����Ŀ¼
- ԭ�ĵ�ַ
- �����Ķ�����
- ��ʼ��Abstract & Introduction & Conclusion��
- ��֪��Body��
- 2. Related Work
- Conventional Methods
- Data-Driven Methods
- 3. Methodology
- 3.1 Light-Enhancement Curve (LE-Curve)
- 3.2 DCE-Net
- 3.3 Non-Reference Loss Functions
- 4. Experiment
- 4.1 Ablation Study
- 4.2 Benchmark Evaluations
- 4.2.1 Visual and Perceptual Comparison
- 4.2.2 Quantitative Comparison
- 4.2.3 Face Detection in the Dark
- �عˣ�Review��
- ����
ԭ�ĵ�ַ
https://arxiv.org/abs/2001.06826
�����Ķ�����
�������ķ�
��ʼ��Abstract & Introduction & Conclusion��
Low-Light(����)ͼ��ή��ͼ����ѧ�Լ�������Ϣ��������ǰ��Ӱ��������飬���ᵼ�´�����Ϣ�Ĵ���(���磺����/����ʶ��)�����������һ���·���(light-weight deep network)���ڽ��Low-Lightͼ����ǿ���⣬�����������ת��Ϊ��һ��image-specific���߹�������(ͼ����Ϊ����������Ϊ���)���������߶�������Ķ�̬��Χ�ڽ������ؼ��������Ӷ������ǿͼ��
��������ͨ������һϵ��non-reference����ʧ����(spatial consistency loss, exposure control loss, color constancy loss, illumination smoothness loss,���Լ�ӷ�ӳ��ǿ����)��ʹ��������û���κβο�ͼ���������ܹ�����end-to-endѵ�������������ڶ�����ݼ��϶�ȡ����SOTA��

����ͼ��ʾ�����Կ�������Zero-DCE�ܹ��ڱ��ֹ�����ɫ��ϸ�ڵ�����£���ͼ����кܺõ���ǿ��
���ĵ���Ҫ���������㣺
- ����˵�һ����paired��unpaired data����low-light��ǿ���磬�����ȱ����˹���ϵķ��գ�Ҳ����ʹ�������ܺܺõط��������ֹ��������¡�
- �����һ��image-specific���ߣ�ͨ������Ӧ������������ϳ�һ��pixel-wise and higher-order���ߣ������ڸ���Ķ�̬��Χ�ڽ�����Ч��ӳ�䡣
- Zero-DCE�ܹ���û�вο�ͼ�������½���ѵ��(ͨ������task-specific��non-reference��ʧ��������ɼ��������ǿ����)
����֮�⣬Zero-DCE��light-weight�ģ���������С�����Կ���Ӧ���������������⾫��(�����������)
��֪��Body��
2. Related Work
Conventional Methods
��������ڽ�����һЩ��ͳ�ķ���(���磺HE-based������ͼ��ֱ��ͼ�ֲ�������Retinex ���۵ķ���)��������Ϊ��Щ��ͳ����Ҫô������ظı�ͼ���ֱ��ͼ�ֲ���Ҫô������һЩ���ܲ���ȷ������ģ��(���������)������������ķ�����ͨ��image-specific����ӳ�������ǿ�����ֲ��Կ�����ǿͼ���Ҳ������unrealistic artifacts��
ͬʱ��������ͬ��ʹ������ӳ��ķ���(Lu Yuan and Jian Sun - Automatic exposure correction of consumer photographs)�����˶Աȣ���������ķ�����data-driven���������non-reference��ʧ������������õ����õ�³���ԣ�����Ķ�̬������Χ�Լ����͵ļ��㸺����
Data-Driven Methods
���������ķ������Ա���Ϊ������֧��CNN-based��GAN-based��
1��CNN-based�����������CNN-based��������Ҫpaired data(low/normal light image)�����мලѵ������Щpaired dataͨ��ͨ��������ɼ�ͼƬʱ�ı���������ã�����ʹ��ͼ�������������Ժϳɡ������֪����Щ����paired data�ķ���ͨ����high cost(�����ռ�)���������ݼ�������һЩ���/����ʵ��ͼƬ(�˹��ϳ�)��������Ӱ�쵽ģ�͵ķ�������(��ģ��Ӧ������ʵ����IJ�ͬ�����£�ͨ�������ɫƫ������)��
2��GAN-based�� unsupervised GAN-based�������Ա�����ѵ��������ʹ��paired data������EnlightenGAN(֮ǰ��SOTA����õ�GAN-based����)ʹ����unpaired data������ͼ����ǿ��Ȼ����Щunpaired dataͨ��Ҳ��Ҫ������ѡ��
���������Zero-DCE����������data-driven�����������ŵ㣺
- ̽����һ��ȫ�µ�ѧϰ����(zero reference)�������˶�paired/unpaired data������
- ����non-reference��ʧ�����������ͼ����м�ӵ�������
- ����ķ�����high efficient��cost efficient��.
���߽����������ŵ�鹦�ڣ�zero reference learning framework + lightweight network structure + effective non-reference loss functions.
3. Methodology
Zero-DCE�Ŀ������ͼ��ʾ����������ѧϰһ��best-fitting����ǿ���ߣ��������Ӧ��Curve��������ͼ���RGBͨ�����������ؽ���ӳ�䣬�Ӷ����������ǿͼ��

3.1 Light-Enhancement Curve (LE-Curve)
�ܵ�ͼ��༭������"Curves Adjustment"�����������߳������һ���ܹ���low-lightͼ���Զ�ӳ�䵽��ǿͼ�������ߣ����߲�����self-adaptive�ģ�����ȡ��������ͼ�����������������������Ҫ��
- ��ǿͼ�������ֵ��һ��Ϊ[0,1]�������������overflow truncation�����µ���Ϣ��ʧ��
- ��Ƶ�����Ӧ���ǵ����ģ��Ӷ������������ؼ�IJ���(�Աȶ�)��
- ����Ӧ�þ����ܵؼ�ʹ�������ݶȷ����������ǿɵ��ġ�
Ϊ�˴ﵽ����������Ҫ�����������һ���������ߣ�

���У�xΪ�������꣬LE(I(x); ��)Ϊ����ͼ��I(x)����ǿ���������[-1,1]Ϊ��ѵ�������߲���(�����ߵĴ�С�������ع��)��ÿ�����ض���һ��Ϊ[0,1]���������в�������pixel-wise��ʹ��ʱ���������RGBͨ���ֱ�Ӧ��LE-Curve������Ը��õر��ֹ�����ɫ�Լ�����������
�ڲ�ͬ�Ħ����������£�ͼ������ͼ(b)��ʾ�����Կ�����Ƶ����߿��Ժܺõ���������������Ҫ���⣬LE-Curve��������/��������ͼ��Ķ�̬��Χ����������������ǿlow-light�������Ա�������ع���
Higher-Order Curve��
ͨ��������ʽ(1)�����LE-Curve������ʹ�õ�����ø����Ӷ�ʹ��ģ���ܹ���Ӧ�ڸ���challenging�����������£�

���У�nΪ�����Ĵ���(�������ʣ����Ľ�n����Ϊ8����������������)����nΪ1ʱ��ʽ(2)���˻�Ϊ��(1)����ͼ?���ṩ��high-order Curve��ʾ�������Կ����������(b)�е�ͼ�������и�ǿ��ĵ�������(���������)��
Pixel-Wise Curve��
�����ᵽ�ĸ߽����߿����ڸ����Ķ�̬��Χ�ڵ���ͼ�����ڦ�Ӧ�������е����أ�������Ϊglobal adjustment������global mapping������over-/under- enhance�ֲ�������Ϊ�˽��������⣬�������¶����Ϊһ��pixel-wise����(��.����ͼ���ÿ�����ض������Ӧ������)��

���У���Ϊparameter map(������ͼ��ά��һ��)����������ֲ������ڵ����ض�������ͬ��ǿ��(Ҳ������ͬ�ĵ������ߣ���һ��)����������������������Ա��ֵ�����ϵ������pixel-wise�ĸ߽�����(ʽ3)Ҳ������Ƶ�3��Ҫ��

��ͼΪ����ͨ����estimated curve parameter map��ʾ�������Կ�����ͬͨ����best-fitting parameter maps�������Ƶĵ������ƣ���ֵ��ͬ��˵����Դ���low-lightͼ����ͨ��֮�������ԺͲ����ԡ����ߵ�parameter map�ܹ�ȷ�ر�ʾ��ͬ������������(����ǽ�ϵ���������)����˿���ֱ��ͨ��pixel-wise curve mapping����ͼ����ǿ����(e)��ʾ���������������ڰ�������ǿ��
3.2 DCE-Net
Ϊ��ѧϰ������ͼ��������best-fitting curve parameter map֮���ӳ���ϵ������ʹ����Deep Curve Estimation Network (DCE-Net)������Ϊlow-lightͼ�����Ϊһ�����ڸ߽����ߵ�pixel-wise curve parameter maps�����Ĺ�����CNN��7�����жԳƽṹ�ľ��������(������U-Net)��ǰ6��ľ�����Ϊ(3x3x32��stride=1)Ȼ���һ��ReLU���������down-sampling��bn��(������Ϊ����ƻ��������ؼ�Ĺ�ϵ)�����һ�����ͨ��Ϊ24(����8�������ִε�parameter maps)����һ��Tanh�������
��������IJ�����Ϊ79,416��FlopsΪ5.21G(input Ϊ256x256x3)����������
3.3 Non-Reference Loss Functions
Ϊ��ʹ��ģ�͵�ѵ��������Zero-reference�ģ����������һϵ��non-reference loss����������ǿͼ���������
Spatial Consistency Loss:
Lspa �ܹ�ά������ͼ��������ǿ�汾֮����������(�Աȶ�)���Ӷ��ٽ���ǿ��ͼ�����ܱ��ֿռ�һ���ԡ�

���У�KΪ�ֲ��������������(i)��������iΪ���ĵ��ĸ���������(top, down, left, right)��Y��I�ֱ�Ϊ��ǿͼ�������ͼ��ľֲ�����ƽ��ǿ��ֵ������ֲ������Size�����Ե�����Ϊ4x4�����Ϊ����Size��loss�������ȶ�������
Exposure Control Loss:
Ϊ�˿���under-/over-�ع�����������Lexp �������ع�̶�������������ֲ������ƽ��ǿ����well-exposedness Level E֮��IJ����������ѭ������������E��ΪRGB��ɫ�ռ��е�gray leavel������ʵ������Ϊ0.6(���������ᵽE��[0.4,0.7]֮����������ܲ���)��

���У�MΪ���ص��ľֲ���������������SizeΪ16x16��YΪ��ǿͼ���оֲ������ƽ������ǿ��ֵ��
Color Constancy Loss��
����Gray-World��ɫ�������(����Gray-World���Բ�����ƪ����:https://zhuanlan.zhihu.com/p/84783847)�������Lcol ���ھ�����ǿͼ���е�DZ��ɫƫ��ͬʱҲ��������������ͨ��֮��Ĺ�ϵ��

���У�Jp ������ǿͼ��ͨ��p��ƽ��ǿ�ȣ�(p, q)����һ��ͨ����
Illumination Smoothness Loss��
Ϊ�˱����������ؼ�ĵ�����ϵ����ÿ��curve parameter map A��������ƽ������ʧ��

���У�NΪ������������x����y �ֱ����ˮƽ�ʹ�ֱ������ݶȲ�����
Total Loss��

����Wcol��WtvA ΪLoss��Ȩ��(Դ����Exposure control lossǰҲ��Ȩ��)
4. Experiment
Ϊ�˳�ַ���Zero-DCE������̬��Χ����������ѵ�����ϲ���low-light��over-exposedͼ��(Part 1 of SICE���ݼ���3022�Ų�ͬ�ع�̶ȵ�ͼ������2422��ͼƬ����ѵ��)��ͼ��ߴ�Ϊ512x512��
batch sizeΪ8������2080Ti��ʹ��(0, 0.02)��˹������ʼ��Ȩ�أ�bias��ʼΪ������ʹ��ADAM�Ż���(lr=1e-4)��Wcol Ϊ0.5��WtvA Ϊ20���Ӷ�ƽ��loss��߶Ȳ�ࡣ
4.1 Ablation Study
Contribution of Each Loss��

����ͼ���Կ������Ƴ�Lspa �ᵼ�¶ԱȶȽ���(�����Ƶ�����)���Ƴ�Lexp �ᵼ�µ����������عⲻ�㣻�Ƴ�Lcol ��������ص�ɫƫ�����Ƴ�LtvA �ή������������ԣ��Ӷ��������Ե�artifacts��
Effect of Parameter Setting��

����������Ҫ̽��Zero-DCE����ȿ����Լ������Ĵ���������ͼ��ʾ��L-F-N����Zero-DCE��L�������ÿ����F��feature map�Լ���������ΪN��
Impact of Training Data��

ʹ�ò�ͬ���ݼ���Zero-DCE����ѵ����1��ԭѵ������(2422)��900��low-lightͼ��Zero-DCELow ��2��DARK FACE��9000��δ��ע��low-lightͼ��Zero-DCELargeL ��3��SICE���ݼ�Part 1 and Part2��ϵ�4800�Ŷ����ع�ͼ��Zero-DCELargeLH
��?(d)�п��Կ������Ƴ��ع�������Zero-DCE��������ع���Щwell-lit����(��������)����(e)�п��Կ�����ʹ�ø���Ķ����ع��ѵ�����ݣ�Zero-DCE�Ժڰ�����Ļָ�Ч������á�
4.2 Benchmark Evaluations
�ڶ�����ݼ�(NPE LIME MEF DICM VV�Լ�SICE��Part2)����ĿǰSOAT�ķ��������˶Աȡ�
4.2.1 Visual and Perceptual Comparison

��ͼΪ��ͬ�����Ŀ��ӻ��Ƚϣ�����֮�⣬�����н���User Study��������ͬ�����������Ӿ�������
User Study���ṩ����ͼ����Ϊ�ο�������15�˶���Щ��ǿͼ����Ӿ��������ж�����������Ϊ����a) �Ƿ����over-/under-exposed artifacts��over-/under- enhanced����b) �Ƿ����ɫƫ��c) �Ƿ���ڲ���Ȼ�������Լ����������ַ�ΧΪ1-5��Խ��Խ�á�
Perceptual Index������ʹ��US score����Ӧ��perceptual Index��������֪������Խ��Խ�á�
���US��PI�Ľ�����±���ʾ������ΪUS������ΪPI��

4.2.2 Quantitative Comparison

����֮�⣬�����Ա��˲�ͬ�����ļ����ٶ�(��˵�����ֿ��ֺ�)��

4.2.3 Face Detection in the Dark
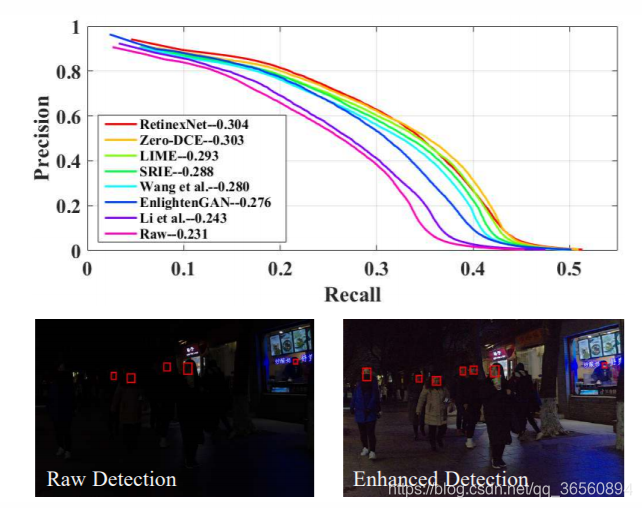
ͬʱ�������ڻ���DARK FACE���ݼ����������������Ӧ����Zero-DCE�����Կ���Ч�����������˲��١�
�عˣ�Review��
Zero-DCE������CVPR2020����ͬ������������˵���ڶ�����ݼ����Ͼ�ΪSOTA��������һ������Ҳ�ǵ�һ�νӴ�Low-Light Enhancement���������ƪ���¶����������˵ĸо�����idea������Ч���ܺã�����ΪZero-Reference�������Լල��˼�룬Curve���ò���������������������ҽ�������ͼ���йء�
����һЩ������������ƪ���µ����ۣ������кܶ�ֵ����˼�ĵط������籾��δ�����������(��������Ҳ�ᵽδ���ῼ������Ӱ��)����Ŀǰ�����������ȶ�������Ч�����Dz����ģ������ٶ�����Ŀ졢ģ��Ҳlightweight������ѵ��ʱ��Ҳ�̣�����˵ֻ��Ҫ30min��������ƻ��Ǻ����Եġ�
����
��ƪ���µĴ���Ƚϼ�����������ԭ���ߵ�Code(����)����ʱ���ڷ����Լ��ĸ��ִ��롣
����Ϊ���˵�dz����ˮƽ���ޣ����в��ԣ���������ָ�㡣
δ������ͬ�⣬����ת�أ�лл��