说明
本文以开源框架nacos,版本号为1.3.2针对leader 的选举进行源码解析 ,leader 选举采用raft 算法实现,所以对raft 算法原理也会进行阐述;
Nacos源码下载地址:https://github.com/alibaba/nacos
Raft 算法原理
Raft理论是分布式数据一致性算法,为了便于理解Raft算法分成了4个部分:
-Leader选举
-日志复制
-成员变更
-日志压缩
本文章只讲述leader 选举
系统角色:
Leader、Candidate、Follower
- Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
- Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
- Candidate:Leader选举过程中的临时角色。
term
?Raft 算法将时间划分成为任意不同长度的任期(term)。任期用连续的数字进行表示。每一个任期的开始都是一次选举(election),一个或多个候选人会试图成为领导人。如果一个候选人赢得了选举,它就会在该任期的剩余时间担任领导人。在某些情况下,选票会被瓜分,有可能没有选出领导人,那么,将会开始另一个任期,并且立刻开始下一次选举。Raft 算法保证在给定的一个任期最多只有一个领导人
选举原则:
典型的投票选举算法(少数服从多数),也就是说,在一定周期内获得投票最多的节点成为主节点。每个term都是一个选举时间,当选择出来的leader 都有一个任期时间,超时后在重新选择.
常见问题
Raft 选举以问题的方式来理解如何通过raft 算法来实现选举
p1.leader选举什么时候发生:
- 刚启动时,所有节点都是follower,这个时候发起选举,选出一个leader;
- 当leader挂掉后,时钟最先跑完的follower发起重新选举操作,选出一个新的leader。
- 成员变更的时候会发起选举操作。
p2.Raft中选举中给候选人投票的前提?
? ?Raft确保新当选的Leader包含所有已提交(集群中大多数成员中已提交)的日志条目。这个保证是在RequestVoteRPC阶段做的,candidate在发送RequestVoteRPC时,会带上自己的last log entry的term_id和index,follower在接收到RequestVoteRPC消息时,如果发现自己的日志比RPC中的更新,就拒绝投票。日志比较的原则是,如果本地的最后一条log entry的term id更大,则更新,如果term id一样大,则日志更多的更大(index更大)
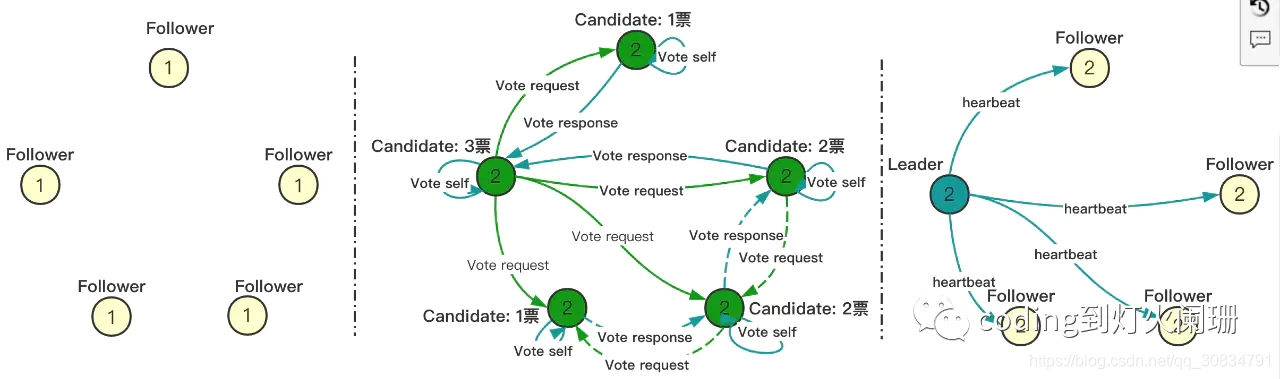
p3 如何避免网络恢复后,不发生切主?
如上图,B分区的2个节点由于永远得不到超过半数的投票,所以任值周期不断累加。当网络恢复后,原来的Leader由于任值周期小,切换为Follower状态,集群重新选主。
如何避免重新选主,将投票阶段分拆成两阶段,即预投票阶段和投票阶段。
预投票阶段:任值周期不累加,选出得票数过半的节点。
投票阶段:由在预投票阶段选出的节点发起投票请求,任值周期累加,最终选出主节点。
这样,B分区2个节点的任值周期就会小于等于原Leader的任值周期,当网络恢复后就不会重新选主。
Nacos leader 选举
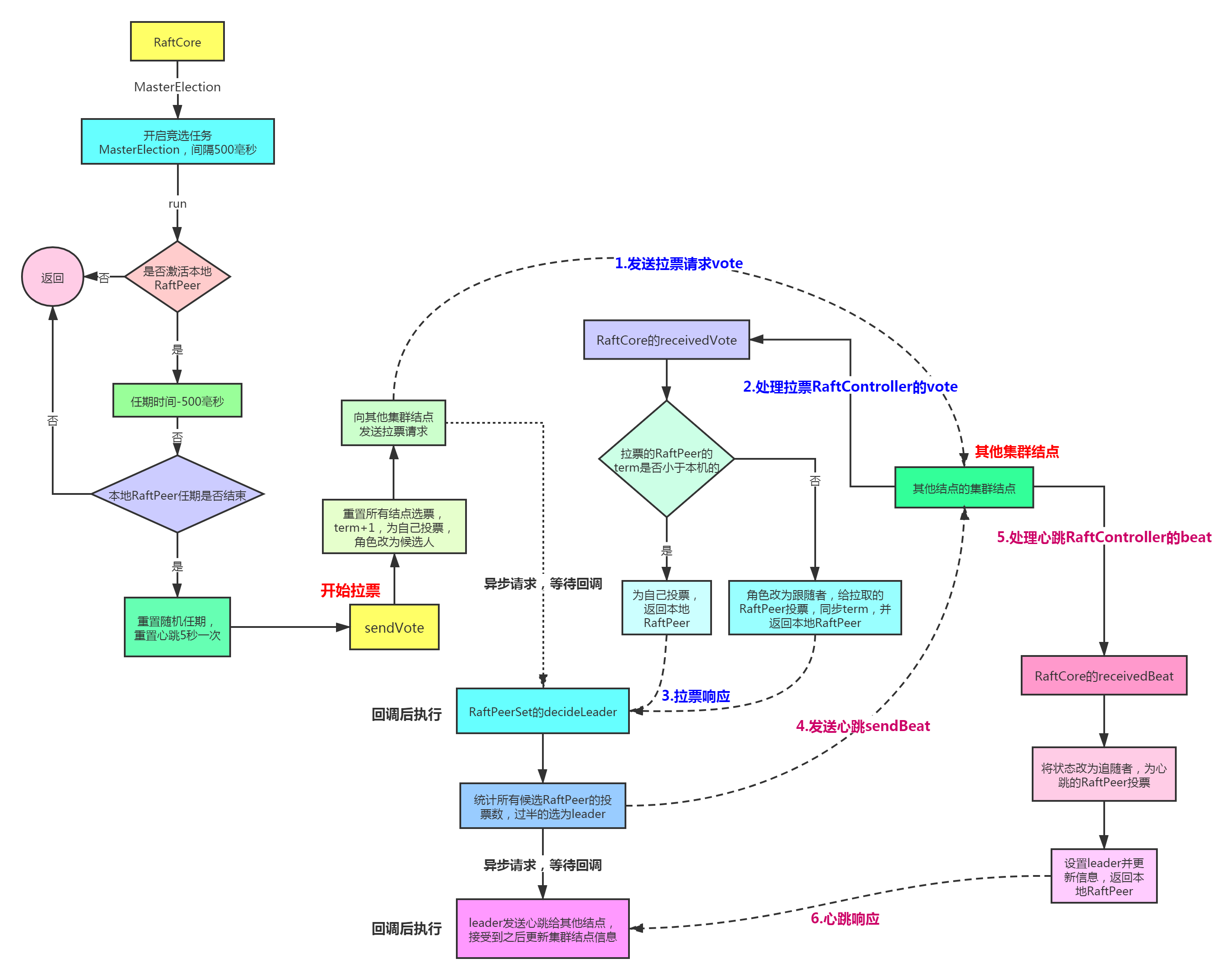
Raft 竞选流程图
RaftCore核心类
raftCore#init 初始化方法,粘贴部分代码
//todo 每500毫秒就行leader 选举GlobalExecutor.registerMasterElection(new MasterElection());
//todo 每500毫秒心跳
GlobalExecutor.registerHeartbeat(new HeartBeat());
MasterElection--leader 选举线程
任期超时才能发起选举请求,并重置心跳,leader任期时间,避免重复发起;
心跳时间每个节点都是不一样,采用随机值(15~20s);这样做的好处在于避免多节点同时发起选举,提高选举成功率
public void run() {try {//可以开始选举的标记if (!peers.isReady()) {return;}RaftPeer local = peers.local();local.leaderDueMs -= GlobalExecutor.TICK_PERIOD_MS;//-定时任务500毫秒//任期超时没到if (local.leaderDueMs > 0) {return;}// reset timeout 重置任期超时时间和心跳时间,准备开始拉票local.resetLeaderDue();local.resetHeartbeatDue();//拉票sendVote();} catch (Exception e) {Loggers.RAFT.warn("[RAFT] error while master election {}", e);}}
sendVote ---发起投票
任期term+1 ,并且状态设置为CANDIDATE候选者,投票自己,并异步的发送给其它节点,票数过半的为leader
private void sendVote() {RaftPeer local = peers.get(NetUtils.localServer());Loggers.RAFT.info("leader timeout, start voting,leader: {}, term: {}", JacksonUtils.toJson(getLeader()),local.term);//把投票信息设为nullpeers.reset();//term+1local.term.incrementAndGet();local.voteFor = local.ip;//投票给自己local.state = RaftPeer.State.CANDIDATE;//切换角色为候选者Map<String, String> params = new HashMap<>(1);params.put("vote", JacksonUtils.toJson(local));for (final String server : peers.allServersWithoutMySelf()) {final String url = buildUrl(server, API_VOTE);try {HttpClient.asyncHttpPost(url, null, params, new AsyncCompletionHandler<Integer>() {@Overridepublic Integer onCompleted(Response response) throws Exception {if (response.getStatusCode() != HttpURLConnection.HTTP_OK) {Loggers.RAFT.error("NACOS-RAFT vote failed: {}, url: {}", response.getResponseBody(), url);return 1;}RaftPeer peer = JacksonUtils.toObj(response.getResponseBody(), RaftPeer.class);Loggers.RAFT.info("received approve from peer: {}", JacksonUtils.toJson(peer));//统计投票结果,过半的为成功选举为leaderpeers.decideLeader(peer);return 0;}});} catch (Exception e) {Loggers.RAFT.warn("error while sending vote to server: {}", server);}}}
}
RaftController#vote
Vote方法实际调的也是RaftCore的receivedVote;该方法用synchronized 修饰;目的确保选举的同步性,确保变量term的数据安全性;
投票规则:远程任期小于本地就投self;简单粗暴
public synchronized RaftPeer receivedVote(RaftPeer remote) {if (!peers.contains(remote)) {throw new IllegalStateException("can not find peer: " + remote.ip);}RaftPeer local = peers.get(NetUtils.localServer());if (remote.term.get() <= local.term.get()) {//远程任期小于本地就投selfString msg = "received illegitimate vote" + ", voter-term:" + remote.term + ", votee-term:" + local.term;Loggers.RAFT.info(msg);if (StringUtils.isEmpty(local.voteFor)) {local.voteFor = local.ip;}return local;}//重置leader termlocal.resetLeaderDue();//本地node 状态变更为跟随者local.state = RaftPeer.State.FOLLOWER;local.voteFor = remote.ip;local.term.set(remote.term.get());//任期同步更新Loggers.RAFT.info("vote {} as leader, term: {}", remote.ip, remote.term);return local;
}
问题1:
心细的同学应该发现了问题;在讲解raft 原理中针对leader 选举提到投票阶段分拆成两阶段;可目前并木有,这样有可能会造成已有数据丢失;场景描述如下
场景:五个节点ABCDE,其中A,B,C 在一个网段Net1,其中A 为leader; D,E在另外一个网段Net2;那么Net2由于某种原因,某短暂时间不能和Net1通信,导致net2 节点D,E 进行leader选举,term 任期不断加1,而此时有服务注册,使ABC 节点服务数据有新增;
那么问题来了,当Net1和Net2网络恢复正常了,此时D 发起leader选举,由于term>A,B,C ,有可能选举通过并且最后成为leader ,这样就会造成数据丢失,因为A,B,C 的数据明显多于D,最后通过心跳 会把其它节点数据保存和新leaderD一制;数据成功丢失
针对这个问题,nacos 技术员巧妙的避开了,就是当有新数据添加时,term+100,也就是大概有25(一个任期在15~20秒)分钟时间恢复网络,所以很难有数据丢失,但是同样有易主现象(在数据没有新增的情况下);
问题2:
同样会出现双leader 问题;
场景:五个节点ABCDE,其中A,B 在一个网段Net1,其中A 为leader; C、D,E在另外一个网段Net2;那么Net2由于某种原因,某短暂时间不能和Net1通信,导致net2 节点C、D,E 进行leader选举,最终选出其中一个比如C;形成双主模式;(两个不同的term 有一个leader)
Raft算法采用任期过期来精选重选,避开了集群中有两个leader的现象,而nacos 自制的raft采用心跳机制避开双leader 现象;leader 发起心跳时会把其它节点包含另一个leader状态重置为follower(采用先下手为强的原则);即使两个leader 都重置为follower ;leader 任期超时后也会重新发起选举;
RaftCore的decideLeader--确定leader
超过半数表示投票成功,确定为leader; node个数在ServerMemberManager#init 初始化时回去读取cluster.conf 文件,或者远程读取等方式加入到缓存中
public RaftPeer decideLeader(RaftPeer candidate) {peers.put(candidate.ip, candidate);SortedBag ips = new TreeBag();int maxApproveCount = 0;String maxApprovePeer = null;for (RaftPeer peer : peers.values()) {if (StringUtils.isEmpty(peer.voteFor)) {continue;}ips.add(peer.voteFor);if (ips.getCount(peer.voteFor) > maxApproveCount) {//超过最大投票数就行更新maxApproveCount = ips.getCount(peer.voteFor);maxApprovePeer = peer.voteFor;}}//超过半数if (maxApproveCount >= majorityCount()) {RaftPeer peer = peers.get(maxApprovePeer);peer.state = RaftPeer.State.LEADER;if (!Objects.equals(leader, peer)) {leader = peer;ApplicationUtils.publishEvent(new LeaderElectFinishedEvent(this, leader, local()));Loggers.RAFT.info("{} has become the LEADER", leader.ip);}}return leader;
}
HeartBeat ----心跳
心跳只能是leader 发送,并且附带数据同步给其它节点,使所有节点数据最终一致性
public class HeartBeat implements Runnable {@Overridepublic void run() {try {if (!peers.isReady()) {return;}RaftPeer local = peers.local();local.heartbeatDueMs -= GlobalExecutor.TICK_PERIOD_MS;if (local.heartbeatDueMs > 0) {return;}//重置心跳local.resetHeartbeatDue();//发生心跳sendBeat();} catch (Exception e) {Loggers.RAFT.warn("[RAFT] error while sending beat {}", e);}}
sendBeat -- 发送心跳
单机或者不是leader 不会发送心跳,把leader 的相关数据打包给其它节点
private void sendBeat() throws IOException, InterruptedException {RaftPeer local = peers.local();//单机或者不是leader 不会发心跳if (ApplicationUtils.getStandaloneMode() || local.state != RaftPeer.State.LEADER) {return;}if (Loggers.RAFT.isDebugEnabled()) {Loggers.RAFT.debug("[RAFT] send beat with {} keys.", datums.size());}//重置任期local.resetLeaderDue();// build dataObjectNode packet = JacksonUtils.createEmptyJsonNode();packet.replace("peer", JacksonUtils.transferToJsonNode(local));ArrayNode array = JacksonUtils.createEmptyArrayNode();if (switchDomain.isSendBeatOnly()) {Loggers.RAFT.info("[SEND-BEAT-ONLY] {}", String.valueOf(switchDomain.isSendBeatOnly()));}if (!switchDomain.isSendBeatOnly()) {for (Datum datum : datums.values()) {ObjectNode element = JacksonUtils.createEmptyJsonNode();if (KeyBuilder.matchServiceMetaKey(datum.key)) {element.put("key", KeyBuilder.briefServiceMetaKey(datum.key));} else if (KeyBuilder.matchInstanceListKey(datum.key)) {element.put("key", KeyBuilder.briefInstanceListkey(datum.key));}element.put("timestamp", datum.timestamp.get());array.add(element);}}packet.replace("datums", array);// broadcastMap<String, String> params = new HashMap<String, String>(1);params.put("beat", JacksonUtils.toJson(packet));String content = JacksonUtils.toJson(params);ByteArrayOutputStream out = new ByteArrayOutputStream();GZIPOutputStream gzip = new GZIPOutputStream(out);gzip.write(content.getBytes(StandardCharsets.UTF_8));gzip.close();byte[] compressedBytes = out.toByteArray();String compressedContent = new String(compressedBytes, StandardCharsets.UTF_8);if (Loggers.RAFT.isDebugEnabled()) {Loggers.RAFT.debug("raw beat data size: {}, size of compressed data: {}", content.length(),compressedContent.length());}for (final String server : peers.allServersWithoutMySelf()) {try {final String url = buildUrl(server, API_BEAT);if (Loggers.RAFT.isDebugEnabled()) {Loggers.RAFT.debug("send beat to server " + server);}//发送给其它节点HttpClient.asyncHttpPostLarge(url, null, compressedBytes, new AsyncCompletionHandler<Integer>() {@Overridepublic Integer onCompleted(Response response) throws Exception {if (response.getStatusCode() != HttpURLConnection.HTTP_OK) {Loggers.RAFT.error("NACOS-RAFT beat failed: {}, peer: {}", response.getResponseBody(),server);MetricsMonitor.getLeaderSendBeatFailedException().increment();return 1;}//添加raftPeerpeers.update(JacksonUtils.toObj(response.getResponseBody(), RaftPeer.class));if (Loggers.RAFT.isDebugEnabled()) {Loggers.RAFT.debug("receive beat response from: {}", url);}return 0;}@Overridepublic void onThrowable(Throwable t) {Loggers.RAFT.error("NACOS-RAFT error while sending heart-beat to peer: {} {}", server, t);MetricsMonitor.getLeaderSendBeatFailedException().increment();}});} catch (Exception e) {Loggers.RAFT.error("error while sending heart-beat to peer: {} {}", server, e);MetricsMonitor.getLeaderSendBeatFailedException().increment();}}}
RaftController#beat --- 接收心跳
Beat 方法直接调用的是raftCore#receivedBeat 所以我们直接看此方法,由于此方法太长分段解析;
final RaftPeer local = peers.local();
final RaftPeer remote = new RaftPeer();
JsonNode peer = beat.get("peer");
remote.ip = peer.get("ip").asText();
remote.state = RaftPeer.State.valueOf(peer.get("state").asText());
remote.term.set(peer.get("term").asLong());
remote.heartbeatDueMs = peer.get("heartbeatDueMs").asLong();
remote.leaderDueMs = peer.get("leaderDueMs").asLong();
remote.voteFor = peer.get("voteFor").asText();if (remote.state != RaftPeer.State.LEADER) {Loggers.RAFT.info("[RAFT] invalid state from master, state: {}, remote peer: {}", remote.state,JacksonUtils.toJson(remote));throw new IllegalArgumentException("invalid state from master, state: " + remote.state);
}
//保证只有大于本地任期才接收心跳
if (local.term.get() > remote.term.get()) {Loggers.RAFT.info("[RAFT] out of date beat, beat-from-term: {}, beat-to-term: {}, remote peer: {}, and leaderDueMs: {}",remote.term.get(), local.term.get(), JacksonUtils.toJson(remote), local.leaderDueMs);throw new IllegalArgumentException("out of date beat, beat-from-term: " + remote.term.get() + ", beat-to-term: " + local.term.get());
}
//本地不是跟随者,可能是候选人,所以将自己变为跟随者,选远程的leader
if (local.state != RaftPeer.State.FOLLOWER) {Loggers.RAFT.info("[RAFT] make remote as leader, remote peer: {}", JacksonUtils.toJson(remote));// mk followerlocal.state = RaftPeer.State.FOLLOWER;local.voteFor = remote.ip;
}final JsonNode beatDatums = beat.get("datums");
local.resetLeaderDue();
local.resetHeartbeatDue();
//如果有其它leader 信息则进行更新
peers.makeLeader(remote);
接下来就是同步leader data 了,根据数据key 和更新时间,来找出需要更新的数据在去拉取leader 数据就行更新,并且重值term
// update datum entry
String url = buildUrl(remote.ip, API_GET) + "?keys=" + URLEncoder.encode(keys, "UTF-8");
HttpClient.asyncHttpGet(url, null, null, new AsyncCompletionHandler<Integer>() {@Overridepublic Integer onCompleted(Response response) throws Exception {if (response.getStatusCode() != HttpURLConnection.HTTP_OK) {return 1;}List<JsonNode> datumList = JacksonUtils.toObj(response.getResponseBody(), new TypeReference<List<JsonNode>>() {});for (JsonNode datumJson : datumList) {Datum newDatum = null;OPERATE_LOCK.lock();try {Datum oldDatum = getDatum(datumJson.get("key").asText());if (oldDatum != null && datumJson.get("timestamp").asLong() <= oldDatum.timestamp.get()) {Loggers.RAFT.info("[NACOS-RAFT] timestamp is smaller than that of mine, key: {}, remote: {}, local: {}",datumJson.get("key").asText(),datumJson.get("timestamp").asLong(), oldDatum.timestamp);continue;}if (KeyBuilder.matchServiceMetaKey(datumJson.get("key").asText())) {Datum<Service> serviceDatum = new Datum<>();serviceDatum.key = datumJson.get("key").asText();serviceDatum.timestamp.set(datumJson.get("timestamp").asLong());serviceDatum.value = JacksonUtils.toObj(datumJson.get("value").toString(), Service.class);newDatum = serviceDatum;}if (KeyBuilder.matchInstanceListKey(datumJson.get("key").asText())) {Datum<Instances> instancesDatum = new Datum<>();instancesDatum.key = datumJson.get("key").asText();instancesDatum.timestamp.set(datumJson.get("timestamp").asLong());instancesDatum.value = JacksonUtils.toObj(datumJson.get("value").toString(), Instances.class);newDatum = instancesDatum;}if (newDatum == null || newDatum.value == null) {Loggers.RAFT.error("receive null datum: {}", datumJson);continue;}raftStore.write(newDatum);datums.put(newDatum.key, newDatum);notifier.addTask(newDatum.key, ApplyAction.CHANGE);local.resetLeaderDue();if (local.term.get() + 100 > remote.term.get()) {getLeader().term.set(remote.term.get());local.term.set(getLeader().term.get());} else {local.term.addAndGet(100);}raftStore.updateTerm(local.term.get());
总结
Nacos 制定自己raft时做了一些变更;
变更一:
leader 任期没有超时现象,在发起心跳的时候都会在重置任期时间,导致不超时,除非宕机;避免了node之间频繁通讯;同时通过心跳机制重置其它节点为follower,避免长时间双leader 现象
变更二:
选举未采用双阶段选举模式,简化了模式;通过数据变更term+100 的方式来解决短时间分区问题;
特征:
一、term 的变更发生在两个地方:1.leader 选举,加1;2.数据更新,加100;
二、心跳只能leader 发送;
三、数据同步term必须大于等于本地term才是更新的前提;
四、选举是发起方的term必须大于本地term