,2660,1892,2660,1984,500,1984,走进监狱,最终的结论如果是经由法院判决有罪,那么,最重要的应该是法律
500,1984,674,1984,674,2065,500,2065,问题!
page生成主要思路:
1.解析出来的图片的前缀都有唯一的标识,如001-P16_0.jpg,001-P16_1.jpg,...,001-P16_9.jpg,他们的唯一标识是001-P16,也就是说001-P16这一页分割成了0-10行级别的图片,如果恢复成整页,只要将这些图片排序按从上到下的顺序拼接即可。
2.被分割出来的图片我们把它称为segment,每个segment的width和height都不同,height先不用管,但从上到下拼接时,width是要保持一致的,取这些segments中最大的width,将小于max_width的segment都pad到相应的长度。
3.pad的时候由于段首和段位的长度明显要小于段间的长度,如果都pad到segment的前端或后端显然不合适,这时候做一个简单的判断,如果是开头就pad到segment的前端,如果是结尾或段中就pad到segment的后端。
4.最后将pad成page的图片在外围在pad上白色,这个可以自己选择,也可以不进行pad,根据个人需求进行选择。
label生成主要思路:
1.由行级别的bbox坐标和字符两个部分组成,可以根据自己需求改动,很灵活
2.先生成bbox的坐标再将每个segment的label读取写入新的page level的label中,bbox坐标生成看代码吧,怕写文字会有误解- -!
代码部分:
import numpy as np
import cv2
import os
from glob import glob
import re
from tqdm import tqdmdef get_char_nums(segments):nums = []chars = []for seg in segments:label_head = seg.split('.')[0]label_name = label_head + '.txt'with open(os.path.join(label_root,label_name), 'r', encoding='utf-8') as f:lines = f.readlines()nums.append(len(lines[0]))chars.append(lines[0])return nums, charsdef addZeros(s_):head, tail = s_.split('_')num = ''.join(re.findall(r'\d',tail))head_num = '0'*(4-len(num)) + numreturn head + '_' + head_num + '.jpg'def strsort(alist):alist.sort(key=lambda i:addZeros(i))return alistdef pad(img, headpad, padding):assert padding>=0if padding>0:logi_matrix = np.where(img > 255*0.95, np.ones_like(img), np.zeros_like(img))ids = np.where(np.sum(logi_matrix, 0) == img.shape[0])if ids[0].tolist() != []:pad_array = np.tile(img[:,ids[0].tolist()[-1],:], (1, padding)).reshape((img.shape[0],-1,3))else:pad_array = np.tile(np.ones_like(img[:, 0, :]) * 255, (1, padding)).reshape((img.shape[0], -1, 3))if headpad:return np.hstack((pad_array, img))else:return np.hstack((img, pad_array))else:return imgdef pad_peripheral(img, pad_size):assert isinstance(pad_size,tuple)w, h = pad_sizeresult = cv2.copyMakeBorder(img, h, h, w, w, cv2.BORDER_CONSTANT, value=[255, 255, 255])return resultif __name__=='__main__':label_root = r'G:\ocr\HWDB2.xTrain_label'label_det = r'G:\ocr\HWDB2.xTrain_fullLabels'pages_root = r'G:\ocr\HWDB2.xTrain_images'pages_det = r'G:\ocr\HWDB2.xTrain_fullpages'os.makedirs(label_root, exist_ok=True)os.makedirs(pages_root, exist_ok=True)pages_for_set = os.listdir(pages_root)pages_set = set([pfs.split('_')[0] for pfs in pages_for_set])for ds in tqdm(pages_set):boxes = []pages = []seg_sorted = strsort([d for d in pages_for_set if ds in d])widths = [cv2.imread(os.path.join(pages_root, d)).shape[1] for d in seg_sorted]heights = [cv2.imread(os.path.join(pages_root, d)).shape[0] for d in seg_sorted]max_width = max(widths)seg_nums, chars = get_char_nums(seg_sorted)pad_size = (500, 1000)w, h = pad_sizelabel_name = ds + '.txt'with open(os.path.join(label_det, label_name), 'w') as f:for i,pg in enumerate(seg_sorted):headpad = True if i==0 else True if seg_nums[i] - seg_nums[i-1]>5 else Falsepg_read = cv2.imread(os.path.join(pages_root, pg))padding = max_width - pg_read.shape[1]page_new = pad(pg_read, headpad, padding)pages.append(page_new)if headpad:x1 = str(w + padding)x2 = str(w + max_width)y1 = str(h + sum(heights[:i+1]) - heights[i])y2 = str(h + sum(heights[:i+1]))box = np.array([int(x1),int(y1),int(x2),int(y1),int(x2),int(y2),int(x1),int(y2)])else:x1 = str(w)x2 = str(w + max_width - padding)y1 = str(h + sum(heights[:i + 1]) - heights[i])y2 = str(h + sum(heights[:i + 1]))box = np.array([int(x1), int(y1), int(x2), int(y1), int(x2), int(y2), int(x1), int(y2)])boxes.append(box.reshape((4,2)))char = chars[i]f.writelines(x1 + ',' + y1 + ',' + x2 + ',' + y1 + ',' + x2 + ',' + y2 + ',' + x1 + ',' + y2 + ',' + char + '\n')pages_array = np.vstack(pages)pages_array = pad_peripheral(pages_array,pad_size)pages_name = ds + '.jpg'# cv2.polylines(pages_array, [box.astype('int32') for box in boxes], True, (0, 0, 255))cv2.imwrite(os.path.join(pages_det, pages_name),pages_array)群: