只能靠写博客来鞭策自己学习了
- 读取数据
-
- 读取数据库的数据
- 读取文件的数据
- 读取多个文件的数据
- 写入数据
-
- 写到数据库
- 写到文件
- 写到多个文件
系列文章第四篇,学习一下 spring batch 的两个重要的功能,读数据(Reader)和写数据(Writer) 。
第一篇文章的传送门: Spring batch系列文章(一)―― 介绍和入门
第二篇的文章传送门: Spring batch系列文章(二)―― 核心api
第三篇的文章传送门: Spring batch系列文章(三)―― 决策器和监听器
读取数据
读取数据库的数据
读取数据库的数据很简单,框架提供了很多实现好的 ItemReader 类,其中有个 JdbcPagingItemReader 就是专门用来读取数据库的数据的。
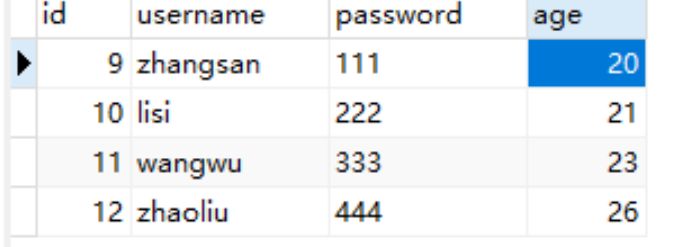
首先准备数据库并插入数据
create table user(id int PRIMARY key auto_increment,username varchar(30),password varchar(30),age int);
insert into user(username,password,age) values ('zhangsan','111',20);
insert into user(username,password,age) values ('lisi','222',21);
insert into user(username,password,age) values ('wangwu','333',23);
insert into user(username,password,age) values ('zhaoliu','444',26);
执行脚本得到数据库:
为了方便展示,我把 job,step,reader,writer 都写在了一个类里,开发时肯定要进行分开编写方便阅读也增加可重用性。
首先创建任务和步骤,这些过程和之前没什么不同,因为要使用 reader,所以在 step 创建的时候,需要使用 chunk,这是关键代码:
@Bean
public Step itemReaderDBStep() {
return stepBuilderFactory.get("itemReaderDBStep").<User,User>chunk(1).reader(dbItemReader()).writer(dbItemWriter()).build();
}
dbItemReader 和 dbItemWriter 方法分别提取出来:
@Bean
public JdbcPagingItemReader<User> dbItemReader() {
JdbcPagingItemReader jdbcPagingItemReader = new JdbcPagingItemReader();jdbcPagingItemReader.setDataSource(dataSource);jdbcPagingItemReader.setFetchSize(2);jdbcPagingItemReader.setRowMapper((rs, rowNum) -> {
User user = new User();user.setId(rs.getInt(1));user.setUsername(rs.getString(2));user.setPassword(rs.getString(3));user.setAge(rs.getInt(4));return user;});MySqlPagingQueryProvider mySqlPagingQueryProvider = new MySqlPagingQueryProvider();mySqlPagingQueryProvider.setSelectClause("id,username,password,age");mySqlPagingQueryProvider.setFromClause("from user");Map<String, Order> sortMap = new HashMap<>(1);sortMap.put("id",Order.ASCENDING);mySqlPagingQueryProvider.setSortKeys(sortMap);jdbcPagingItemReader.setQueryProvider(mySqlPagingQueryProvider);return jdbcPagingItemReader;
}
@Bean
public ItemWriter<User> dbItemWriter() {
return items -> {
for (User item : items) {
System.out.println(item);}};
}
reader 方法中,需要导入 datasource,指定每页读取多少条数据,还要指定 rowmapper 用来进行对象转换,另外需要指定 sql 语句,当然也可以集成 jpa、mybatis 等框架,这里为了简介就不去整那么麻烦了。集成 jpa 会使这部分代码看上去比较简单,可读性也会更高。这里就用了最原始的方式“暴力读取”。
运行结果展示:

需要注意的是这里的 mySqlPagingQueryProvider 必须指定排序规则,否则会报错。
读取文件的数据
读取文件的数据只需要做稍微的改动,首先准备一个文件,这里以 csv 文件为例,放在 resource 目录下。文件名 user.csv

从文件中读取数据,用到的是FlatFileItemReader,必须设置resource和lineMapper,resource就是文件的路径,lineMapper就是每一行数据的解析,我使用的是DefaultLineMapper,只需要设置一个tokenizer和fieldSetMapper,tokenier通过DelimitedLineTokenizer创建,可以指定一些解析的细节,fieldSetMapper指定读取的数据和对象之间的映射。
@Bean
public ItemReader<User> fileItemReader() {
FlatFileItemReader reader = new FlatFileItemReader();reader.setResource(new ClassPathResource("user.csv"));//解析数据DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();tokenizer.setNames(new String[]{
"id","username","password","age"});DefaultLineMapper<User> mapper = new DefaultLineMapper<>();mapper.setLineTokenizer(tokenizer);mapper.setFieldSetMapper(fieldSet -> {
User user = new User();user.setId(fieldSet.readInt("id"));user.setUsername(fieldSet.readString("username"));user.setPassword(fieldSet.readString("password"));user.setAge(fieldSet.readInt("age"));return user;});reader.setLineMapper(mapper);return reader;
}
执行结果

读取多个文件的数据
读取多个文件的数据用到的 ItemReader 类是 MultiResourceItemReader,只需要在上边的例子中稍微改动一个部分:
resource 下的文件我复制了三份,分别是 user.csv、user1.csv、user2.csv 表示区分,id 分别是 1-5、11-15、21-25



引入 resources,放三个文件的路径数组:
@Value("classpath:/user*.csv")
private Resource[] resources;
引入 MultiResourceItemReader:
@Bean
public ItemReader multiResourceItemReader(){
MultiResourceItemReader<User> reader = new MultiResourceItemReader();reader.setDelegate(fileItemReader());reader.setResources(resources);return reader;
}
其中 fileItemReader 方法和上个例子中一样:
@Bean
public FlatFileItemReader<User> fileItemReader() {
FlatFileItemReader reader = new FlatFileItemReader();reader.setResource(new ClassPathResource("user.csv"));//解析数据DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();tokenizer.setNames(new String[]{
"id","username","password","age"});DefaultLineMapper<User> mapper = new DefaultLineMapper<>();mapper.setLineTokenizer(tokenizer);mapper.setFieldSetMapper(fieldSet -> {
User user = new User();user.setId(fieldSet.readInt("id"));user.setUsername(fieldSet.readString("username"));user.setPassword(fieldSet.readString("password"));user.setAge(fieldSet.readInt("age"));return user;});reader.setLineMapper(mapper);return reader;
}
然后把 multiResourceItemReader 放入到 step 中:
@Bean
public Step itemReaderFileStep() {
return stepBuilderFactory.get("itemReaderFileStep").<User,User>chunk(5).reader(multiResourceItemReader()).writer(fileItemWriter()).build();
}
执行查看结果:
结果比较长 我进行了拼接:
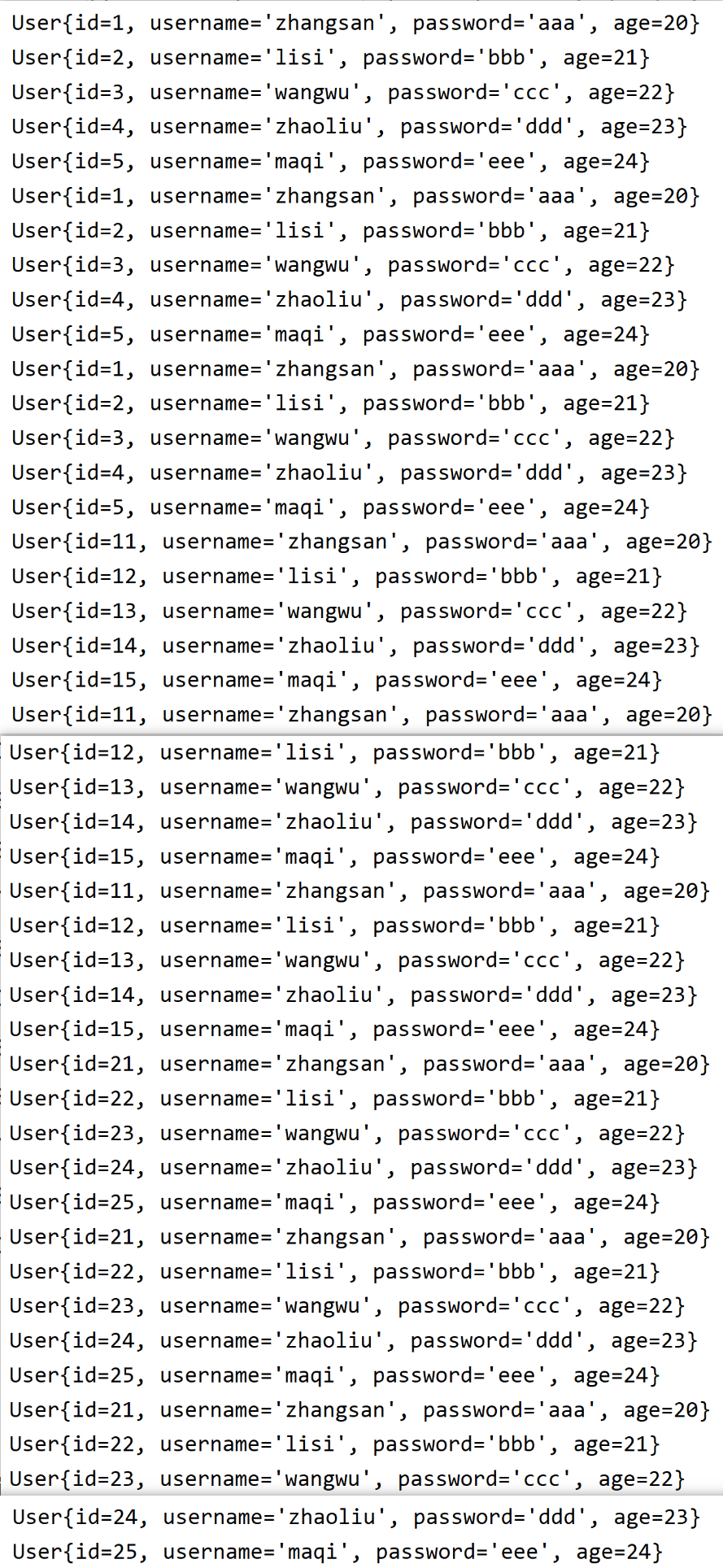
到这里,读取多个文件的功能就算完成了。
写入数据
写到数据库
有了前边的读取数据,其实写入也一样的,spring batch框架已经给我们提供了相应的类,JdbcBatchItemWriter可以帮助我们直接把读取到的数据直接写入数据库。为了简单表示,这里我没有集成持久层框架,直接用sql语句,把读到的数据插入到数据库。首先复用一下之前读数据的方法,我们依然从文件中读取数据,下边是文件的内容和读方法的有关代码。

这里提一下,由于我的文件中的 id 都是重复的,插入数据时作为主键不能插入,所以我在往数据库中写数据的时候,直接忽略掉了 id 值,因为数据库中的 id 是自增的,所以我们让他自动生成即可。
@Bean
public FlatFileItemReader<User> fileItemReader() {
FlatFileItemReader reader = new FlatFileItemReader();reader.setResource(new ClassPathResource("user.csv"));//解析数据DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();tokenizer.setNames(new String[]{
"id","username","password","age"});DefaultLineMapper<User> mapper = new DefaultLineMapper<>();mapper.setLineTokenizer(tokenizer);mapper.setFieldSetMapper(fieldSet -> {
User user = new User();user.setUsername(fieldSet.readString("username"));user.setPassword(fieldSet.readString("password"));user.setAge(fieldSet.readInt("age"));return user;});reader.setLineMapper(mapper);return reader;
}
可以看到读方法已经把读取的数据转换成了 user 对象,我们只需要在 writer 方法里写上相应的逻辑即可。代码比较简单:
@Bean
public ItemWriter<User> toDbWriter() {
JdbcBatchItemWriter<User> writer = new JdbcBatchItemWriter();writer.setDataSource(dataSource);writer.setSql("insert into user(username,password,age) values" +"(:username,:password,:age)");writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());return writer;
}
执行后,查看数据库:
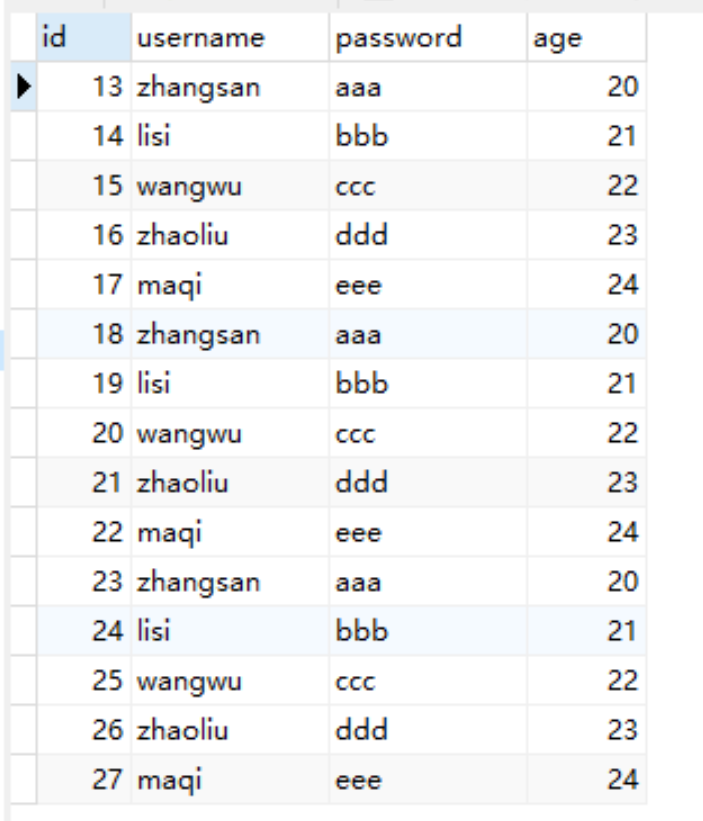
写到文件
从文件中读取用的是 FlatFileItemReader,那么写数据到文件就是 FlatFileItemWriter,下面我们来看具体的例子,这个例子还是从文件中读取数据(就是图个方便,继续复用之前的代码),然后写出到另一个文件中。
读取的文件同上,图片就不再贴了。
原本我打算写出到 classpath 下的 user1.csv,试了几次发现写出文件都为空,我把写出文件定到磁盘,文件改为了 txt 格式才可以,猜测可能是 csv 格式写不进去。
@Bean
public ItemWriter<User> toFileWriter() {
FlatFileItemWriter<User> writer = new FlatFileItemWriter();String filePath = "E://user.txt";writer.setResource(new FileSystemResource(filePath));writer.setLineAggregator(new LineAggregator<User>() {
@Overridepublic String aggregate(User item) {
return item.toString();}});return writer;
}
这种方式文件需要提前创建好空文件。
运行后文件变为:
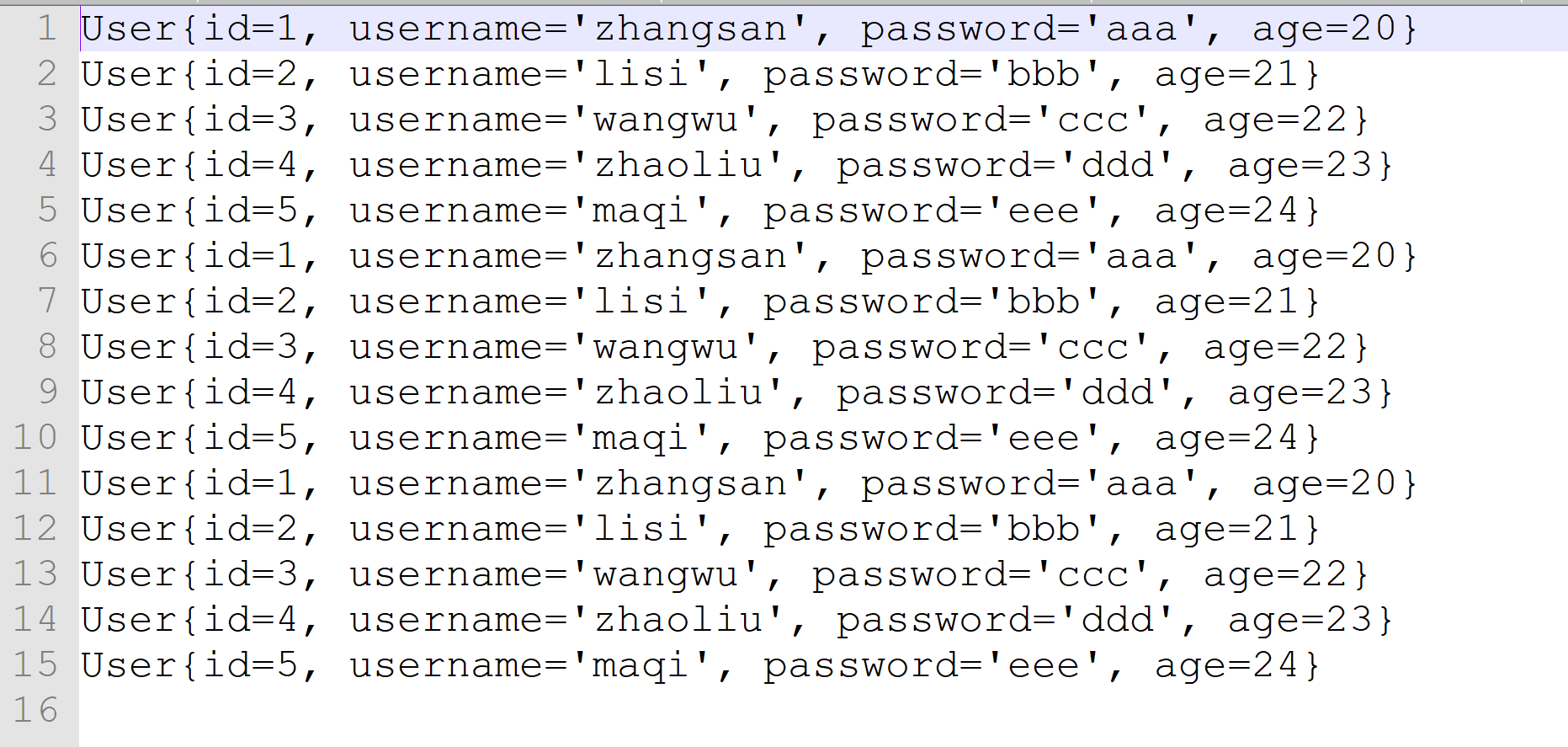
如果再次运行,文件会被清空,然后重新写入,而不是继续写到文件中。
写到多个文件
这个功能不怎么常用,写入多个文件和从多个文件中读取也是类似的,都需要有一个写入文件的 writer,如果需要写入多个文件,再需要一个 writer 类管理,框架提供了 CompositeItemWriter 和 ClassifierCompositeItemWriter 两个类,其中 CompositeItemWriter 可以把读取到的数据写入到多个文件(每个文件都有全部的内容,文件格式可以不同),ClassifierCompositeItemWriter 可以把数据分类写到多个文件中。
这个功能我自己还没来得及写,打算等以后用到了再去尝试,到这里为止,框架的基础部分都已经学的差不多了,当然还有更深入的知识,比如异常的处理,重试和跳过,控制任务的执行的 JobLauncher 还可以通过一些调度框架实现任务的定时执行。等等
等以后有时间再来进行补充,下一篇准备写个 quartz 的入门,就这样。