在前面两节的内容中我们已经介绍了注意力机制的实现原理,在这节内容中我们讲一讲有关于注意力机制的几个变种:
Soft Attention和Hard Attention
我们常用的Attention即为Soft Attention,每个权重取值范围为[0,1]
对于Hard Attention来说,每个key的注意力只会取0或者1,也就是说我们只会令某几个特定的key有注意力,且权重均为1。
Global Attention和Local Attention
一般不特殊说明的话,我们采用的Attention都是GlobalAttention。根据原始的Attention机制,每个解码时刻,并不限制解码状态的个数,而是可以动态适配编码器长度,从而匹配所有的编码器状态。下面是模型示意图:
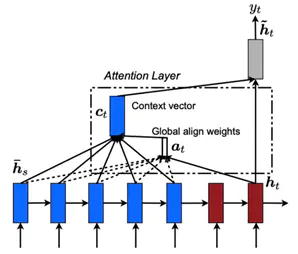
在长文本中我们对整个编码器长度进行对齐匹配,可以会导致注意力不集中的问题,因此我们通过限制注意力机制的范围,令注意力机制更加有效。
在LocalAttention中,每个解码器的ht对应一个编码器位置pt,选定区间大小D(一般是根据经验来选的),进而在编码器的[pt-D,pt+D]位置使用Attention机制,根据选择的pt不同,又可以把Local Attention分为Local-m和Local-p两种。

图 LocalAttention
Local-m:简单设置pt为ht对应位置:
Pt= t
Local-p:利用ht预测pt,进而使用高斯分布使得Local Attention的权重以pt呈现峰值形状。
Hierarchical Attention
Hierarchical Attention也可以用来解决长文本注意力不集中的问题,与Local Attention不同的是,Local Attention强行限制了注意力机制的范围,忽略剩余位置;
而Hierarchical Attention使用分层思想,在所有的状态上都利用了注意力机制,示意图如下:

图 HierarchicalAttention
在长文本中,文本由多个句子组成,句子由多个词语组成。在这样的思路中,首先分别在各个句子中使用注意力机制,提取出每个句子的关键信息,进而对每个句子的关键信息使用注意力机制,提取出文本的关键信息,最终利用文本的关键信息进行篇章及文本分类,公式如下:
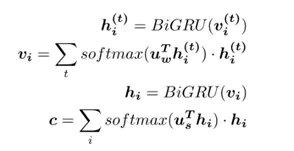
Attention Over Attention
Attention Over Attention的基本思想是对Attention的结果再Attention一次,但是具体步骤和Hierarchical Attention不同。
在AttentionOver Attention中,第一次Attention的结果是获得一个权重矩阵,两个维度分别是请求长度和文本长度,横轴和纵轴分别代表一方对另一方的注意力分布。对文本长度进行均值归一化得出和请求长度相同的注意力平均分布向量;在请求长度上归一化,则可以表示文本中各个词关于请求的注意力分布矩阵。
在第二次Attention中,我们用第一次Attention的两个结果再次求Attention权重,可以得到一个关于阅读文本的注意力分布向量。
总结:本节内容主要介绍了Attention机制的几个不同的分类变种,目前Attention机制已经成为深度学习和自然语言处理中重要的一部分,出现在各种各样的模型和任务里,事实证明,Attention机制在许多场景下是非常有效的,并且由于其形式简洁,通常不会为模型带来更多的复杂度。因此,Attention机制应当是我们在做自然语言处理尤其是Seq2Seq任务中几乎必不可少的帮手。
关注小鲸融创,一起深度学习金融科技!
